会社の中に「Pythonやってみたいんだけど」という人がいてもいまは直接会ってコーチすることもできない、でも仲間を増やしたい、そんなときに。
Python チュートリアル
まず、日本語のドキュメントがあることを紹介しておく。
https://docs.python.org/ja/3/tutorial/index.html
Katacoda :環境を構築するところで挫折させないために
Jupyter notebook の設定でつまづく前にまずはPythonを動かしてもらう。
そのためにKatacodaのこのシナリオ
https://www.katacoda.com/scenario-examples/scenarios/notebooks-py
を使ってもらう。

起動したら「START SCENARIO」を実行。
せっかくなのでセルをMarkdown に切り替えて実行してもらう


ここまで来たらPython を電卓として使ってみてもらう
2 + 2
▶実行

50 - 5*6
▶実行

Pythonの構文をちょこっと紹介しておく
for i in range(5):
print(i)
▶実行
これに辞書型を組み合わせてみて
purple = {"ニックネーム": "れにちゃん",
"出身地": "神奈川県",
"キャッチフレーズ": "感電少女",
"生年月日": "1993年6月21日"}
for key in purple:
print(key, purple[key])
▶実行

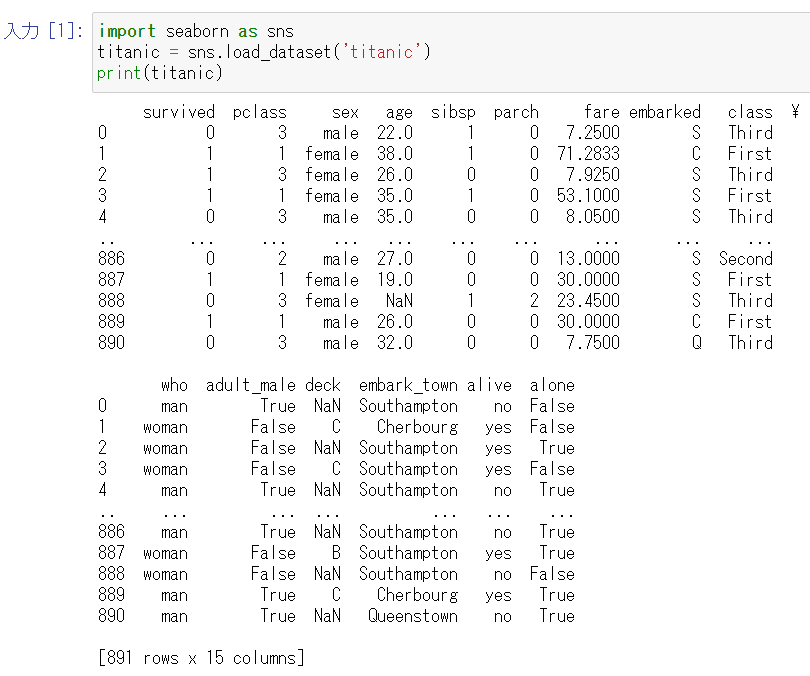
食欲をそそるためにseabornのタイタニックデータセットを読み込んで表示させてみようとしたけれどそれはできませんでした。
import seaborn as sns
titanic = sns.load_dataset('titanic')
print(titanic)

でもmatplotlibはいけそう。
