CyberAgent Developers Advent Calendar 2018の12日目の投稿となります。
前日はmarty-suzukiさんの「バンクシーのシュレッダーを1時間で実装して申請した話とその後」でした。
12日目は、AI Lab の接客対話グループの馬場(@baba5246)が担当します。
この研究グループでは、接客ロボットの研究開発を進めていますが、ロボットの認識能力を高めるために、ロボットに付属しているセンサーだけでなく、外部カメラ・センサーを設置して周辺状況の認識をしています。

その周辺状況のひとつである「周りの人の状況」を認識するための、Pose Estimation(骨格検出)について既存手法を紹介しながら、実際にいくつかの画像でどう動くかを調べていきたいと思います。
Pose Estimation (骨格検出)とは
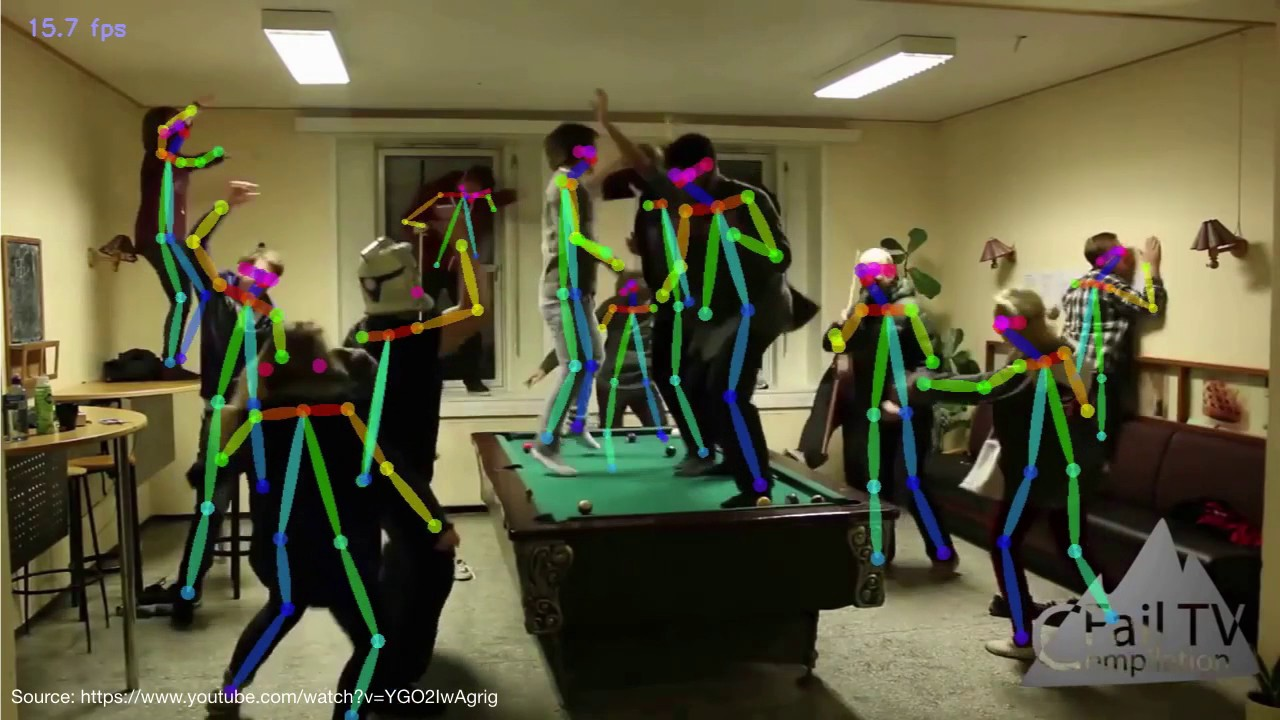
(OpenPose 紹介動画から引用)
Pose Estimation は画像から人の骨格(身体部位とその繋がり)を検出するタスクで、深層学習による画像処理タスクの精度向上のおかげで、近年、飛躍的にその精度が上がってきています。Pose Estimation の手法にも様々なものがあり、2D画像内での骨格の座標を特定するものや、2D画像から骨格の3D座標を推定するもの、また、複数人に対応しているものやリアルタイム処理を売りにしているものまで、多種多様な手法が提案されています。
今回は2D画像内での骨格検出手法の中でも、独断と偏見で有名どころをピックアップしてご紹介します。
手法1:OpenPose
 ["Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields", Z. Cao, et al., CVPR 2017](http://openaccess.thecvf.com/content_cvpr_2017/papers/Cao_Realtime_Multi-Person_2D_CVPR_2017_paper.pdf)
["Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields", Z. Cao, et al., CVPR 2017](http://openaccess.thecvf.com/content_cvpr_2017/papers/Cao_Realtime_Multi-Person_2D_CVPR_2017_paper.pdf)
ここ数年でみると、一般に最も広く利用されている Pose 推定手法です。それまで主流だった、人全体の範囲を検知してからその内部の関節パーツを推定するトップダウンのアプローチではなく、先に関節部位を推定してそれらを繋げるボトムアップな方法をとりながら、当時のコンペ(2016 MSCOCO Keypoint Challenge)で優勝するほどの精度を叩き出しました。
非商用で使う分には無料でライブラリを公開しており、簡単に試すことができるのも素晴らしいですね。
特徴は、部位同士や複数人が重なり合っていてもそれらを正確に分離できる点と、それを非常に高速にリアルタイムで処理できる点です。使ってみるとわかりますが、非常に頑健で、少々画素が荒くとも画像がとぎれていようとも正確に検出することができます。

