日本語の半角全角特殊文字問題
英数字
聞くところによると、公共の組織においては、一桁は全角、二桁以上は半角で入力するというルールがある (あった?) そうです。「平成30年 (半角) と令和3年 (全角) って、なんでやねん!」と思ったら、そういうことだったのか・・・。(そもそも西暦にしてほしい)
あと、部署名で使われがちな IT とか DX とかも、半角全角混ざりがちですね。
カタカナ
「半角カナはエラーの元」ということで使用しないのがIT業界の常識ですが、一般の人にとっては半角カタカナは狭いセルに文字を詰め込む便利文字。というわけで、名簿やアンケートなどに半角カタカナが混ざっていることがあります。
特殊文字
前株/後株で異なる会社だったりもするので、入れてくれるのはありがたいのですが、㈱とか㍿とか、特殊文字は使わないでほしいのです。㍿はともかく、① なんかは当たり前に使われてます。
これらの例は、表記ゆれにより同一データを同一とみなせなくなるので、データ分析において問題となります。
また、本来同じデータなのに別と扱われるとで、データの圧縮効率も低下します。
これらの理由から、できるだけ早い段階でデータとして無意味な違いは解消するのが望ましいです。可能ならデータ入力の段階から排除したいところですが、いただいたデータに文句は言えないので、加工する方法を考えます。
