はじめに
この記事は文書執筆の指南書で解説されている問題点を RedPen で発見する - Qiitaのtextlint版です。
そのため、先に元ネタとなる記事を読んでおく必要があります。
実装の細部は異なりますが、RedPenとtextlintは似たようなルールを持っているので、
それを比較して読みたい人向けの記事となっています。
Atomのプラグインであるlinter-textlintを使いながら書きました。
(QiitaにはPull Request駆動で書ける仕組みがないので、簡易的なチェックしかしてません)
対象とする読者
本稿の対象は論文やマニュアルなどの技術文書を書く人です。本稿を読むにあたって特に専門的な知識は必要ありません。ただし textlint についての記事ですので、textlintをインストール しておくとよいでしょう。
指南書で紹介されている文書の問題点
以下、上記の指南書で解説されている文書の問題点と、textlint による検知方法について解説します。
また、この中で登場するルールは基本的に日本語を対象にしたルールです。
追記(2016-07-13): この辺のルールをまとめたプリセットは以下にあります
文の長さ
「理科系の作文技術」の8章「わかりやすく簡潔な表現」を含め、数多くの文書執筆の指南書で「文は短く簡潔」に書くべきと言われています。長い文を理解するのには時間がかかりますし、そもそも読者が文を理解できない可能性があります。上記の執筆指南書ではありませんが、「技術文書の書き方」という資料では文を 100 文字以内にするべきと解説しています。
RedPen では文の長さに関する機能に、SentenceLength があります。SentenceLength は入力文書の中に長すぎる文(センテンス)が見つかるとエラーを出力します。また、私は文を短くする方法について「文が長すぎる問題とその対処」という記事を書きました。あわせて参考にしてください。
textlintではtextlint-rule-sentence-lengthのルールで文章の長さをチェックすることができます。
言葉の品性
技術文書では感情的な単語や、曖昧な単語など利用するべきではない単語があります。たとえば、「文章の書き方」の 17ページ目より「言葉の品性」の解説で利用するべきでない単語について紹介しています。
RedPen が提供する InvalidExpression は使用するべきでない単語が見つかるとエラーを出力します。ただし、InvalidWord 用の表現辞書は十分でないので、各自気になる表現を追加してください。
textlintではtextlint-rule-prhで正規表現ベースの辞書を作成できます。
英語向けでは、ジェンダーやポリティカルコネクトな単語をチェックするalexを使ったtextlint-rule-alexがあります。
細かいものだと!?!?を禁止するtextlint-rule-no-exclamation-question-markというルールがあります。
冗長な表現
「文章の書き方」では「〜ことができる」や「〜を行う」を冗長な表現として紹介しています。「することができる」は有害と考えられる」 で紹介したようにスクリプトで冗長表現を検知するとよいでしょう。今後、RedPen >本体でも冗長表現を検知する機能を提供する予定です。
このルールが今のところtextlintにはないです。
冗長な表現という単位が難しいのでルールにしきれてない感じでした。
一部表現に対応したルールがあります。
用語の揺らぎ
「文章の書き方」の6ページ、「言葉の揺れ」は、文書で使用する単語(用語)が揺れないようにとアドバイスしています。文書で利用される用語に揺らぎがあると、読者が内容を理解できなくなる恐れがあります。RedPen では、SuggestExpression という機能で用語の揺らぎに対処します。用語として使うべき単語と、単語の揺らぎのペアを登録していると、文書に単語の揺らぎが現れた時にエラーを出力します。
さらに @kongou_ae さんが作成されたプラグイン redpen-validator を利用すると、ひらがなと漢字の使い分けなどより詳しく文書を検査できます。
また、句読点などのシンボルも文書内で統一されていない場合があります。読みにくさへ大きく影響はしませんが、見栄えが悪いので統一しましょう。この問題に対して RedPen ではシンボルの誤用を検知する InvalidSymbol を提供しています。
こちらもtextlint-rule-prhでプロジェクトごとに表記揺れの辞書を作っていく形になると思います。または、textlint-rule-terminologyを使うことでも辞書管理が出来ます。
textlintは$ textlint --fix で辞書を元に自動修正ができるようになっています。
そのため、後から表記揺れの辞書を追加してまとめて自動修正するという導入方法も取ることができます。
- style(all): 表記揺れを修正 by azu · Pull Request #124 · azu/JavaScript-Plugin-Architecture
- techbooster.ymlをベースにして漢字の開きなどを後から統一しました。