(OpenPose 論文から引用)
この手法のキーアイデアは「Part Affinity Fields」という部位間のベクトルの学習にあります。部位と部位の間にあたる画素すべてに下図のようなベクトルを教師として付与し、それを学習しています。$L^{*}_{c,k}(p)$ はピクセル $p$ につけるべき教師ベクトルで、人 $k$ の肢 $c$ 上にあるピクセル $p$ では、ベクトル $v$ を教師として付与します。なんという力技… ![]()
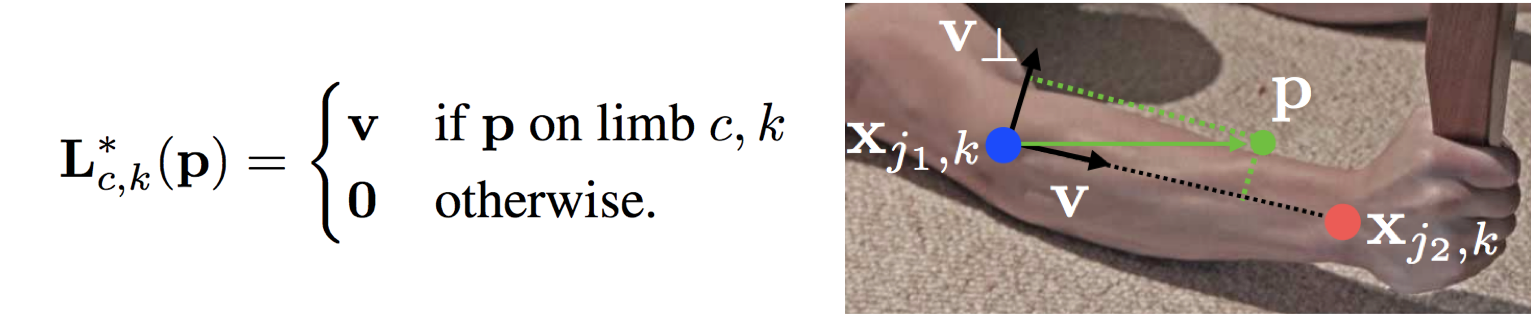
しかし、そのおかげで部位間のベクトルを推定でき、ある部位に繋げられる他の部位が複数あっても、そのベクトルによって正確に繋がるべき部位のペアを見つけ出すことができます。この教師データは非常に貴重で作成に手間がかかるので、独自にデータセットを作るのが困難で、商用利用を$25,000に設定するのもうなずけます。
実装も、各深層学習ライブラリ用にいくつも展開されていて、ひとまず試しに入れてみることが簡単にできるので、気が向いた方は以下からお試しください。
- 本家:https://github.com/CMU-Perceptual-Computing-Lab/openpose
- TensorFlow:https://github.com/ildoonet/tf-pose-estimation
- Keras:https://github.com/michalfaber/keras_Realtime_Multi-Person_Pose_Estimation
- Swift:https://github.com/infocom-tpo/SwiftOpenPose
手法2:PoseNet
 ["PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model", G. Papandreou, et al., ECCV 2018](https://arxiv.org/pdf/1803.08225.pdf)
["PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model", G. Papandreou, et al., ECCV 2018](https://arxiv.org/pdf/1803.08225.pdf)
もう一つここでご紹介するのは Google から発表された PoseNet です。PoseNet も OpenPose と同様、ボトムアップアプローチな手法ですが、特徴としては Web ブラウザでも動作するよう作られています。時代と逆行して Python 実装をしないあたりにこだわりを感じますが、こちらから非常に簡単にデモを試すことができます。
こちらの手法も部位間のベクトルを利用する点で、発想は OpenPose に似ていますが、OpenPose のような強力な教師データを使わずに、OpenPose よりも高い精度を出しています。下図のように、部位のヒートマップを推定するのと同時に、部位周辺画素から部位への小さなベクトル(図中の"Short-range offsets")と、部位間の大きなベクトル(図中の "Mid-range offsets")を学習しています。
 ([PoseNet 論文](https://arxiv.org/pdf/1803.08225.pdf)より引用)
([PoseNet 論文](https://arxiv.org/pdf/1803.08225.pdf)より引用)
この小さなベクトルがいい役割をしていて、推定する部位のピクセル座標をより正確にするために使われる一方で、部位間のベクトルを正確につなげることにも使われます。これにより、強力な教師ベクトルがなくとも、正確に骨格を検出できるようです。
ただ、OpenPose より少し面倒な点として、検出できる最大人数を設定しないといけません。この最大人数分、検出しようとするアルゴリズムなため、3人しか写っていないのに6人分(重複している)の Pose が返ってきたりします。まあ、ある程度はルールで重複を取り除けるので、なんとかなります。
実は、PoseNet ではセグメンテーション(領域分割)を行うことも含まれていて、その部分に興味ある方はぜひ論文をご参照ください。
いろんなポーズを推定してみた
※ 時間の関係で、いったん OpenPose の結果を載せています。時間があれば、poseNetの結果も追記します。
※ 今回はデフォルトのパラメータで利用しています。パラメータチューニングや実装ライブラリの変更などをすれば結果は変わるので、参考程度にご覧ください。
※ 画像はぱくたそさんから拝借してます。
正面、横、後ろ



