カニバリゼーション対策の概要
今回はSEO対策の一つである、カニバリゼーション対策についてデータサイエンスの知見とPythonを用いて効率的かつ効果がある対策を検討します。
カニバリゼーションとは?
二つ以上の記事が同じキーワードでランクインしていること。例えば、「千葉 お土産 選び方」というキーワードでGoogle検索をし、自社メディアが5位と15位に同時にランクインしている状況のことです。なぜカニバリゼーションが良くないのか?
理由は記事の評価が分散してしまう可能性があるためです。先ほどの例でいえば、5位の記事を本来は評価してほしいはずなのに、15位の記事にも評価が与えられてしまいます。そうすると、他の競合サイトが上位表示をしてしまう可能性があります。Googleの検索エバンジェリストのジョン・ミュラーも、以下のようにカニバリの影響を話していました。
「カニバリが発生している状況は、子供たちが一列に並びながらも、同一サイト内の2人が共に一番になりたいと思って争っているような状況。このような状況では、最終的に他の誰か(競合サイト)が先に滑り込むことになる。カニバリを発生させてサイトの評価を水に流してしまうようなことはやめるべき。」
カニバリゼーション対策の方針
次にカニバリゼーションの対策をどのように行っていくのか、その方針を下記へ記載していきます。-
「対策が必要なカニバリの状態」を定義する
ここでは「そもそもカニバリ」とはどういった状態のページを指すのかの定義を定めます。これが定義できていないと、カニバリしているキーワードとしていないキーワードの順位変動の差や、対策方針などをそもそも決めることができません。
そして、今回は効果を最大化するためにカニバリの中でも対策が必要なキーワードと不要なキーワードに分けています。 -
カニバリしているキーワード&ページをリストアップする
もしカニバリによって検索順位が下がっている場合には、カニバリしているキーワードとページをリストアップしていきます。ここでリストアップしたキーワードに対して、どのような対策をするのかを4以降で検討します。 -
カニバリが検索順位を下げる原因なのかを分析する
定義が決まった後は「カニバリが問題なのか否か」を分析します。検索順位が下がる要因はカニバリ以外にも季節要因、アルゴリズムアップデート、競合の対策など様々あげられます。そのため今回のメディアでは順位が下がる原因の一つとして、カニバリがあるのか?疑問を解消していきます。 -
キーワード別にどの対策を行うのか、分類をする
カニバリしているキーワードといっても、検索順位・他キーワードでの流入状況・コンテンツの類似度などを総合的に踏まえて対策を検討していく必要があります。ここでは「どんなキーワードに対して、どんな対策を打つべきなのか」を分類分けしていきます。 -
カニバリの対策を実施する
最後に4で決めたカニバリの対策を実施します。
今回は手順2~4のところでPythonを使いビッグデータの処理をしていきます。また、2の箇所では定常性があるか否かなど、データサイエンスの知見を活かして対策をしていきます。
次の章で実際に対策をしているため、行った内容を記載します。
「対策が必要なカニバリの状態」を定義する
今回、対策が必要なカニバリの状態を今回は以下の全てを満たす場合と定義します
- 同じキーワードの30位以内に同ドメインのページが2つ以上入っている
- 両方のページの検索順位の差が10以上になっている
同じキーワードで2つ以上のページが10位以内に上位表示されている場合、ページ内での占有率が高まります。そのため自社ドメインへのクリック率も上昇するため、手を出さない方が得策といえるでしょう。
