こちらの記事は、Greg Rafferty 氏により2019年11月に公開された『 Forecasting in Python with Facebook Prophet 』の和訳です。
本記事は原著者から許可を得た上で記事を公開しています。
私はベイエリアでデータサイエンティストをしているGreg Raffertyです。今回のプロジェクトで使用したコードは私のgithubからも確認できます。
この記事では、Facebook Prophetという予測ライブラリを使って様々な予測をする方法と、専門知識を使ってトレンドの不整合を処理するいくつかの高度なテクニックを紹介します。ProphetのチュートリアルはWeb上にたくさん出回っていますが、Prophetのモデルをチューニングしたり、アナリストの知識を統合してモデルにデータを適切にナビゲートさせるための方法は、どれもあまり詳しく書かれていません。この記事ではその両方を取り扱うつもりです。

https://www.instagram.com/p/BaKEnIPFUq-/
以前のTableauを使った予測についての記事では、改変したARIMAアルゴリズムを使って、米国内の商用フライトの乗客数を予測しました。ARIMAのアプローチは定常的なデータや短い時間枠を予測する場合には適切に機能しますが、ARIMAでは扱えないケースもあり、Facebookのエンジニアはそんなケースで使うためのツールを開発しました。Prophetはそのバックエンドを確率的コーディング言語であるSTANで構築されています。これによりProphetは、季節性、専門知識の包含、リスクのデータ駆動推定を追加する信頼区間など、Bayes統計学がもたらす多くの利点を持つことができるのです。
ここでは、Prophetの使い方とその利点を説明するために、3つのデータソースを見ていきます。実際にお手元でも試したいのであれば、まずはProphetをインストールしましょう。Facebookのドキュメントに簡単な説明があります。今回の記事を執筆するにあたって使用したモデルを構築するのに必要な全てのコードはこのノートブックから確認出来ます。
航空旅客
まずは簡単なものから始めてみましょう。前回の記事で使用したのと同じ航空旅客データを使用します。Prophetではタイムスタンプであるdsと値であるyの2つ以上のカラムを持つ時系列データが必要です。データをロードしたら、次のようにフォーマットしましょう:
passengers = pd.read_csv('data/AirPassengers.csv')df = pd.DataFrame()
df['ds'] = pd.to_datetime(passengers['Month'])
df['y'] = passengers['#Passengers']
このわずか数行で、Prophetは私が以前構築したARIMAモデルと同じくらい洗練された予測モデルを作ることができます。ここで私はProphetを呼び出し、6年間の予測を立てています(頻度は月次、期間は12か月×6年):
prophet = Prophet()
prophet.fit(df)
future = prophet.make_future_dataframe(periods=12 * 6, freq='M')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
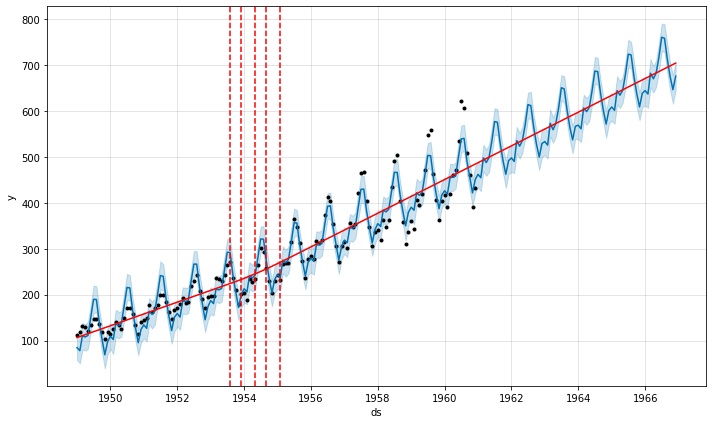
米国の民間航空会社の旅客数(1000人単位)
Prophetは、元のデータを黒い点で囲み、予測モデルを青い線を表示します。水色の領域は信頼区間です。add_changepoints_to_plot関数を使用すると、赤い線も追加されます。垂直に引かれた赤い破線はProphetがトレンドの変化を特定した場所を示し、赤い曲線はすべての季節性を取り除いたトレンドを示しています。この記事では、このプロット形式をこの後も使用していきます。