Power Query ではどうか
Power Query では残念ながら、そのような変換ができる関数は実装されておりません。カスタム関数を作れるので、一度作ってしまえばコピペまたはテンプレートにして流用は可能です。
数字だけなら10個定義するだけなので、まだ力づくで頑張れるのですが、アルファベット、カタカナ、特殊文字...となると、心折れますよね。
半角・全角・特殊文字を変換する関数を持つ言語
ブラウザ (Edge) で「半角 全角 変換」と検索したら、Copilot が変換用の Python コードを教えてくれました。その中で使っていたのがこちらです。
unicodedata.normalize('NFKC', text)
unicodedata.normalize('NFKC', text) は、Python の unicodedata モジュールを使って、Unicode 文字列を正規化するための関数で、全角文字を半角に変換したり、特殊文字を標準文字に変換したりします。
というわけで、Python であれば一括で、全角英数字を半角にしたり、半角カナを全角カナにしたり、㈱ などの特殊文字を 株 に変換したりできます。
「正規化」って、データベース用語だと思ってたんですけど、それとはまた別の意味があったんですね。
ちなみに、データベースで言う「正規化」は、Power BI ユーザーにはおなじみの スタースキーマ を作る時に出会う言葉で、できる限りデータの重複を削除することです。スタースキーマにおいては、ファクトはできる限り正規化し、ディメンションは非正規化します。
じゃあ Python とやらを使ってみようかと思っても、Power BI ユーザーからするとハードルが高いですよね。
ところが、Power BI の発展形である Microsoft Fabric なら、そんな Python コードも簡単に利用できてしまうのです。
Python コードの使い方
AI によって生成された Python コードを実行するには、Fabric の ノートブック を使用します。コードを試すだけなら、コピペして実行ボタンを押すだけです。
ノートブックは対話型コンピューティング環境であり、ユーザーはライブ コードや数式、グラフ、説明テキストを含むドキュメントを作成して共有できます。 Python や R、SQL、Scala など、さまざまな言語でコードを書いて実行できます。
Fabric を使用するための前提条件
- ワークスペースのライセンス モードが Premium/Fabric 容量に設定されている
- テナントの設定あるいはワークスペースが紐づいている Premium/Fabric 容量の設定で [ユーザーは Fabric アイテムを作成できます] が有効化されている
