Dify を使えば 高性能 AIモデル の チャットボット を簡単に作成できます。
ただ、AI モデル の学習は「公開された情報」を元にしており、いわゆる「非公開の情報」を回答することは不可能です。
それどころか、誤った情報を もっともらしく 提示してくる恐れもあります。
これを解決するのが「RAG(Retrieval-Augmented Generation)」と呼ばれる技術です。
RAG(Retrieval-Augmented Generation)
質問に関連する情報を「知識ベース(外部のデータベースなど)」から検索して回答文を作成する技術のことを「RAG(Retrieval-Augmented Generation)」と呼びます。
この「検索」は単なるキーワード検索ではありません。
情報は「ベクトルデータ(文章の意味や特徴を数値化した値)」形式で保存されており、質問との「類似度」が高いものを取り出して使用します。
情報のベクトル化
情報を検索しやすい形に「数値化」することを「ベクトル化」と言います。
ベクトル化により、質問との類似度が高い情報を迅速に見つけることが可能となります。
Dify で ベクトル化 できる情報は次のとおりです。
- テキストファイル:
.txt - Markdownファイル:
.md - PDFファイル:
.pdf - HTMLファイル:
.html - Excelファイル:
.xlsx,.xls - Wordファイル:
.docx - CSVファイル:
.csv
など
埋め込みモデル
文章や単語の意味を数値ベクトルとして表現する AIモデル のことを「埋め込みモデル」と言います。
通常、高性能モデルの方が より正確なベクトル化 が可能です。
| モデル名 | 料金 (1000トークンあたり) |
性能 (平均スコア) |
|---|---|---|
| text-embedding-3-large | $0.00013 | 54.9% |
| text-embedding-3-small | $0.00002 | 44.0% |
| text-embedding-ada-002 | $0.00010 | 31.4% |
上表は、OpenAI が提供する「埋め込みモデル」の料金と 多言語検索ベンチマーク(MIRACL)の平均スコア を示したものです。
small は 前世代の ada から 12.6% ほど性能が向上したにも関わらず、料金は ada の $\frac{1}{5}$ にまで抑えられています。
一方、large の性能は 54.9% まで向上していますが、その分 料金も small の約7倍にまで跳ね上がっています。
そこそこ の性能で良ければ、コストパフォーマンスの良い text-embedding-3-small を選択すれば良いと思います。
埋め込みモデル は「ナレッジベースへの問い合わせ」の度に呼び出されます。
問い合わせ回数 あるいは 問い合わせ時のトークン数 が少なければ、large を選択しても良いと思います。
チャンク
ナレッジへ登録する情報は「意味のある小さな塊(チャンク)」に分割されます。