参考)https://webtan.impress.co.jp/e/2019/06/24/32979
カニバリしているキーワード&ページをリストアップ
では、ここでカニバリしているキーワードをPythonでリストアップする方法を記載します。
1. SearchConsoleとSpreadsheetを連携させる
SearchConsoleとSpreadsheetを連携させることで、サチコでは25,000行という大量の流入キーワード一覧を見ることができます。
カニバリのためにはクリック数が少ないキーワード×ページもリストアップするため、連携をしています。連携方法は以下をご覧ください。
https://allweb-consulting.co.jp/seo/searchconsole_and_spreadsheet_integration/
2. キーワード×ページを取得する
連携ができたら、「OpenSlider」をクリック。
以下の設定をしたうえで、データを取得してください。
- DateRange:直近1か月間
- GroupBy:Page / Query
- Rows returned:25,000 rows
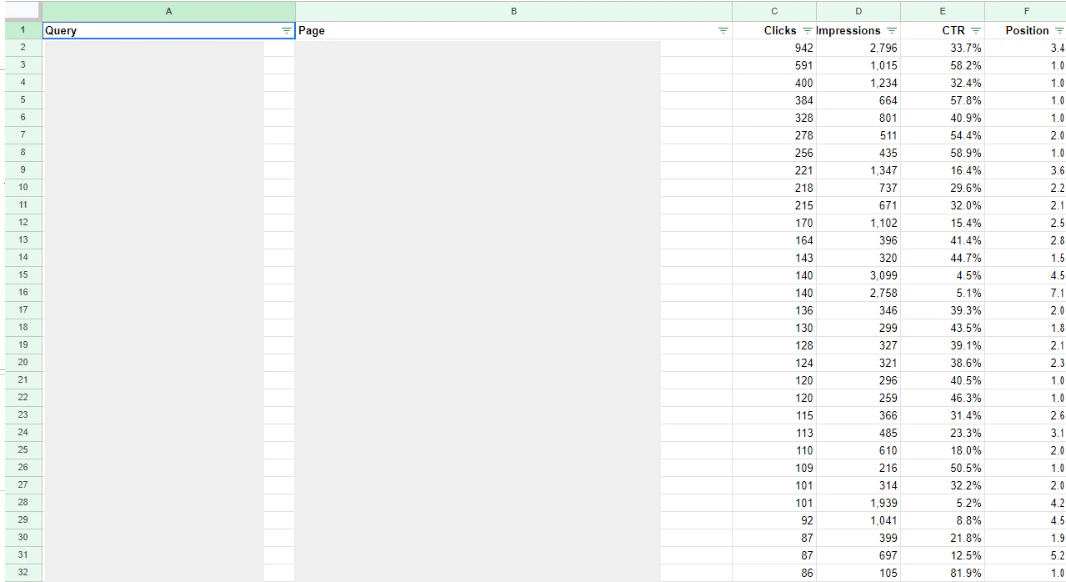
3. Pythonでカニバリキーワードをリストアップする
df_origin = pd.read_csv('/content/drive/MyDrive/media/cannibali/202407_query.csv')
df = df_origin.copy()
df = df.loc[df["Position"]<31]
#30位以下のキーワードをdfへ格納する
query_count = df["Query"].value_counts()
freq_queries = query_count[query_count > 1].index
#キーワードが2つ以上存在しているindexをfreq_queriesへ格納
df_duplicate = df[df["Query"].isin(freq_queries)]
#重複しているキーワードの情報を取得
df_duplicate = df_duplicate.loc[df_duplicate["Clicks"]>0]
#Clicksが1以上になっているキーワードのみを抽出(※0も含めると量が多くなるため)
df_unique = df_duplicate["Query"].unique()
over_list = []
for query in df_unique:
df_l = df_duplicate.loc[df_duplicate["Query"] == query]["Position"].sort_values(ascending=False)
df_length = len(df_l)
for i in range(df_length-1):
diff = df_l.iloc[i] - df_l.iloc[i+1]
if diff >10:
over_list.append(query)
break
df_dupli_diff = df_duplicate[df_duplicate["Query"].isin(over_list)]
df_dupli_diff
カニバリが検索順位を下げる原因なのか分析
次に、カニバリによって本当に順位が下がっているのかを分析します。手順としては以下の通りです。
- カニバリしているキーワードの検索順位の変動をダウンロードする
- カニバリする前後で検索順位の変動を示すファイルを分ける
