こちらの記事は、『How to easily Detect Objects with Deep Learning on Raspberry Pi』の和訳になります。
免責事項: 著者は大量のデータとハードウェアなしでMLを構築するためのサービス nanonets.comを運営しています。
投稿の一番下にGithubリポジトリへのリンクがあります。
はじめに
一般的には、限られたデータで、スマートフォンやRaspberryPi等の低スペックマシン上で複雑なディープラーニングモデルを実行することは難しいと言われています。この記事ではRaspberryPiを使用し、物体検出を行う方法を説明します。

ムンバイの道路上での自動車の検出
なぜそのような動機に至ったのか
RaspberryPiは、1500万台ものデバイスが販売され、1時代を築いたすばらしいハードウェアです。 そして、ハッカー達はRaspberryPiをベースに更に素晴らしいプロジェクトを作り上げています。私たちはディープラーニングと RaspberryPiのカメラと組み合わせて、RaspberryPi上で物体検出が出来ないものだろうかと考えました。
もしそれが可能なら、下の画像のようにスマートフォンでも物体検出が出来る、という事を意味します。

物体検出とは?
人類の2000万年もの進化は人間の視覚をかなり進化させました。 人間の脳は 全ニューロンのうち触覚が8%、聴覚でわずか3%しか使っていないにも関わらず、視覚情報の処理には30 %ものニューロンを費やしています。人間は機械と比べて2つの大きな利点があります。 1つ目は立体視が出来ること、2つ目は現実世界から取得できる無尽蔵の訓練データです。(5歳の幼児は30fpsで約27億枚の画像をサンプリングしています。)

人間と同様のレベルのパフォーマンスを発揮するために、専門家は画像認識の問題を4つの異なるカテゴリに分類しました。
- クラス分類(Classification):画像ごとにラベルを割り当てる。
- 位置特定(Localization):クラス分類したラベルの物体が画像上のどこにあるか矩形位置で示 す。
- 物体検出(Object Detection):画像内の複数の物体に対してラベルと矩形位置を描画する。
- セグメンテーション(Image segmentation):物体検知した対象について輪郭を囲む領域を作成する
その中でも物体検出は、様々なアプリケーションで使用する事が出来ます。※ 画像セグメンテーションはより正確な結果を得られますが、訓練データの作成が複雑になるという問題があります。また、物体検出後にセグメンテーションすることも可能です。
物体検出の使い道
物体検出は重要性が高く非常に使い勝手が良いので様々な業界でのアプリケーションに使用されています。 以下にいくつかの例を示します。

物体検出はどのような問題を解決するか?
物体検出は、様々な問題の解決策と成り得ます。以下は、大まかなカテゴリーです。
- あるオブジェクトが自分の画像に入っているかどうか? 例) 侵入者の検知など
- 画像のどこに、探しているオブジェクトがあるか?例) 自動運転での障害物検知など
- 画像の中にいくつのオブジェクトがあるか? 物体検出は、オブジェクトの数を数えることを得意とします。例) 倉庫にある棚の中にいくつ箱があるか?
- 画像内に何種類のオブジェクトがあるか?例) 動物園のどの部分にどの動物がいるのか?