pandas や scikit-learn も使えるようです。ボストン住宅価格データセットが読み込める。
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
boston = load_boston()
import pandas as pd
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names) # 説明変数(boston.data)
boston_df['MEDV'] = boston.target # 目的変数(boston.target)
boston_df.head()
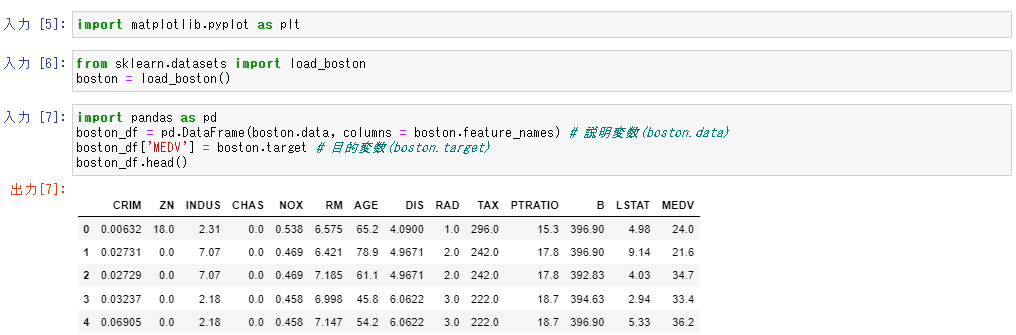
これで機械学習のハンズオンはできそうです。
それはおいおい準備するとして、まずは可視化ができることを会社の仲間に伝えたい。
import matplotlib.pyplot as plt
d = {'apple':10, 'banana':30, 'orange': 40, 'kiwi': 15}
x = [1,2,3,4]
plt.bar(x, d.values(), tick_label=list(d.keys()))
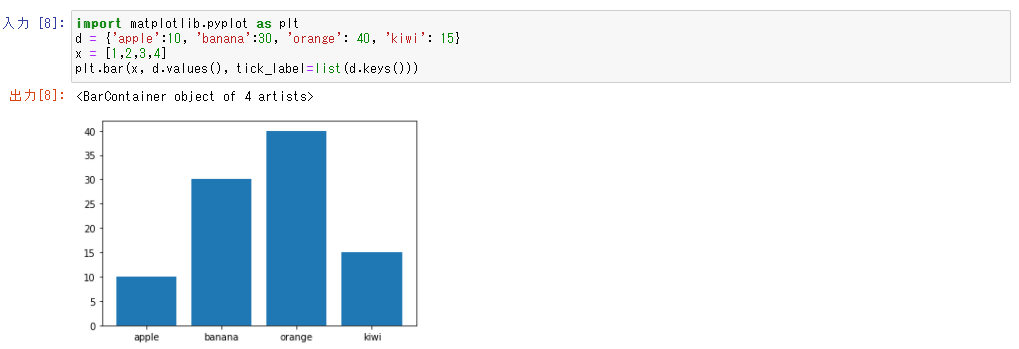
これでなんとかいけそうです。
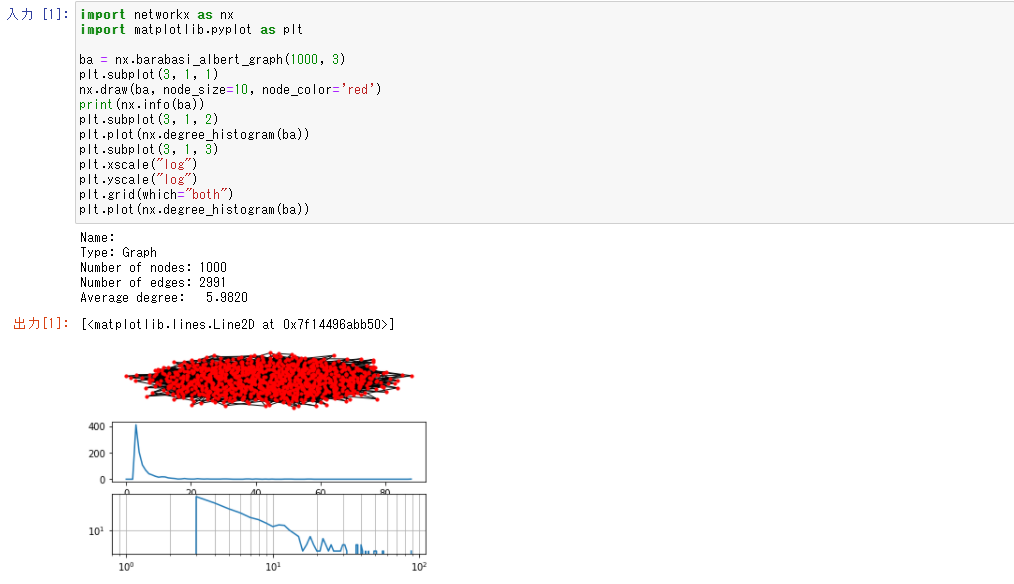
もし、興味を持ってもらえそうな人だったらネットワーク分析とかも。
import networkx as nx
import matplotlib.pyplot as plt
ba = nx.barabasi_albert_graph(1000, 3)
plt.subplot(3, 1, 1)
nx.draw(ba, node_size=10, node_color='red')
print(nx.info(ba))
plt.subplot(3, 1, 2)