また、textlint-rule-preset-JTF-styleというプリセットにもひらがなと漢字の使い分けのルールが含まれています。
次の記事でも似たような話が書かれています。
二重否定
二重否定を使用した文は読者の理解を阻害します。「数学文書作法」の 4.2節、「二重否定を避ける」では、二重否定を避ける理由について解説しています。RedPen では DoubleNegative という機能で二重否定の利用を検知します。ただし、実装が十分でないため、検知しきれない事例があります。二重否定が検知できていない例が見つかったら RedPen の Issue に登録していただけますと助かります。
textlintではtextlint-rule-no-double-negative-jaが同様のルールを提供しています。
形態素解析した結果を使い
- なくはない
- ないでもない
- ないものではない
- ないことはない
- ないわけではない
- ないとはいいきれない
- ないとはかぎらない
の二重否定をチェックする機能を実装しています。
以下の論文などを参考に実装した記憶があります。
括弧の利用方法
「文章の書き方」の 25ページ目、「注釈と括弧」では必要でない括弧を削るべきと解説しています。括弧があると文が読みにくくなるのです。残念ながら、RedPen では「必要でない括弧」を識別できません。かわりに、RedPen の ParenthesizedSentence は括弧の用法に制限をかけます。かけられる制限は長さ、入れ子、一文に存在してよい数です。詳しくはマニュアルを参照してください。
textlint-rule-preset-JTF-styleの一部に括弧関連のルールがありますが、textlintもこの辺のルールがありません。
「の」の多用
「文章の書き方」の 29ページ目では格助詞「の」の利用に注意するべきという記載があります。格助詞「の」は名詞を接続する便利な助詞ですが、使うと文が曖昧になります。そのため「の」のかわりに、情報量の多い単語で名詞を接続しましょう。RedPen は JapaneseAmbiguousNounConjunction を提供しています。JapaneseAmbiguousNounConjunction は **格助詞の「の」+名詞連続+格助詞の「の」**という「の」の利用でも曖昧性が生じやすいパターンを検知します。
textlintではtextlint-rule-no-doubled-joshiによって、1センテンスに同じ助詞が連続するケースをチェックできます。
textlint-rule-no-doubled-joshiを入れるとかなりのエラーを見つける事ができると思います。
また、このルールはfalse positiveになりやすいので、判定処理の工夫したり、例外の設定など細かく手を入れています。
Thanks @takahashim.
弱い表現
「かもしれない」などの**弱い表現(ぼかした表現)**は技術文書の持つ正確性を損なってしまいます。弱い表現の利用は十分注意してください。ぼかした表現については「数学文書作法」の 2.5章に記述されています。RedPen では WeakExpression という機能で弱い表現を検知します(英語のみ対応)。日本語についても早期に対応致します。
textlintではtextlint-rule-ja-no-weak-phraseで弱い表現をチェックすることができます。
次のような表現を弱い表現として認識しています。
基本的には辞書ベースにすぎないので、特殊なアルゴリズムがあるわけではないです。
- 〜かもしれない
- 〜と思う
- 〜と思います
あきらかな誤り
以下の項目は指南書では指摘されていないですが、執筆者がやってしまう、あきらかな誤りです。
単語の連続使用
「私ははエンジニアです」のように助詞を連続して書いてしまう場合があります。RedPen は同一単語が連続で使用された箇所を検知する SuccesiveWord という機能を提供しています。
textlintではこのルールがまだありません。
こういうtypoはIMEを使うと多いので、何かいいアルゴリズムがあれば実装したいと思います。
上記の例は助詞が連続していたので、textlint-rule-no-doubled-joshiによって偶然見つける事ができました。
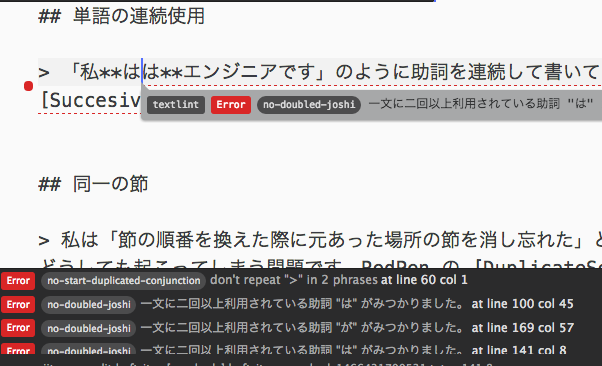
同一の節
私は「節の順番を換えた際に元あった場所の節を消し忘れた」という事例を知っています。これはケアレスミスと言えますが、同時に長い文書を書いているとどうしても起こってしまう問題です。RedPen の DuplicateSectionは類似する節(章)を発見するとエラーを出力します。
このルールはtextlintにはないです。
パラグラフかセンテンスで類似を判定すれば実装できそうな気がします。
ギャップのある節
長い文書を書いていると節間の内包関係に注意がいかず、ミスがおこります。たとえば、以下のサンプルでは 1章の直下に節 1.1.1 が現れています。しかし本来であれば、節 1.1.1 と 1 章の間には節1.1が来なくてはなりません。
= 1章
...
=== 節 1.1.1
=== 節 1.1.2
...