-
ワークスペースで [+ 新しい項目] → [ノートブック] とクリックします
-
右側の広いエリアの英語が書かれているところ (「セル」と言います) に、生成された Python コードを貼り付けます
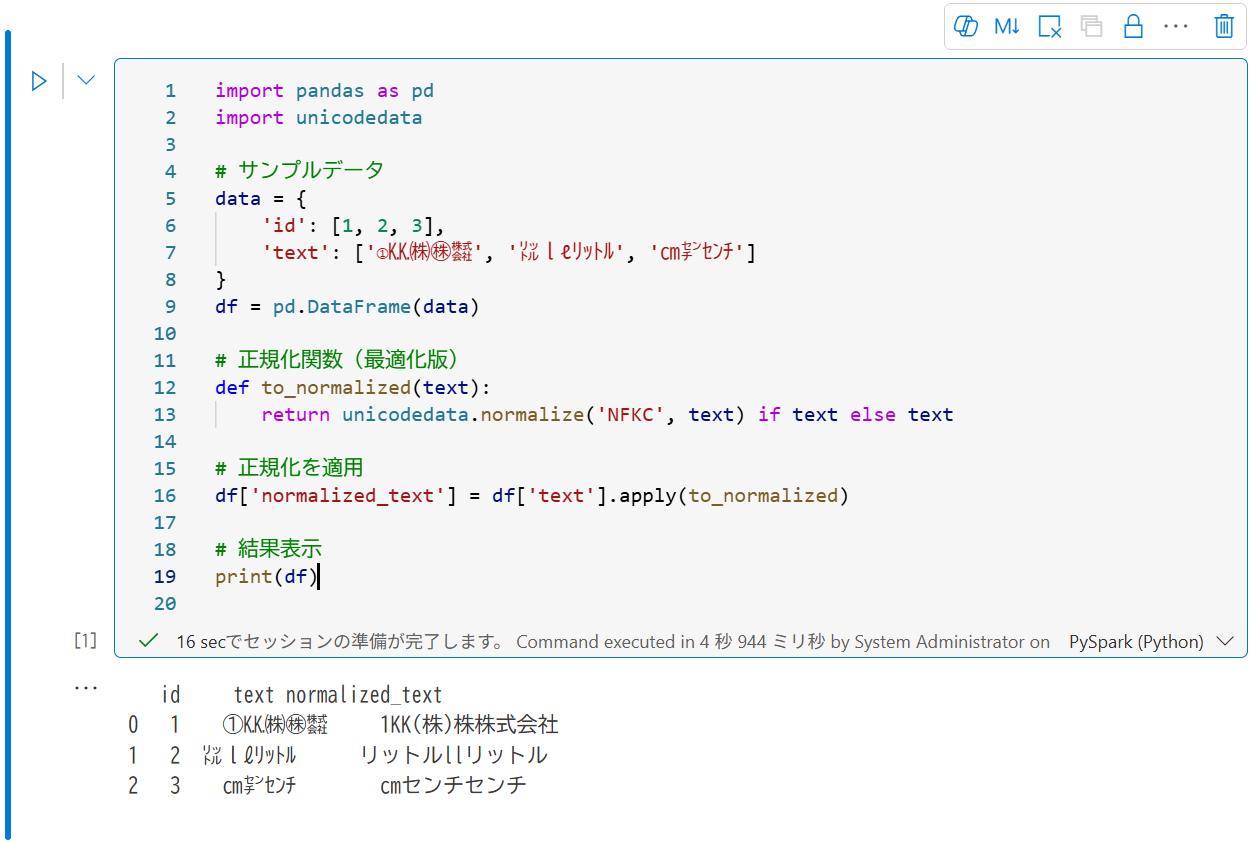
import pandas as pd import unicodedata # サンプルデータ data = { 'id': [1, 2, 3], 'text': ['①㏍㈱㊑㍿', '㍑lℓリットル', '㎝㌢センチ'] } df = pd.DataFrame(data) # 正規化関数(最適化版) def to_normalized(text): return unicodedata.normalize('NFKC', text) if text else text # 正規化を適用 df['normalized_text'] = df['text'].apply(to_normalized) # 結果表示 print(df) -
セルの左上にある▷ボタンを押すと、Spark の環境が立ち上がって、コードが実行されます。19行目で結果表示するようにしているので、終了するとセルの下に実行結果が表示されます。