シンプルなケースはここまでにして、今度はもう少し複雑なデータを見ていきましょう。
Divvyバイクシェア
Divvyはシカゴの自転車シェアリングサービスです。私は以前、Divvyのデータを分析してWeather Undergroundから集めた気象情報と関連づけたプロジェクトに取り組んだことがあります。私はこのデータが強い季節性を示すとわかっていたので、Prophetの能力をデモンストレーションする素晴らしい例になるだろうと思い、これを選びました。
Divvyのデータは乗車ごとに区分されています。Prophet向けにデータをフォーマットするには、まず日ごとのレベルに総計し、一日ごとの”events”カラムのモード(例えば天候条件の例として:「不明確」「雨や雪」「晴れ」「曇り」「嵐」「不明」など)、利用(乗車)回数、そして平均気温からなるカラムを作成します。
データのフォーマットが完了したら、1日あたりの利用回数を見てみましょう:
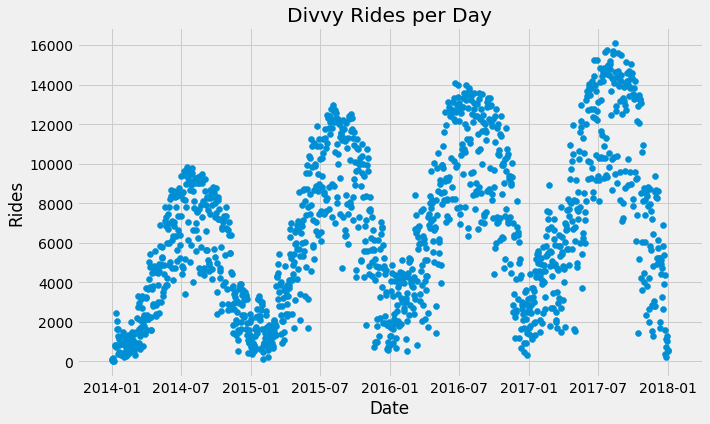
ここから、データには明らかな季節性があり、トレンドが時間とともに増加していることがわかります。このデータセットを使って、外部説明変数(additional regressors)、この場合は天気と温度を追加する方法を説明します。ま温度を見てみましょう:
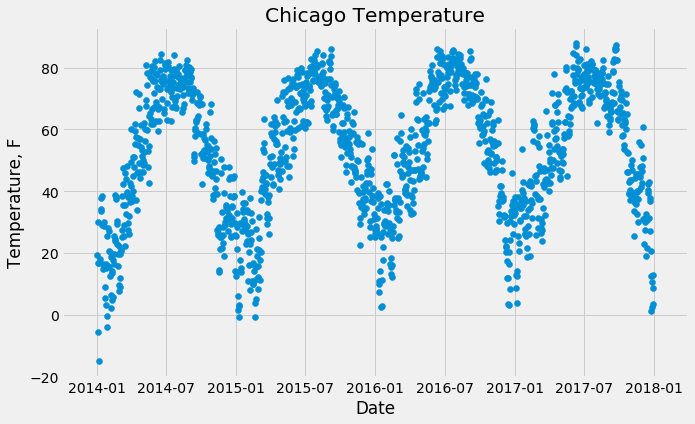
前のグラフとよく似ていますが、増加トレンドはありません。天気が晴れて暖かい日には自転車に乗る人が多くなり、両方のプロットが連動して上下するため、この類似性は理にかなっています。
別の外部説明変数を追加して予測を作成する際、追加する外部変数には予測期間のデータが必要です。このため、私はDivvyのデータを1年短くして、天気情報と合わせてその年を予測できるようにしています。またProphetにアメリカのデフォルトの祝日も追加しているのがわかると思います。
prophet = Prophet()
prophet.add_country_holidays(country_name='US')
prophet.fit(df[d['date'] < pd.to_datetime('2017-01-01')])
future = prophet.make_future_dataframe(periods=365, freq='d')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
上記のコードブロックは、航空旅客セクションで説明したトレンドプロットを作成するものです。
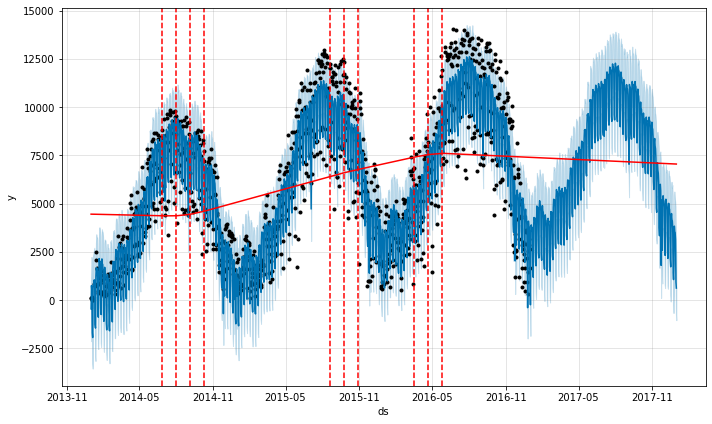
Divvyトレンドプロット
そして以下がコンポーネントプロットになります:
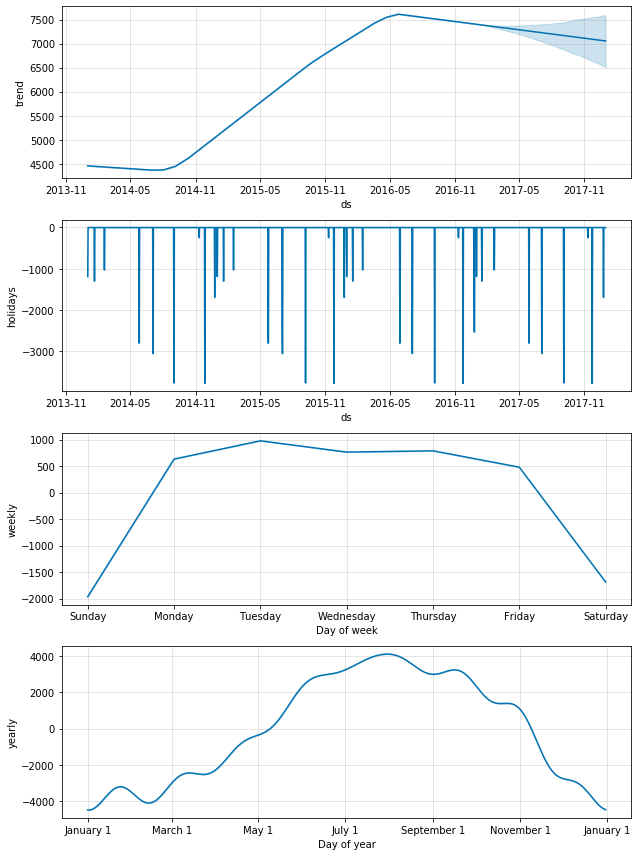
Divvyコンポーネントプロット
コンポーネントプロットは、トレンド、休日、季節性の3つのセクションで構成されています。これら3つのコンポーネントの合計が、実際にはモデル全体を占めています。トレンドとは、その他すべてのコンポーネントを差し引いたデータが示すものです。休日プロットは、モデルに含まれるすべての休日が及ぼした影響を示します。Prophetに実装されている休日は、それによってトレンドがベースラインから逸脱するものの、そのイベントの終了後には元に戻るような、不自然なイベントと捉えることができます。外部説明変数(後ほど詳しく説明します)は、それによってトレンドがベースラインから逸脱し得るという点では休日と似ていますが、イベントの後もトレンドは変化したままになるものです。今回のケースでは、休日はすべて乗客数の減少につながっており、これもまた、利用者の多くが通勤者であることを考慮すれば理にかなっています。