こちらの記事は、『Goodbye, Object Oriented Programming』の和訳になります。

私は何十年もの間、オブジェクト指向言語でプログラミングをしてきました。最初に使ったオブジェクト指向言語はC ++で、次にSmalltalkを使い、その後.NETとJavaを使いました。
私は継承、カプセル化、およびポリモーフィズムというパラダイムの三本柱の恩恵を活用することに熱狂的でした。これらはパラダイムの三本柱です。
再利用の約束を得ることと、この新しくエキサイティングな環境に私よりも以前に来ていた人々によって得られた知恵を利用することに、私は貪欲でした。
現実世界のオブジェクトをクラスに割当てるという考えに対し興奮を抑えることができず、世界の全てが正しい場所にきちんと収まることを期待していました。
これは、大間違いでした。
継承:倒れる第1の柱

一見すると、継承はオブジェクト指向パラダイムの最大の利点であるように思われます。
新たに教化された者に例として紹介される、形状階層の単純化された例はすべて、論理的に理解できるように思えます。
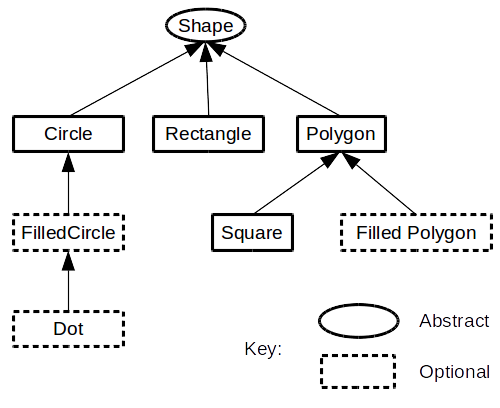
そして、「再利用」はその日のスローガンになるのです。
いや…その一年、またおそらくは永遠のスローガンとなります。
私はこれを鵜呑みにし、新たな知見を胸に世界に飛び出していきました。
バナナ、猿、ジャングル問題
宗教と解決すべき課題とを心に抱いて、私はクラス階層の構築を始め、コードを書き始めました。そしてすべては順調に進んでいました。
既存のクラスから継承することにより、再利用の約束をうまく利用する準備ができていた日を、私は決して忘れません。それは私がずっと待っていた瞬間でした。
新しいプロジェクトが現れ、私は前回のプロジェクトでとても好きだったクラスを思い出しました。
問題ない。お役立ちの再利用だ。他のプロジェクトからそのクラスを取ってきて使うだけだ。
ええと…実際は…そのクラスだけじゃないか。基底クラスが必要になる。でも…でも、それだけだ。
あー…待てよ…基底クラスの基底クラスも必要みたいだな…
それと…「すべての」基底クラスが必要になるな。オーケー…オーケー…何とかする。問題ない。
やったね。今度はコンパイルができないよ。なぜ??ああ、わかった…このオブジェクトは他のオブジェクトを包含してる。だからそれも必要になるんだろう。問題ない。
ちょっと待って…そのオブジェクトが必要なだけじゃない。オブジェクトの基底とその基底の基底とその基底の…と、包含されているすべてのオブジェクトと、それらが包含するもののすべての基底と、それらの基底の基底の基底が必要で…
あーあ!
Erlangを開発したJoe Armstrongによる素晴らしい引用があります。
「オブジェクト指向言語の問題は、暗黙の環境を常に持ち歩いていることだ。
欲しかったのはバナナだけなのに、あなたが得たのはバナナを持っていたゴリラと、ジャングル全体だった。」
バナナ、猿、ジャングル問題のソリューション
深すぎる階層を作成しないことで、この問題を解決することができます。
しかし、もし継承が再利用のキーであるならば、そのメカニズムに私が課す制限は再利用の利点を確実に制限するでしょう。そうでしょう?
そうなのです。
それでは、教えに盲目的に従った哀れなオブジェクト指向プログラマは何をすべきでしょうか?