- オブジェクトの大きさはどのくらいなのか?特にカメラで写真を撮る場合、大きさを特定するのは簡単です。 例) 写真の中の果物の大きさなど
- 違うオブジェクト同士がどのように作用しているのか?例) サッカーの試合での選手のフォーメーションは、試合の結果にどう影響するのか。
- 時間の経過と共にオブジェクトの位置がどう変化しているか?(オブジェクトのトラッキング) 例)電車のような動いているオブジェクトのトラッキングとそのスピードの計算など
20行以下での物体検出のソースコード
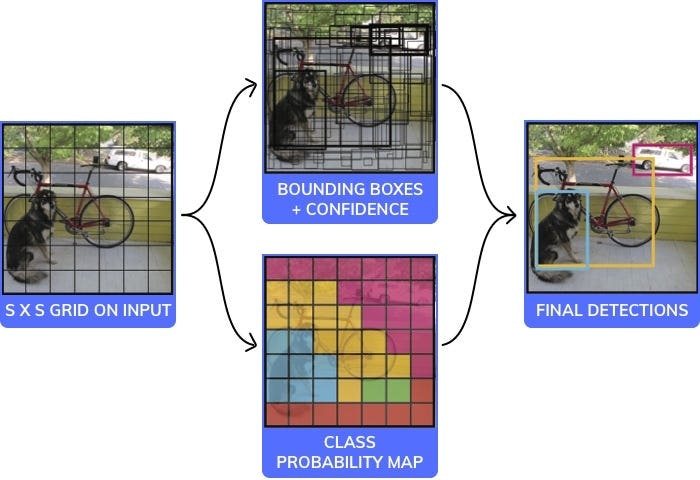
YOLOアルゴリズムの可視化
物体検出に使用される様々なモデルとアーキテクチャが存在します。それぞれが速度、サイズ、精度の要素においてメリット、デメリットがあります。私たちはその中から最も人気があるYOLOを選びましました: YOLOを使用し、どのように動作するかを20行以下のソースコード(コメントを無視した場合)で少しご紹介します。
注意:これはサンプルコードですので、実際に動くことを保証していません。このコードは下のイメージにある標準的なCNN部分がブラックボックスになっています。
こちらに全文が掲載されています。 https://pjreddie.com/media/files/papers/yolo_1.pdf
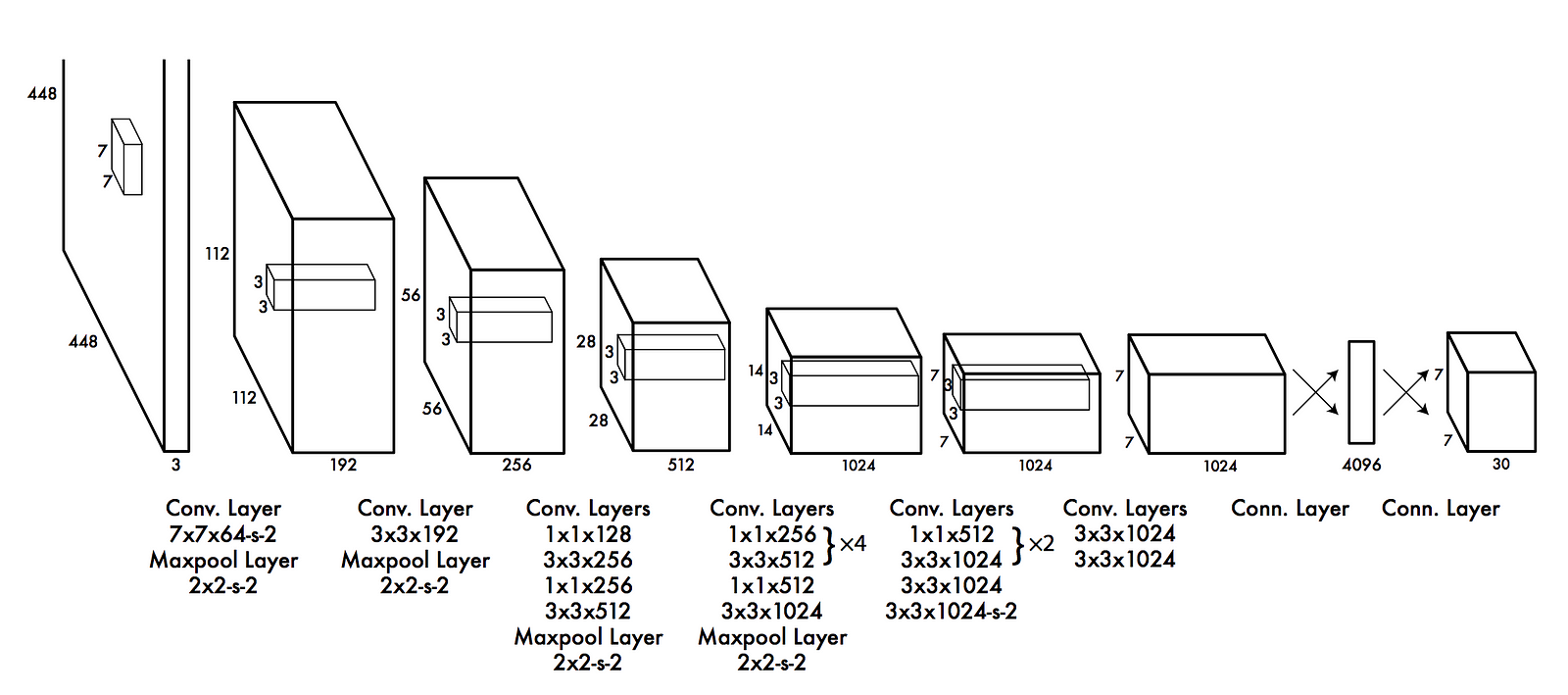
YOLOで使われる畳み込みニューラルネットワークのアーキテクチャ
# this is an Image of size 140x140. We will assume it to be black and white (ie only one channel, it would have been 140x140x3 for rgb)
image = readImage()
# We will break the Image into 7 coloumns and 7 rows and process each of the 49 different parts independently
NoOfCells = 7
# we will try and predict if an image is a dog, cat, cow or wolf. Therfore the number of classes is 4
NoOfClasses = 4
threshold = 0.7
# step will be the size of step to take when moving across the image. Since the image has 7 cells step will be 140/7 = 20
step = height(image)/NoOfCells
# stores the class for each of the 49 cells, each cell will have 4 values which correspond to the probability of a cell being 1 of the 4 classes
# prediction_class_array[i,j] is a vector of size 4 which would look like [0.5 #cat, 0.3 #dog, 0.1 #wolf, 0.2 #cow]
prediction_class_array = new_array(size(NoOfCells,NoOfCells,NoOfClasses))