週毎の季節性コンポーネントを見ると、利用者数は週を通じてほぼ一定ですが、週末には急激に減少することがわかります。これはほとんどの乗客が通勤者であるという推測を支持する更なる証拠になります。最後に注目したいのは、年間の季節変動のグラフがかなり波打っていることです。これらのプロットはフーリエ変換、本質的にはスタック正弦波で作成されています。明らかに今回のケースのデフォルト値は自由度が高すぎます。カーブを滑らかにするために、今度はProphetモデルを作成して、年間の季節性をオフにし、それに対応するために外部変数を追加しますが、自由度は低くします。このモデルでは、これらの天候の変数も追加します。
prophet = Prophet(growth='linear',
yearly_seasonality=False,
weekly_seasonality=True,
daily_seasonality=False,
holidays=None,
seasonality_mode='multiplicative',
seasonality_prior_scale=10,
holidays_prior_scale=10,
changepoint_prior_scale=.05,
mcmc_samples=0
).add_seasonality(name='yearly',
period=365.25,
fourier_order=3,
prior_scale=10,
mode='additive')prophet.add_country_holidays(country_name='US')
prophet.add_regressor('temp')
prophet.add_regressor('cloudy')
prophet.add_regressor('not clear')
prophet.add_regressor('rain or snow')
prophet.fit(df[df['ds'] < pd.to_datetime('2017')])
future = prophet.make_future_dataframe(periods=365, freq='D')
future['temp'] = df['temp']
future['cloudy'] = df['cloudy']
future['not clear'] = df['not clear']
future['rain or snow'] = df['rain or snow']
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
トレンドプロットはほとんど同じだったため、コンポーネントプロットのみお見せします:
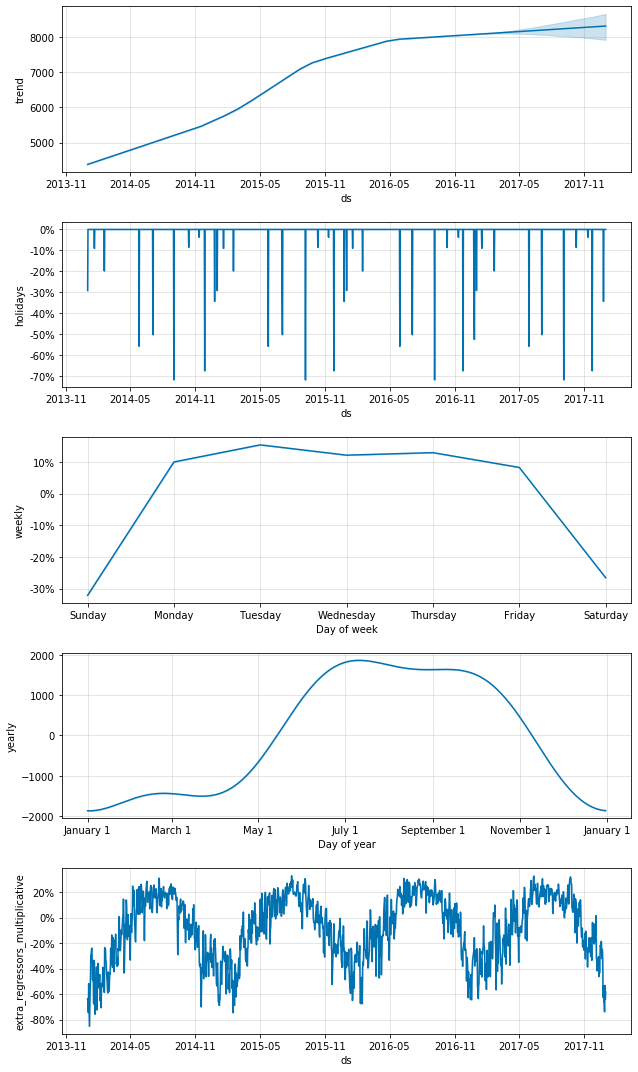
カーブを滑らかにし、年間の季節性と天候の外部変数を追加したDivvyコンポーネントプロット
このプロットでは、トレンドの最後の年は上向きになっており、最初のプロットのように下向きになっていません!これは昨年のデータの平均気温が低く、利用者数が予想以上に減少したためと説明できます。また、年次のカーブが平滑化され、extra_regressors_multiplicativeプロットが追加されています。これは天候の影響を示しています。利用者数の増減も想定通りの結果になっています。夏には利用者数が増加し、冬には減少と、その変動の多くは天候によって説明できます。実演のためにもう一つ確認したいことがあります。上記のモデルを、今度は雨や雪の外部変数のみを追加してもう一度実行します。コンポーネントプロットは次のとおりになりました。
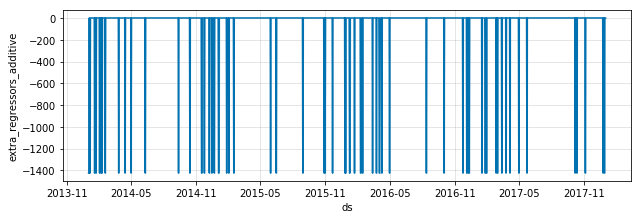
雨や雪の影響のみを示したDivvyコンポーネントプロット
これは、雨や雪が降っている日は、そうでない日に比べて、一日の利用回数が約1400回も少なくなることを示しています。なかなか面白いでしょう?