- カニバリする前後の検索順位に対して、マン=ホイットニーのU検定を行う
3の箇所は後ほど詳しく解説していきます。
1. キーワードの検索順位変動のダウンロード
searchconsoleへ以下の情報を記入します。
- 日付:できるだけ長く入力(キーワードの日時変化を取得するため)
- キーワード:カニバリしているキーワードの一つを入力
- ページ:カニバリしているページの一つを入力
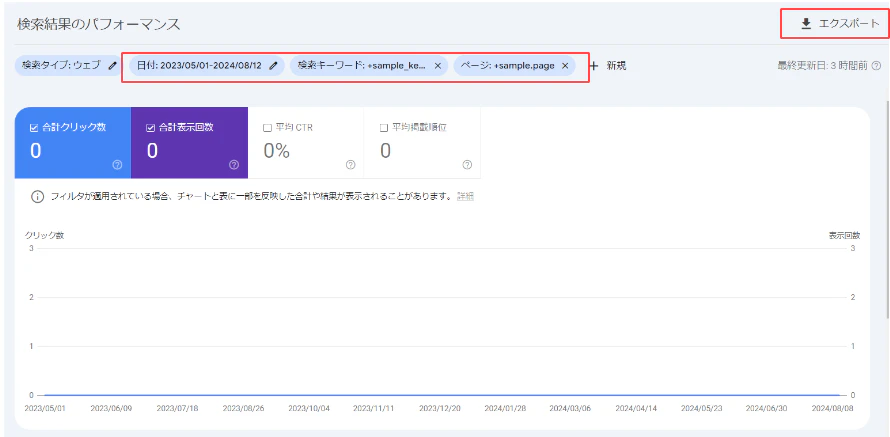
反映された後に右上の「ダウンロード」ボタンでCSV出力する。
この作業をキーワードを同じにして、2ファイル以上出力しましょう。
例えば、キーワード「千葉 お土産」に対して「sample1.html」と「sample2.html」の2つのページがカニバリしている場合、期間・キーワードは同じでページのみ変えたファイルをダウンロードしましょう。
2. 検索順位の変動を示すファイルを分ける
先ほど出力したファイルには「カニバリする側」と「カニバリされる側」が存在していると思います。
以下のグラフは横軸が日付を示しており、縦軸は検索順位です。検索順位は下になるほど1位に近づきます。
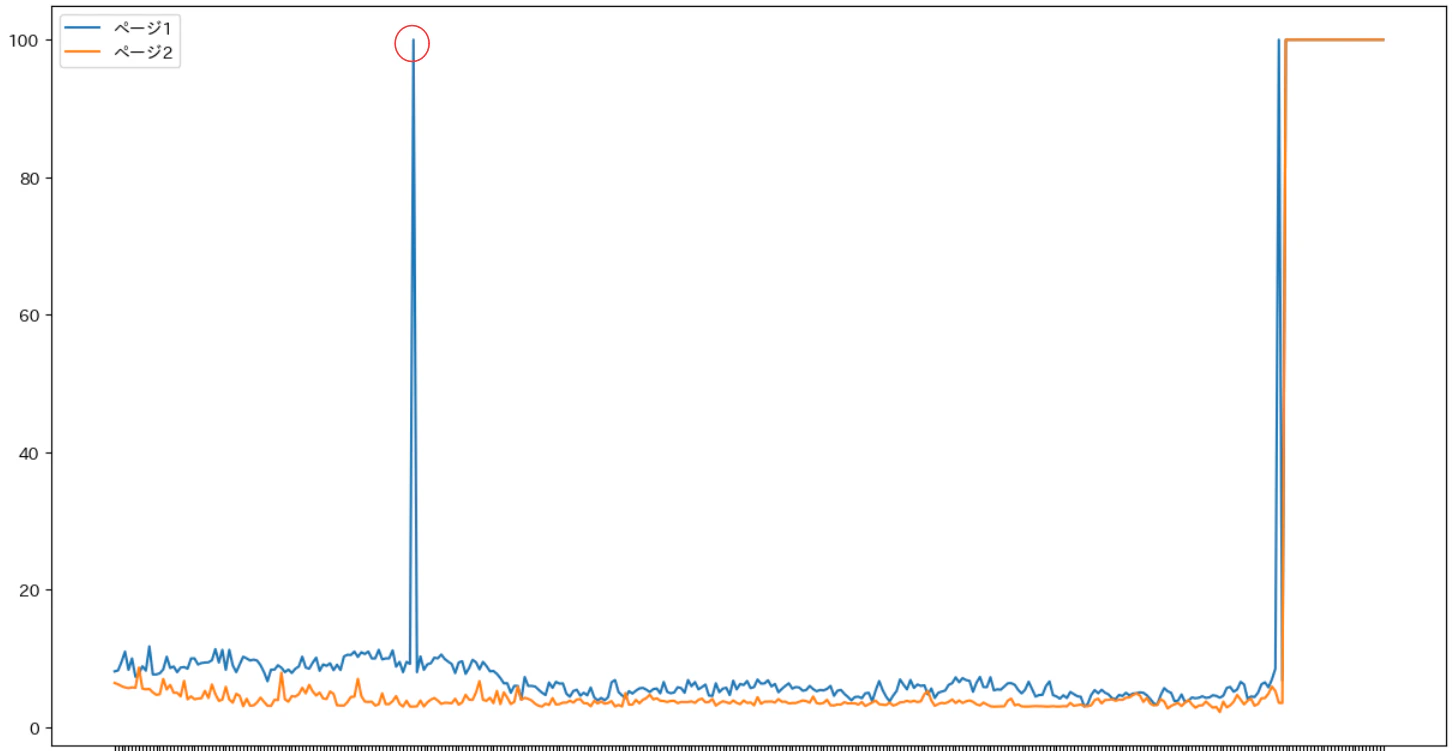
このグラフの場合には、ページ2のほうが上位表示されており、ページ1のほうが下位であり順位変動も激しいです。そのため、ページ2がカニバリする側でページ1がカニバリされる側となります。
次に難しいのが「いつカニバリした」と定義するのかです。今回は「カニバリする側の検索順位が急に上位になったタイミング」をカニバリしたタイミングと定義しました。
上記のグラフでいえば、赤丸の箇所の次のタイミングに急に圏外となっており、その次のタイミングで急に上位表示されています。この日付は2024年5月9日なので、その日付を「カニバリしたタイミング」と定義しています。
そのため、「カニバリされたページ」について2024年5月9日より前の順位変動を示したファイルとその後の順位変動を示したファイルの2つのファイルを作成します。
ここまでのPythonコードを以下へ記述します。
df_1st = pd.read_csv('/content/drive/MyDrive/media/cannibali/kaldi_must_buy_1.csv')
df_2nd = pd.read_csv('/content/drive/MyDrive/media/cannibali/kaldi_must_buy_2.csv')
df_2nd["日付"] = pd.to_datetime(df_2nd["日付"])
period1_start = pd.Timestamp("2024-01-23")
period1_end = pd.Timestamp("2024-05-08")
period2_start = pd.Timestamp("2024-05-10")
period2_end = pd.Timestamp("2024-07-30")
df_period1 = df_2nd[(df_2nd["日付"] >= period1_start) & (df_2nd["日付"] <= period1_end)].set_index("日付")
df_period2 = df_2nd[(df_2nd["日付"] >= period2_start) & (df_2nd["日付"] <= period2_end)].set_index("日付")
3. マン=ホイットニーのU検定を行う
