同じデータをEinstein Discoveryで分析した記事がこちらにあります。
予測ビルダーで同じ分析してみることでEinstein Discoveryと予測ビルダーの製品としての位置付けが説明しやすいのではないかと思って試してみました。
(なお、Spring'19のバージョンをベースに記述しています。)
今回使用するデータ
前の記事と同じkaggleのタイタニックのデータです。
train.csv は生存/死亡の情報がある学習対象です。test.csv はこの項目がない予測対象です。
gender_submission.csv は予測対象の実際の生死情報なので、答え合わせに使います。
手順
-
train.csv(生存情報をもつレコード=学習対象)とtest.csv(生存情報を持たないレコード=予測対象)をカスタムオブジェクトにロード
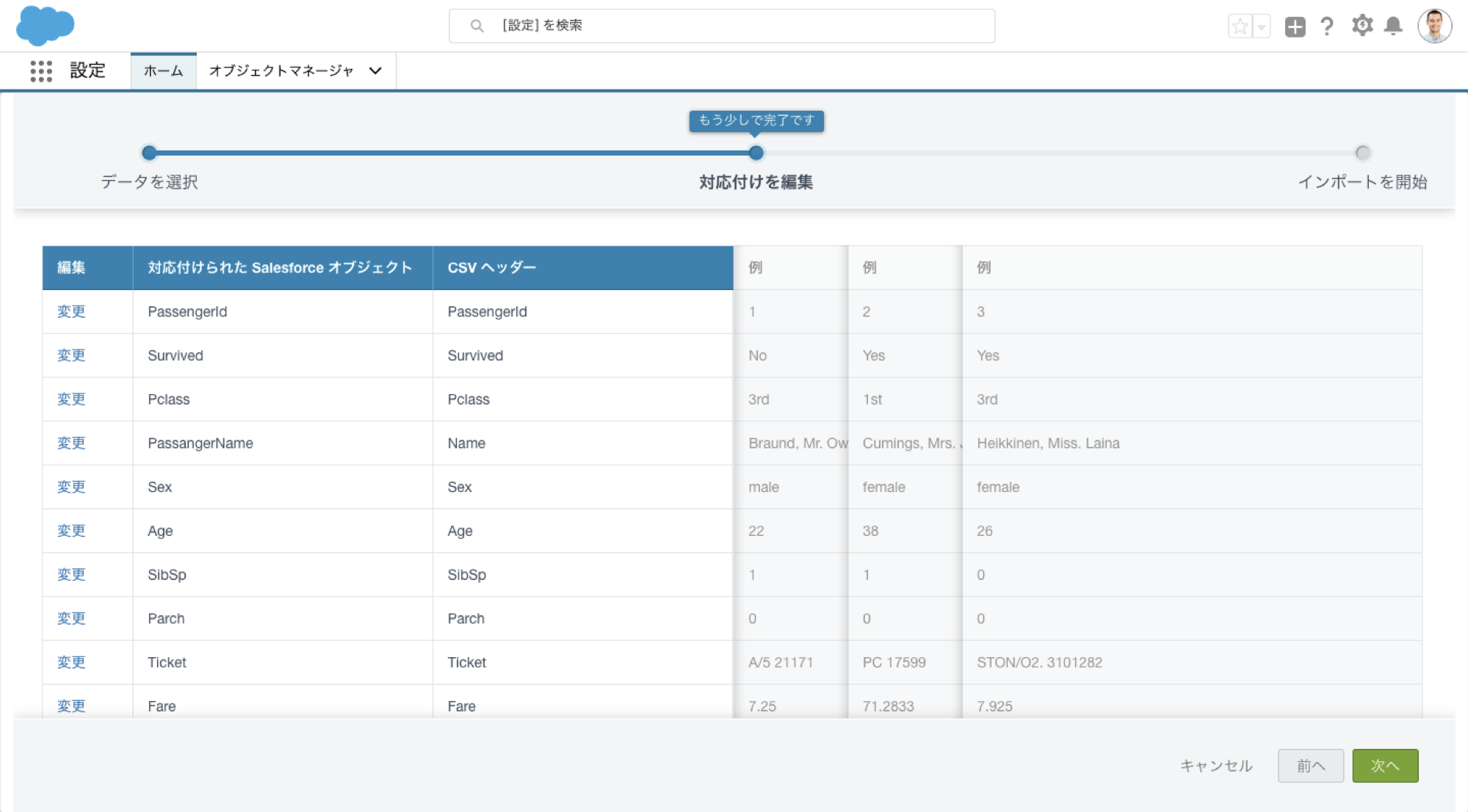
インポート・ウィザードを使いましたが手段は何でも構いません。test.csvをロードした分についてはSurvivedの値はnullになります。 -
チェックボックス(boolean)の数式項目を作成
Survivedの項目がYesのときはtrue、それ以外はfalseとなる数式項目を作ります。これは現在予測ビルダーで予測できるのがboolean値だからです。
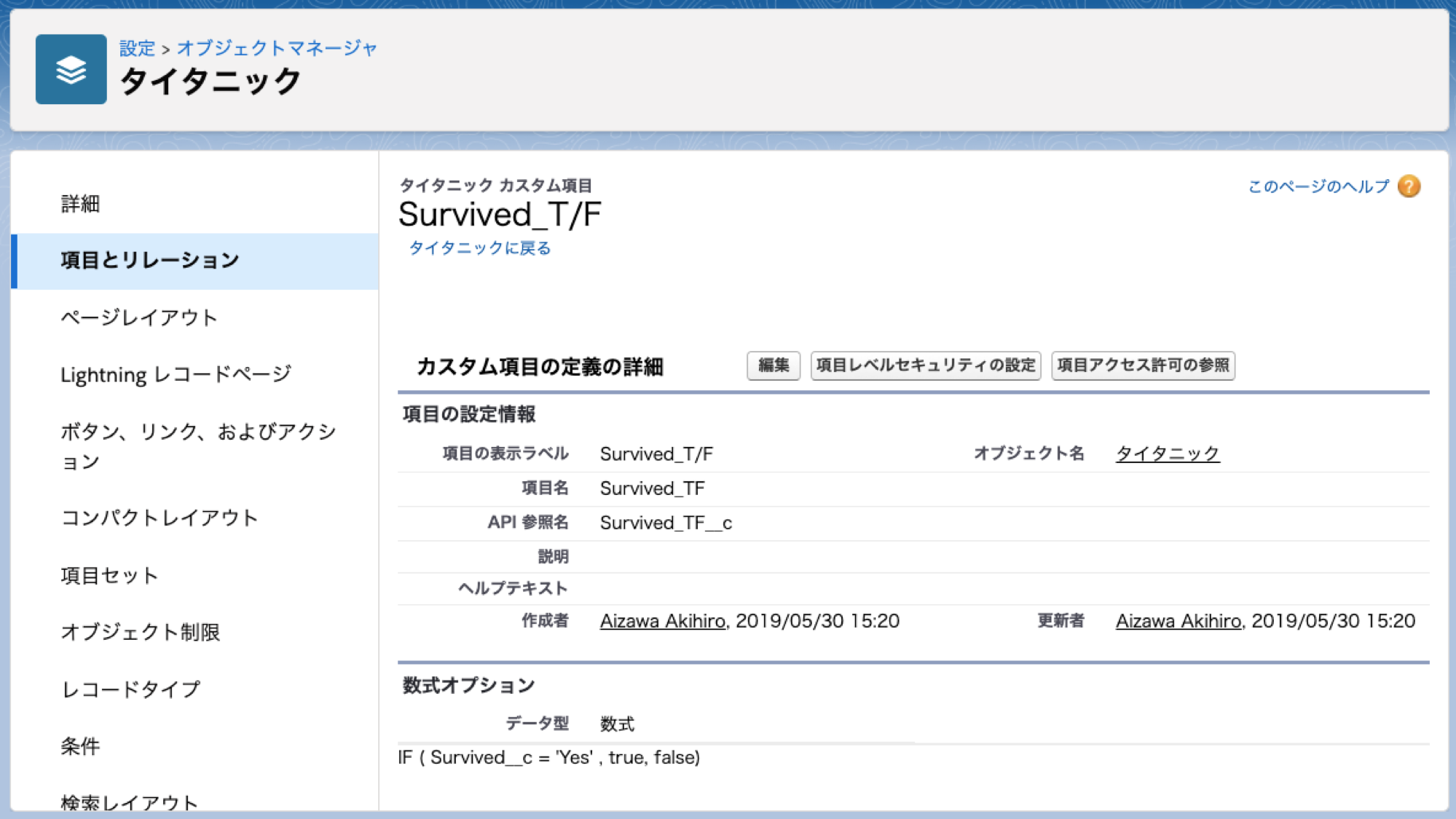
-
リストビューを確認
SurvivedのYes/Noが適切に作成した数式項目に反映されているか確認します。
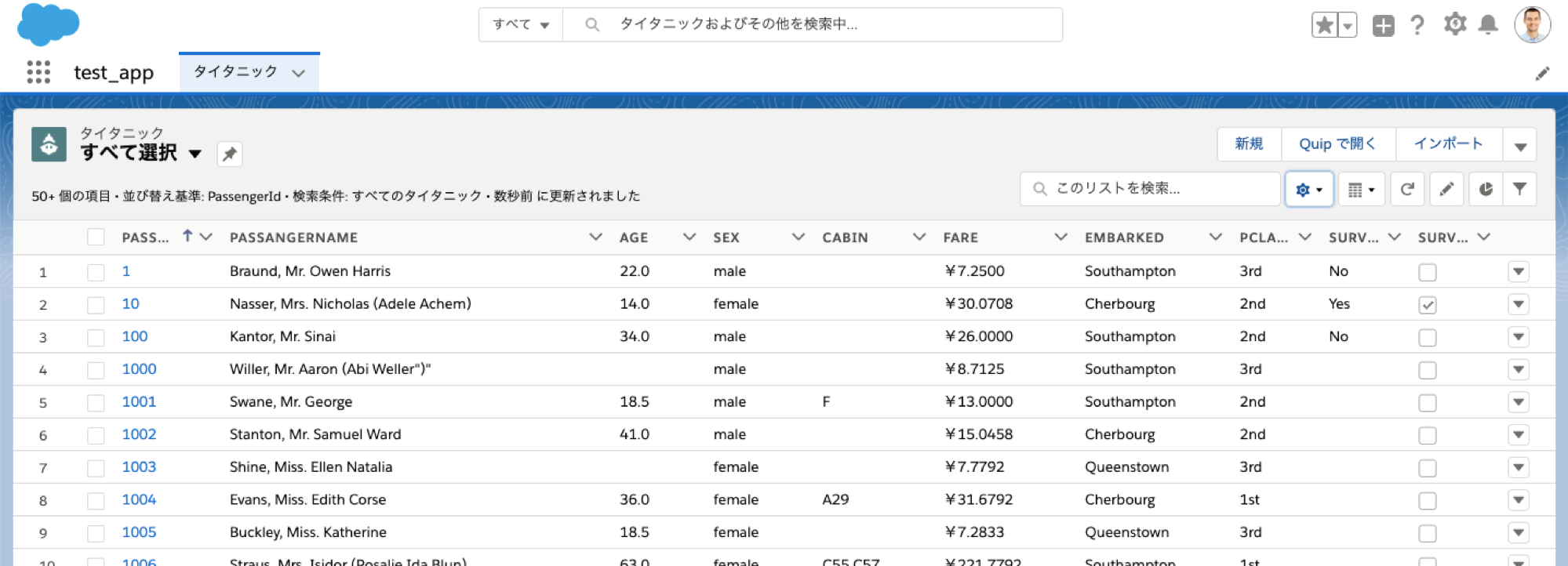
-
設定画面より予測ビルダーをひらきます
ここからが予測ビルダーの操作です。
-
新しい予測を作成します
