はじめに
Distributed computing (Apache Hadoop, Spark, ...) Advent Calendar 2016の20日目です。
Apache Kuduをインストールして、テーブルを作ってinsertやupdateを試してはみたけれど、の次のステップとしてStremっぽいテストデータの作成、クエリの実行とパフォーマンスの確認方法について見ていこうと思います。
Apache Kudu のコンポーネントや用語の説明については割愛しています。
適宜下記なども参照してください。
Cloudera World Tokyo 2016 での発表資料
Apache Kuduのドキュメント
想定環境
- CentOS 7.2
- Cloudera Manager 5.9.0
- CDH 5.9.0 (4 node cluster/Impala構成済み)
- Apache Kudu 1.1.0
CDH5.9.0に含まれているImpala2.7からはKuduの表を扱えるようになっているので以前のようにKuduにアクセスするためのImpalaのforkであるImpala-Kuduをインストールする必要はなくなりました。
インストールせずに動かしたいだけなら単一ノードのQuickStart VMもあります。
http://kudu.apache.org/docs/quickstart.html
Kudu-examples
今回はKuduの開発メンバーによって公開されているkudu-examplesを使用します。
下記のようにすることでリポジトリを取得できます。
git clone https://github.com/cloudera/kudu-examples
java/collectl
言語も内容も色々とあるのですが、せっかくなので、リアルタイムに更新されていく自分の環境データということでノードのパフォーマンスを収集するcollectlを使ってみたいと思います。Collectl自体はOSのコマンドでTCP/IP経由で収集したデータを送信できます。今回のサンプルはクラスタの各ノードから送られてくるパフォーマンスデータを待ち受けてKudu上にInsertしていく、というものになります。
サンプルのページに移動してビルド
cd kudu-examples/java/collectl
mvn package
(Mavenがインストールされていない場合はsudo yum install mavenなどとしてインストールしてください)
Kudu Masterを指定して実行(例)
java -DkuduMaster=n1:7051,n2:7051,n3:7051 -jar target/kudu-collectl-example-1.0-SNAPSHOT.jar
kuduMasterの書式は<hostname>:<port>で、Masterが複数ある場合は,で区切って指定します。
上記ではn1,n2,n3の3つのMasterを想定していますが、一つの場合は単一のMasterの<hostname>:<port>で問題ありません。