正規分布ではなく、対応のない2つのグループのデータに差があるのか否かを調べる検定です。今回比べる2つのグループのデータというのは以下の2つです。
- カニバリされたページの、カニバリ前(5/9以前)の検索順位変動
- カニバリされたページの、カニバリ後(5/9以降)の検索順位変動
この二つのデータの検索順位に差があるのかを調べます。もし
- 差がある:カニバリ前後で順位に差がある
→カニバリによって順位が減少した可能性がある - 差がない:カニバリ前後で順位に差がない
→カニバリによって順位が減少した可能性は低い
という結論を出すことができます。
差がある場合でも、カニバリと順位減少の因果関係を示すわけではありません。例えば
- アルゴリズムアップデートがあった
- リライトをした
といった場合には、それが順位減少の要因と考えることもできます。可能性の一つととらえておきましょう。
Pythonコードでは以下のように記載します。
# 両期間の共通日付を取得
common_dates = df_period1.index.intersection(df_period2.index)
# 共通日付に対して対応するデータを抽出
rank_period1 = df_period1.loc[common_dates, "掲載順位"]
rank_period2 = df_period2.loc[common_dates, "掲載順位"]
# Mann-Whitney U検定の実施
stat, p_value = mannwhitneyu(df_period1["掲載順位"], df_period2["掲載順位"])
print(f"Mann-Whitney U検定結果: stat = {stat}, p_value = {p_value}")
# 中央値の計算
median_period1 = df_period1["掲載順位"].median()
median_period2 = df_period2["掲載順位"].median()
print(f"期間1の中央値: {median_period1}")
print(f"期間2の中央値: {median_period2}")
# グラフの描画
plt.figure(figsize=(10, 6))
plt.plot(df_period1.index, df_period1["掲載順位"], label='カニバリ前の期間')
plt.plot(df_period2.index, df_period2["掲載順位"], label='カニバリ後の期間')
plt.title('期間ごとの掲載順位の変化')
plt.xlabel('日付')
plt.ylabel('掲載順位')
plt.legend()
plt.grid(True)
plt.show()
その結果は以下の通りでした。
Mann-Whitney U検定結果: stat = 2491.5, p_value = 3.685277925083408e-07
期間1(カニバリ前)の中央値: 3.68
期間2(カニバリ後)の中央値: 4.42
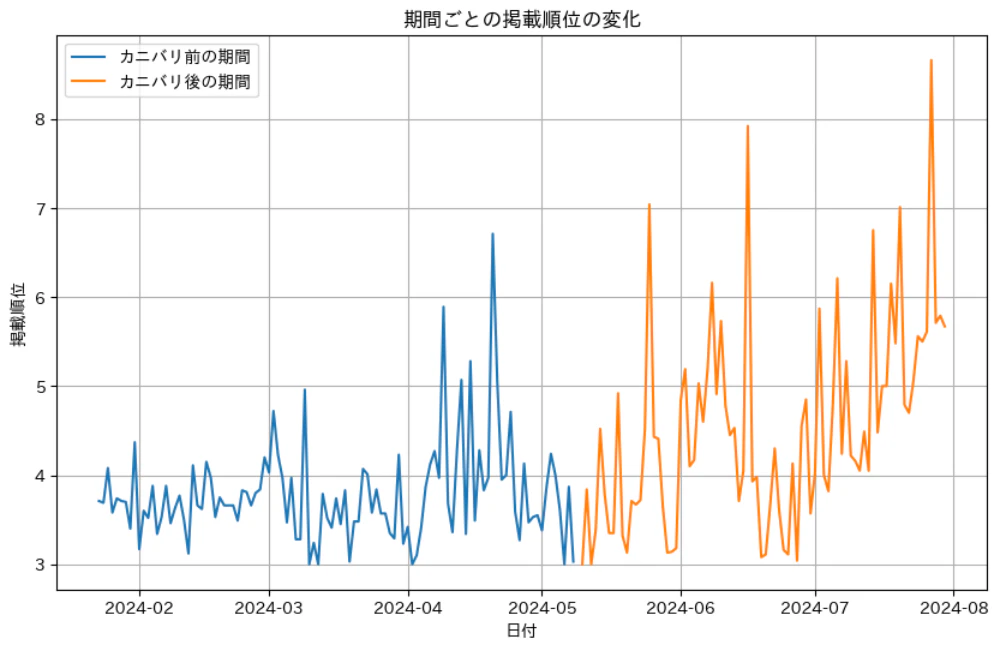
まず、p値が0.05以下であるため「差がある」といえるでしょう。次にカニバリ前後の中央値は、カニバリ後のほうが低い順位になっています。
そのため、カニバリ後のほうが順位が減少しているといえるでしょう。
今回は他の外部要因もなかったため、順位減少の原因がカニバリと仮定しておきます。
キーワード別にどの対策を行うのか分類
ここまでで以下の準備が整いました。
- カニバリキーワードとページのリストアップ