-
新しい予測に名前をつけます
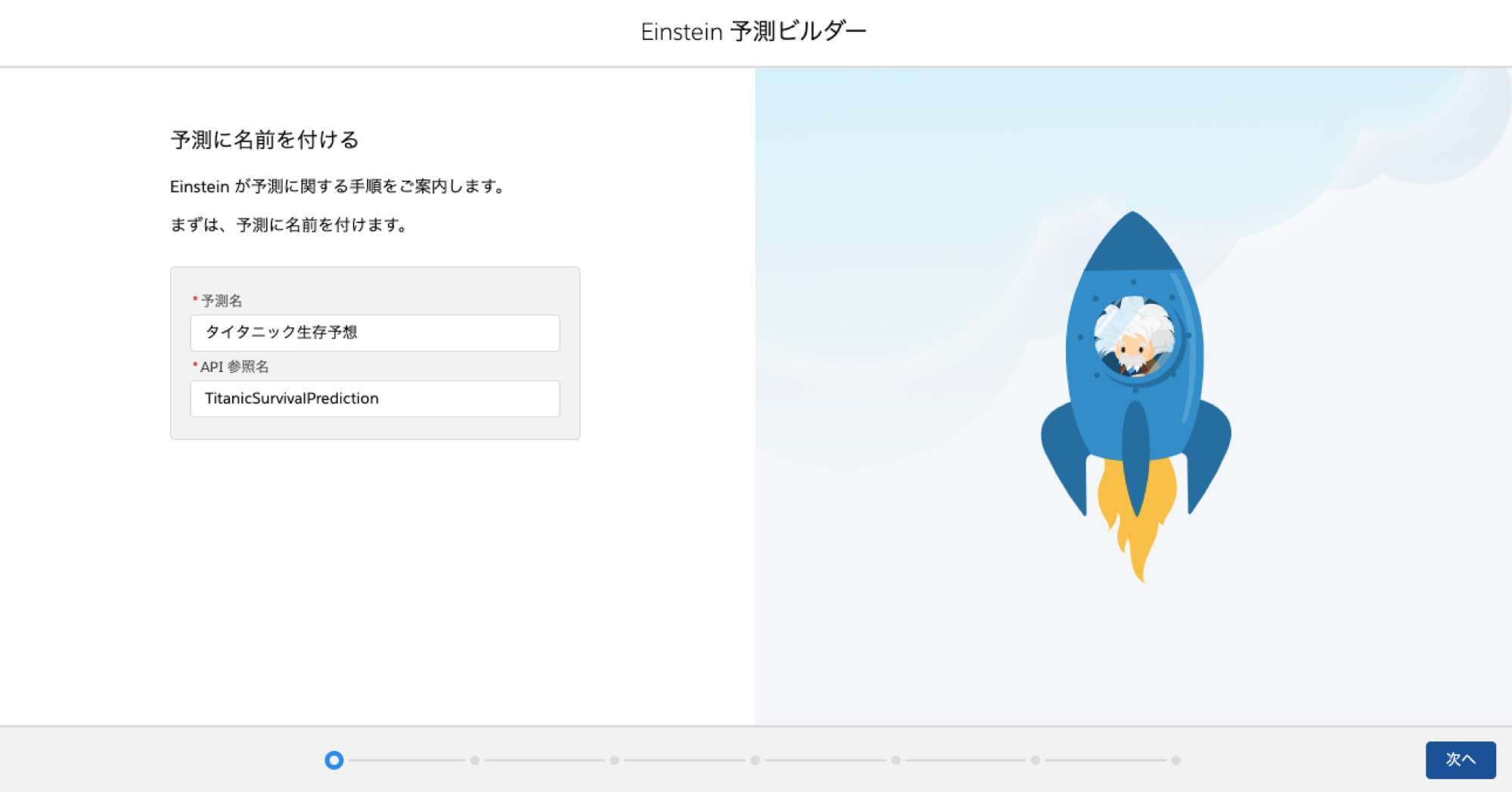
-
予測するオブジェクトを選びます
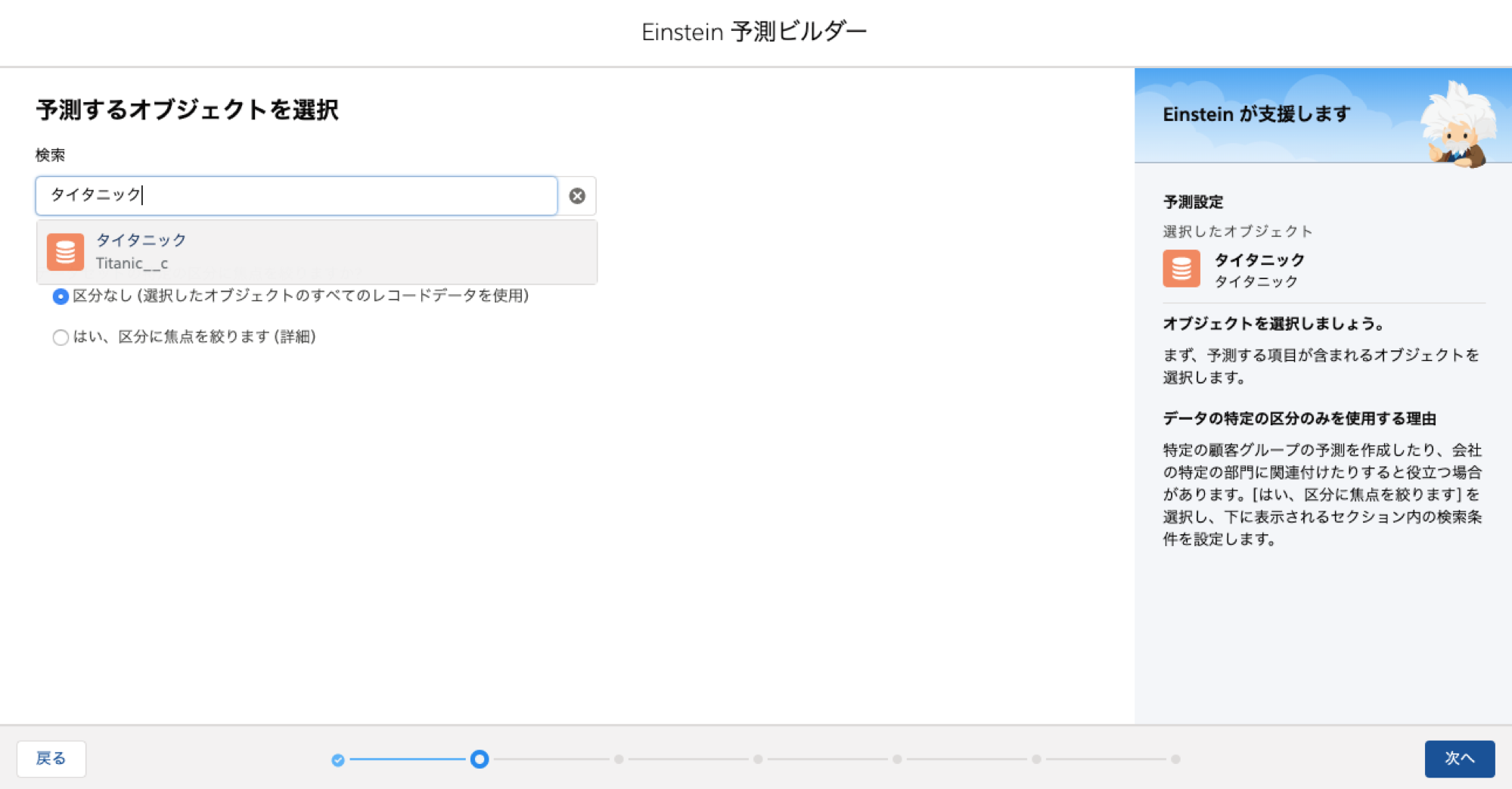
-
予測する項目として先程作成したbooleanの数式項目を選びます
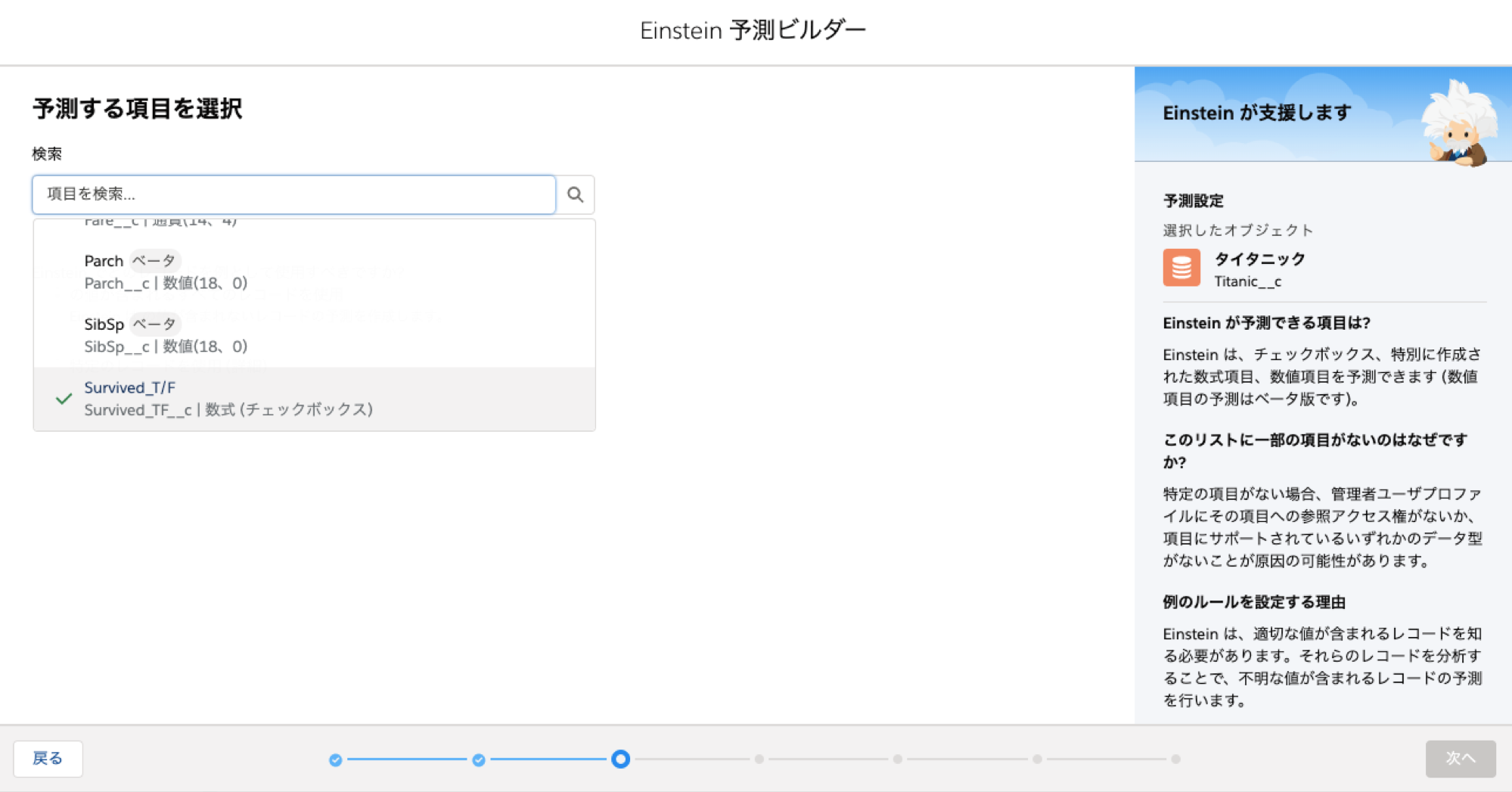
-
サンプルとして使用するレコードを指定します
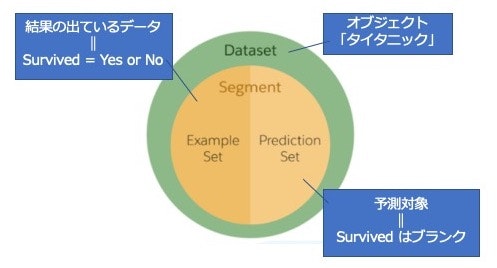
SurvivedにYes/Noいずれかが入っているレコードを対象とします。予測対象レコードはそれ以外のレコードです。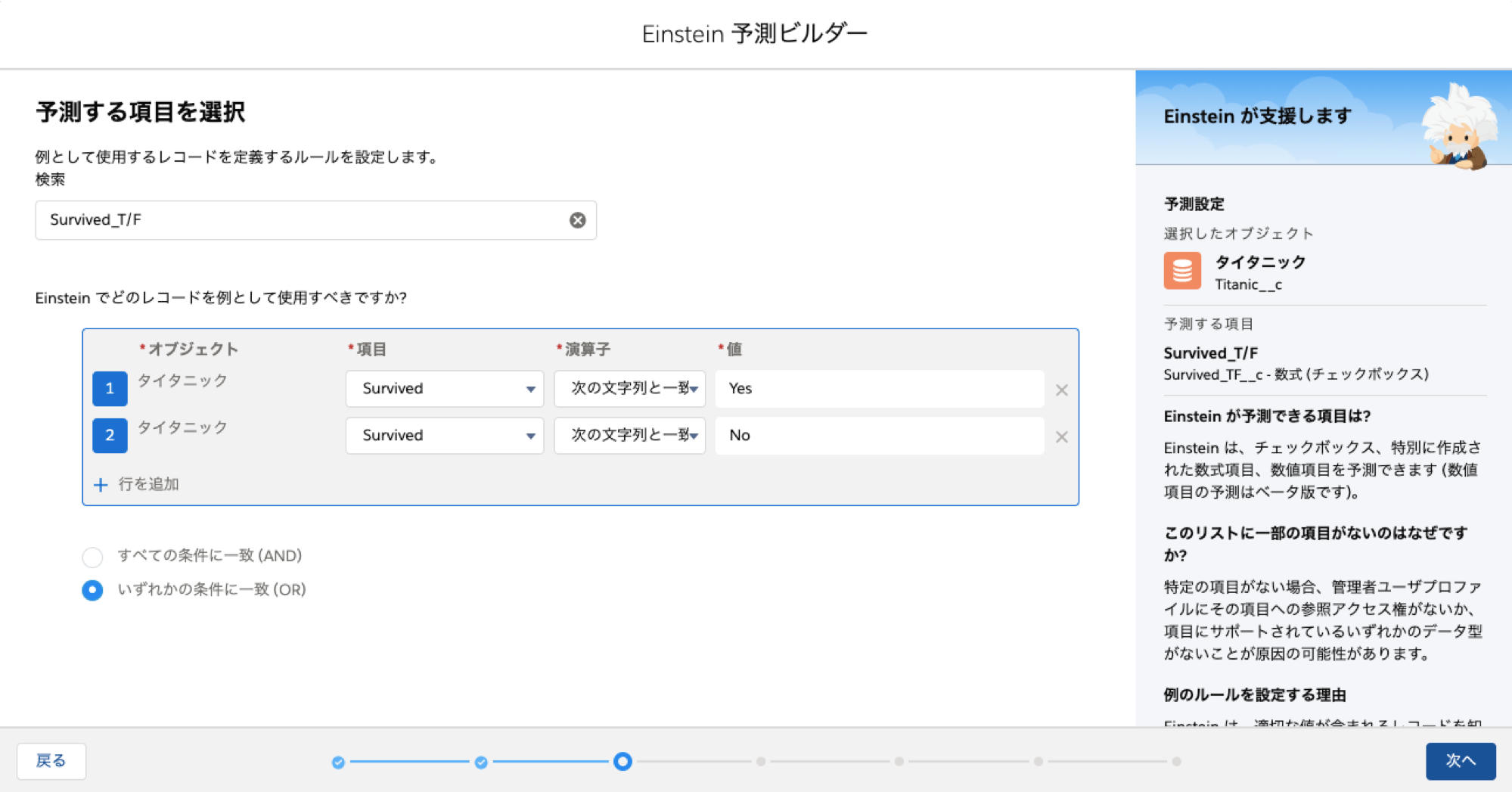
-
予測の基準となる項目を選択します