全文検索する場合に比べて「必要な情報だけを効率的に検索」できるため、余計な情報を含まない正確な回答を作成することが可能となります。
ナレッジへ情報ファイルを登録する際、Dify は情報ファイルの内容を自動的にチャンクへ分割します。
分割するサイズを変更することもできますが、不用意に変更すると回答精度の低下を招きます。
分割するサイズが小さすぎるとき
文脈を理解できず、情報をうまく活用できないことがあります。
分割するサイズが大きすぎるとき
余計な情報が含まれることになり、検索効率が低下します。
「空のナレッジベース」の作成
ここからは実際にナレッジベースを構築していきます。
Dify では複数のナレッジベースを作成可能で、各ナレッジベースには複数のドキュメントを登録することができます。
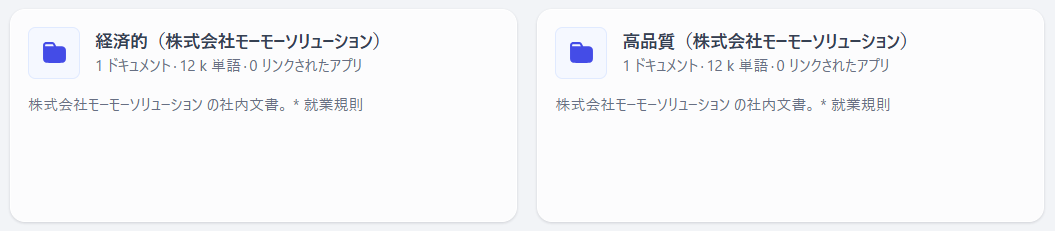
本記事では 二種類のナレッジベース を作成していきます。
-
経済的ナレッジベース
埋め込みモデルを使用せず、キーワードで関連情報を検索する。
外部のAPIを呼び出さないので費用を抑えられる反面、情報の検索精度は低い。
-
高品質ナレッジベース (Dify の推奨方式)
埋め込みモデルが変換したベクトルデータを用いて、関連する情報を検索する。
多少 費用は生じるものの、特別な理由が無い限り「高品質ナレッジベース」を利用すべきでしょう。
① 空のナレッジベースを作成
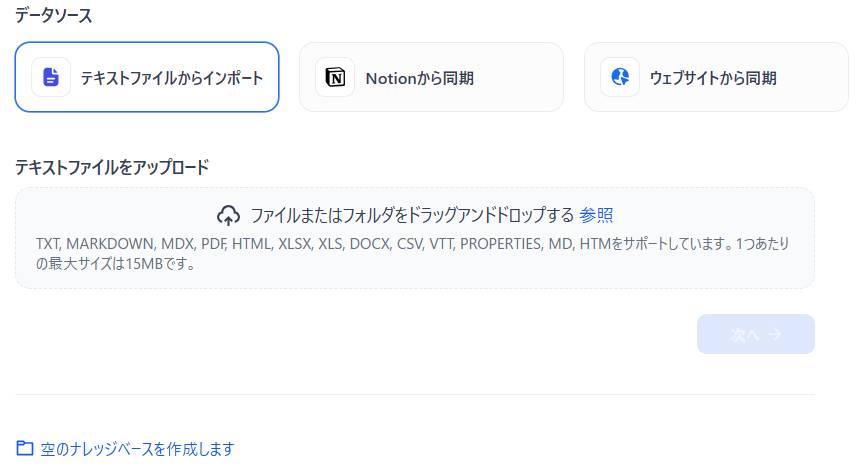
ナレッジベースの作成画面の下に、小さく「空のナレッジベースを作成します」と表示されています。
これをクリックして「空のナレッジベース」を二つ作成してください。
② ナレッジへアクセスする権限を設定
それぞれのナレッジ画面から「設定」画面を開き、「ナレッジへアクセス可能なユーザー」を設定します。
左側メニューの「設定」をクリックしてください。
設定する内容は下表のとおりです。
| 項目 | 設定内容 |
|---|---|
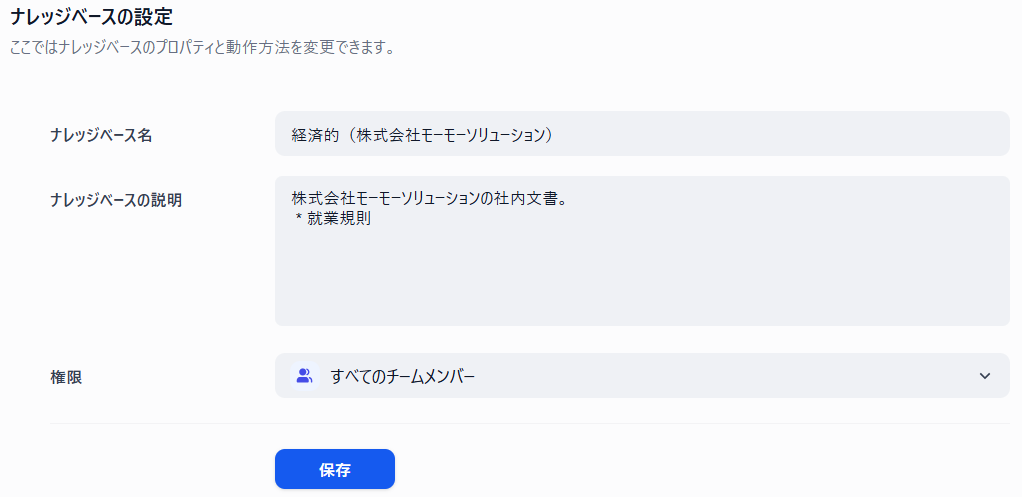
| ナレッジベース名 | 経済的(株式会社モーモーソリューション) |
| ナレッジベースの説明 | 株式会社モーモーソリューションの社内文書。 ・就業規則 |
| 権限 | すべてのチームメンバー |
| 項目 | 設定内容 |
|---|---|
| ナレッジベース名 | 高品質(株式会社モーモーソリューション) |
| ナレッジベースの説明 | 株式会社モーモーソリューションの社内文書。 ・就業規則 |
| 権限 | すべてのチームメンバー |
ドキュメントの追加(経済的 ナレッジベース)
別途 用意していた Word文書ファイルを 情報ファイル として登録します。
ファイル名: 株式会社モーモーソリューション 就業規則.docx
(A4 で 20 ページの文書ファイル)
これは事前に Gemini 2.0 Flash で作成した、ダミーの就業規則です。
厚生労働省が配布している「モデル就業規則」から架空の内容で マークダウン形式データを作成した後、手作業で Word 文書に変換しました。

