クエリに関する戦略
SELECT * を避ける
一つだけ言えることは、そのクエリですべてのカラムが必要になることは、ほとんどないということです。
特に、複数のテーブルを結合した際に取得する行の数は計り知れません。
-- 3つのテーブルすべての行から取得される!
SELECT * FROM a
LEFT JOIN b
ON a.id = b.a_id
LEFT JOIN c
ON a.id = c.a_id
取得する列はすべて明示的に選択してあげるべきでしょう。
この罠に陥りがちなのが、あなたがORMフレームワークを利用しているときです。
デフォルトのクエリは、たいていすべての行を取得しようとするはずです。
//これは先程のクエリと同じ問題を抱えている
$a_table = TableRegistry::get('a');
$a_table->find('all')
->contain(['b', 'c']);
確かにデメリットも存在します。
第一に、もし100の行が必要になるときは、コードがスマートではなくなることです。
$a_table = TableRegistry::get('a');
$a_table->find('all')
->select('hoge', 'foo', 'bar' //....これが後100回続く
->contain(['b', 'c']);
表示されている表に新たなカラムが必要になるかもしれません。
その際には、表示する側とクエリを発行する側の双方で、確実に修正をする必要があります。
多くのコードの記述を省く*の使用か、パフォーマンスの選択になることでしょう。
この場合なら、パフォーマンスを取るほうが優勢に思えます。
WHEREでかける条件をHAVINGで書かない
次のSQL文は、富山県の60歳以上の人数を取得するためのものです。
SELECT name, age
FROM people
WHERE pref = '富山'
GROUP BY name
HAVING age >= 60
あなたは違和感に気づくことになるでしょう。わざわざage >= 60という条件を、HAVINGで書く理由はどこにも見当たりません。
このように書き直されたクエリは、全く同じ結果を返すことになります。
SELECT name, age
FROM people
WHERE pref = '富山'
AND age >= 60
GROUP BY name
見出しにあるように、後者のwhereで書かれたクエリのほうがパフォーマンスは優れていることでしょう。
ではこの2つのクエリの違いはどこにあるのでしょうか?
単純なSQLの実行順序を見ていきましょう。
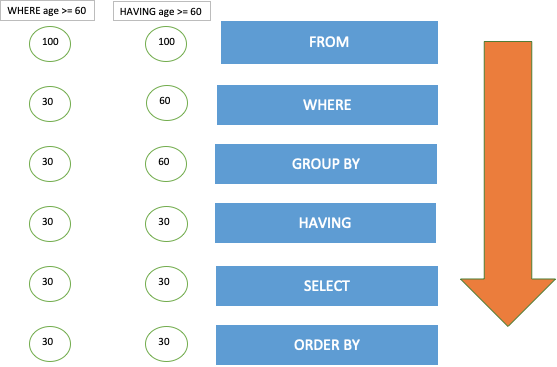
簡単なイメージです。左の数字は、取得された件数を表しています。
WHEREで絞り込まれた場合には、早い段階で取得件数は30件まで絞り込まれています。
その後の作業もスムーズに進行することでしょう。
HAVINGは結果セットに対して絞り込まれます。
HAVINGは全行をスキャンしてソートしてから絞り込みを実行するでしょう。
HAVINGは基本的にや集約された結果に対して使用されるものです。
ソートはコストが高い
ソートは思っているよりもコストの高い操作です。
ORDER BYで順序を明示的に指定するのはもちろんですが、
以下の操作においても、暗黙のソートが使われています。
GROUP BYDISTINCT- 集約関数(SUM、COUNT、AVG、MAX、MIN)
- 集合演算子(UNION、INTERSECT、EXCEPT)
- ウィンドウ関数
この話を聞いて不安になる必要はありません。インデックスがソートに関する問題を解決してくれます。
最も利用されることの多いB木インデックスは、既にデータをソート順に格納しています。
逆に言えば、インデックスを用いていない列に対してはソートを利用するのは、良い考えではないでしょう。
また、下記にあげる列に対してはインデックスは使用されません。
-
COUNT(*)や、price * 1.08など、計算された列 - 結合テーブルに対するソート
しかし、投稿に関するお気に入りの総数の多い順で並び替えたい欲求は自然と生まれてくるものです。
そのようなソートを実現させる方法は、設計に関する戦略をご覧ください。
アプリケーションコードとも向き合う
SQLの最適化は、クエリのみにとどまる話ではありません。
例えば、あなたはORMが発行するクエリを見たことはありますか?