Salesforceレコードの作成者や所有者は今回の場合明らかに無関係ですので、そういった項目は外します。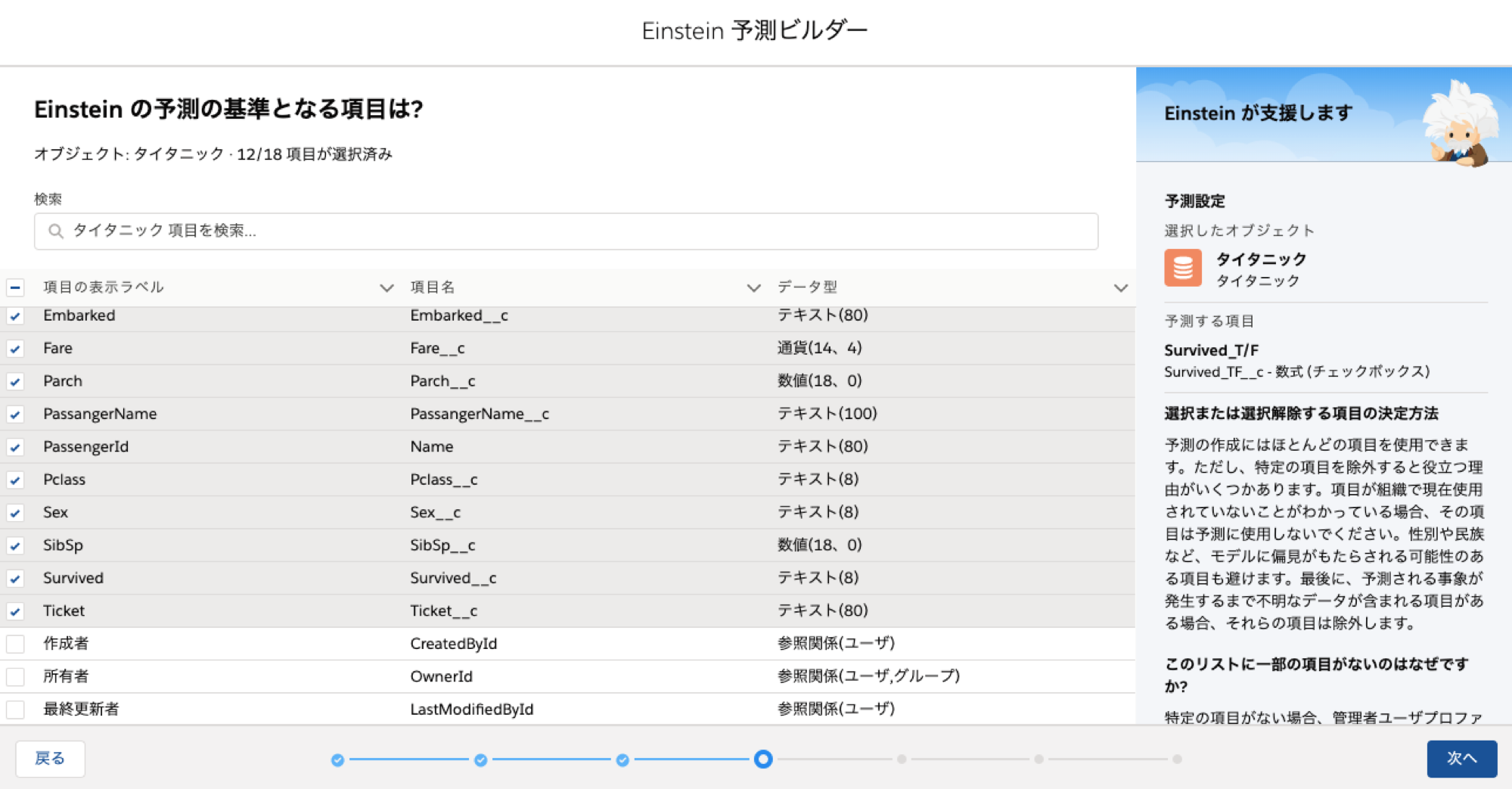
-
結果を保存する項目名を指定します
予測ビルダーは結果をカスタム項目に出力しますので、その項目を指定します。存在しない場合は予測ビルダーの方で作成しますので、事前に作成しておく必要はありません。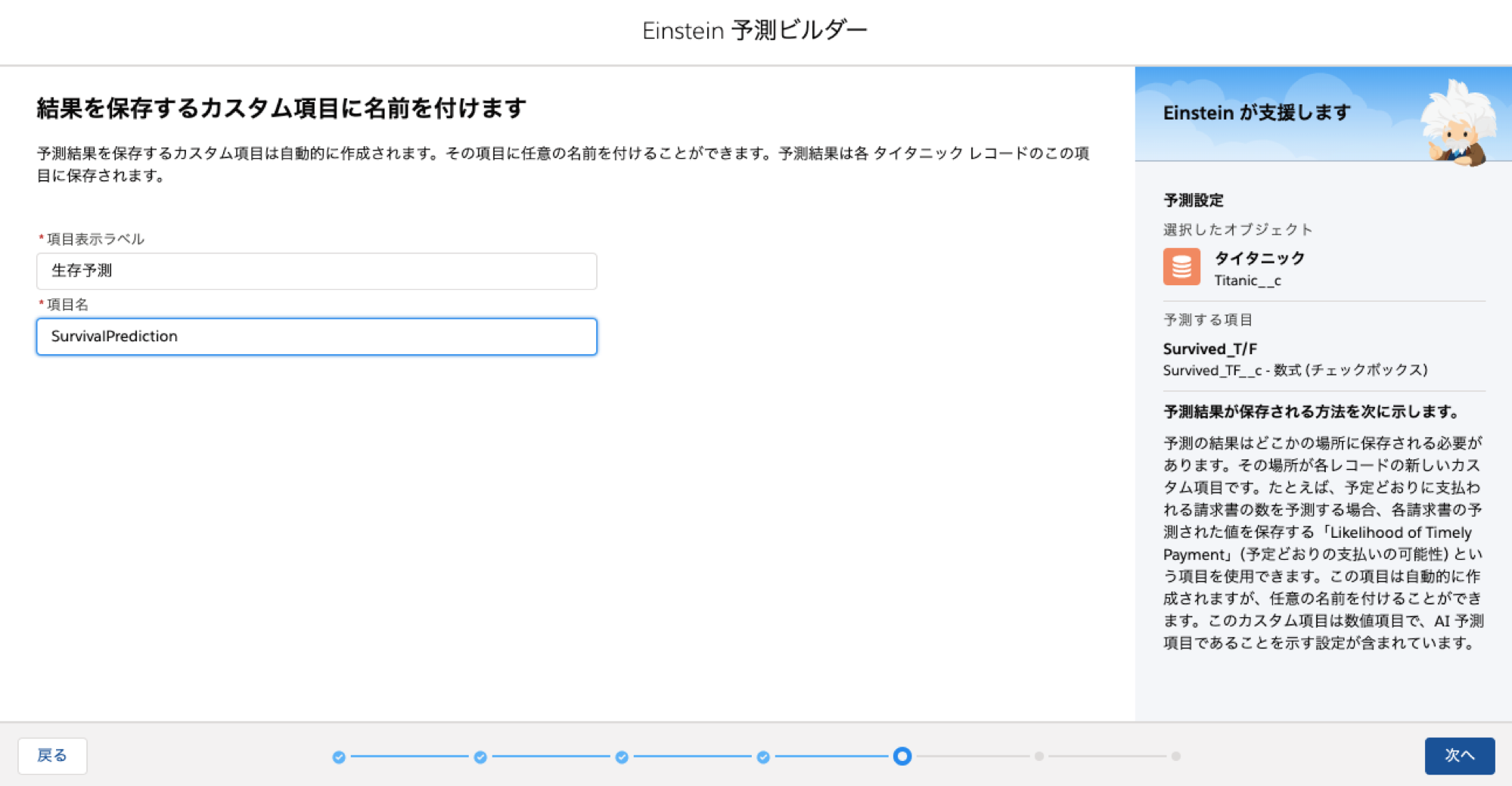
-
今までの設定を確認し予測を構築します。
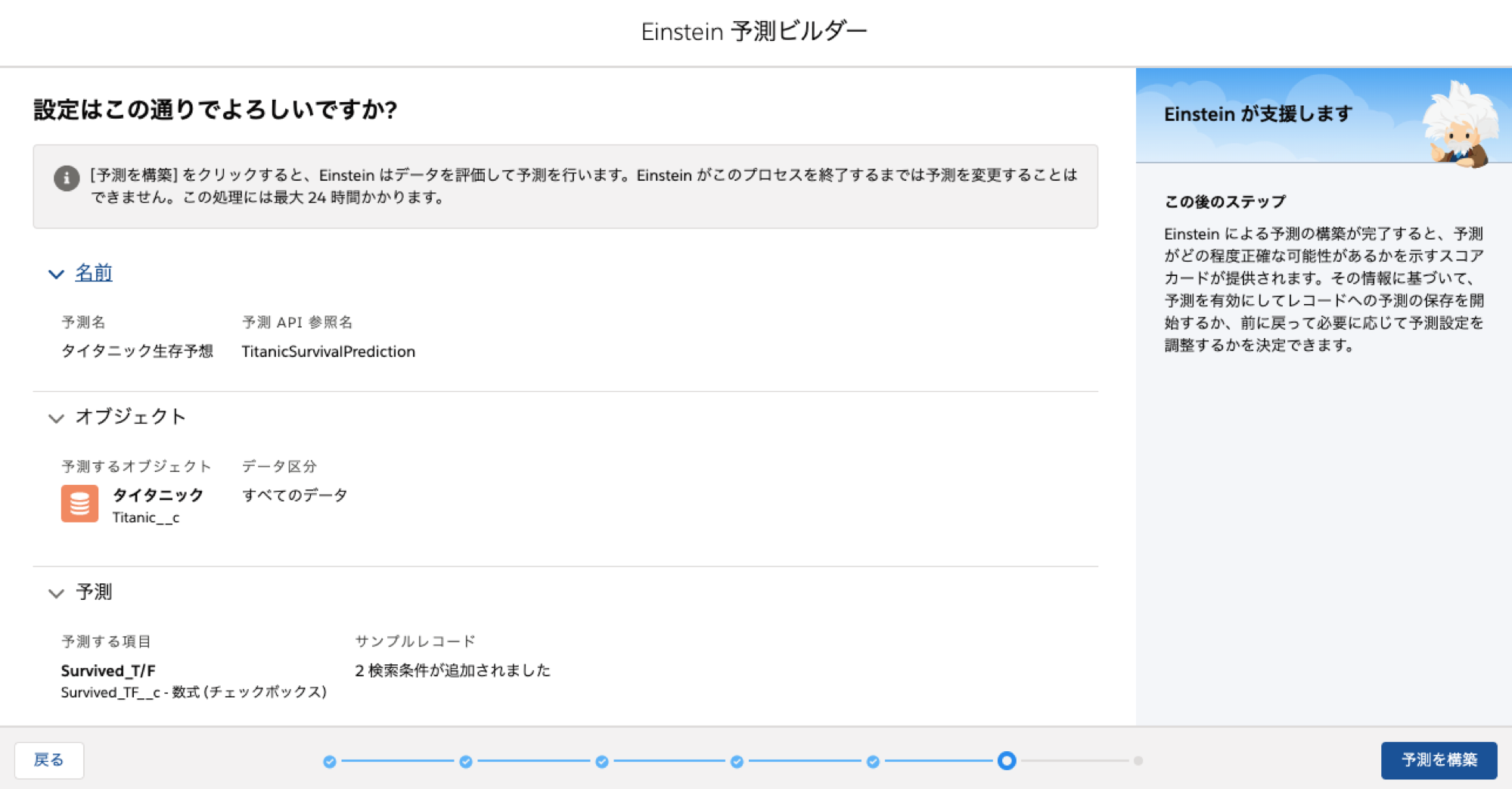
-
構築には時間がかかります。
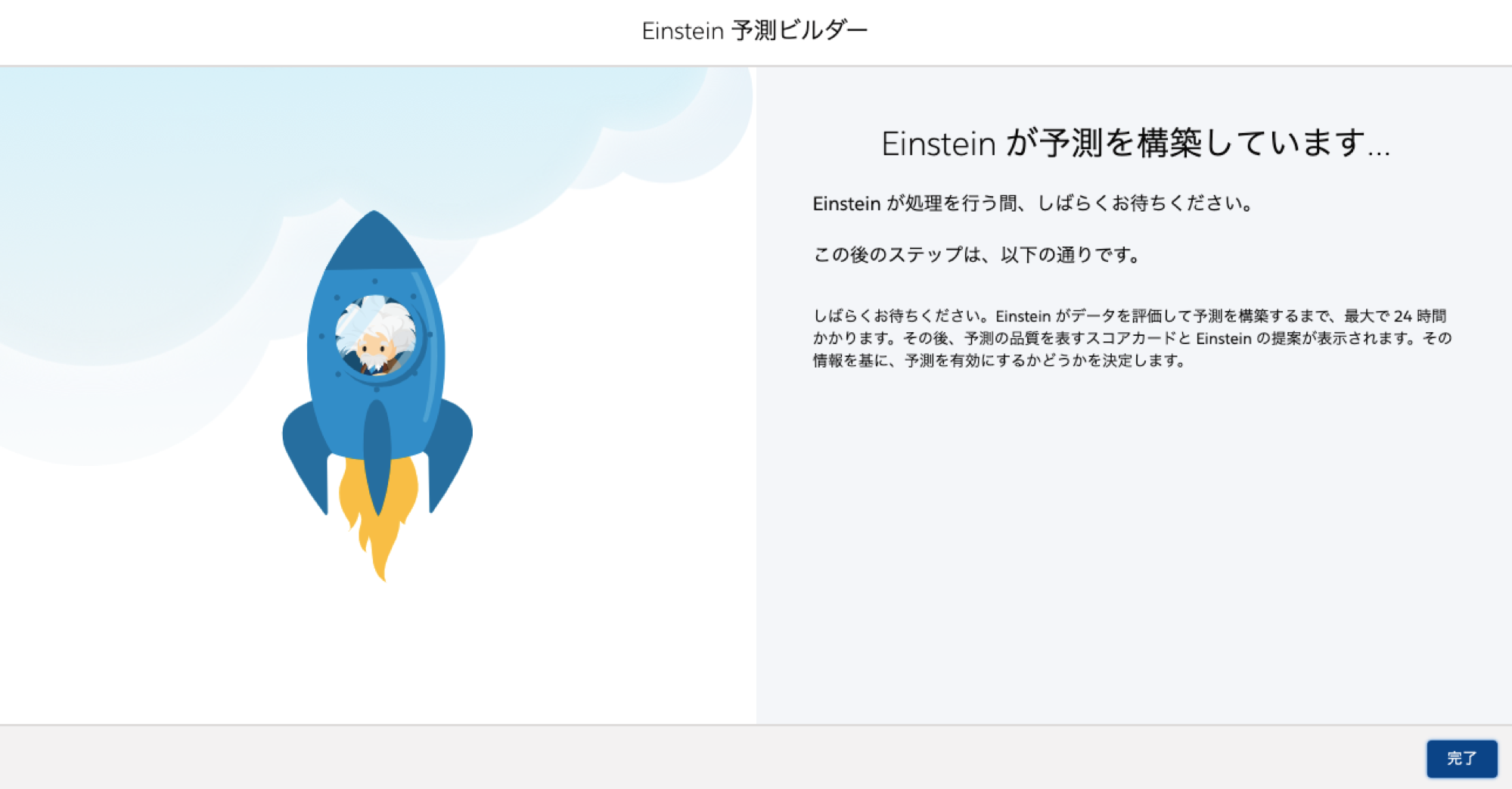
構築中は状況が「待機中」となります。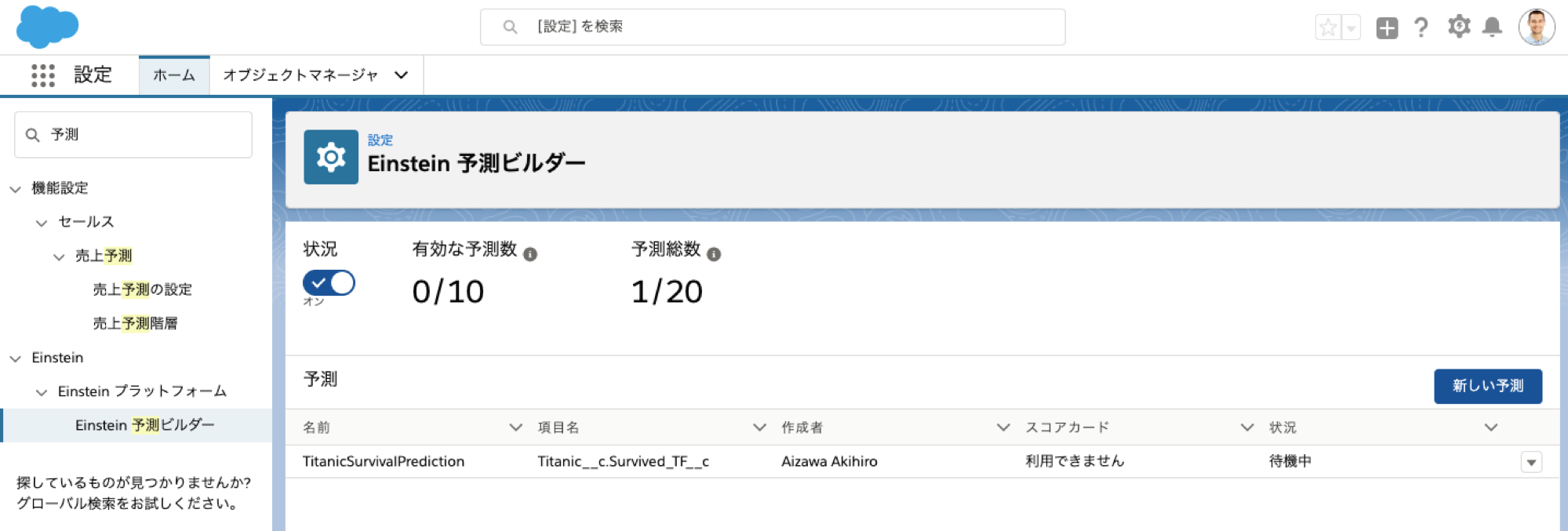