- カニバリ後に順位が落ちているという検定
次に、カニバリとなっているページ別にどのような対策を行うべきかの検討をします。結論、以下の分類分けをします。
- 「カニバリした側のページ」で別キーワードからの流入も多く見込める場合:「カニバリされた側の」ページ最適化
- 「カニバリした側のページ」で別キーワードからの流入も多く見込めない場合
┗「カニバリされた側のページ」のランキングが10位以上(11位~):コンテンツ統合
┗「カニバリされた側のページ」のランキングが10位以下(1位~10位):canocical
まず、「カニバリした側のページ」について別キーワードからの流入が多いか否かを判断します。別キーワードからの流入が多い場合には、そのページを無理にリライトする必要はありません。むしろリライトしたことで別キーワードからの流入数が下がってしまう可能性もあるでしょう。そのため、「カニバリされた側」でより順位を上げられるようにリライトをするべきです。
一方で別キーワードからの流入が多くない場合には、カニバリを防ぐために「カニバリした側」への評価はなくす方針にするべきだと考えています。つまり、canonicalで評価を別ページへ移動させるか、コンテンツを統合するべきでしょう。
では「カニバリされる側」はどのように対処すべきでしょうか?ここの判断軸は「カニバリされた側のページ」のランキングが10位以上か否か、としています。
カニバリされた側のページランクが10位以上なら、CTRを向上させるためにリライトの必要があるでしょう。そのため、コンテンツ統合とともリライトも行い、順位の向上も目指します。ただ、10位以下ならカニバリをなくすだけで順位が高くなる可能性もあるため、リライトは行いません。
参考)https://webtan.impress.co.jp/e/2019/07/01/32980
以下にその判断を行い、該当キーワードをCSV出力するコードを記載します。
df_page = df_origin.copy()
df_dupli_diff.sort_values("Clicks",ascending=False,inplace=True)
columns =["query","page","max_clicks","duplicate_clicks","click_rate"]
df_rate = pd.DataFrame(columns=columns)
query_list = df_dupli_diff["Query"].unique()
for query in query_list:
query_click =[]
df_query = df_dupli_diff[df_dupli_diff["Query"]==query]
page = df_query.iloc[len(df_query)-1,:]["Page"]
df_page_list = df_page[df_page["Page"]==page]
df_page_list = df_page_list[df_page_list["Page"]!=query]
max_clicks = df_page_list["Clicks"].max()
duplicate_clicks = df_query.iloc[len(df_query)-1,:]["Clicks"]
click_rate = max_clicks / duplicate_clicks
query_click.append(query)
query_click.append(page)
query_click.append(max_clicks)