ここまで実行するとサンプルのプログラムが実行され、Kudu上での表の作成と各ノードからのcollectlでのデータ収集の準備が整った状態になります。
続けてデータの生成送付の処理をしていきます。
データの収集を行うcollectlコマンドのインストール
sudo yum install maven collectl
パフォーマンスデータを収集してn1にデータを送信する例
collectl --export=graphite,n1,p=/
ここまで終ればKuduにデータが流れ込んでいっています。必要に応じて実行ノードを増やすことで生成データを増加させることができます。
次に格納されたデータをImpalaを使って確認したいと思います。
Impalaによるクエリの実行
これまでの処理でのKuduへのアクセスはJava APIを通じたものでした。そのため、Kuduには表ができていますが、Impalaからクエリを実行するためにはImpala側でも表を定義してKuduの表とのマッピングを行う必要があります。
マッピングに使うcreate table文の例はReadMeにも記載されていますが、KuduのWebUIからも確認することができます。
以下はMasterのWebUI(hostname:8051)にアクセスしたところからの例です。
Masterが複数ある場合、Leaderを確認する必要があります。
まず、Kudu MasterのWebUI上部のMastersをクリックします。
MasterのLeaderをみつけたらLinkになっているUUIDをクリックしてLeaderのWebUIに遷移します。
LeaderページのTablesをクリックします。(1.1.0ではLeader以外ではエラーになります)

今回の対象であるmetric表を選択します。

ページの下部に下記のようにImpalaでCreate Tableする際の定義が表示されます。
これは表示するクラスタの内容(Masternodeの名前など)を反映したものになっているのでそのままコピーしてimpala-shellなどで実行できます。
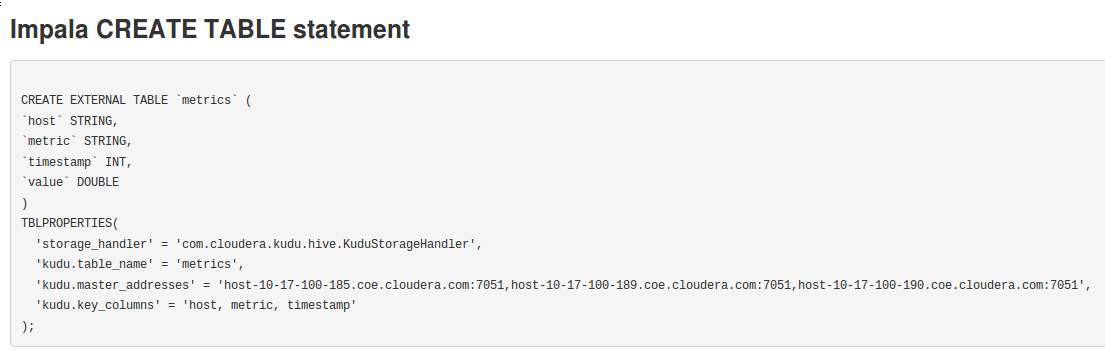
metric名の確認
Impala側でも表ができたらmetrics表にアクセスできるようになります。
どのようなメトリクスが収集されているかは下記のようにして確認できます。
> select distinct metric from metrics order by metric;
+---------------------+
| metric |
+---------------------+
| cpuload.avg1 |
| cpuload.avg15 |
| cpuload.avg5 |
| cputotals.idle |
| cputotals.irq |
| cputotals.nice |
| cputotals.soft |
| cputotals.steal |
| cputotals.sys |
| cputotals.user |
| cputotals.wait |
| ctxint.ctx |
| ctxint.int |
| ctxint.proc |
| ctxint.runq |