-
構築が完了しました
通知によって気づくことができます。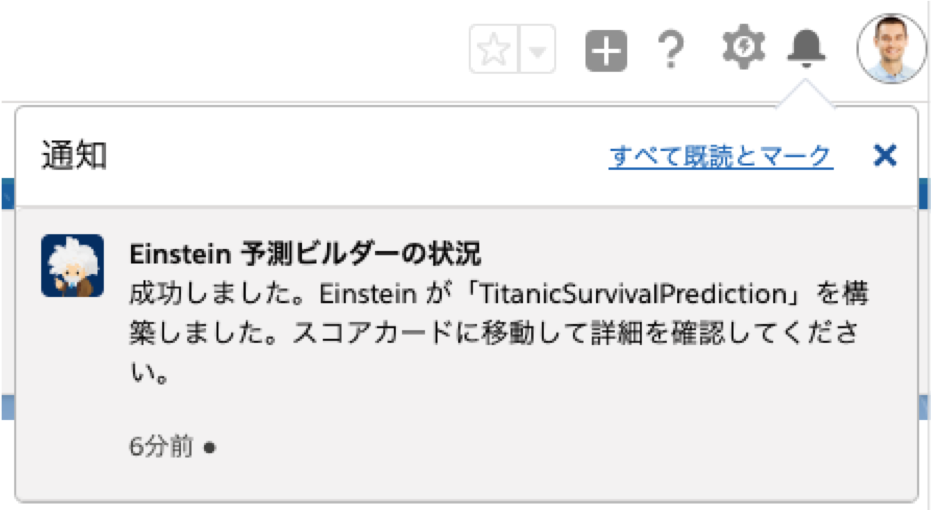
状況が「レビュー準備完了」に変わりました。
-
スコアカードを表示してみます
予測品質は素晴らしいということなので一安心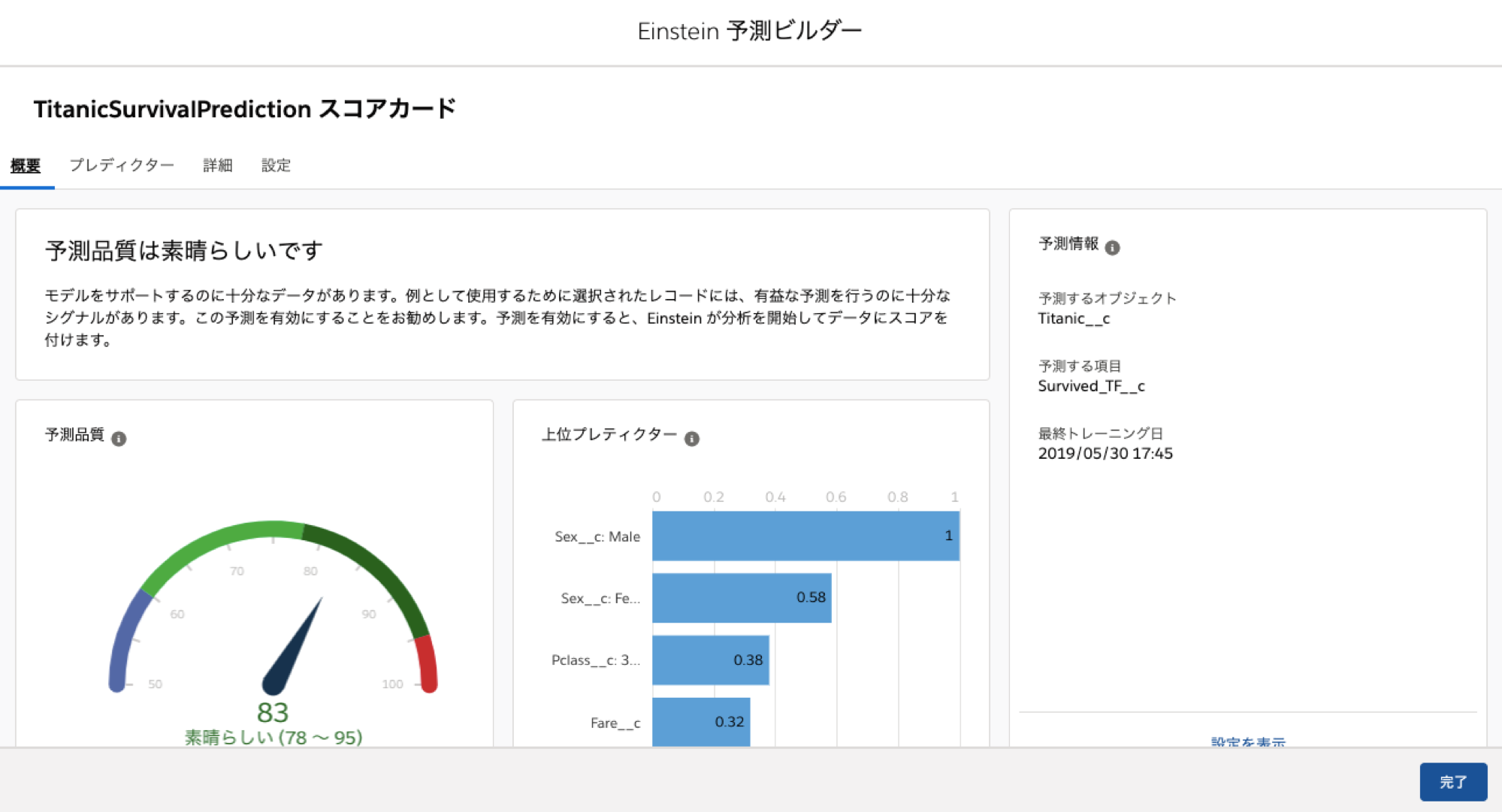
-
有効化します
結果が指定したカスタム項目に書き込まれます。これに少し時間がかかることがありますが、落ち着いて待ちましょう。
-
結果を確認します
リストビューに予測結果の項目を追加しました。Survivedがnullのレコードに対し結果が書き込まれています。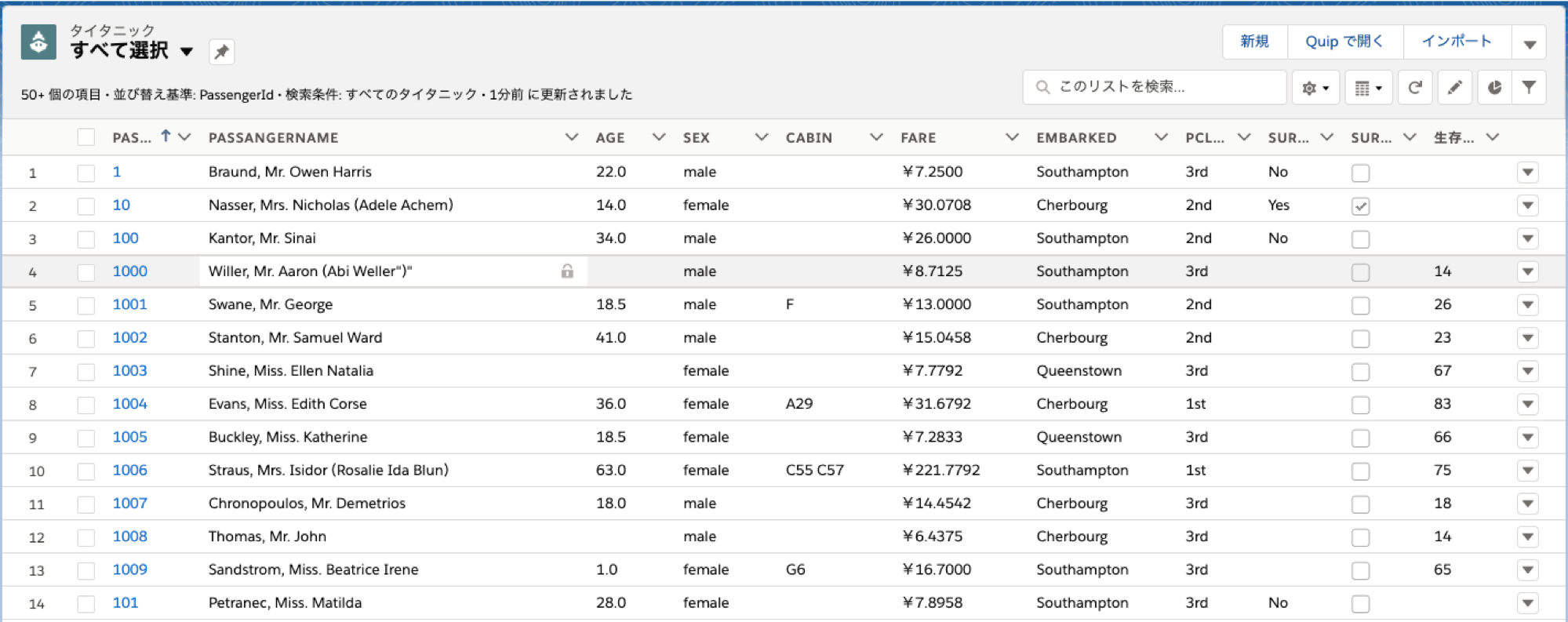
確かに女性の生存率が高く出ています。
答え合わせ