plt.plot(nx.degree_histogram(ba))
plt.subplot(3, 1, 3)
plt.xscale("log")
plt.yscale("log")
plt.grid(which="both")
plt.plot(nx.degree_histogram(ba))
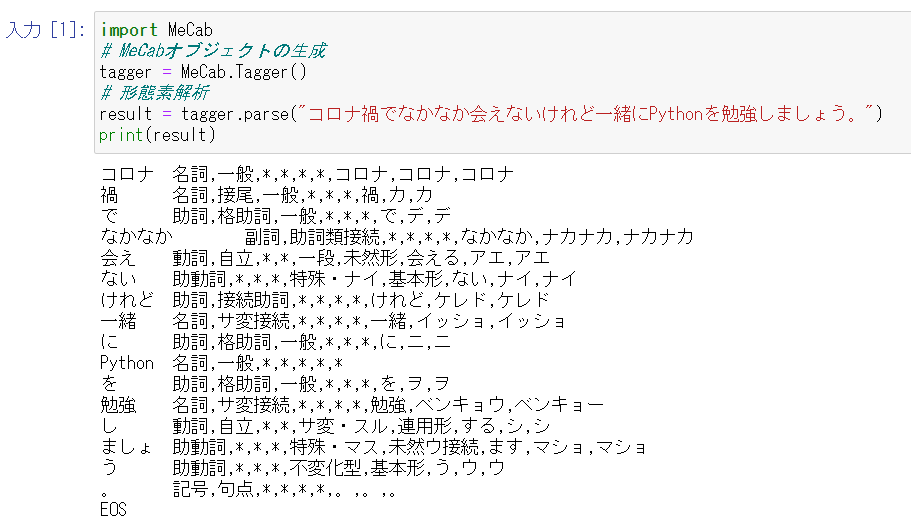
欲を言えば、形態素解析ができるといいな。
import MeCab
# MeCabオブジェクトの生成
tagger = MeCab.Tagger()
# 形態素解析
result = tagger.parse("コロナ禍でなかなか会えないけれど一緒にPythonを勉強しましょう。")
print(result)
from janome.tokenizer import Tokenizer
t = Tokenizer()
toks = t.tokenize("コロナ禍でなかなか会えないけれど一緒にPythonを勉強しましょう。")
for tok in toks:
print(tok)
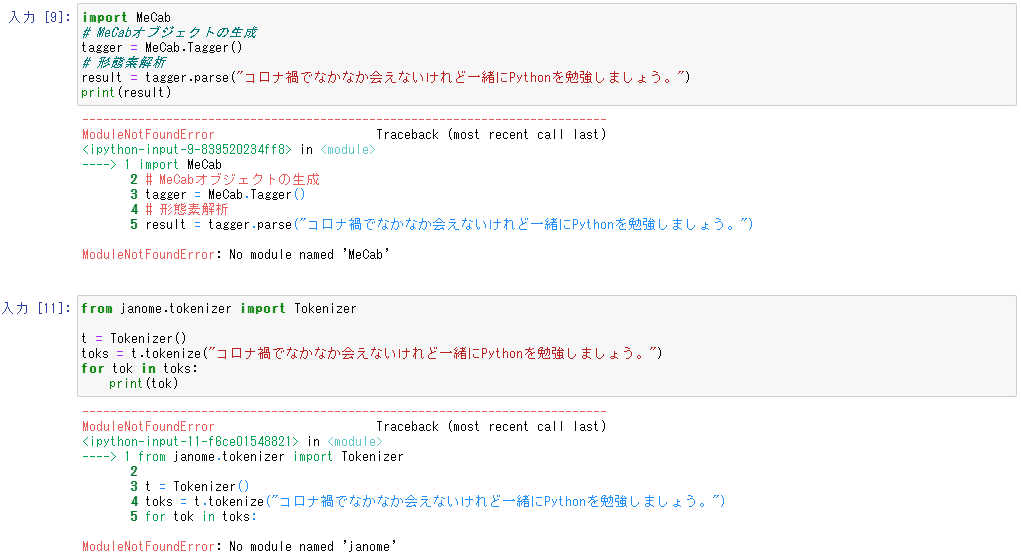
MeCab も janome もダメでした。
Katacoda のこのシナリオは日本人向けに作られた環境じゃないのでしょうね。
WordCloudはどうでしょう。
import wordcloud
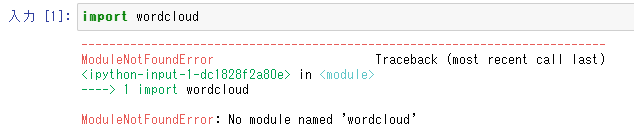
これは無理でした。
Google Books API
じゃあ Google Books API を使って、取得した情報を表示することはできるでしょうか。
import requests
url = 'https://www.googleapis.com/books/v1/volumes?q=isbn:'
def main(isbn):
req_url = url + isbn