# stores 2 bounding box suggestions for each of the 49 cells, each cell will have 2 bounding boxes, with each bounding box having x, y, w ,h and c predictions. (x,y) are the coordinates of the center of the box, (w,h) are it's height and width and c is it's confidence
predictions_bounding_box_array = new_array(size(NoOfCells,NoOfCells,NoOfCells,NoOfCells))
# it's a blank array in which we will add the final list of predictions
final_predictions = []
# minimum confidence level we require to make a prediction
threshold = 0.7
for (i<0; i<NoOfCells; i=i+1):
for (j<0; j<NoOfCells;j=j+1):
#we will get each "cell" of size 20x20, 140(image height)/7(no of rows)=20 (step) (size of each cell)"
#each cell will be of size (step, step)
YOLOで使われている20行以下のソースコードの説明
物体検出のためのディープラーニングモデル作成方法
ディープラーニングの流れとしては、重要な6ステップがあり、それを3つの部分に分けました。
- 訓練データの収集
- 学習済みモデルの作成
- 未知の画像に対する予測
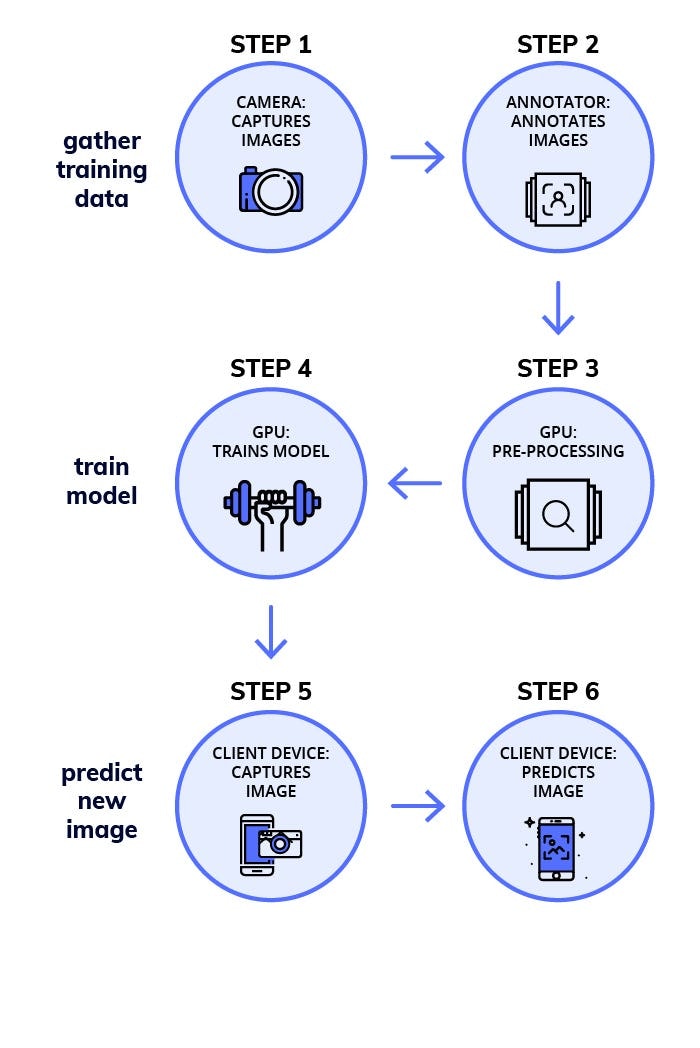
フェーズ1:訓練データの収集
ステップ1 画像の収集(少なくともオブジェクト当たり100枚)
この作業ではオブジェクトあたり2~300枚の画像が必要となります。物体検出をしようとしている対象のオブジェクトに出来るだけ近いデータを使用してください。

ステップ2 アノテーション(手作業で画像に矩形を描画する)
画像に矩形を描画します。LabelImgの様なツールを使っても良いです。この作業は集中力と時間が必要となりますので、2,3人に作業を手伝ってもらうのも良いかもしれません。

フェーズ2:GPUを使用して学習済みモデルを作成する
ステップ3 転移学習のために、事前に学習させたモデル(学習済みのモデル)を見つける
このリンクで詳細を確認できます。http://medium.com/nanonets/nanonets-how-to-use-deep-learning-when-you-have-limited-data-f68c0b512cab
事前に学習させたモデルが必要になります。学習済みモデルを作成するために10万枚程度の画像が必要となります。
ここのリンクで事前に学習させたモデルを見つけることができます。
ステップ4 GPUでのトレーニング(AWS/GCPなどのクラウドサービスや自分のGPUマシーン)
Dockerイメージ
モデルに学習させるプロセスは必要以上に難しいので学習が簡単にでき、プロセスがシンプルになるようにDockerイメージを作成しました。
モデルに学習をさせるには、以下を実行します。
sudo nvidia-docker run -p 8000:8000 -v「pwd」:data
docker.nanonets.com/pi_training -m train -a ssd_mobilenet_v1_coco -e ssd_mobilenet_v1_coco_0 -p '{"batch_size":8、 "learning_rate":0.003}'
詳細は、こちらのリンクを参照してください。
Dockerイメージ内のrun.shスクリプトを以下のパラメータで呼び出すことができます。