IDをマッチングさせてgender_submission.csvの生死情報を新規カラムにロードします。50を閾値として生存/死亡の予想とみなすと以下のような正答率になります。
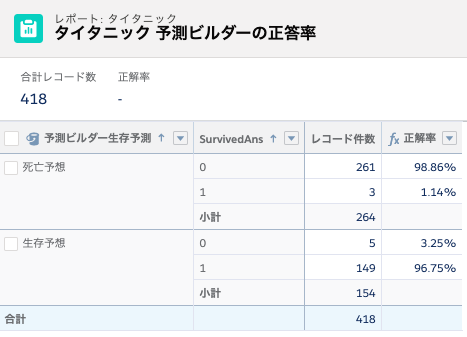
死亡と予想していた人の98.86%が実際に死亡していて、生存と予想した人の96.75%が実際に生存したという結果になりました。
Einstein Discoveryとの違い
現時点では予想する項目値はtrue/falseのboolean値であるということはありますが(数値項目はベータ)、それ以外の大きな違いは以下のようになると思います。
ストーリーがない
スコアカードを見れば影響が大きいと判断した予測因子はわかりますし、
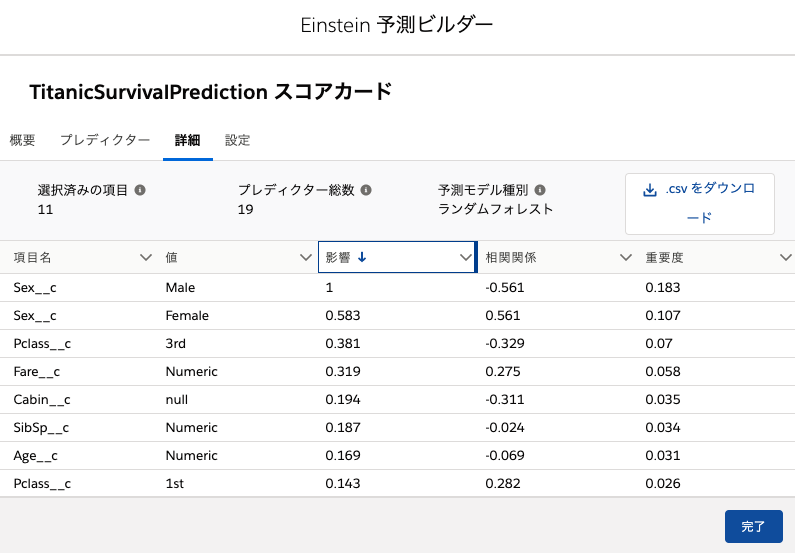
影響がプラスに働いたかマイナスに働いたかもわかります。