response = requests.get(req_url)
return response.text
if __name__ == "__main__":
while True:
isbn_input = input("input ISBN >>>")
print(main(isbn_input))
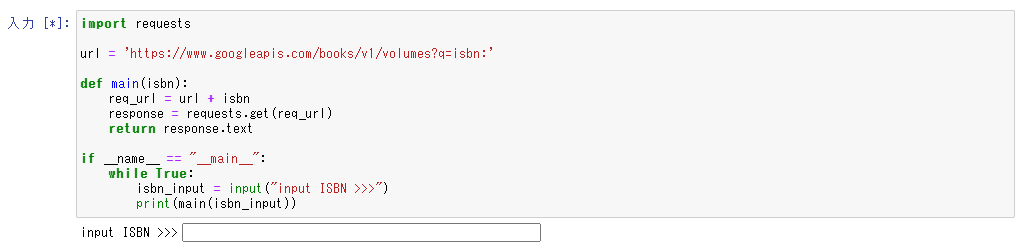
これは行けそうです。
何でもいいので、手もとにある本のISBNコード(2段バーコードの上段の13桁)を入力してみて貰いましょう。


jsonで応答が戻ってきました。
こうすればビッグデータから情報を抽出する最初の一歩を体験してもらうことができます。
input ISBN >>>9784163907383
{
"kind": "books#volumes",
"totalItems": 1,
"items": [
{
"kind": "books#volume",
"id": "aIaCtAEACAAJ",
"etag": "ICKqWNZ3GZI",
"selfLink": "https://www.googleapis.com/books/v1/volumes/aIaCtAEACAAJ",
"volumeInfo": {
"title": "CRISPR究極の遺伝子編集技術の発見",
"authors": [
"ジェニファー・ダウドナ",
"サミュエル・スターンバーグ"
],
"publishedDate": "2017-10",
"industryIdentifiers": [
{
"type": "ISBN_10",
"identifier": "4163907386"
},
{
"type": "ISBN_13",
"identifier": "9784163907383"
}
],
"readingModes": {
"text": false,
"image": false
},
"pageCount": 333,
"printType": "BOOK",
