こちらの記事は、Cassie Kozyrkov 氏により2018年 8月に公開された『 What on earth is data science? 』の和訳です。
本記事は原著者から許可を得た上で記事を公開しています。
最も端的に表してみたのがこちらです。「データサイエンスとはデータに価値をもたらすための学問である」
もうここで読むのを止めてもらっても構いません。まだお付き合いいただけるなら、データサイエンスに属する3つの分野について見ていきましょう。
誰も本当には定義したことがない用語
データサイエンスという用語の初期の歴史を詳しく調べてみると、2つのテーマが合わさっているとわかります。
その2つを楽しい感じに言い換えるとこうなります
- ビッグデータとはコンピュータでさらにこねくり回すこと。
- 統計学の専門家たちはあまりコーディングができない。
こうして、データサイエンスは誕生しました。
私が初めて聞いた、職業としての定義は「データサイエンティストとはコーディングができる統計学の専門家である」でした。
この話になると、私はすぐに様々なことを言いたくなってしまいますが、まずはデータサイエンスそのものを見ていきましょう。

2014年頃のTwitter上での定義
データサイエンティストとはサンフランシスコに住んでる統計学の専門家のこと。
データサイエンスとはMacでやる統計学のこと。
データサイエンティストとはどのソフトウェアエンジニアよりも統計学が得意で、どの統計学の専門家よりもソフトウェアエンジニアリングが得意な人のこと。
私は2003年に発売開始した「Journal of Data Science」誌が正確にスコープを絞り込もうとしたやり方が好きです
「データサイエンス」によるデータに関係するほとんど全てのものを意味します。
ええと...全て?情報と関係ないことを考えるほうが難しいと思うのだけれども。(これについて頭が爆発する前に私は考えるのを止めたほうがいいでしょう)
それ以来、よく見かけるConwayのベン図(下)からMasonとWigginsの有名な記事まで、多くの意見を見てきました。
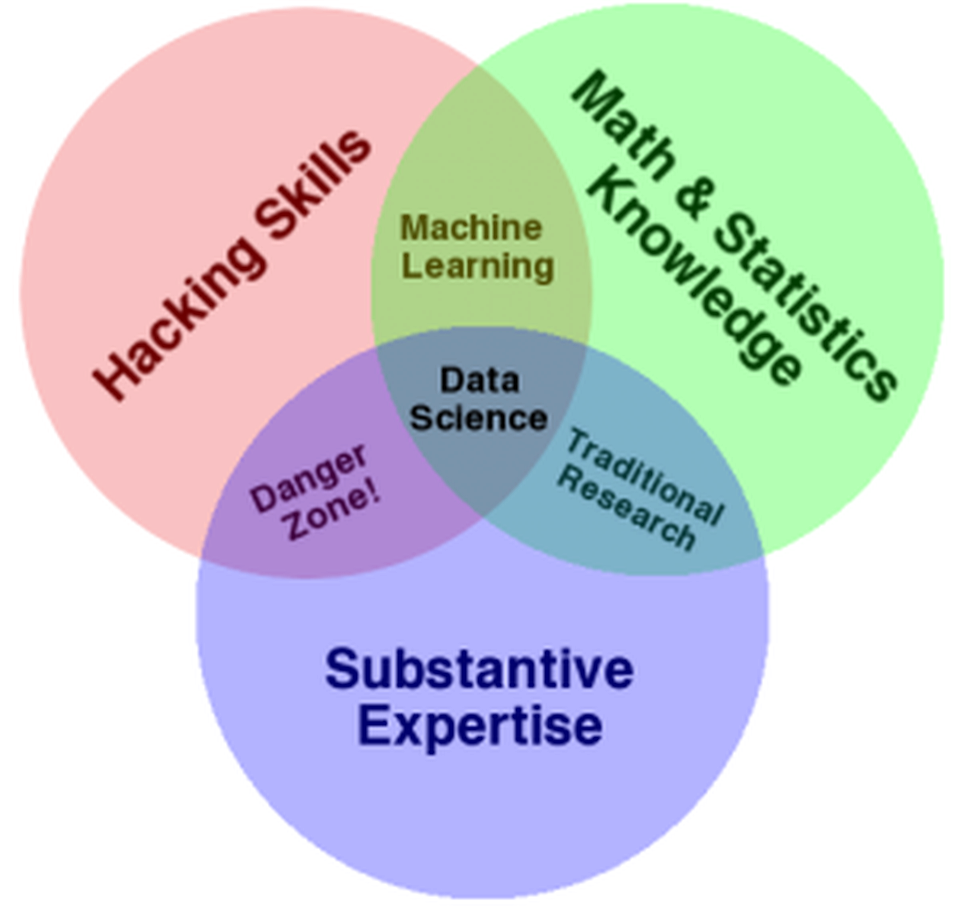
Drew Conwayによるデータサイエンスの定義。ウィキペディアの定義のほうが私の個人的な好みに近い。
ウィキペディアの定義が、私が生徒に教えている定義と非常に近いです
データサイエンスとは、データに基づいて「実際の現象を理解および分析」するための「統計学、データ分析、機械学習、およびそれらに関連する方法を統合する概念」である。
ちょっと長いので、簡潔でかつ魅力的な言葉に直してみます
「データサイエンスとはデータに価値をもたらすための学問である」
いまのあなたの頭の中にはこんなことが浮かんでいるでしょう:「惜しいね、キャシー。かっこいいとは思うけど、省きすぎ。『価値をもたらす』って言葉だけで、この専門領域全てを表せると思ってるの?」
オッケー。じゃあ図を見ながら考えましょう。