Python はかなりメジャーなので、「このコードを初心者にもわかるように詳しく解説して」とか「CSV ファイルから変換するにはどうするの?」とかの質問にも気さくに答えてくれます。どこの AI を使っても、だいたい良い感じにコードを生成したり、コードの解説をお願いしたりできるので便利です。
CSV ファイルを変換したい
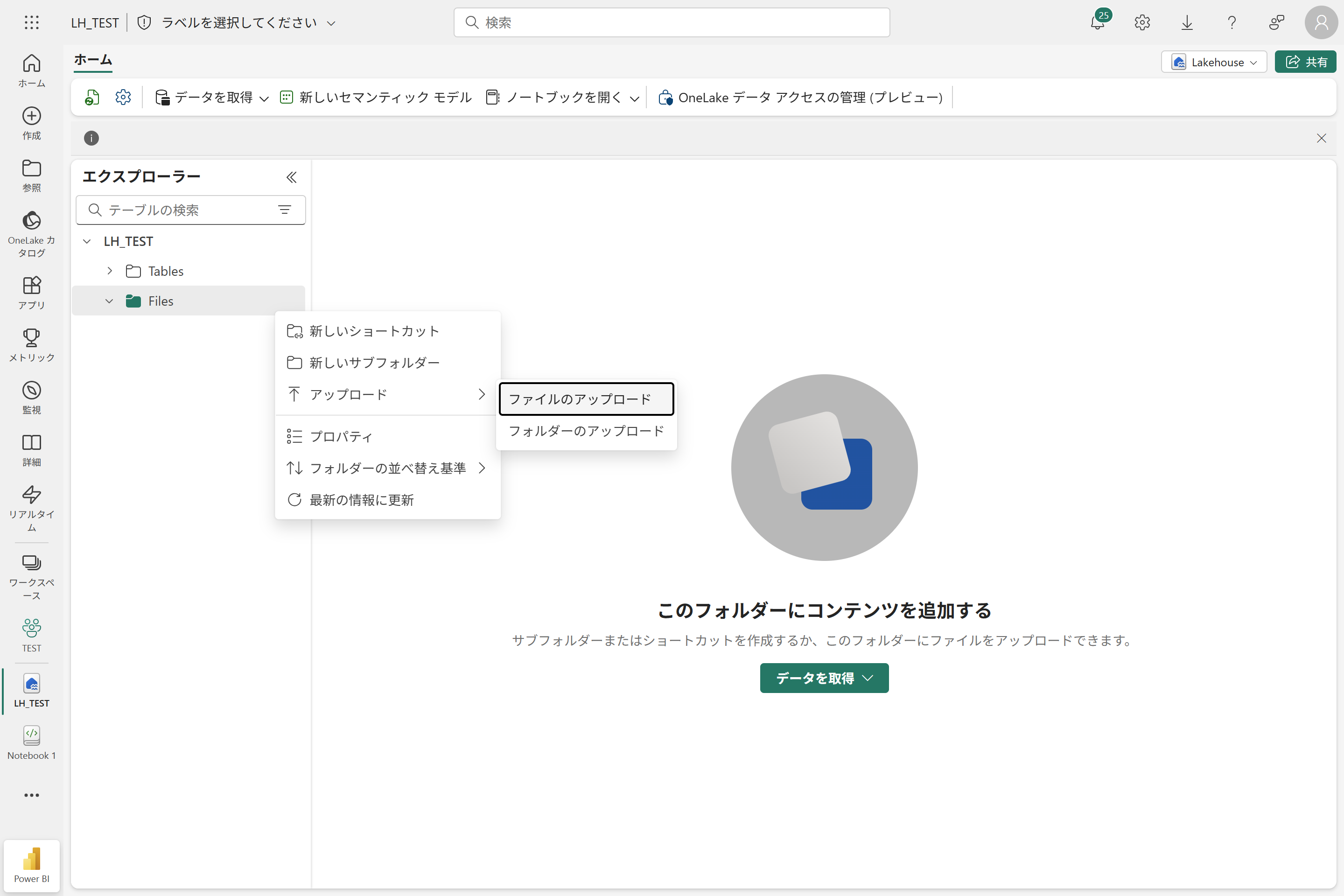
Fabric でファイルを扱うには、レイクハウス を作成し、その配下の Files にCSVをアップロードするのが第一歩です。
他にもいろいろ方法はありますが、お試しではこれが一番手っ取り早いかなと思います。
環境に合わせた Python コードを Fabric の Copilot に生成してもらう
一般の生成AIだと基本的に、ローカル環境でコードを実行する前提になっているので、Fabric のレイクハウスにアップロードしたファイルの操作に適したコードを生成してくれません。
そこで、Fabric の Copilot にも登場してもらいます。最小サイズの F2 から Copilot が利用できるようになったので、抜群にハードルが下がりました。
Fabric で Copilot を使用するための前提条件