run.sh [-m mode] [-a architecture] [-h help] [-e experiment_id] [-c checkpoint] [-p hyperparameters]
-h display this help and exit
-m mode:mode: should be either `train` or `export`
-p key value pairs of hyperparameters as json string
-e experiment id. Used as path inside data folder to run current experiment
-c applicable when mode is export, used to specify checkpoint to use for export
さらに詳細の情報はこちらを参照してください。
NanoNets/RaspberryPi-ObjectDetection-TensorFlow
良いモデルを作るためには、正しいハイパーパラメータを選択する必要があります。
正しいパラメータを探す
ディープラーニングでは高い精度のモデルを作成するためにパラメータチューニングをする必要があります。ある理論に少し基づいたちょっとした裏技があります。これは適切なパラメータを探すのに大いに役に立ちます。
モデルの量子化(RaspberryPiの様な低スペックマシン、スマートフォンのためにファイルサイズを小さくする)
RaspberryPiやスマートフォンなどの小さいデバイスは、メモリが少なく処理速度もあまり早くはありません。
ニューラルネットワークの学習では各層の重みづけを微調整します。有効な結果を出すために浮動小数点精度を使用する必要があります。(この作業に量子化表現を使用するための研究があります)
学習済みモデルを作成することと、未知データを予測することは大きな違いがあります。ディープニューラルネットワーク(DNN)は入力に含まれる高レベルのノイズに非常によく対処できるため、両方うまくこなすことができます。
なぜ量子化するのか
ニューラルネットワークのモデルは、ディスク上で大量の容量を使用する可能性があります。例えば、オリジナルのAlexNetは浮動小数点形式で200 MBを超えています。1つのモデルに、何百万ものニューラルネットワークを構成するノードとノード間の重み付けが存在するので、容量のほとんど全てがその重みで占められてしまいます。
ニューラルネットワークのノードと重みは、もともと32ビットの浮動小数点数として格納されています。量子化を行う単純な理由は、各層の最小値と最大値を格納し、次に各浮動招集店の値を8ビット整数に圧縮することによってファイルサイズを縮小することです。ファイルのサイズは75%減少します。
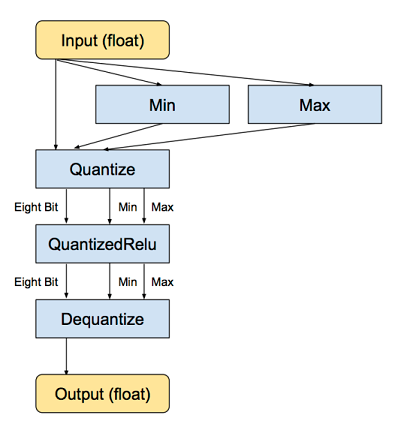
量子化のためのソースコード
curl -L "https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz" |
tar -C tensorflow/examples/label_image/data -xz
bazel build tensorflow/tools/graph_transforms:transform_graph
bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=tensorflow/examples/label_image/data/inception_v3_2016_08_28_frozen.pb \
--out_graph=/tmp/quantized_graph.pb \
--inputs=input \