"maturityRating": "NOT_MATURE",
"allowAnonLogging": false,
"contentVersion": "preview-1.0.0",
"panelizationSummary": {
"containsEpubBubbles": false,
"containsImageBubbles": false
},
"imageLinks": {
"smallThumbnail": "http://books.google.com/books/content?id=aIaCtAEACAAJ&printsec=frontcover&img=1&zoom=5&source=gbs_api",
"thumbnail": "http://books.google.com/books/content?id=aIaCtAEACAAJ&printsec=frontcover&img=1&zoom=1&source=gbs_api"
},
"language": "un",
"previewLink": "http://books.google.de/books?id=aIaCtAEACAAJ&dq=isbn:9784163907383&hl=&cd=1&source=gbs_api",
"infoLink": "http://books.google.de/books?id=aIaCtAEACAAJ&dq=isbn:9784163907383&hl=&source=gbs_api",
"canonicalVolumeLink": "https://books.google.com/books/about/CRISPR%E7%A9%B6%E6%A5%B5%E3%81%AE%E9%81%BA%E4%BC%9D%E5%AD%90%E7%B7%A8%E9%9B%86%E6%8A%80%E8%A1%93%E3%81%AE.html?hl=&id=aIaCtAEACAAJ"
},
"saleInfo": {
"country": "DE",
"saleability": "NOT_FOR_SALE",
"isEbook": false
},
"accessInfo": {
"country": "DE",
"viewability": "NO_PAGES",
"embeddable": false,
"publicDomain": false,
"textToSpeechPermission": "ALLOWED",
"epub": {
"isAvailable": false
},
"pdf": {
"isAvailable": false
},
"webReaderLink": "http://play.google.com/books/reader?id=aIaCtAEACAAJ&hl=&printsec=frontcover&source=gbs_api",
"accessViewStatus": "NONE",
"quoteSharingAllowed": false
}
}
]
}
The Zen of Python :今はまだ語り過ぎない
そしてPythonの禅について軽く紹介する。
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
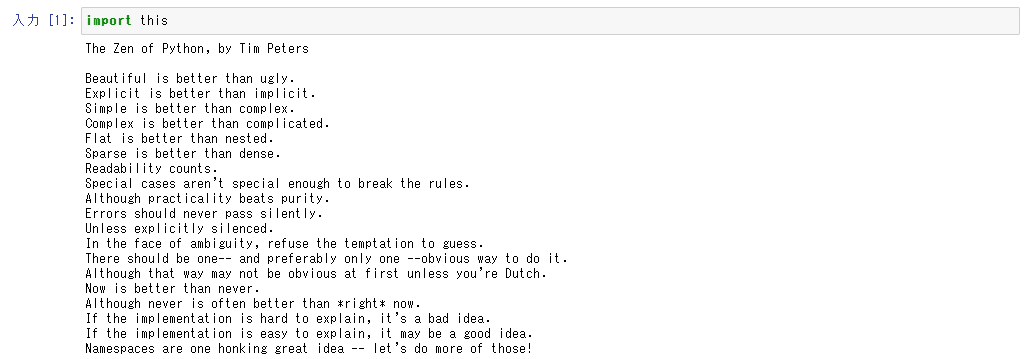
まず仲間になって貰うことが着地点なので、Zenについては熱を入れすぎないようにする。
The UNIX Philosophy とか
C++が歩んだ苦難の道 とか
それぞれに敬意を表しながらやってゆこう。
Jupyter notebook のインストールに誘う
Katacodaのさっきのシナリオではできなかったことがあるのを逆手にとって、
「じゃあ次はJupyter notebook を自分の環境にインストールしましょう」と誘ってみる。
「そうするとこんなことが出来るからね」って伝えることができます。