最後に、このデータセットを時間単位で集約し、もう1つのコンポーネントプロットである日次の季節性を作成します。そのプロットは次のようになります:
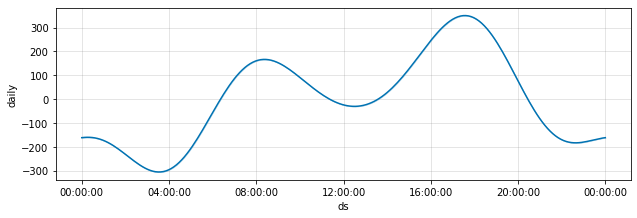
日次の季節性を示したDivvyコンポーネントプロット
Rives氏が言うとおり、午前4時は朝起きる時間としては最悪なのでしょう。明らかにシカゴの自転車利用者たちも同意見のようです。午前8時を過ぎると朝の通勤者によるピークを迎えます。そして午後6時頃には夕方の帰宅者による全体のピークが訪れます。真夜中過ぎに小さなピークがあるのもわかります。バーから家に帰る人たちによるものだと思われます。以上がDivvyのデータです!次はInstagramに移りましょう。
Prophetは本来Facebookが自社のデータを分析するためにされたものです。ならばこのデータセットはProphetを使ってみるには最適でしょう。私はInstagramでいくつかの興味深いトレンドを持つアカウントを探し、次の3つのアカウントを見つけました: @natgeo、@kosh_dp、@jamesrodriguez10
National Geographic

https://www.instagram.com/p/B5G_U_IgVKv/
2017年、私はあるプロジェクトに取り組んでいる時、National GeographicのInstagramアカウントにある異常があることに気付きました。2016年の8月、写真あたりのいいね数が不可解にも突然、劇的に増加し8月が終わるとすぐにベースラインに戻るという出来事がありました。私はこの急上昇がいいね数を増やすための1ヶ月を通したマーケティングキャンペーンによるものとしてモデル化し、将来のマーケティングキャンペーンの効果を予測できるかどうか試してみようと思いました。
National Geographicののいいね数は以下のとおりです。トレンドは明らかに増加しており、時間の経過とともにばらつきも増えています。いいね数が劇的に多い例外はたくさんありますが、2016年8月のスパイクでは、その月に投稿されたすべての写真が、その前後の月に投稿されたものよりも圧倒的に多いいいね数を獲得しています。

これがなぜなのか推測したくはありませんが、せっかく作ったこのモデルのために、例えばNational Geographicのマーケティング部門が、特にいいね数を増やすことを目的とした1カ月間のキャンペーンを行ったと仮定してみましょう。まず、この事実を無視したモデルを構築し、比較するためのベースラインを作成します。
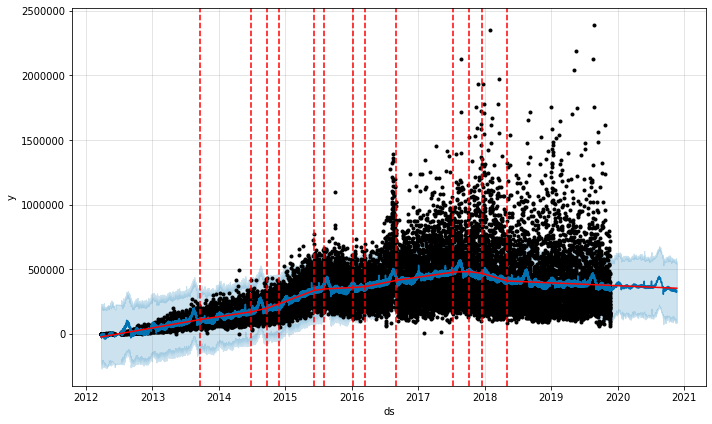
National Geographicの写真1枚あたりのいいね数
Prophetはこのスパイクのために混乱してしまっているようです。毎年8月の急上昇が青線で示されているように、毎年の季節性コンポーネントにこのスパイクを追加しようとしているのがわかります。Prophetはこれを繰り返しのイベントであるとということにしたいようです。Prophetに、他の年では繰り返されていない特別なことが2016年には起こったということを伝えるために、この月に休日を作ることにしましょう:
promo = pd.DataFrame({'holiday': "Promo event",
'ds' : pd.to_datetime(['2016-08-01']),
'lower_window': 0,
'upper_window': 31})
future_promo = pd.DataFrame({'holiday': "Promo event",
'ds' : pd.to_datetime(['2020-08-01']),
'lower_window': 0,
'upper_window': 31})promos_hypothetical = pd.concat([promo, future_promo])