いずれも問題なく推定できていますね。
特に最後の画像は、実際に耳が写っていないのに耳を推定できています。
切れてる、逆さ、真横



いずれもうまく検出できず。。
とくに逆さや真横のような画像は学習データに含まれてなさそうので、それらを含めて再学習をすれば結果が変わりそうです。
いろんな体勢

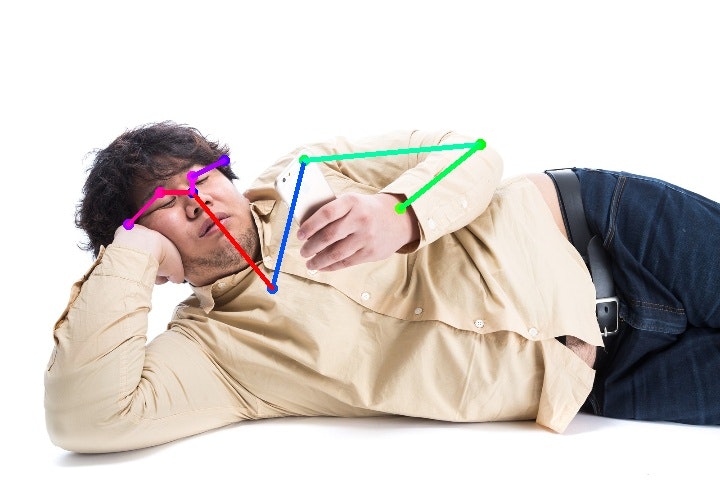

休日のお父さんポーズはなんとか善戦しています。
が、やはり寝そべると難しさが増す感じ。
ロボットと2次元


(https://shingeki.tv/season3/ より引用)

(https://anime.granbluefantasy.jp/ より引用)
より人間に近い方のロボット(CommU)は骨格をきれいにとれています。
また、進撃の巨人も善戦しているように見えますね。画風によってはチューニングなしできれいにとれそう。
ゴリラとチンパンジー


いくらDNAが近いからって見た目が遠ければ無理でしたね。。
おわりに
今回利用した画像は、被写体が大きかったり陰影をつけていたりそもそも学習データとかけ離れていたりと、非常に学習モデル側に不利な画像が多かったのですが、それでもきれいに骨格を出せていて面白かったですね。時間があれば、PoseNetや他の手法も追記していこうと思います。
おわり。