一度も見たことがないというなら、仕事中にこの文章を眺めている場合ではありません。
確かにORM魔法のようにクエリを発行してくれますが、現実ともしっかり向き合うべきなのです。
代表的な話題としては、「N + 1問題」などがあります。
あなたの使用しているフレームワークは、Eager loadingをサポートしていますか?
また、全く必要のないクエリをアプリケーションコード内で発行していることに気づくきっかけになるかもしれません。
データベースとアプリケーションコードでは、それぞれ苦手なことと得意なことがあります。
例えば、データベースは複雑な文字列の処理は苦手なので、アプリケーションコードに任せるべきでしょう。
反対に、行をカウントするなら、データベースのほうが適切です。
インデックスに関する戦略
インデックスを知る
パフォーマンスの最適化について、インデックスの話題は欠かせません。
インデックスについて、「特定の単語について調べたいとき、本を全ページ見開いて探すのでなく索引を使って探す」なんて例えがよく使われます。
場合によっては、データ行を参照せずに値を取得することも可能です。(カバリングインデックス)
MySQLにおいて一般的なのは、B木インデックスです。
インデックスをむやみやたらに貼らない
インデックスが使われたら早くなるからといって、すべてのカラムにペタペタ貼るべきではありません。
そもそも、基本的には一つのクエリでは一つのインデックスしか使用できませんし、インデックスが多すぎる場合には、挿入、更新、削除といった動作のコストが高くつきます。
テーブルの設計にあった、最適なインデックスを選択しましょう。
に主キーとUNIQUEキーを設定している時点で自動でインデックスので、わざわざさらにインデックスを指定する必要はありません。
また、重複インデックスに対しても無力です。全く同じインデックスが作成されたとしても、警告を出したりしてくれることはないでしょう。
カーディナリティの高いものを選ぶ
最適なインデックスを選択する指標となるものが、カーディナリティです。
カーディナリティとは、そのカラムの持つデータの種類の度合いです。
例えば、性別を表す列なら、男女の2種類しかないので、カーディナリティは低いです。
対して、誕生日はカーディナリティの高い列だと言えます。
インデックスは、カーディナリティの高い列に対して効果的です。
カーディナリティの低い列にインデックスを利用した場合には、かえって逆効果になる可能性もあります。
複合インデックスを理解する
複合インデックスは、列の順序が重要です。
次のようなインデックスがあったとします。
`ADD INDEX idx(sex, birth_date)'
次のクエリはいずれもインデックスが使用されません。
SELECT first_name, last_name
FROM users
WHERE birth_date = '1970-11-11'
SELECT first_name, last_name
FROM users
WHERE sex = '男' or birth_data = '1970-11-11'
このインデックスにはまだ問題があります。
通常は、WHEREでは、カーディナリティの高い選択から初めたほうが、パフォーマンスはよくなります。
100→50→2の順序で数が絞られていくよりも、
100→4→2の順序で進めたほうがよいのは直感的に明らかです。
インデックスの使用されない方法
あなたがもしインデックスを使用したくないのなら、以下の方法を検討してみるべきです。
列を加工する
SELECT age
FROM user
WHERE age + 10 > 60
インデックスを利用する列は単純にするべきです。もとの列を加工してやったら、MySQLはそれを理解することができません。
暗黙の型変換
SELECT age
FROM user
WHERE age > '60'
WHEREの右辺の値が今度は文字列になっています。
このような場合には、ageを文字列に変換してから比較を行います。
このような場合にも、インデックスの利用は難しいでしょう。
中間一致または後方一致
SELECT name
FROM user
WHERE name LIKE '%山%'
このようなクエリは非常に便利ですが、インデックスは使われてくれません。
前方一致の場合はインデックスを利用してくれます。
SELECT name
FROM user
WHERE name LIKE '%山'
or条件
SELECT name
FROM user
WHERE name '山田' or '山中'
このクエリはこのように書き換えることが可能です。
SELECT name
FROM user
WHERE name = '山田'
UNION ALL
SELECT name
FROM user
WHERE name = '山中'
否定条件
SELECT name
FROM user
WHERE name <> '山田'
否定条件は、返却する行数が多すぎて、オプティマイザがシーケンシャルスキャンのほうが有利だと判断する可能性があります。
設計に関する戦略#
最適なデータ型を選択する##
データ型の選択に際して、最も大切で当たり前なことは、小さなデータ型を選択することです。
text型より`varchar'型、のほうがパフォーマンスに与える影響が良いことは言うまでもありません。
またもや当たり前のことを述べますが、一般的に正しいデータ型を選択するべきです。
あなたのデータベースは数字や日付を格納するはずのデータをvarchar型になっていたりしませんか?