ウィキペディアの定義に完璧に忠実な、データサイエンスの図解を用意しました。
これは何でしょう?そして、どのようにしてこの図における自分の立ち位置がわかるのでしょうか?
この3分野を一般的な手法で分けようとしたあなた、一旦落ち着いて。
統計学の専門家と機械学習エンジニアの違いは、一方がRを使用し、もう一方がPythonを使用するということではありません。
SQL vs R vs Pythonで分類するのは、非常に多くの理由で賢明ではありません。特にソフトウェアというのは発展していくものなので。(最近では、SQLで機械学習することさえできます。)
最後まで掘り下げなくてもいいですか?それならば先に進んでしまって、この節は読まなくて大丈夫です。
おそらくさらに良くないのが、初学者が好んでやりがちな分類です。
うん、あなたが思っている通り。アルゴリズムで分類する方法です(びっくりですよね!それって大学の授業の分け方ですよ)。
お願いだから、ヒストグラム vs t検定 vs ニューラルネットワークで分類したりしないでくださいね。
正直に言って、賢くて要領を得てる人なら、データサイエンスのどの領域でも同じアルゴリズムを使うことができます。
それはまるでフランケンシュタインみたいですが、自分の意のままに操れるはずです。
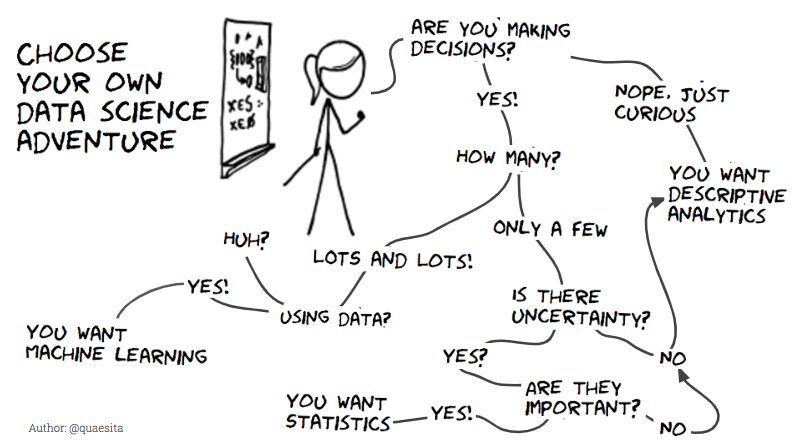
ドラマチックな準備はもう十分です!私が提案する分類方法はこちらです。

無 - 1つ - 多数
これは一体なんでしょう?
もちろん、意思決定のことです。(不完全な情報の下での話です。もし必要なすべての事実が見えているなら、好きなだけ多くの意志決定をするために記述的アナリティクスを使えばいいです。ただ事実を見つめさえすれば十分です。)
我々の世界に影響を与えるのは、行動、つまり意思決定である。
私は先ほどデータに価値をもたらすということについて話すと約束しました。
私にとって、価値というのは現実世界の行動に影響を与えることと密接に結びついています。
仮に私がサンタクロースを信じているとして、それは私の行動に何かしら影響を与えない限り、特に重要なことではありません。
そして、その行動がもたらしうる潜在的な結果によっては、とても重要になり始めるかもしれません。
我々の世界に影響を与えるのは、行動、つまり意思決定です(そして、逆に世界が我々に影響を与えるようにします)。
そこで、データに価値をもたらす3つの主要な方法を備えた、意思決定という観点で見たときのの新しい図を紹介します。