情報ファイルの登録
それぞれのナレッジ画面を開き、「登録する情報ファイル」を追加します。
左側メニューの「ドキュメント」をクリックしてください。

「テキストファイルをアップロード」枠にファイルをドラッグするか、「参照」をクリックして ファイル選択ダイアログ を開き、Word文書ファイル を選択してください。

指定したファイル名が表示されたら、「次へ」ボタンをクリックしてください。

チャンク設定
情報ファイルをチャックに分割する際のパラメータを設定します。
ここでは下図のように設定します。

① チャンク設定
| 項目 | 説明 |
|---|---|
| チャンク識別子 | テキスト分割に使用する区切り文字です。 連続する2個の改行を区切りとします。 |
| 最大チャンク長 | チャンクサイズ(文字数またはトークン数)に 400 を設定します。 |
| チャンクのオーバーラップ | 隣接するチャンク同士で重複する部分のサイズ(文字数またはトークン数)です。 50 を設定します。 |
| 連続するスペース、改行、タブを置換する | スペース・改行・タブ文字を除去します。 チェックしておきます。 |
| すべてのURLとメールアドレスを削除する | URL とメールアドレスを除去します。 未チェックにしておきます。 |
| Q&A形式で分割 | 情報ファイルをQ&A形式(「"Q"と"A"」や「"質問"と"回答"」など)で分割します。 未チェックにしておきます。 |
② 検索設定
| 項目 | 説明 |
|---|---|
| トップK | 検索結果の上位 K個 のチャンクを使用します。 4 を設定します。 |
「保存して処理」ボタンをクリックすると 情報ファイルの登録 が実施されます。
登録が終了すると登録した情報ファイルが表示されます。