promoデータフレームには2016年8月のイベントのみが含まれ、promos_hypotheticalデータフレームには、National Geographicが2020年8月に実施を検討していると仮定した追加のプロモーションが含まれています。休日を追加する場合、Prophetでは、ブラックフライデーを感謝祭に含めるか、クリスマスイブをクリスマスに含めるかなど、基本的な休日イベントに含める日数を多めに設定することもできますし、少なめに設定することもできます。今回、私は”holiday”の後に31日を追加し、月全体をイベントに含めました。以下がそのコードと新しいトレンドプロットになります。Prophetオブジェクトを呼び出すときに、holidays=promoを指定していることに注意してください。
prophet = Prophet(holidays=promo)
prophet.add_country_holidays(country_name='US')
prophet.fit(df)
future = prophet.make_future_dataframe(periods=365, freq='D')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
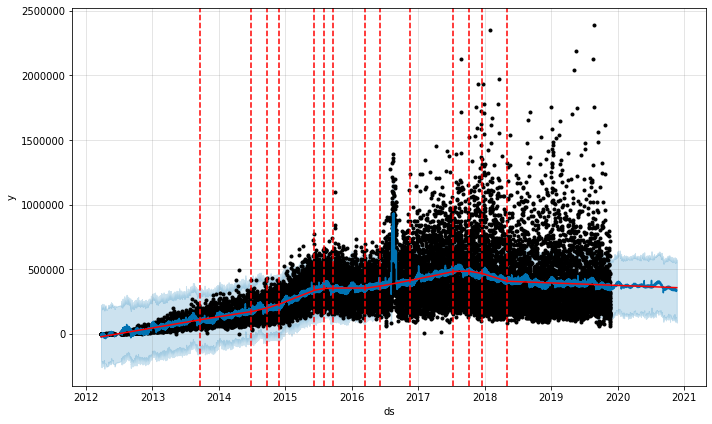
2016年8月のマーケティングキャンペーンを含めたNational Geographicの写真1枚あたりのいいね数
素晴らしいですね!ここでProphetはこの馬鹿げたいいね数の急増を毎年8月ではなく、2016年のみに確かに急増したことを示しています。そこで次はもう一度このモデルを、promos_hypotheticalデータフレームを使い、National Geographicが2020年に同じキャンペーンを実施したらどうなるのか予測してみましょう。
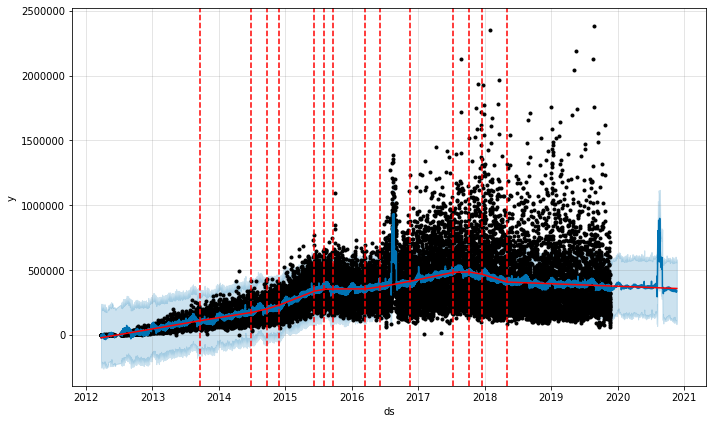
2020年にマーケティングキャンペーンを行なったと仮定した場合のNational Geographicの写真1枚あたりのいいね数
この方法を使って、不自然なイベントを追加したときの動作を予測することができます。例えば、今年の商品販売計画はモデルになるかもしれません。それでは次のアカウントに移りましょう。
Anastasia Kosh

https://www.instagram.com/p/BfZG2QCgL37/
Anastasia Koshはロシアの写真家で、自身のインスタグラムに奇抜な自画像を投稿したり、YouTubeにミュージックビデオを投稿したりしています。私が数年前にモスクワに住んでいたとき、私たちは同じ通りに住んでおり隣人同士でした。当時、彼女のInstagramには約1万人のフォロワーがいましたが、2017年にはYouTubeのアカウントがロシアで急速に広まり、モスクワの10代を中心にちょっとした有名人になっています。彼女のInstagramアカウントは飛躍的に成長し、フォロワーは急速に100万人に近づいており、この指数関数的な成長は、Prophetにとってぴったりなチャレンジになると思いました。
モデル化するデータは次のとおりです:
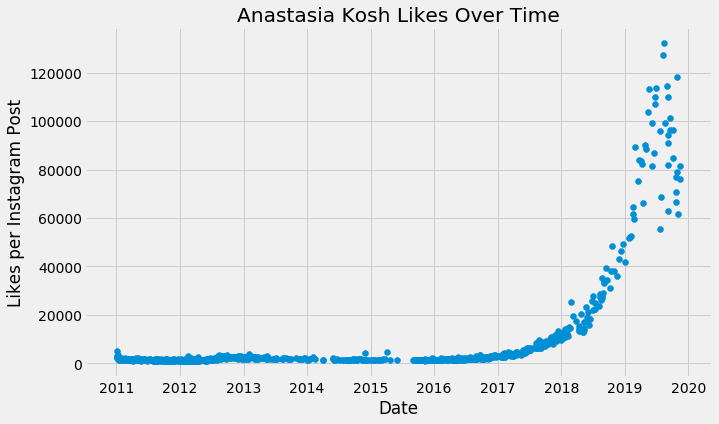
これは典型的なホッケースティック型で楽観的な成長を示していますが、この場合に限っては本当にこのようになるでしょう!これまで見てきた他のデータと同じように、線形成長でモデル化すると、非現実的な予測になります。
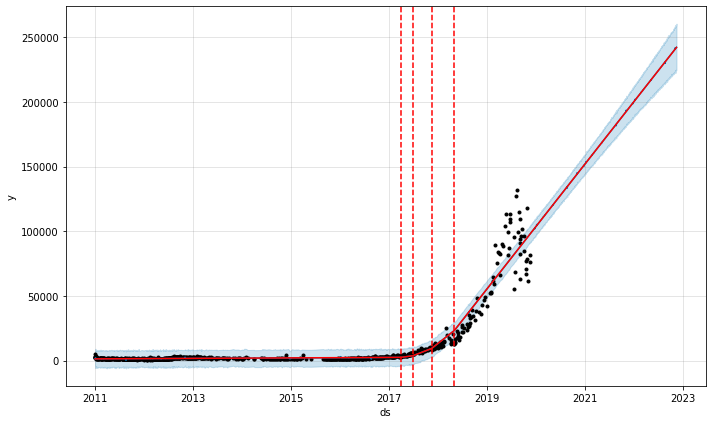
線形成長するAnastasia Koshの写真1枚あたりのいいね数
この曲線は無限に続きます。ですが、もちろんInstagramのいいねの数には上限があります。理論的には、この上限はサービス上の全登録アカウント数に等しくなります。しかし現実的には、すべてのアカウントに写真が閲覧されるわけではなく、また気に入ってくれるわけでもありません。ここで、アナリストとしてのちょっとした専門知識が役に立ちます。今回、私はこれをロジスティック成長でモデル化することにしました。そのためにはProphetに上限値ceiling(Prophetはそれをcapと呼びます)と下限値のfloorを教えてあげなければなりません。
cap = 200000
floor = 0
df['cap'] = cap
df['floor'] = floor
Instagramについての私の知識と少しの試行錯誤の結果、いいねの上限は20万回、下限は0回に決めました。Prophetでは、これらの値は時間の関数として定義できるため、定数である必要はありません。この場合は、定数値がまさに必要なケースと言えます:
prophet = Prophet(growth='logistic',
changepoint_range=0.95,
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
seasonality_prior_scale=10,
changepoint_prior_scale=.01)
prophet.add_country_holidays(country_name='RU')
prophet.fit(df)
future = prophet.make_future_dataframe(periods=1460, freq='D')
future['cap'] = cap
future['floor'] = floor
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
私は今回この成長をロジスティック成長と定義し、すべての季節性をオフにして(このプロットではそれほど多くはなかったようです)、更にいくつかのパラメータを調整しました。Anastasiaのフォロワーの大部分がロシアにいるので、私はロシアのデフォルト休日も追加しました。.fitメソッドをdfで呼び出すと、Prophetはdfのcapとfloorのカラムを見て、それらをモデルに含めるように認識します。この時、予測データフレームを作成するときにもこれらのカラムをデータフレームに追加するようにしましょう(上記のコードブロックのfutureデータフレーム)。これについては、次のセクションで改めて説明します。ですが今の所はこれで、トレンドプロットはずっと現実的なものになりました!
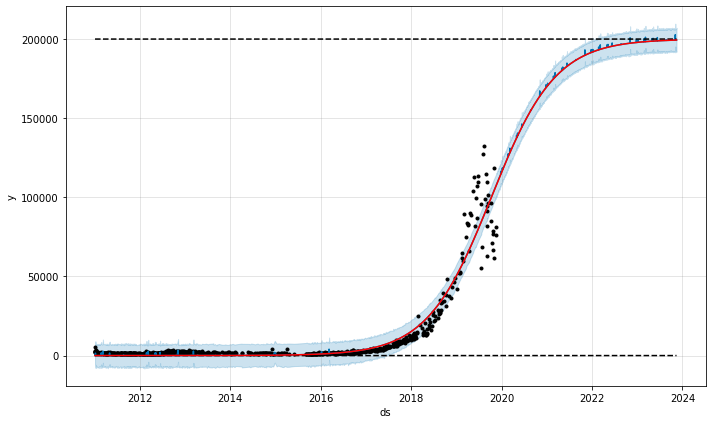
ロジスティック成長するAnastasia Koshの写真1枚あたりのいいね数
それでは最後の例を見ていきましょう。
James Rodríguez

https://www.instagram.com/p/BySl8I7HOWa/
James Rodríguezはコロンビアのサッカー選手で、2014年と2018年の両方のワールドカップで素晴らしいプレーをした人物です。彼のInstagramアカウントは開設以来着実に成長しています。しかし、以前の分析に取り組んでいた際に、過去2回のワールドカップの間、彼のアカウントに急激かつ持続的なフォロワーの増加が見られることに気づきました。National Geographicのアカウントの急増がホリデーシーズンとしてモデル化できるのとは対照的に、Rodríguezの成長は2つのトーナメントの後、ベースラインには戻らずに、また新たなベースラインを再定義しています。これは根本的に異なる動きであり、この動きを取得するにはこれまでとは異なるモデル化アプローチが必要です。
以下がJames Rodríguezのアカウント開設以降の写真1枚あたりのいいね数は以下の通りです:
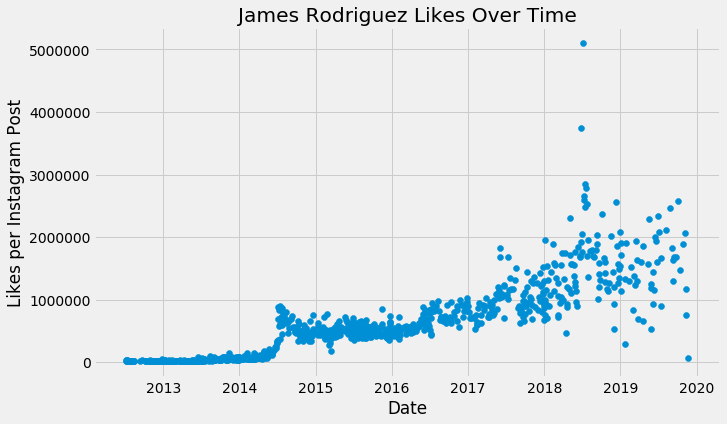
今回のチュートリアルでこれまでに使用してきたテクニックだけでは、これをきれいにモデル化するのは困難です。2014年夏の第一回ワールドカップではトレンドのベースラインが増加し、2018年夏の第二回ワールドカップではスパイクが発生し、さらにベースラインも変化した可能性があります。この動きをデフォルトモデルでモデル化しようとしても、うまくいきません。
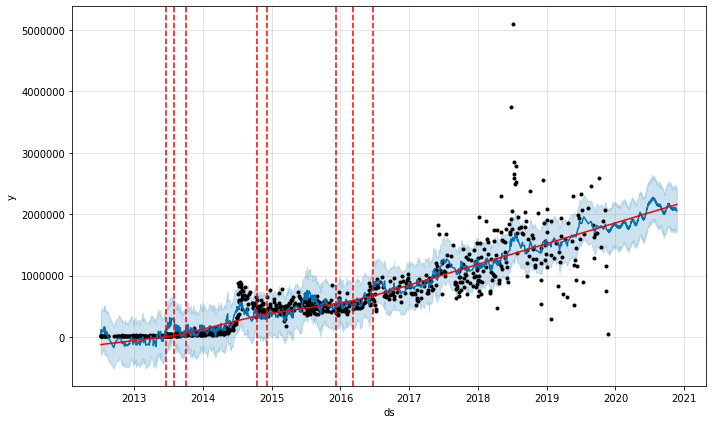
James Rodríguezの写真1枚あたりのいいね数
とはいえ、これがひどいモデルであるとも言えません。この2つのワールドカップでの振る舞いがきちんとモデル化されていないだけです。上のAnastasia Koshのデータのように、これらのトーナメントを休日としてモデル化すれば、モデルに改善が見られます。
wc_2014 = pd.DataFrame({'holiday': "World Cup 2014",
'ds' : pd.to_datetime(['2014-06-12']),
'lower_window': 0,
'upper_window': 40})
wc_2018 = pd.DataFrame({'holiday': "World Cup 2018",