| disktotals.readkbs |
| disktotals.reads |
| disktotals.writekbs |
| disktotals.writes |
| nettotals.kbin |
| nettotals.kbout |
| nettotals.pktin |
| nettotals.pktout |
+---------------------+
データ収集ノードの確認
収集元のノード名も持っているので、下記のようにして意図したノードからデータがあるかを確認することも可能です。
> select distinct host from metrics order by host;
+-------------------------------------+
| host |
+-------------------------------------+
| host-10-17-100-184.coe.cloudera.com |
| host-10-17-100-185.coe.cloudera.com |
| host-10-17-100-189.coe.cloudera.com |
| host-10-17-100-190.coe.cloudera.com |
+-------------------------------------+
CPU使用率(idle)の変遷
状況によって実行したいクエリは変わると思いますが、例えばCPUにどれだけ余裕があるかを特定のノードについて時系列で確認する場合の例は下記のようになります。timestampはUNIX timeで格納されているので、表示時にunix time->UTC->JSTと変換をさせています。
> select host, from_utc_timestamp(from_unixtime(`timestamp`, 'yyyy-MM-dd HH:mm:ss'), 'JST') JST, value
from (select * from metrics
where metric = 'cputotals.idle' and host='host-10-17-100-185.coe.cloudera.com') as met
order by `timestamp` limit 10;
+-------------------------------------|---------------------|-------+
| host | jst | value |
+-------------------------------------|---------------------|-------+