- ワークスペースのライセンス モードが Premium/Fabric 容量に設定されている。もしくは、Fabric Copilot 容量が有効化され、利用可能なユーザーとして登録されている
- テナント設定で [ユーザーは、Azure OpenAI に対応する Copilot やその他の機能を使用できます] ならびに [Azure OpenAI に送信されたデータは、容量の地理的リージョン、コンプライアンス境界、または国内クラウド インスタンスの外部で処理できます] の設定が有効化されている
-
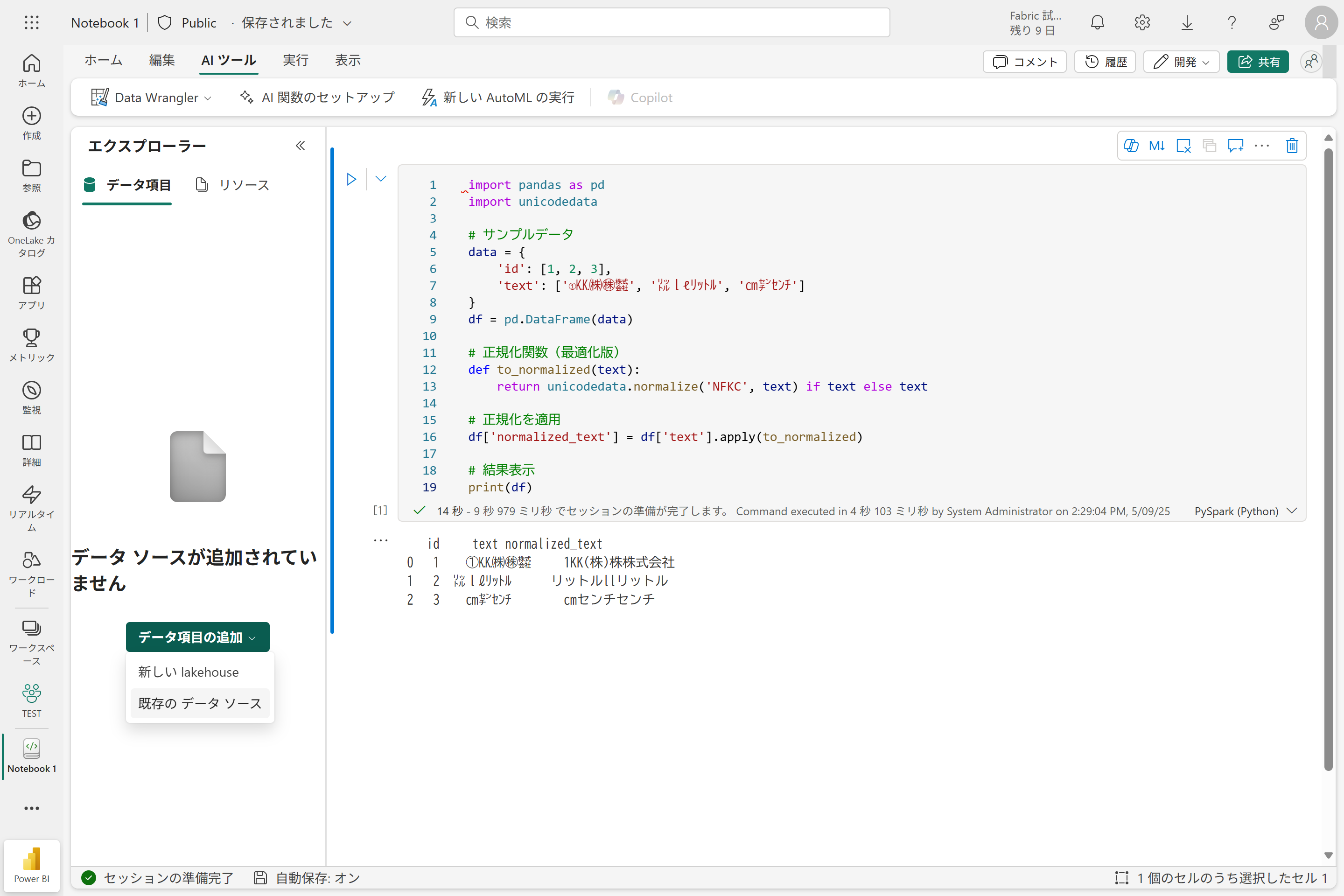
このノートブックをレイクハウスに紐づけます。セルの左側の [エクスプローラー] ペインの [データ項目の追加] をクリックし、[既存の データソース] を選択します。
-
先ほどファイルをアップロードしたレイクハウスを選択して接続します。
[現在のセッションを停止する] というダイアログが表示されるので、[今すぐ停止] をクリックします。

-
コードの実行結果が表示されている部分の 下に カーソルを合わせると、[+ コード] と [+ Markdown] が表示されるので、[+ コード] の方をクリックします。
-
追加された空のセルの右上に並んだボタンから Copilot ボタンをクリックし、次の指示を入力して実行 (紙飛行機ボタンをクリック) します。