'ds' : pd.to_datetime(['2018-06-14']),
'lower_window': 0,
'upper_window': 40})world_cup = pd.concat([wc_2014, wc_2018])prophet = Prophet(yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
holidays=world_cup,
changepoint_prior_scale=.1)
prophet.fit(df)
future = prophet.make_future_dataframe(periods=365, freq='D')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
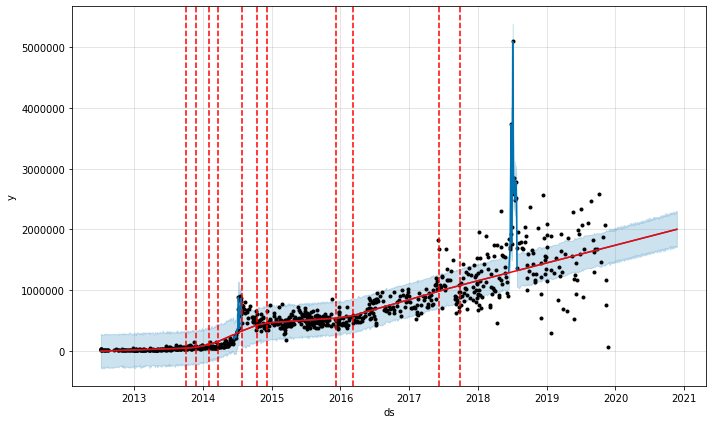
ワールドカップ期間中に休日を追加した際のJames Rodríguezの写真1枚あたりのいいね数
2014年のワールドカップを中心に、変化していくトレンドラインにモデルが対応していくのがあまりに遅く、個人的にまだ気に入りません。トレンドラインの移行が滑らかすぎます。こんな時は、外部説明変数を追加することで、Prophetに唐突な変化を考慮させることができます。
この例では、それぞれの大会ごとに大会前と大会後の2つの期間を定義しています。このようにモデル化することで、トーナメントの前には特定のトレンドラインがあり、トーナメント中にそのトレンドラインは直線的な変化を経て、トーナメントの後にはさらに異なるトレンドラインが続くように想定します。私はこれらの期間を0か1、オンかオフかで定義し、Prophetにデータを訓練させてその大きさを学習させます。
df['during_world_cup_2014'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2014-05-02')) & (df['ds'] <= pd.to_datetime('2014-08-25')), 'during_world_cup_2014'] = 1
df['after_world_cup_2014'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2014-08-25')), 'after_world_cup_2014'] = 1df['during_world_cup_2018'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2018-06-04')) & (df['ds'] <= pd.to_datetime('2018-07-03')), 'during_world_cup_2018'] = 1
df['after_world_cup_2018'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2018-07-03')), 'after_world_cup_2018'] = 1
「休日」イベントを含めるように、将来のデータフレームを以下のように更新します。
prophet = Prophet(yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
holidays=world_cup,
changepoint_prior_scale=.1)prophet.add_regressor('during_world_cup_2014', mode='additive')
prophet.add_regressor('after_world_cup_2014', mode='additive')
prophet.add_regressor('during_world_cup_2018', mode='additive')
prophet.add_regressor('after_world_cup_2018', mode='additive')prophet.fit(df)