一般に文字列を比較するよりも整数を比較するほうがコストがかかりません。
あえて正規化を崩す##
私達は幼い頃から、データベースは適切に正規化するように母親によく諭されたものです。
よくある正規化されたデータベースの例
booksテーブル
| title | author_id | publish date | ISBN |
|---|---|---|---|
| 吾輩は猫である | 1 | 1905-10-06 | 0000000000000 |
| 伊豆の踊り子 | 2 | 1926-01-01 | 0000000000001 |
| 雪国 | 2 | 1927-06-12 | 0000000000002 |
| ノルウェイの森 | 3 | 1987-09-04 | 0000000000003 |
authorsテーブル
| author_id | name | sex | died |
|---|---|---|---|
| 1 | 夏目漱石 | 男 | 1916-12-09 |
| 2 | 川端康成 | 男 | 1972-04-16 |
| 3 | 村上春樹 | 男 | 9999-99-99 |
テーブルを正規化するのは、良い設計です。
この例では、booksテーブルから、冗長な著者の情報はありません。
データの更新は正規化されていないものと比べて、きっと早くなることでしょう。
しかし、正規化されたデータベースには短所もあります。
青空文庫に掲載されている本を探すクエリを考えてみましょう。
SELECT books.title, authors.name
FROM books
INNER JOIN authors
ON books.author_id = authors.id
WHERE auhtors.died >= DATE_ADD(CURRENT_DATE(), INTERVAL 50 YEAR)
ORDER BY authors.name
まず、テーブルを結合すると、多少なりともコストが掛かることは頭の片隅にいれておきましょう。
今回の例は単純な結合すみましたが、複雑な結合が介入するとその分コストは大きくなることでしょう。
さらに、インデックスは期待できるものではもうありません。
このクエリを最適化する方法が、非正規化です。
| title | publish date | ISBN | name | sex | died
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
| 吾輩は猫である | 1905-10-06 | 0000000000000 | 夏目漱石 | 男 | 1916-12-09
| 伊豆の踊り子 | 1926-01-01 | 0000000000001 | 川端康成 | 男 | 1972-04-16
| 雪国 | 1927-06-12 | 0000000000002 | 川端康成 | 男 | 1972-04-16
| ノルウェイの森 | 1987-09-04 | 0000000000003 |村上春樹| 男 | 9999−99-99
クエリは単純になります。
SELECT title, name
FROM books
WHERE died >= DATE_ADD(CURRENT_DATE(), INTERVAL 50 YEAR)
ORDER BY name
パフォーマンス上の問題は解決できましたが、非正規化の欠点は正規化の長所がすべて失われることです
もし著者の情報を更新や削除をしようとするなら、すべての更新を確実に行われることを達成しなければなりません。
正規化と非正規化は重大なトレードインです。
本当にその非正規がが必要なのか、正規化を崩すことによりデメリットを上回るメリットがあるのか、もう一度慎重に考えてみましょう。
キャシュされた結果をもたせる
先ほどと同じテーブルを使用して、出版した本が多い順著者を並べ替えます。
SELECT count(*) AS book_cnt authors.name
FROM books
LEFT JOIN authors
ON books.author_id = authors.id
GROUP BY books.author_id
ORDER BY book_cnt
ORDER BYに指定したbook_cntには、インデックスは使用されません。
そのため、ファイルソートは覚悟しておく必要はあるでしょう。
また、この例では比較的簡単にすみましたが、集計を表示するために複雑なサブクエリが必要になるかもしれません。
そんなときは、authorsテーブルに予めbook_cnt列をもたせておきます。
booksテーブルに新たな書籍が追加されたタイミングで、同時にbook_cnt列も更新して置く方法が一般的です。
booksテーブルを更新する際のコストはかかる、冗長構成になるなどのデメリットは存在します。
リアルタイム性があまり重要でない数をカウントする必要があるなら、キャッシュテーブルを使用するてもあります。
例えば、コミケの参加者を得るために、入場者がカウントされるたびに他のテーブルを更新するのは現実出来ではありません。
そのような時には、1時間おきくらいにバッチ処理などで集計した結果を格納するキャシュテーブルを生成するのが有効です。
最後に
パフォーマンスを改善するヒントを提供してきましたが、それらが実際に有効かどうかは実装に依るところです。
パフォーマンスを改善したいのなら、必ずプロファイリングや測定が重要になってきます。
情報を鵜呑みにするのではなく。いかに活用するかを考えるべきでしょう。
参考書籍
実践ハイパフォーマンスMySQL
SQLアンチパターン
プログラマのためのSQL
達人に学ぶSQL徹底指南書
困ったら公式