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:05 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:06 | 84 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:07 | 81 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:08 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:09 | 97 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:10 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:11 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:12 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:13 | 98 |
| host-10-17-100-185.coe.cloudera.com | 2016-12-20 18:11:14 | 98 |
+-------------------------------------|---------------------|-------+
簡単なクエリの紹介だけですが、上記から各ノードから送付されるメトリクスの種別や頻度(毎秒)がわかると思いますので、クエリ作成の際の参考にしていただければと思います。
Cloudera Managerによるパフォーマンスの確認
最後に実施した作業のワークロードを確認していきたいと思います。
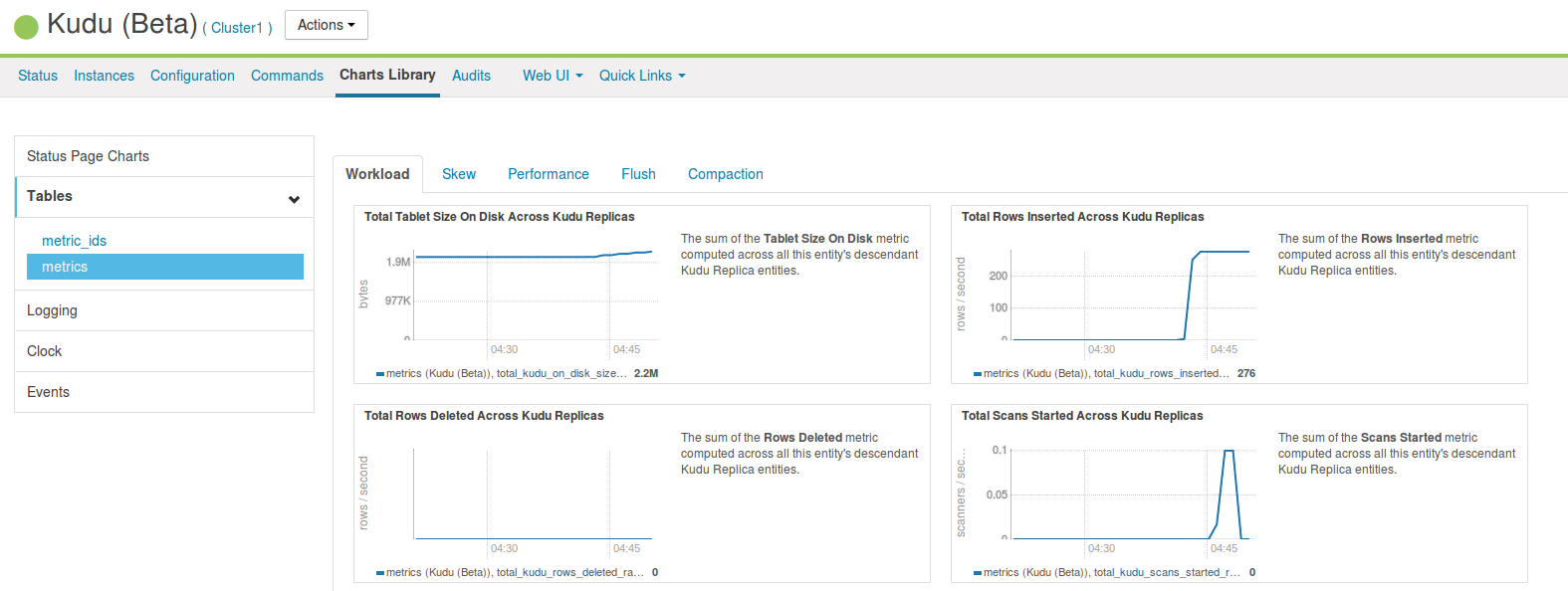
Cloudera ManagerではChart Libraryを使って生成行数や読み取りデータ量を確認することができます。
その際、Kudu ServiceとTablet Serverなどのroleとで確認できるChartが異なっているので注意が必要です。
Service
特定の表のデータ量の変遷や行の増加量などといった情報を確認することができます。
表全体としてのデータの状況やリソース消費を確認する際に有用です。
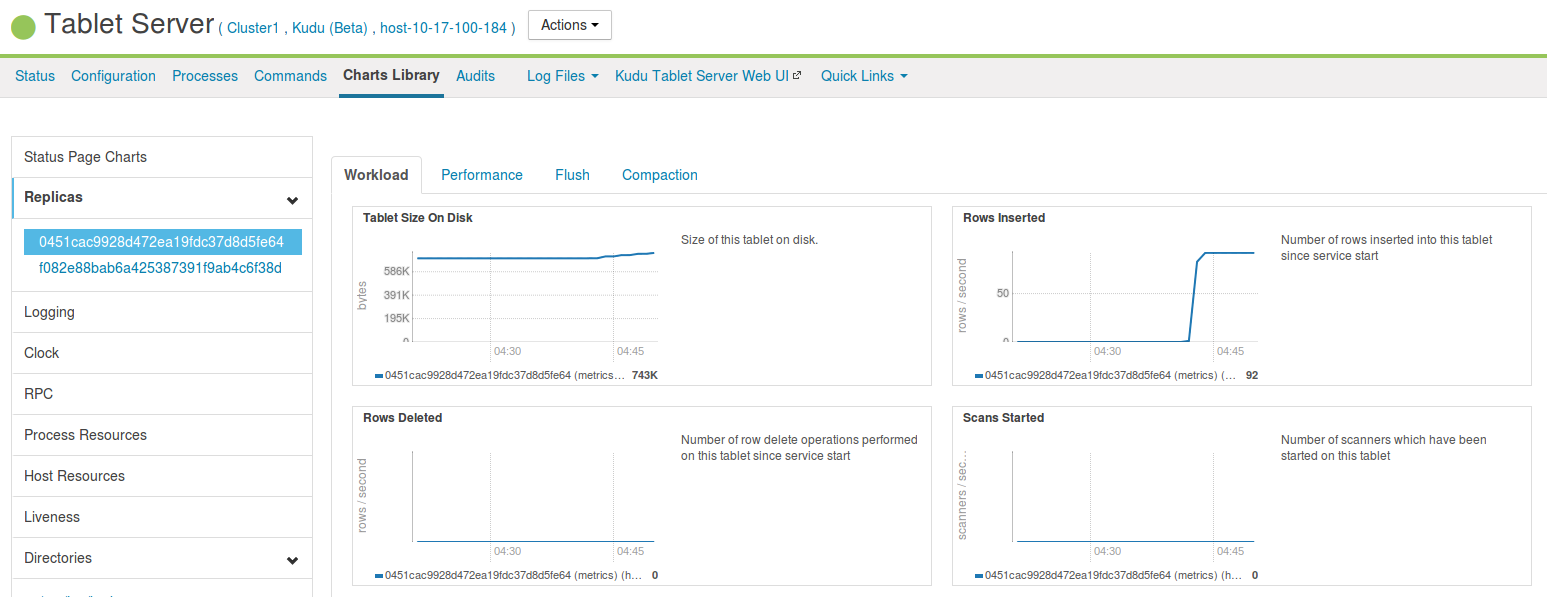
TabletServer
TabletServer上で特定のレプリカの処理を追跡することができます。
テーブル設計によってはデータの生成/スキャンに対してホットスポットとなるパーティションができてしまうことがあります。
テーブル全体のチャートからは判別できない負荷の偏りなどを確認する際に威力を発揮します。
おわりに
いかがでしたでしょうか。
構築するシステムの負荷テストをする際には実際のデータを使うのが一番ですが、sampleを使用することでインストールしていくつかコマンドを実行してみる、というテストよりも少し動きのある検証ができるのでぜひ一度試してもらえればと思います。
今回の処理だけだとあまり負荷にはならないと思うので、裏でMapReduceを実行したりするとKudu上のデータをクエリする際にそれなりに動きのある情報が見れるかもしれないですね。
また、kudu-examplesの他のサンプルではランダムデータをinsertするものなどもあるのでinsertの負荷を上げたい場合などには試してみてください。