包含と委譲です。
これについては後で詳しく説明します。
ダイヤモンド問題
遅かれ早かれ、言語によっては解決できない以下の問題が、その醜い頭をもたげてくるでしょう。

コピー機がスキャナとプリンタの両方を継承する構造は論理的に理解できるように思えますが、ほとんどのオブジェクト指向言語はこれをサポートしていません。オブジェクト指向言語でこれをサポートすることの何がそれほど難しいことなのでしょう?
さて、次の疑似コードで考えてみてください。
Class PoweredDevice {
}
Class Scanner inherits from PoweredDevice {
function start() {
}
}
Class Printer inherits from PoweredDevice {
function start() {
}
}
Class Copier inherits from Scanner, Printer {
}
ScannerクラスとPrinterクラスの両方でstartという関数を実装することに注意してください。
では、Copierクラスはどのstart関数を継承しているのでしょうか。Scanner?Printer?両方はできません。
ダイヤモンド問題のソリューション
解決策は簡単です。多重継承をしないでください。
はい、その通り。ほとんどのオブジェクト指向言語は、これを許可していません。
でも、でも……これをモデル化しなければならないとしたら? 私は再利用がしたいんだ!
そこで、包含と委譲を使う必要があります。
Class PoweredDevice {
}
Class Scanner inherits from PoweredDevice {
function start() {
}
}
Class Printer inherits from PoweredDevice {
function start() {
}
}
Class Copier {
Scanner scanner;
Printer printer;
function start() {
printer.start()
}
}
ここで、Copierクラスが今度はPrinterのインスタンスとScannerのインスタンスを包含していることに注意してください。 start関数をPrinterクラスの実装に委譲しています。 それはScannerにも同じくらい簡単に委譲され得ます。
この問題は、「継承」の柱における、さらに別のヒビになります。
壊れやすい基底クラスの問題
だから私は、継承階層を浅くし、多重継承がおきないようにしています。 私にはダイヤモンド問題はありません。
そしてすべて順調に事は進んでいました。あるできごとまで…
ある日私のコードは動作していて、翌日、動作しなくなりました。私はソースコードを編集していないのに、突如として問題が起こったのです。
多分バグかもしれない…でも待てよ…何かが確かに変わってる…
**しかし、バグは私のコードの中ではありませんでした。**基底クラスが変更されていたのです。
基底クラスに対するどのような変更が私のコードを壊すことができたのでしょうか?
これがその答えです…
次の基底クラスを考えてください(Javaで書かれていますが、Javaがわからない場合でも理解しやすいはずです)。
import java.util.ArrayList;
public class Array {
private ArrayList<Object> a = new ArrayList<Object>();
public void add(Object element) {
a.add(element);
}
public void addAll(Object elements[]) {
for (int i = 0; i < elements.length; ++i) {
a.add(elements[i]); // this line is going to be changed
}
}
}
重要:コメントつきの行に注意してください。この行は後ほど変更され、この変更が後にソースコードを壊します。
このクラスは、そのインタフェースとして**add()とaddAll()**の2つの関数を持っています。 **add()**関数は一つの要素を追加し、addAll()関数はadd関数を呼び出すことによって複数の要素を追加します。
そしてここに派生クラスがあります。
public class ArrayCount extends Array {
private int count = 0;
@Override
public void add(Object element) {
super.add(element);
++count;
}
@Override
public void addAll(Object elements[]) {
super.addAll(elements);
count += elements.length;
}
}
ArrayCountクラスは、一般的なArrayクラスが特殊化したものです。唯一の動作上の違いは、ArrayCountは要素数のカウントを保持することです。