future = prophet.make_future_dataframe(periods=365)future['during_world_cup_2014'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2014-05-02')) & (future['ds'] <= pd.to_datetime('2014-08-25')), 'during_world_cup_2014'] = 1
future['after_world_cup_2014'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2014-08-25')), 'after_world_cup_2014'] = 1future['during_world_cup_2018'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2018-06-04')) & (future['ds'] <= pd.to_datetime('2018-07-03')), 'during_world_cup_2018'] = 1
future['after_world_cup_2018'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2018-07-03')), 'after_world_cup_2018'] = 1forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
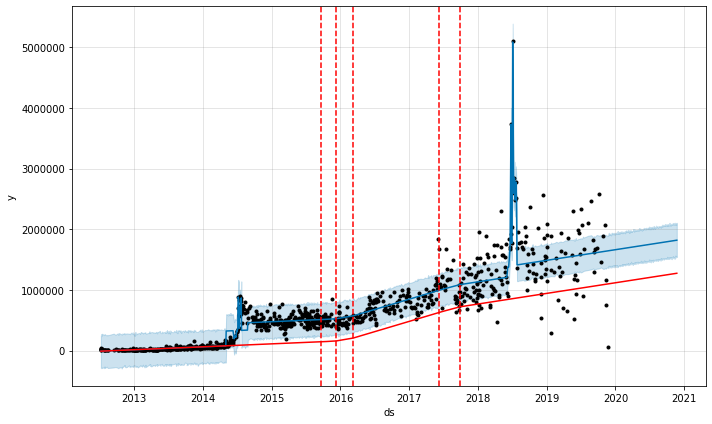
外部説明変数を追加した状態のJames Rodríguezの写真1枚あたりのいいね数
この青い線を見てください。赤い線はトレンドのみを示し、追加の外部変数と休日の影響からは除外されます。ワールドカップ期間中、青のトレンドラインがどのように急激に上昇するかご覧ください。これはまさに、私たちの専門知識が教えてくれる行動です!Rodríguezがワールドカップで初ゴールを決めた時、突如として彼のアカウントに何千人ものフォロワーが集まりました。コンポーネントプロットを見れば、これらの外部説明変数による具体的な効果を確認できます。
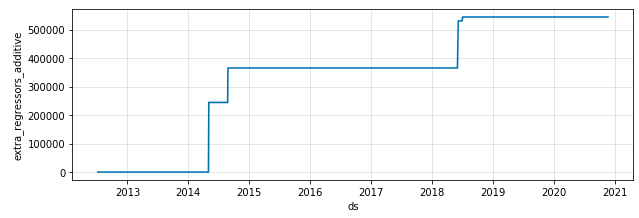
James Rodríguezのワールドカップ外部説明変数のコンポーネントプロット
これは、2013年かた2014年初旬のRodríguezの写真のいいね数にワールドカップは何の影響もなかったことを示しています。2014年ワールドカップ期間中、彼の平均値は画像のように劇的な上昇を見せ、それは大会終了後も続きました(これは彼がこのイベントの間に非常に多くの活発なフォロワーを得たことから説明できます)。2018年のワールドカップでも似たような増加があったもののそれほど劇的ではありませんでした。これはおそらくその時点には、彼のことを知らないサッカーファンがそれほど多く残されていなかったからであると推測できます。
この記事に最後まで付いてきてくれてありがとうございます!これで、Prophetにおける休日の使い方、線形成長とロジスティック成長について、また外部説明変数(additional regressors)を使用してProphetの予測を大幅に向上させる方法を理解できたことと思います。FacebookはProphetという信じられないほどに有益なツールを作り、かつては非常に困難だった確率的予測の作業を、幅広いチューニングが可能なシンプルなパラメーターのセットにしました。これで、あなたの予測も素晴らしいものになりますように!
翻訳協力
Original Author: Greg Rafferty
Thank you for letting us share your knowledge!
この記事は以下の方々のご協力により公開する事が出来ました。
改めて感謝致します。
選定担当: yumika tomita
翻訳担当: siho1
監査担当: takujio
公開担当: siho1
ご意見・ご感想をお待ちしております
今回の記事は、いかがだったでしょうか?
・こうしたら良かった、もっとこうして欲しい、こうした方が良いのではないか
・こういったところが良かった
などなど、率直なご意見を募集しております。
いただいたお声は、今後の記事の質向上に役立たせていただきますので、お気軽にコメント欄にてご投稿ください。
みなさまのメッセージをお待ちしております。