あいみょんの「マリーゴールド」の歌詞をテキストファイルにしておいて、
import wordcloud
import matplotlib.pyplot as plt
import MeCab
bun = ""
with open('あいみょん_マリーゴールド.txt') as f:
for line in f.readlines():
bun = bun + line.strip()
wc = wordcloud.WordCloud(width=1000, height=600, background_color="white",
font_path=r"C:\windows\Fonts\meiryo.ttc",
stopwords=["いつ", "し", "さ", "よう"])
tagger = MeCab.Tagger()
word_kaiseki = tagger.parse(bun)
lines = word_kaiseki.split('\n')
selected = []
for line in lines:
feature = line.split('\t')
if len(feature) == 2:
info = feature[1].split(',')
hinshi = info[0]
if hinshi in ('名詞', '形容詞', '動詞'):
selected.append(feature[0])
wc.generate(" ".join(selected))
plt.imshow(wc)
plt.axis("off")

「マリー」と「ゴールド」が「マリーゴールド」になるようにするにはどうしたらいいのかな、とか、名詞だけを抽出してみたいとか、サビのところをもう少し大きくするためのチューニングはどうしたらいか、などと少しずつプログラムのほうに興味を持ってもらいます。
ほかにも新しい仲間の興味に応じて
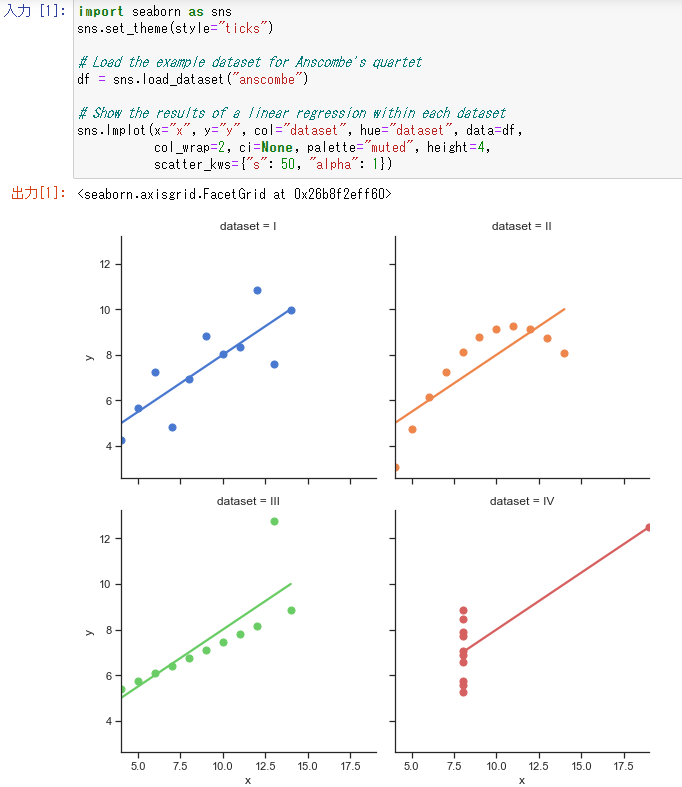