query_click.append(duplicate_clicks)
query_click.append(click_rate)
df_rate.loc[len(df_rate)] = query_click
df_rate
df_rate_low = df_rate[df_rate["max_clicks"]<15]
df_rate_high = df_rate[df_rate["max_clicks"]>=15]
high_query_canocical =[]
high_query_page_opt =[]
for high_query in df_rate_low["query"].to_list():
df_high_query = df_dupli_diff[df_dupli_diff["Query"] == high_query]
if df_high_query.iloc[0,:]["Position"]<11 :
high_query_canocical.append(high_query)
else :
high_query_page_opt.append(high_query)
low_query_301redirect =[]
low_query_merge =[]
for low_query in df_rate_high["query"].to_list():
df_low_query = df_dupli_diff[df_dupli_diff["Query"] == low_query]
if df_low_query.iloc[0,:]["Position"]<11 :
low_query_301redirect.append(low_query)
else :
low_query_merge.append(low_query)
df_high_query_canocical = df_dupli_diff[df_dupli_diff["Query"].isin(high_query_canocical)]
df_high_query_page_opt = df_dupli_diff[df_dupli_diff["Query"].isin(high_query_page_opt)]
df_low_query_301redirect = df_dupli_diff[df_dupli_diff["Query"].isin(low_query_301redirect)]
df_low_query_merge = df_dupli_diff[df_dupli_diff["Query"].isin(low_query_merge)]
df_high_query_canocical.to_csv("high_query_canocical.csv",index=False)
df_high_query_page_opt.to_csv("high_query_page_opt.csv",index=False)
df_low_query_301redirect.to_csv("low_query_301redirect.csv",index=False)
df_low_query_merge.to_csv("low_query_merge.csv",index=False)
カニバリの対策を実施する
今回の記事ではカニバリ対策の実際の方法までは言及しません。上記でリストアップした記事を対策の方針別に対策をしていってください。
以上がPython×データサイエンスを使ったカニバリ対策です。間違っている点や気になった箇所などあれば、随時ご指摘いただけますと幸いです。