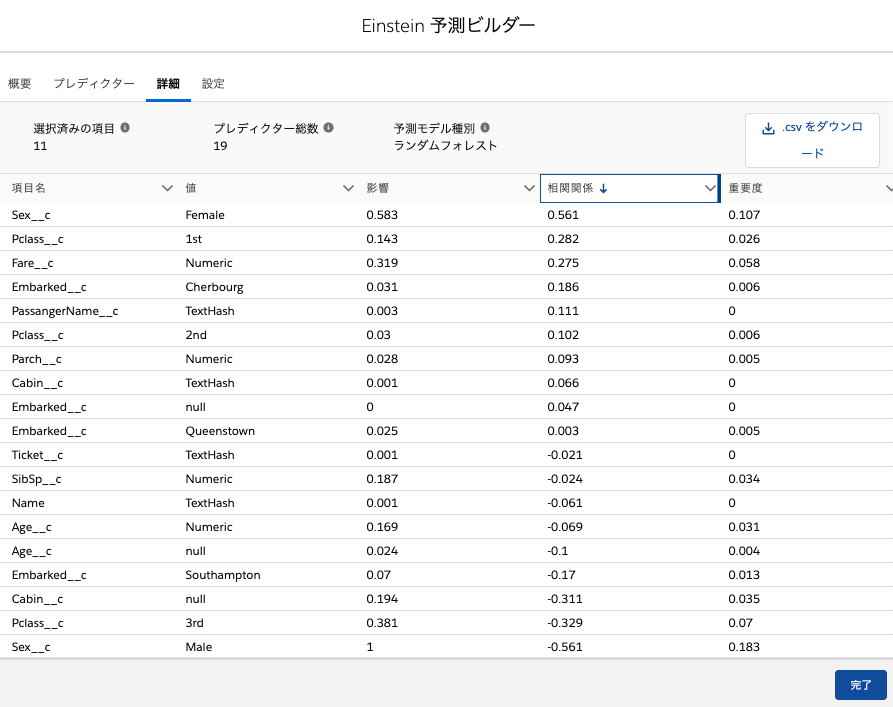
ただし、男性グループの中でも16歳以下の生存率は高い、といった分析は明示してくれません。
評価理由・改善のための推奨事項を明示しない
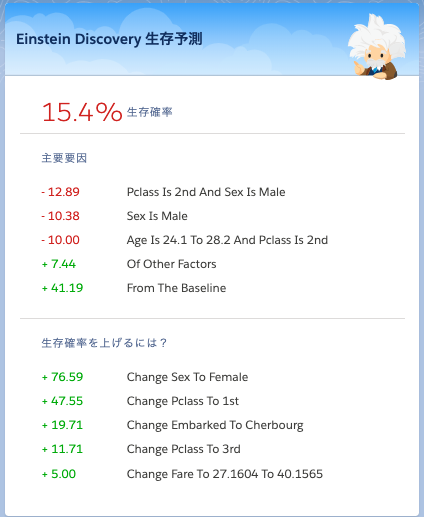
予測因子をどのように評価してこのような予測を行ったのか、改善に効くポイントは何なのかといった推奨事項は表示してくれません。下図はEinstein Discoveryの出力例です。
再予測は即時実行されない
Einstein Discoveryではレコードを変更すると即時に再予測することができますが、予測ビルダーの予測項目更新は1時間程度のタイムラグがあります(再予測されない訳ではありません)。下図はEinstein Discoveryでもし女性だったら生存確率がどの様になるか試してみた様子です。