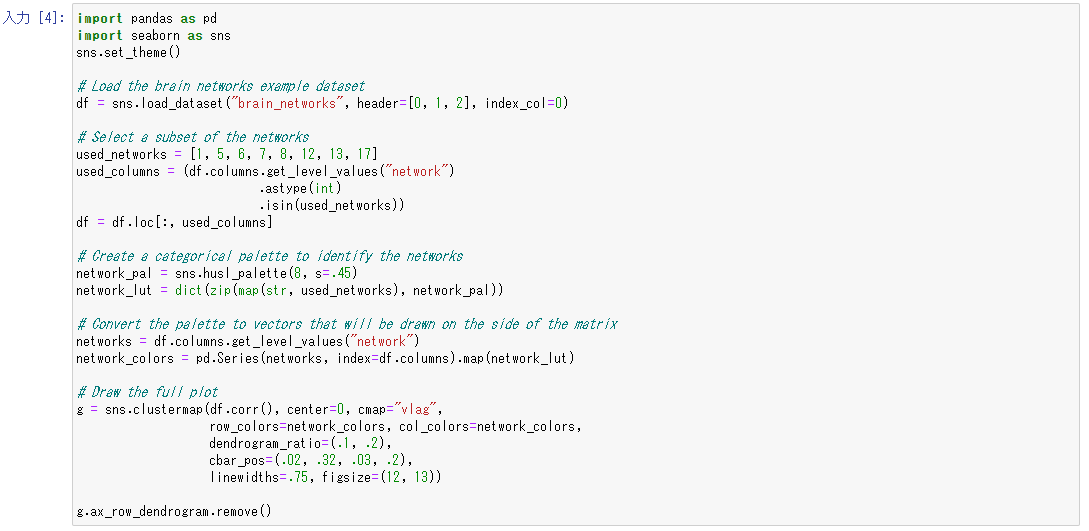
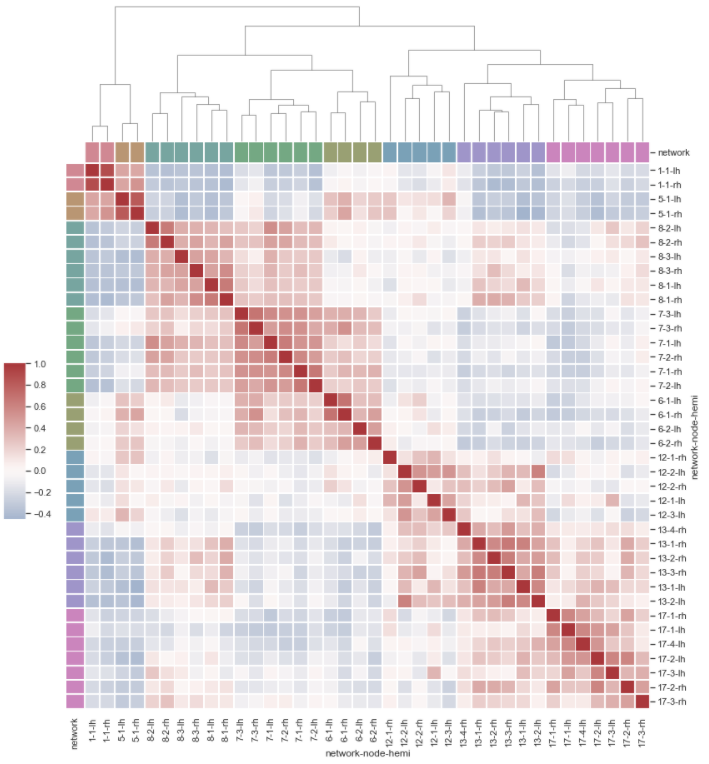
これはコンピュータビジョンを用いた画像認識の例です。


ここから先は、あれこれ伝え過ぎると混乱させてしまうので辻慎吾先生一択で紹介してみます
Youtubeや書籍を紹介する
仲間になってくれる人がプログラム言語やオブジェクト指向に慣れていない人だったらこれがいいかも。
connpass :コミュニティを紹介する
過去の状況も動画で保存されているので観てもらおう。
https://www.youtube.com/channel/UCoKjZ7BAdDrV1nwJdADv0Fw/videos
この回は私の推しです。
https://www.youtube.com/watch?v=w7CxVJb0AJo

資料がアーカイブされていることを伝えて、興味のあるものを探して貰ってもいいかも。
https://startpython.connpass.com/presentation/
connpas おまけ
新しい仲間が女性だったら
新しい仲間がインフラまわりの自動化に関心があれば
資料の質の高さと量の多さだと
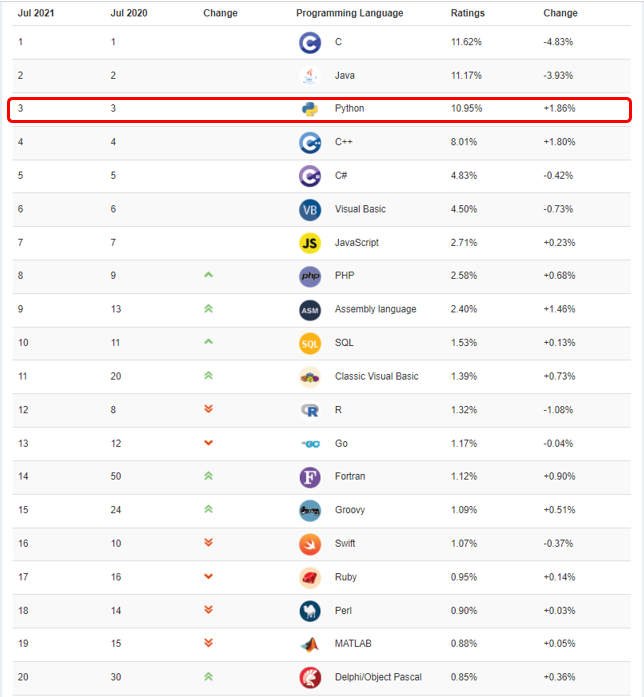
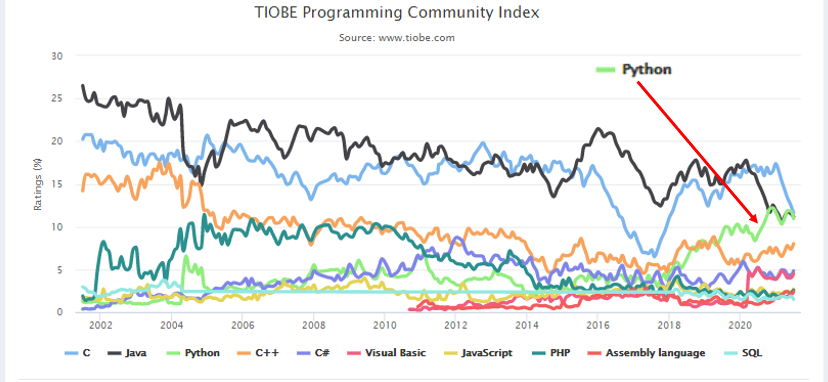
言語の人気を知りたいという人には
ワールドワイドで
資格を取りたいという人には
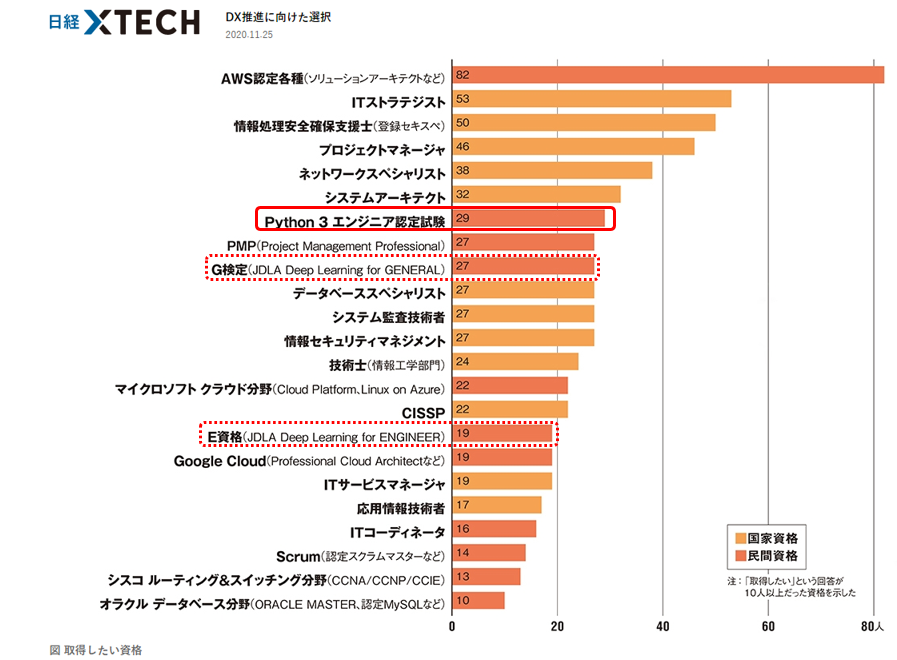
その先の資格
参考にさせていただいた情報
Katacoda
connpass
seaborn Example gallery
みんなのPython 第4版
Pythonスタートブック[増補改訂版]
Pythonで学ぶネットワーク分析 ColaboratoryとNetworkXを使った実践入門
Python 実践データ分析 100本ノック