--outputs=InceptionV3/Predictions/Reshape_1 \
--transforms='add_default_attributes strip_unused_nodes(type=float, shape="1,299,299,3")
remove_nodes(op=Identity, op=CheckNumerics) fold_constants(ignore_errors=true)
fold_batch_norms fold_old_batch_norms quantize_weights quantize_nodes
strip_unused_nodes sort_by_execution_order
注:dockerイメージには量子化が組み込まれています。
フェーズ3:RaspberryPiを使った新しい画像の予測
ステップ5 カメラで新しい画像をキャプチャーする。
RaspberryPiでカメラを動かす必要があります。そして新しい画像をキャプチャーします。

RaspberryPiでカメラを使用する方法については、こちらのリンクを参照してください。
import picamera, os
from PIL import Image, ImageDraw
camera = picamera.PiCamera()
camera.capture('image1.jpg')
os.system("xdg-open image1.jpg")
新しい画像をキャプチャするためのコード
ステップ6 新しい画像を予測する
モデルのダウンロード
モデルのトレーニングが終了したらRaspberryPiにダウンロードします。モデルをエクスポートするには、以下を実行してください。
sudo nvidia-docker run -v `pwd`:data
docker.nanonets.com/pi_training -m export -a
ssd_mobilenet_v1_coco -e ssd_mobilenet_v1_coco_0 -c /data/0/model.ckpt-8998
それからRaspberryPiにモデルをダウンロードしてください。
RaspberryPiにTensorFlowをインストール
RaspberryPiのバージョンによってインストール方法が少し異なるかもしれません
sudo apt-get install libblas-dev liblapack-dev python-dev libatlas-base-dev gfortran python-setuptools libjpeg-dev
sudo pip install Pillow
sudo pip install http://ci.tensorflow.org/view/Nightly/job/nightly-pi-zero/lastSuccessfulBuild/artifact/output-artifacts/tensorflow-1.4.0-cp27-none-any.whl
git clone https://github.com/tensorflow/models.git
sudo apt-get install -y protobuf-compiler
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
export PYTHONPATH=$PYTHONPATH:/home/pi/models/research:/home/pi/models/research/slim
モデルを使用して新しい画像を予測
python ObjectDetectionPredict.py --model data/0/quantized_graph.pb --labels data/label_map.pbtxt --images /data/image1.jpg /data/image2.jpg