RedPen の GappedSection は節の入れ子関係にギャップがあるとエラーを出力します。
textlintはデフォルトのtxt、Markdownに加えて、プラグインでHTML、rst、簡易asciidoc、Re:VIEWなどをサポートしています。
プラグインで任意のフォーマットをサポートできるのもあって、textlintが定めるAST(Abstract Syntax Tree)では、構造に依存する部分については決めていません。
そのため、セクション周りの構造的なルールはファイルフォーマットに依存していることがあります。
Markdownではtextlint-rule-incremental-headersというルールが同様のことをチェックできます。
- ページの始まりの見出しは#(h1)から始まる。
- ページの始まり以外の見出しで#(h1)が使われていない。(##, ###,...を利用する。)
- 見出しの深さ(h1, h2, h3など)は必ず1つずつ増加する。(h1, h3のように急に深くならない)
指南書での記述が発見できていない項目
以下、書籍や指南書での記述は発見できていないのですが、私が過去に注意された項目です。
ですます調、である調
日本語には「ですます調」、「である調」があります。この二つの調が一つの文で現れると、文書の品質が疑われる恐れがあります。JapaneseStyle は文書に両方の表現が現れるとエラーを出力します。残念ながら、RedPen の JapaneseStyle ではですます調、である調の混在を検知できない事例が報告されています。この問題については早めに解決いたします。
textlintではtextlint-rule-no-mix-dearu-desumasuのルールで「ですます調」、「である調」の混在をチェックできます。
見出し、本文、箇条書き それぞれでどちらを優先するかというオプションも持っています。
見出しは混在させない、本文は「ですます調」、箇条書きは「である調」というような設定ができます。
これもfalse positiveになりやすいので、デフォルトでは形態素解析して文末の語調をチェックしています。
false positiveになりやすい理由としては「ですます調」、「である調」の明確な定義が存在していないからだと考えています。
空の節、章
学術雑誌用の論文を書いていた時のことです。論文のある節の直後で小節を開始したところ、査読者から注意を受けました。注意の内容は「学術雑誌用の論文はスペースが充分あるので、小節が開始するまえに節の要約を入れると読者が理解しやくなる」でした。RedPen が提供する VoidSection は空(小節が列挙されているだけ)の節を発見するとエラーを出力します。
このルールはまだありません。
次のルールが利用できます。
長い漢字の連続
私は昔とある書籍を書いていて、編集者の方から「長い漢字の連続は読みにくい」とい言われました。連続する漢字は、単語の切れ目がわかりにくく読みづらくなります。LongKanjiChainh は長過ぎる漢字連続が使用された箇所を教えてくれます。
textlintではtextlint-rule-max-kanji-continuous-lenでチェックできます。
Further Readingとして書いていますが、デフォルトで6文字以上を「長い漢字」として判定する根拠はありません。
漢字を連続しすぎないことが読みやすさに繋がるという、心理学研究結果はあります。
しかし、この文字数については根拠を見つけられませんでした。
4文字と5文字に壁があり、マージンを取って6文字以上をエラーとする という形でデフォルト値を決めました。
例外のオプションがまだないので、Pull Requestを待っています。
実現できていない機能
以下、未だ RedPen でサポートできていない項目です。今後この記事とともに順次追加してゆく予定です。
* 順接の「が」
* 「代名詞」の多用
* 「も」の多用
* 同一レベルの節が一つしかない
* 受動態の多用
* 疑問文
- 順接の「が」
追記: 順接の「が」ではありませんでした。コメント欄を参照
その他のルールについてはCollection of textlint rule · textlint/textlint Wikiにまとめられいます。
おわりに
著名な文書執筆に関する指南書で述べられている「文書の悪い点」を RedPen で検知する方法について解説しました。今後 RedPen のリリースとともに本文書の内容に修正が加わってゆく予定です。
文書執筆の指南書で解説されている問題点を RedPen で発見する - Qiitaのtextlint版でした。
textlintについて日本語で話すGitterのチャットは以下にあります。
ルールについて気になる事がある人は見てみるといいかもしれません。

現状のtextlintは使いやすさよりも作りやすさを優先したデザインになっています。
これは、自然言語には正解がないため、ルールや拡張の作りやすさを高めた方がより面白くなるという予感を元にした設計です。
そのため、textlint本体は日本語や英語といった既存の言語構造に依存しないように気をつけています。
例えば、ある日突然絵文字言語ができた場合にも、その言語に対してルールを書けるような作りとなっている必要があります。
こういうツールに対しては、「自然言語ってのはコードの正誤ほど簡単に白黒つけられないんだよな〜」といった否定的な見解が避けがたく出てくるものだと思いますが、そうであるからこそ、「唯一の正解」を設けない
textlintで日本語テキストの文字校正を試してみた - the code to rock
また、textlintは類似するアーキテクチャを持つESLintと違い、ビルトイン(コア)のルールすら存在しません。
これは、ユーザーが自らルールを選ばないと、曖昧性のある結果が出た際にツール自体へ否定的な感情を持つためです。
使いやすさよりも作りやすさが優先されるのもこの辺の考えがあるためです。
逆に使いやすさではChrome上で拡張として動くtextlint: 文章チェッカーの方が簡単です。
ルールを書かないユーザーにとっての使いやすさは、また別レイヤーにあると思います。
そのため、目先の目標として文章に対してCIは回すことがもっと身近にすることと、そこから新しい文章設計の手法を考えることです。
- textlintをTravis CIで動かして継続的に文章をチェックする - Qiita
- Travis CIでtextlintの指摘をPull Requestのレビューコメントとして書き込む - Qiita
- JavaScript Plugin Architectureというプラグイン設計について学ぶ無料の電子書籍を書いた | Web Scratch