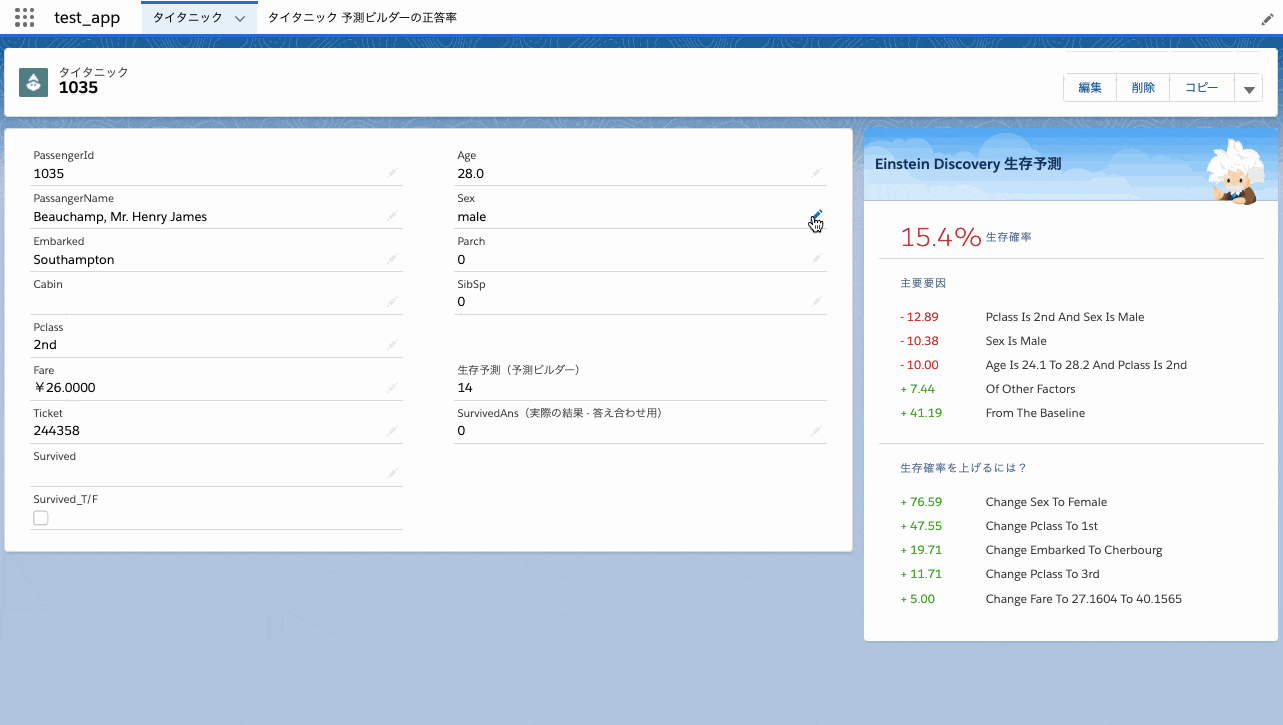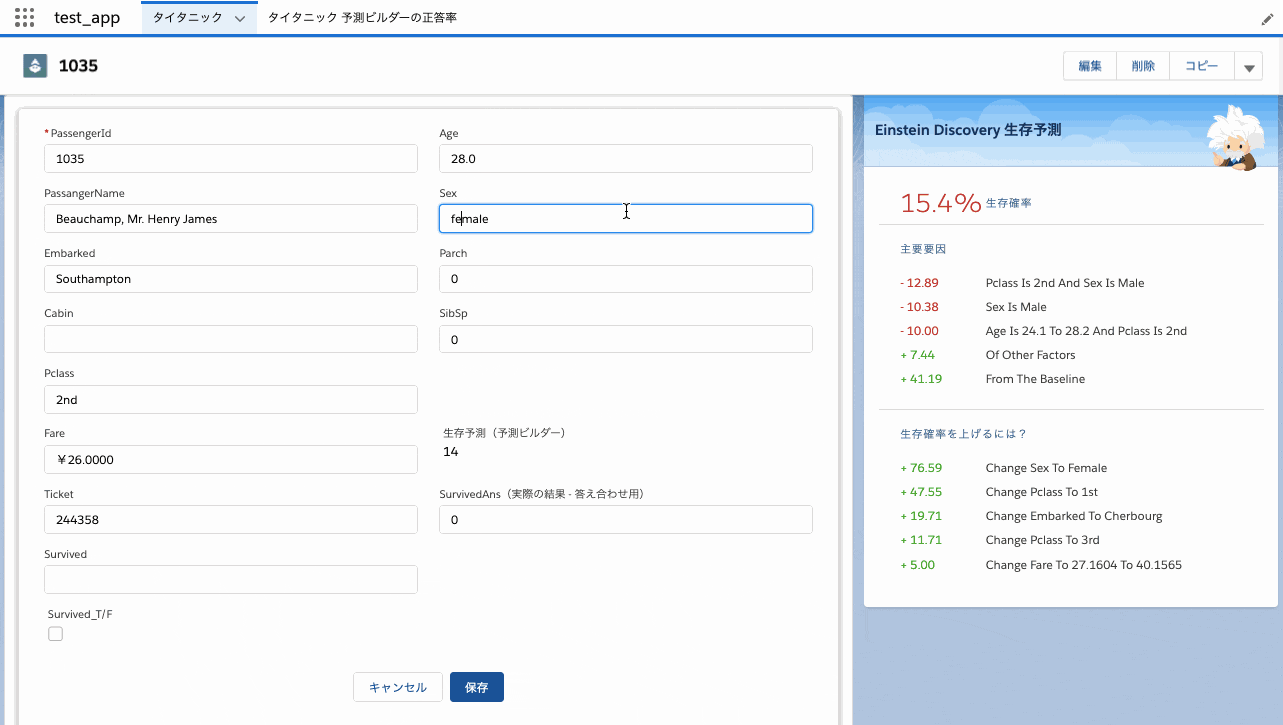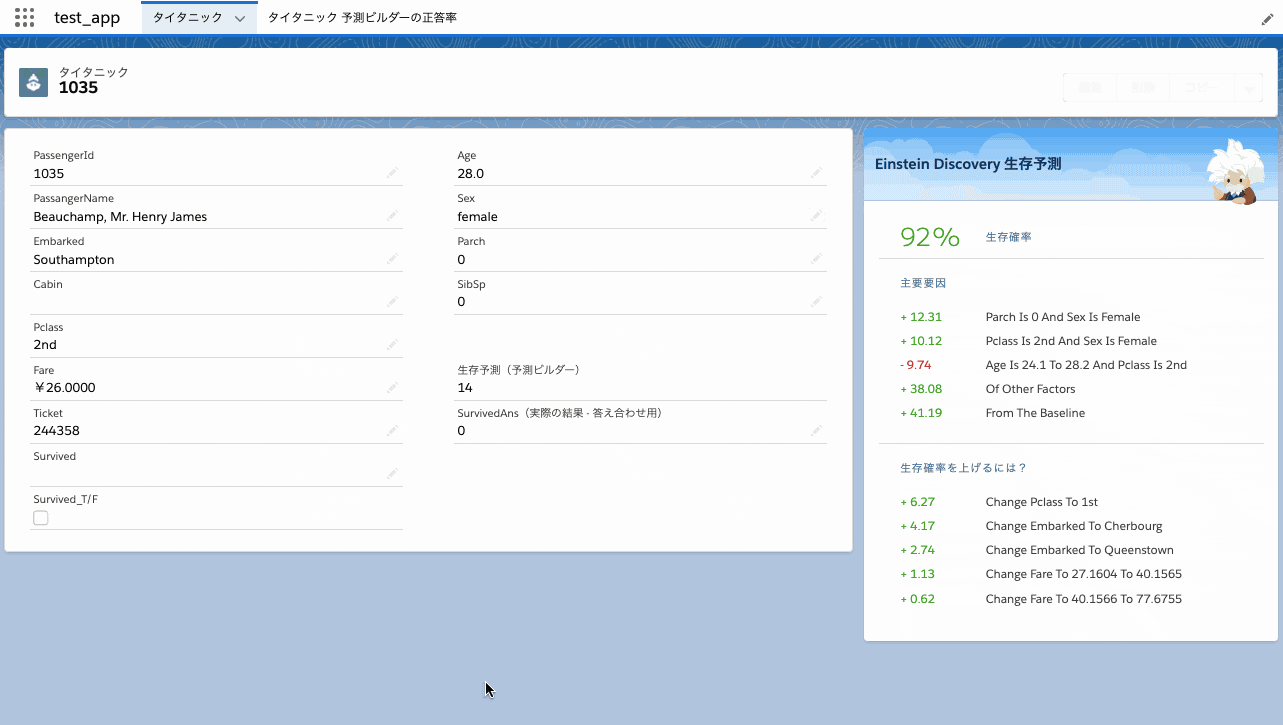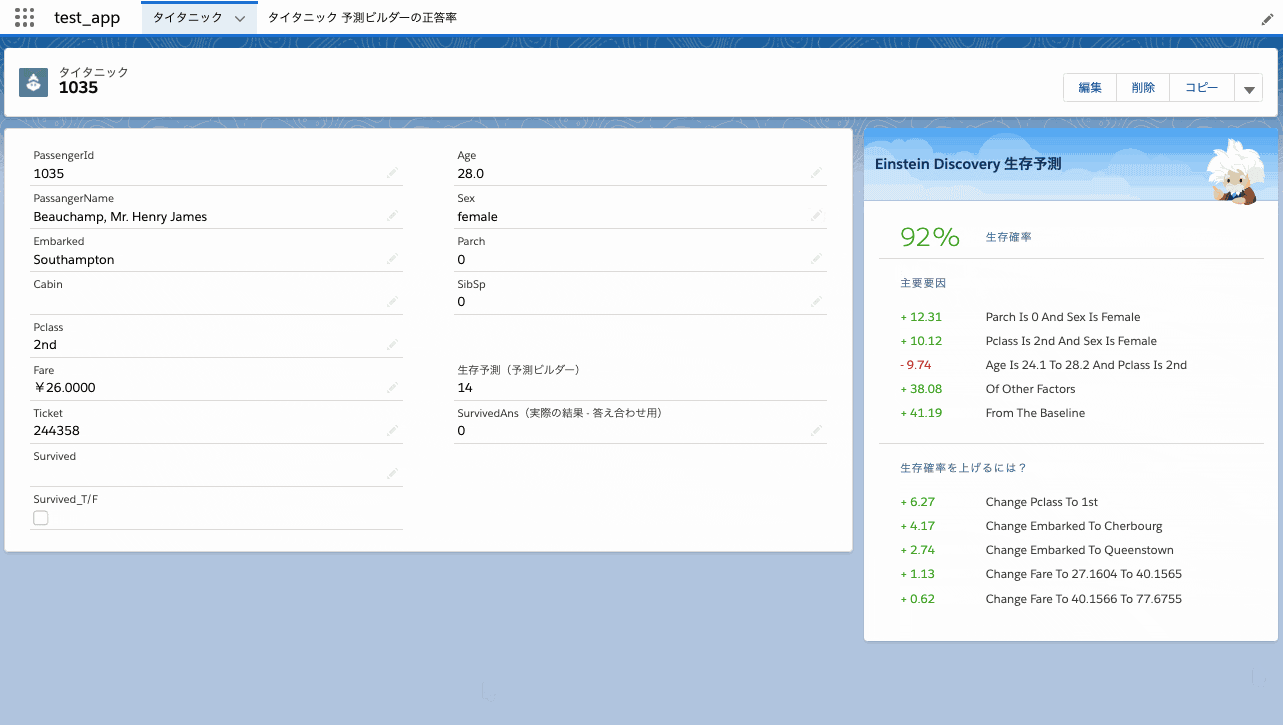
まとめ
Einstein Discoveryでないとできないことは当然あるわけですが、とにかく簡単に予測を作れることが魅力です。データセットを作成する必要もありませんし、オブジェクトの項目に結果が書かれるのでwritebackなどの設定も不要です。
Trailheadではレストランの予約がキャンセルされるか、支払いが遅延するか、といったユースケースで課題が作成されています。ご自身のデータでも役に立つユースケースがないか一度考えてみると面白いかもしれません。