両方のクラスを詳細に見てみましょう。
Array add()は要素をローカルのArrayListに追加します。
Array addAll()は、各要素に対してローカルのArrayList addを呼び出します。
ArrayCount add()は、その基底のadd()を呼び出してからカウントを増やします。
ArrayCount addAll()は、その基底のaddAll()を呼び出してから、要素数だけカウントを増やします。
そして、すべがうまくいきます。
次に破壊的変更です。基底クラスにおけるコメント付きのコード行は、次のように変更されます。
public void addAll(Object elements[]) {
for (int i = 0; i < elements.length; ++i) {
add(elements[i]); // this line was changed
}
}
基底クラスの作成者に限り、それは宣言どおりに機能しています。そして自動化されたテストを全てパスします。
しかし、基底クラスの作成者は派生クラスに気付いていません。そして派生クラスの作成者は不都合な事実を突然知ってショックを受けます。
**ArrayCount addAll()は、その基底のaddAll()を呼び出しますが、これは、派生クラスによって「オーバーライド」されているadd()**を内部的に呼び出します。
これにより、派生クラスのadd()が呼び出されるたびにカウントが増え、また、派生クラスのaddAllにおいて追加された要素の数だけ**「再度」カウントが増えます**。
「二重にカウント」しているのです。
この事が起きる可能性があるなら、そしてそれは起きているのですが、派生クラスの作成者は基底クラスがどのように実装されていたかを「知って」いなければなりません。また派生クラスの作成者は、それが彼らの派生クラスを予期しない方法で破壊する可能性があるため、基底クラスのすべての変更について通知されなければなりません。
うーん!この巨大なヒビは、貴重な継承の柱の安定性を絶えず脅かしています。
壊れやすい基底クラスの問題のソリューション
もう一度、お役立ちの包含と委譲についてです。
包含と委譲を使用することにより、ホワイトボックスプログラミングからブラックボックスプログラミングへと移ります。ホワイトボックスプログラミングでは、基底クラスの実装を調べなければなりません。
ブラックボックスプログラミングでは、その関数の1つをオーバーライドして基底クラスにコードを注入することはできないため、実装を完全に無視することができます。私たちはインターフェースに気を配るだけで良いのです。
ホワイトボックスプログラミングの傾向は、厄介です…
継承は再利用にとって大きな勝利であると思われていました。
オブジェクト指向言語では、包含や委譲を簡単に実行できません。
オブジェクト指向言語は継承を容易にするよう設計されていました。
もしあなたが私のような人間であれば、あなたは継承を使用した再利用について疑問に思い始めるはずです。もっと言えば、クラス階層で分類することに対してあなたの自信は揺らいでるのではないでしょうか。
階層の問題
新しい会社に入るたび、例えば従業員ハンドブックといったCompany Documentsを置く場所を作成するとき、私はこの問題に悩むのです。
Documentsという名前のフォルダを作成し、その中にCompanyという名前のフォルダを作成するか?
それとも、Companyという名前のフォルダを作成してから、その中にDocumentsという名前のフォルダを作成するのか?
両方とも、うまくいくのです。しかし、どちらが正しいのでしょうか?
どちらがベストなのでしょうか?
カテゴリ階層の考え方は、より一般的な基底クラス(親)があり、派生クラス(子)はそれらのクラスのより特殊化されたバージョンであるということでした。そして継承チェーンをたどるにつれて、それはさらに特殊化されていきます。
(上記の形状階層を参照)
しかし、親と子が任意に場所を入れ替えることができるなら、このモデルでは明らかに何かが間違っています。
階層の問題のソリューション
何が間違っているのかというと…
カテゴリ階層は機能しません。
それでは、階層は何に適しているのでしょうか。
包含です。
現実の世界を見ると、包含(または排他的所有権)階層がいたるところに見られるでしょう。
あなたが見つけることができないのは、カテゴリ階層です。ちょっと深堀りしてみましょう。
オブジェクト指向パラダイムは、オブジェクトでいっぱいの、現実世界を前提としていました。
しかしすなわち、それは壊れたモデルを使います。
カテゴリ階層では実社会をモデル化できません。そのため、この壊れたモデルを使うことになるのです。
現実の世界は包含階層で満たされています。包含階層の良い例はあなたの靴下です。それはあなたの家の中に包含されたあなたの寝室に包含されたあなたのドレッサーの中の1つの引き出しに包含された靴下の引き出しの中にあるのです、等々。
ハードドライブ上のディレクトリは、包含階層の別の例です。ディレクトリはファイルを包含します。
では、私達はどのように分類をするのでしょうか?