データマイニング/分析
どういった決定をしたいのかまだわからない場合は、インスピレーションを求めて現場に行ってみるのがベストです。
その行動はデータマイニングやアナリティクス、記述的アナリティクス、探索的データ解析(EDA)、知識発見(KD)と呼ばれたり、時代によって呼び方は変わります。
アナリティクスの黄金則:自分が見えるものだけに対して結論を下せ
意思決定をどう組み立てて行くか決まってないならば、ここから始めましょう。
嬉しいことに、これは簡単です。
データセットを、暗室にあるたくさんのネガだと思ってみましょう。
データマイニングとは、面白いものがないか確かめるために、機材を使ってなるだけ速くすべてのネガを現像するようなものです。
写真と同じように、見えるものをそこまで深刻に捉えなくていいということを忘れないでください。
あなたが写真を取ったわけではないので、写真に写っていないことはあまりわからないのです。
データマイニングの黄金則は、目の前のことだけに取り組むことです。見ることができるものに対してだけ結論を下し、見えないことに対しては結論は下してはいけません(このためには統計学や多くの専門知識を必要とします)。
それを除けば、何をしてもいいです。速さが正義なので、訓練を積みましょう。
データマイニングの専門性はデータを調査する速さで評価されます。
興味深い貴重な情報を見逃さずに済むのです。
初め、暗室は怖いですが、大したことはありません。
機材の使い方を学ぶだけです。
RのチュートリアルとPythonのチュートリアルがあるので御覧ください。
楽しく感じ始めたら自分のことをデータアナリストと称して良いし、高速で写真(他のあらゆるデータセットも)を現像できるようになればエキスパートアナリストと称して良いです。
統計的推論
インスピレーションは安い一方、厳密さは値が張ります。
データのその一歩先に行きたければ、専門的なトレーニングが必要になります。
統計学を学部と大学院で専攻した者として、少し偏見があるかもしれませんが、統計的推論(略して統計学)は3つの分野の中で最も難しく、とても哲学的です。
慣れるのに最も時間がかかります。
インスピレーションは安い一方、厳密さは値が張ります
利用可能なデータを超えて、この世界に関する結論に基づいた高品質でリスク管理された重要な決定を行う場合、統計学のスキルを自分のチームに取り入れる必要があります。
良い例として、AIシステムの起動ボタンの上に自分の指があるときに、そのシステムをリリースする前に動作を確認する必要があるということです(真面目な話、これはいつも良い考えです)。一旦ボタンから離れて、統計学の専門家を呼びましょう。
統計学は(不確実性の下で)考えを変える科学です。
さらに詳しく知りたい場合は、8分間で分かる統計学まとめを書きましたので、楽しんでもらえると思います。
機械学習
機械学習とは、基本的に、命令ではなく例を用意して、物をラベル付けするためのレシピを作ることです。
私は機械学習についていくつか投稿していまして、機械学習とAIは異なるかどうか、機械学習を始める方法、機械学習ビジネスが失敗する理由といったものがあります。そして、最初の2、3の記事は専門用語で書かれた本質を平易な言葉で書いています。(こちらから始めてください)
おっと、その投稿を英語を話さない友人と共有したい場合は、ここに翻訳したものがまとまってます。
データサイエンス vs 「データサイエンティスト」
様々多くの方がデータに価値をもたらす仕事に従事しています(データサイエンスプロジェクトのトップ10の役割に関する私の調査ここにあるのでチェックしてください)
様々な役割の人がデータサイエンスに関わっている一方で、そうした人々が全てデータサイエンティストだとは思いません。
これはややこしい話なのです。
私の見解では、データサイエンティストとは3つの領域すべて(分析、統計学、およびML / AI)の専門知識を持つ人物です。
私はデータサイエンティストの役職についての私の意見だけが正しいわけではないと分かっているので、別の記事の中で、公正に他の見解も取り上げ、データサイエンス労働市場においてどういった意味を持つのか考えてみました。

データエンジニアリング
最初にデータサイエンスチームにデータを提供する仕事であるデータエンジニアリングについてはどうでしょうか?
洗練された独立した分野であるため、データサイエンス固有の独占欲から守りたいと思っています。
それに、分野的には統計学よりもソフトウェアエンジニアリングにずっと近いです。
データエンジニアリングとデータサイエンスの違いは、前と後の違いです。
データエンジニアリングとデータサイエンスの違いを、前と後の違いだと考えてしまって大丈夫です。
データができるまで(前)に至るまでの技術的作業の大部分は、「データエンジニアリング」と呼んでしまってよく、データが届いた後(後)に行うすべての作業は「データサイエンス」です。
意思決定インテリジェンス(Decision intelligence)
意思決定インテリジェンス(DI)は、データを使用した大規模な意思決定を含む、意思決定に関するすべてのことであるため、エンジニアリングの分野になります。
これは、社会科学および経営科学からのアイデアを用いた、データサイエンスの応用的な側面を論じています。
意思決定インテリジェンスでは、社会科学および経営科学の要素をつけ加えます。
言い換えれば、様々なデータサイエンスの要素の上位集合であり、汎用的な使用のための基本的な方法論の作成のような研究的な事項とは関係しません。
まだ物足りないですか?私はキーボードを打っているけど、ここにデータサイエンスプロジェクトでの役割の、面白いまとめがあります。
翻訳協力
Original Author: Cassie Kozyrkov
Thank you for letting us share your knowledge!
この記事は以下の方々のご協力により公開する事が出来ました。
改めて感謝致します。
選定担当: yumika tomita
翻訳担当: @satosansato3
監査担当: @nyorochan
公開担当: asuma yamada
ご意見・ご感想をお待ちしております
今回の記事は、いかがだったでしょうか?
・こうしたら良かった、もっとこうして欲しい、こうした方が良いのではないか
・こういったところが良かった
などなど、率直なご意見を募集しております。
いただいたお声は、今後の記事の質向上に役立たせていただきますので、お気軽にコメント欄にてご投稿ください。
みなさまのメッセージをお待ちしております。