RaspberryPiのパフォーマンスベンチマーク
RaspberryPiはメモリ量と処理能力の両方に対して制約があります(RaspberryPiの GPUに対して互換性のあるTensorFlowのバージョンはまだリリースされていません。)ですので各モデルが新しい画像を予測するのにかかる時間をベンチマークすることが重要です。
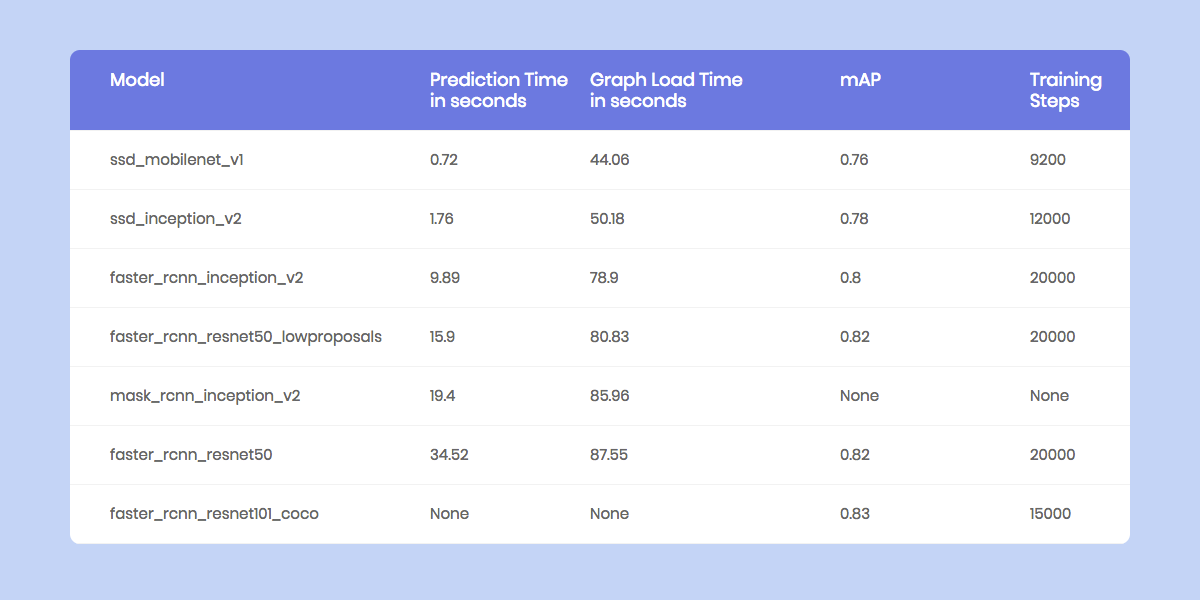
RaspberryPiで実行されている様々な物体検出モデルのベンチマーク
NanoNetsを使ったワークフロー:
NanoNetsは、ディープラーニングを簡単に使うことが出来ることを目指しています。
主に開発、研究している分野は物体検出で、ディープラーニングモデルを実装する上で生じる多くの問題を解決するワークフローを作成しました。
NanoNetsを使用するとどの位ディープラーニングが簡単にできるか
1.アノテーションは不必要
画像にアノテーションを行う必要を削除しました。皆さんのチームには、アノテーションを専門に行う人がいるかと思いますが 必要が無くなります。
2.最良モデルの自動選択とハイパーパラメータの選択
NanoNetsは、 自動であなたにとって最良のモデルを学習します。そのためには、あなたのデータにとって一番良い様々な種類のパラメータで一連の関係モデルを実行ます。
3.値段の高いハードウェアやGPUは不要
NanoNetsは完全にクラウド化されており 、ハードウェアを一切使用せずに動作し、容易に使用できます。
4.RaspberryPiのようなモバイル機器に最適
RaspberryPiやスマートフォンのようなデバイスは複雑な計算負荷の高いタスクを実行するようには設計されていないため、ワークロードを当社のクラウドに外部委託することができます。
これはNanoNets APIを使って画像を予測する簡単なイメージの一部です
import picamera, json, requests, os, random
from time import sleep
from PIL import Image, ImageDraw
# capture an image
camera = picamera.PiCamera()
camera.capture('image1.jpg')
print('caputred image')
# make a prediction on the image
url = 'https://app.nanonets.com/api/v2/ObjectDetection/LabelFile/'
data = {'file': open('image1.jpg', 'rb'), \
'modelId': ('', 'YOUR_MODEL_ID')}
response = requests.post(url, auth=requests.auth.HTTPBasicAuth('YOUR_API_KEY', ''), files=data)
print(response.text)
# draw boxes on the image
response = json.loads(response.text)
im = Image.open("image1.jpg")
draw = ImageDraw.Draw(im, mode="RGBA")
prediction = response["result"][0]["prediction"]
for i in prediction:
draw.rectangle((i["xmin"],i["ymin"], i["xmax"],i["ymax"]), fill=(random.randint(1, 255),random.randint(1, 255),random.randint(1, 255),127))
im.save("image2.jpg")