まあ、Company Documentsについて考えるのであれば、私がそれらをどこに置くかはほとんど問題ではありません。私はそれらをDocumentsのフォルダ、またはStuffという名前のフォルダに置くことができます。
私がそれを分類する方法はタグを使うことです。ファイルに次のタグを付けます
Document
Company
Handbook
タグには順序や階層はありません。 (これはダイヤモンド問題も解決します。)
複数のタイプをドキュメントに関連付けることができるため、タグはインターフェイスに似ています。
でも、非常に多くのヒビが入って、継承の柱が倒れたように見えますね。
さようなら、継承。
カプセル化、倒れる第2の柱

一見すると、カプセル化はオブジェクト指向プログラミングの2番目に大きな利点のようです。
オブジェクト状態変数は外部からのアクセスから保護されています。つまり、それらはオブジェクト内にカプセル化されています。
正体不明の誰かによってアクセスされているグローバル変数について、私達が心配する必要はもうありません。
カプセル化はあなたの変数にとっての金庫です。
このカプセル化というものは素晴らしい!
カプセル化万歳…
それもあるできごとまで…
参照の問題
効率化のために、オブジェクトはそれらの値ではなく参照によって関数に渡されます。
つまり、関数はオブジェクトを渡すのではなく、代わりにオブジェクトへの参照またはポインタを渡すのです。
オブジェクトが参照によってオブジェクトコンストラクタに渡される場合、コンストラクタはそのオブジェクト参照をカプセル化によって保護されているプライベート変数内に置くことができます。
しかし、渡されたオブジェクトは安全ではありません!
何故なのか?他のコードの一部、つまりコンストラクタを呼び出したコードはオブジェクトへのポインタを有するからです。それはオブジェクトへの参照を有している必要があります。そうでなければコンストラクタに渡すことができませんでしたよね?
参照の問題のソリューション
コンストラクタは渡されたオブジェクトを複製する必要があります。そしてそれはシャローコピーではなく、ディープコピーである必要があり、つまり、渡されたオブジェクトに包含されるすべてのオブジェクト、およびそれらのオブジェクトに包含されるすべてのオブジェクト、および…。
これは効率的ではありませんね。
さらにここで発生する問題として、すべてのオブジェクトは複製できるわけではありません。オブジェクトにOSのリソースを持つオブジェクトが関連付けられている場合、複製ができません。
そして、すべての主流のオブジェクト指向言語にこの問題があります。
さようなら、カプセル化。
ポリモーフィズム、倒れる第3の柱

ポリモーフィズムは、オブジェクト指向三本柱の中でも嫌われ者でした。
それはいわばグループにおけるラリー・ファイン氏です。
どこへ行っても彼はそこにいましたが、彼は単なる脇役でした。
ポリモーフィズムが素晴らしくないというわけではなく、これを実現するためにオブジェクト指向言語は必要ではないということです。
オブジェクト指向の余計なものを全く使わずにインターフェースがこれをあなたに与えるでしょう。
インターフェースでは、異なる動作をいくつでも含むことができます。
そして、私達はオブジェクト指向ベースのポリモーフィズムにさよならして、インターフェースベースのポリモーフィズムを迎えるのです。
破られた約束

まあ、オブジェクト指向は、初期の頃、確かに多くのことを約束しました。そしてこれらの約束は、教室に座って、ブログを読み、オンラインコースを受講する、愚直なプログラマーに対していまだにされているものです。
オブジェクト指向が私に嘘をついていたことに気付くまでに何年もかかりました。
私もまた、天真爛漫で、経験が浅く、信じやすい人間でした。
そして私はやけどしたのです。
さようなら、オブジェクト指向プログラミング。
それで次は何?
ハロー、関数形プログラミング。ここ数年、あなたと一緒に仕事をするのはとても嬉しいことです。
ご存知のように、私はあなたの約束を額面どおりに受け取っていませんよ。
私はそれを信じるため、自分の目で見て確かめるつもりです。
一度やけどをすると用心深くなるのです。
分かるでしょう?
翻訳協力
Author: Charles Scalfani(https://medium.com/@cscalfani)
Thank you for letting us share your knowledge!
記事選定: @takitakis
翻訳/技術監査: eucom, @aoharu
Markdown化: @aoharu