このレイクハウスの Files 配下にある sample_input.csv ファイルの text 列に正規化を適用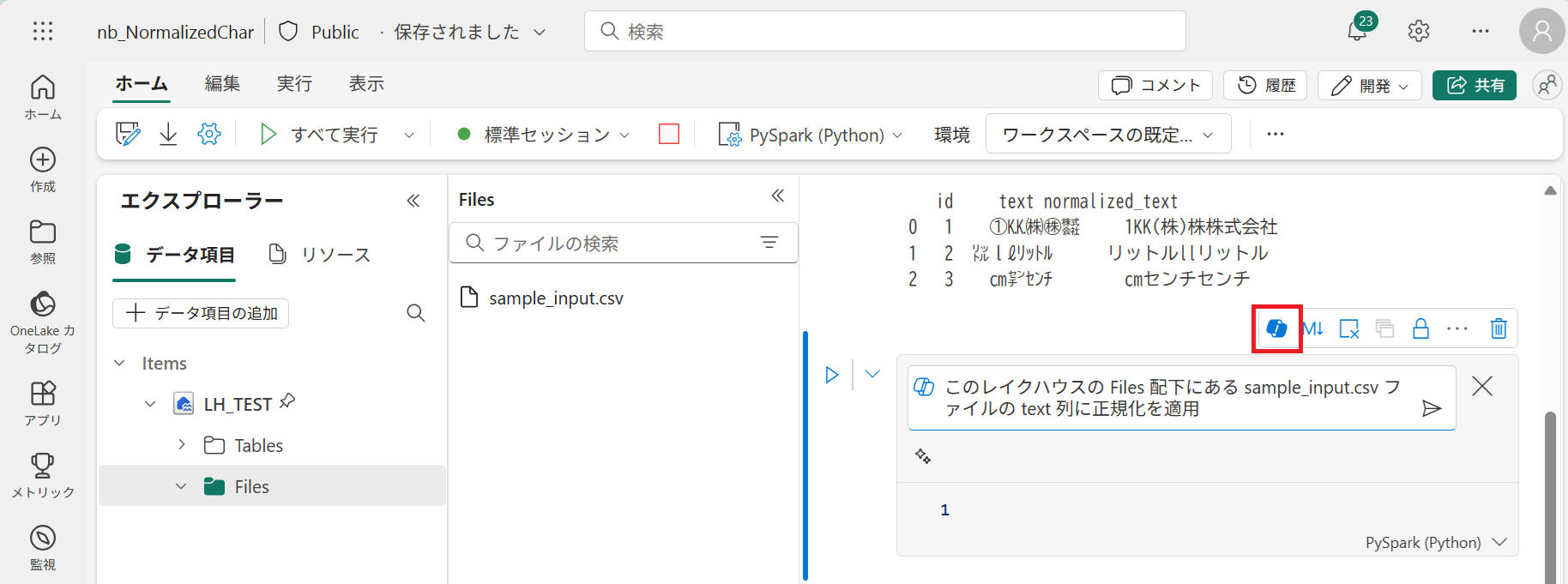
-
コメントも日本語にしてほしいところですが、英語でコードが生成されます。
コードの内容に問題がないことを確認して [同意する] をクリックし、コードを実行します。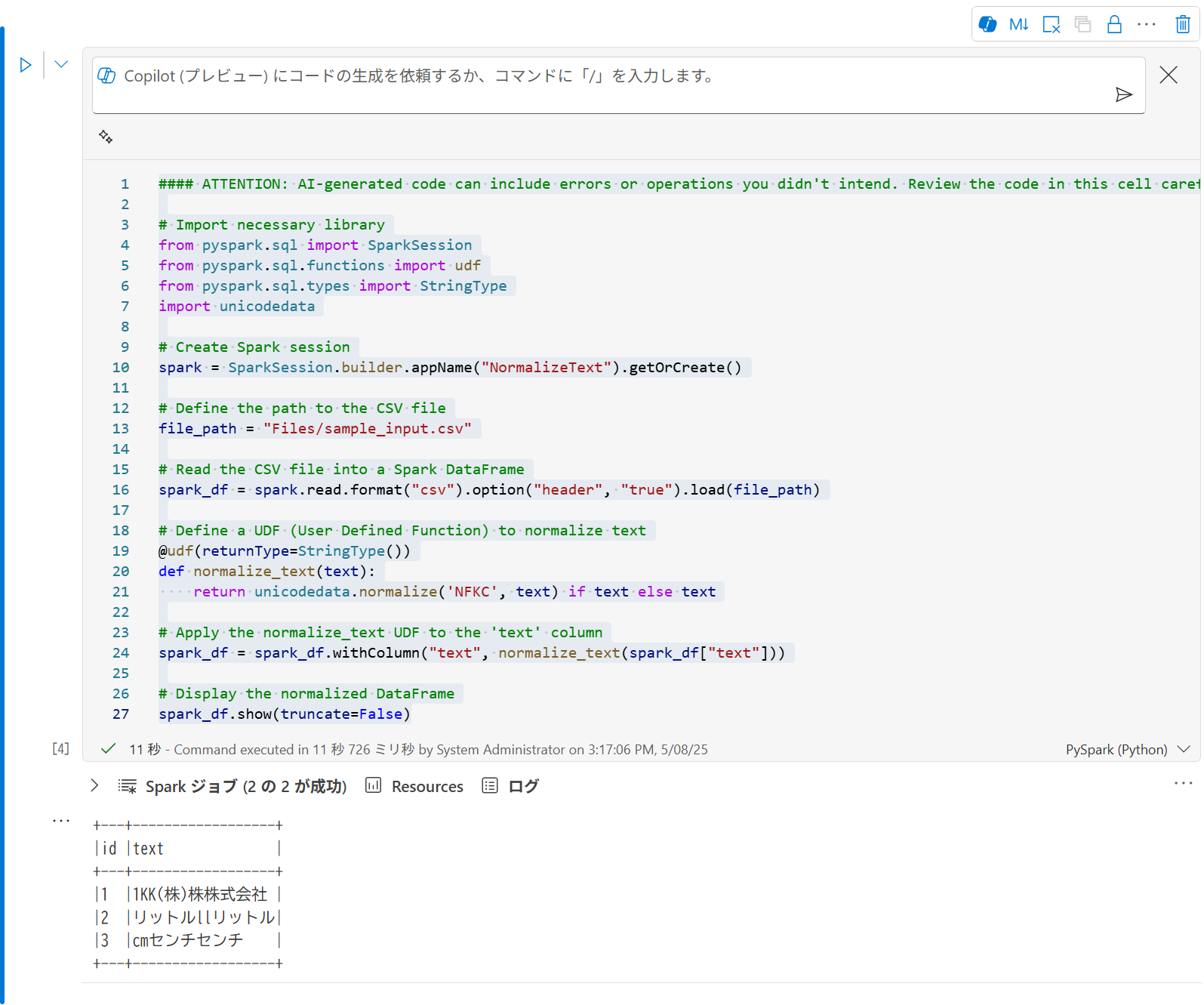
-
さらに、変換結果をレイクハウスのテーブルとして作成するよう指示すると、そのように書き換えてくれます。
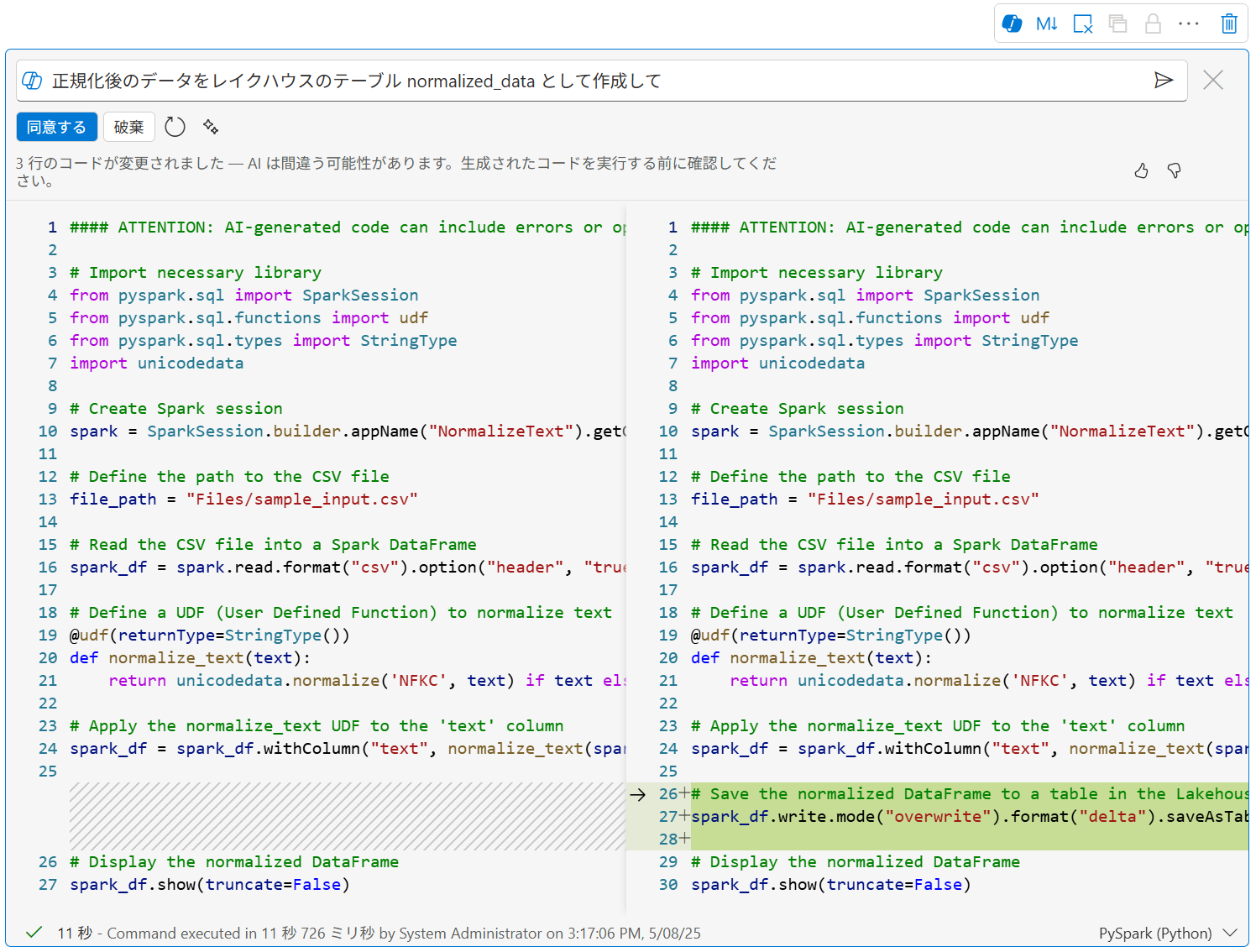
26-28行目が変更されたコードです。 -
[同意する] をクリックすると、変更が反映されます。
コードを実行すると、レイクハウスの Tables 配下に normalized_data テーブルが作成されているのを確認できます。
まとめ
Fabric 容量と機能の有効化という環境さえ整えば、これと言った構築作業をすることなく、Python を使って半角全角変換を実行できます。Power BI から Fabric へ踏み出そうと考えている皆さま、ぜひお試しください。