os.system("xdg-open image2.jpg")
NanoNetsを使って新しい画像を予測するためのコード
独自のNanoNetを構築する
独自のモデルを作って行うことができます
1.GUIを使用する(画像にも自動でアノテーションを付けます):
https://nanonets.com/objectdetection/
2.当社のAPIを使用する:
https://github.com/NanoNets/object-detection-sample-python
ステップ1:リポジトリからソースコードを入手する
git clone https://github.com/NanoNets/object-detection-sample-python.git
cd object-detection-sample-pytho
sudo pip install requests
ステップ2:無料のAPIキーを入手する
http://app.nanonets.com/user/api_key から無料のAPIキーを入手してください。
ステップ3:APIキーを環境変数として設定
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
ステップ4:新しいモデルを作成する
python ./code/create-model.py
注:これにより、次のステップで必要なMODEL_IDが生成されます。
ステップ5:環境変数としてモデルIDを追加する
export NANONETS_MODEL_ID=YOUR_MODEL_ID
ステップ6:訓練データをアップロードする
あなたが検出したいオブジェクトの画像を集めてください。私達のウェブUI(https://app.nanonets.com/ObjectAnnotation/?appId=YOUR_MODEL_ID )を使用するか、labelImgのようなオープンソースツールを使うことでアノテーションを付けることができます。フォルダ、 画像ファイル、およびアノテーション(画像ファイルのアノテーション)でデータセットを準備したら、データセットのアップロードを行います。
python ./code/upload-training.py
ステップ7:学習済みモデルを作成する
画像がアップロードされたら、モデルのトレーニングを開始します
python ./code/train-model.py
ステップ8:モデルのステータスを取得する
学習するために約2時間程度かかります。モデルの学習が終了するとあなたは電子メールをが届きます。モデルの学習中にモデルの状態をチェック出来ます。
watch -n 100 python ./code/model-state.py
ステップ9:予測を行う
モデルの学習が終了したら後、モデルを使って予測を行うことができます
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
コード(Github リポジトリ)
モデルを学習するためのソースコード(Githubリポジトリ):
1.モデル学習と量子化のためのTensorFlowコード
2.モデルトレーニング用NanoNetsコード
RaspberryPiで新しい画像の予測を行うためのソースコード(Githubリポジトリ):
1.RaspberryPiの予測を行うためのTensorFlowのコード
2.RaspberryPiの予測を行うためのNanoNetsコード
アノテーション付きのデータセット:
1.インドの道路で見える車、データセット用にインドの道路の画像から抽出された乗り物
2.COCOデータセット
謝辞:Prathamesh A Juvatkar 、Apoorva Mudgal、 Aatish Patel
記事選定: @takitakis
翻訳/技術監査: @HaraShun
記事作成: @azumana