ドキュメントの追加(高品質 ナレッジベース)
情報ファイルの登録
「経済的 ナレッジベース」のときと操作は変わりません。
チャンク設定
情報ファイルをチャックに分割する際のパラメータ、埋め込みモデル、検索方法を設定します。
ここでは下図のように設定します。
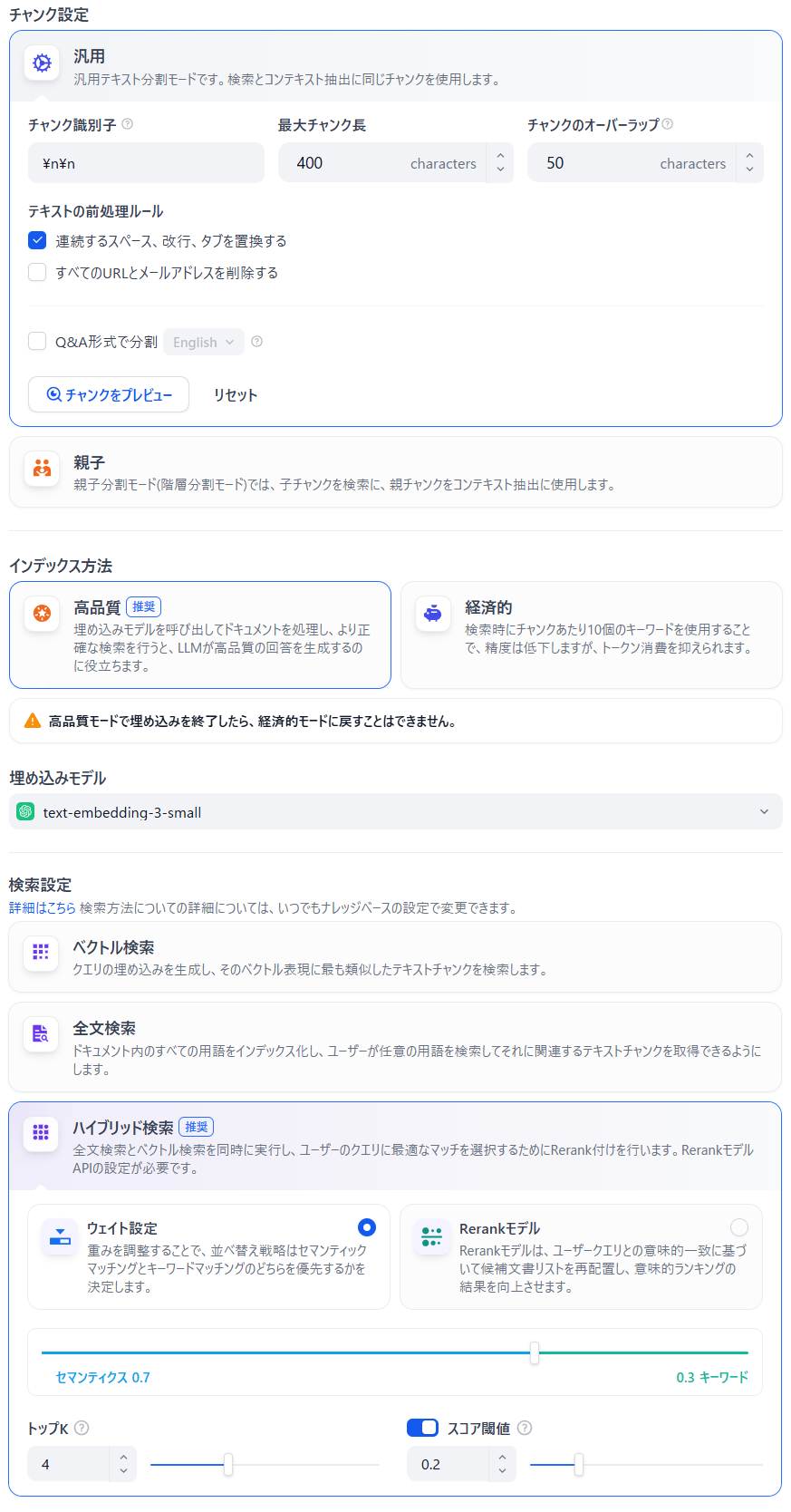
① チャンク設定
「経済的 ナレッジベース」と変わりません。
② 埋め込みモデル
| 項目 | 説明 |
|---|---|
| 埋め込みモデル | 前出の text-embedding-3-small を選びます。 |
③ 検索設定
| 項目 | 説明 |
|---|---|
| 検索方法 | 高精度な検索を実施する「ハイブリッド検索」を選びます。 |
| ウェイト設定 | ベクトル検索と全文検索の比率を「重み」で調節し、検索制度を調節する仕組みです。 こちらを選択してください。 |
| Rerankモデル | AI が嘘をつく状態(ハルシネーション)を低減するモデルを利用する仕組みです。 選択しないでください。 |
「保存して処理」ボタンをクリックすると 情報ファイルの登録 が実施されます。
登録が終了すると登録した情報ファイルが表示されます。

終わりに
これでナレッジベース側の準備が整いました。
次回は 両ナレッジをチャットボットに組み込み、作成される回答の精度を比較してみましょう。