概要
Azure Storage AccountのBlob StorageではブロックBlob、追加Blob、ページBlobの3つを取り扱う事ができる。
今回はそのうちのブロックBlobについて、どのような仕組みでBlobを操作しているのかを調査していく。
Step1. ブロックBLOBについて知る
そもそもBLOBとは
バイナリ・ラージ・オブジェクト(英: Binary Large Object、別名:BLOB)とは、データベース管理システム(DBMS)においてバイナリデータを格納する場合のデータ型である。画像や音声、その他のマルチメディアオブジェクトがBLOBとして格納される。
要するに、ファイル等を保存するためのデータ型である。
Azure Storage AccountではこのBlob専用のBlob Storageがある。
ブロックBLOBとは
Microsoft Learn - ブロック BLOB について
ブロックBLOBは、大量のデータを効率的にアップロードするために最適化されています。
ブロックBLOBはブロックで構成され、それぞれがブロックIDで識別されます。
ブロックBLOBには、最大50,000個のブロックを含めることができます。
ブロックBLOB内の各ブロックは、使用中のサービスバージョンで許可される最大サイズまで、異なるサイズにすることができます。
ブロックBLOBを作成または変更するには、Put Block操作を使用してブロックのセットを書き込み、Put Block List操作を使用してブロックをBLOBにコミットします。
BLOBデータをブロックとして分割し、ブロック群を並列でアップロードすることで
巨大なBLOBデータでも効率よくアップロードできるようにしたものである。
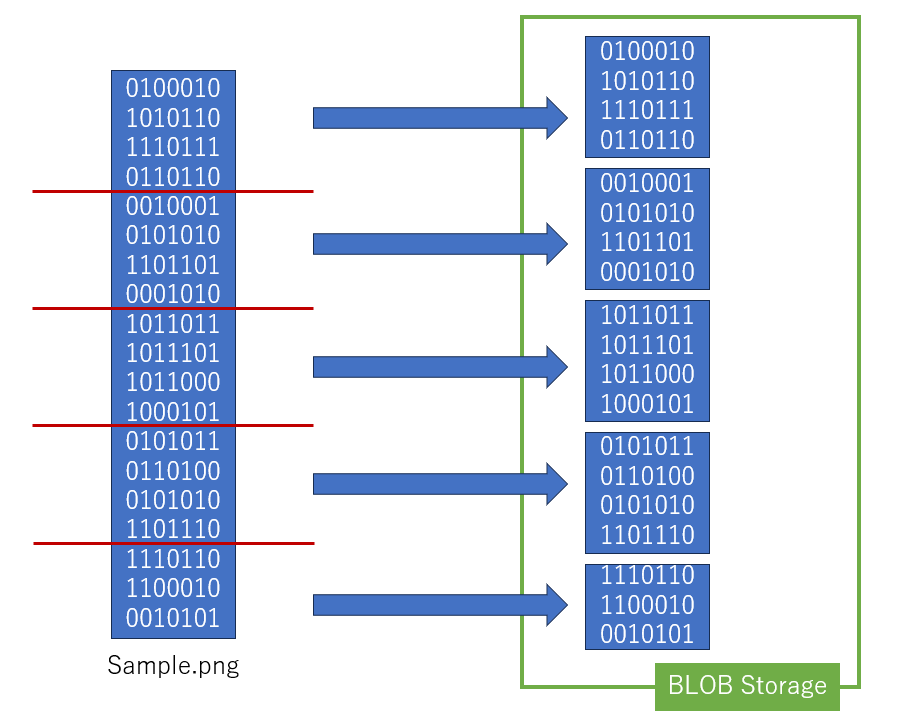
現行バージョンでの1ブロックあたりの容量と1データあたりのブロック数は以下の様になっている。
| 最大ブロックサイズ | 最大ブロック数 | 最大BLOBサイズ |
|---|---|---|
| 4,000 MiB | 50,000 ブロック | 約 190.7 TiB |
Step2. ブロックBLOBに触れてみる
今回はPython向けのライブラリとして提供されている、Azure Blob Storage クライアント ライブラリを使用して操作する。
インストール
pip install azure-storage-blob
実際のコード例
シンプルにアップロードとダウンロードを行う処理。
ブロックを意識することなく、単一のデータとして取り扱える。
from azure.storage.blob import BlobClient
# 接続文字列
connection_str = 'DefaultEndpointsProtocol=https;AccountName=storagesample;AccountKey=<account-key>'
# コンテナー名
container_name = 'test'
# ファイル名
blob_name = 'hello.txt'
client = BlobClient.from_connection_string(connection_str, container_name, blob_name)
# アップロード
upload_data = 'hello world.'
client.upload_blob(upload_data, overwrite=True)
# ダウンロード
download_data = client.download_blob().readall()
Step3. ブロックBLOBを解剖してみる
続いて、ブロックを意識してブロックBlobを取り扱ってみる。
ブロックBlobの主な要素
| 要素 | 説明 |
|---|---|
| ブロックリスト | ブロックIDのリスト。UNCOMMITTED,COMMITEDの2つがある。 |
| ブロックID | ブロックごとに割り振られたID |
| ブロックサイズ | ブロックが持つデータのサイズ。バイト長が入っている。 |
実際のコード例
import base64
import datetime
# アップロード
upload_data = 'hello world.'
## 1. ブロックIDの作成、Base64で一意のIDを指定する
id = base64.b64encode(str(datetime.datetime.now()).encode())
## 2. ブロックの登録
client.stage_block(id, upload_data)
## 3. ブロックの反映
client.commit_block_list([id])
# ブロックリスト
## ここで取得するブロックにはデータは付属していない
blocks = client.get_block_list()
print(blocks)
"""出力結果
([{'id': "b'MjAyMy0xMi0wNSAxNzo1MTo1NC42NjAzMTk='", 'state': <BlockState.LATEST: 'Latest'>, 'size': 12}], [])
1つ目のリストがCommitted、2つ目がUnCommitted
"""
# ダウンロード
## ダウンロードは特に変化なし
download_data = client.download_blob().readall()
ここで注目したいのがアップロードの2と3である。
ブロックを直接保存するのではなく、一旦ID付きで登録してから反映する。
この仕組みのおかげで順番をバラバラにしたブロックをアップロードしても最後の反映の際にIDの順があっていれば正常に保存される。

Step4. ブロックBLOBを組み替えてみる
最後に、応用編としてブロックの組み換えを行ってみる。
追記過多でブロック数が上限の50000を超えた際に、細かいブロックをマージすることでブロック数を減らす処理を行う
ブロックのマージ処理
# ブロックIDリスト
ids = []
# 仮想ブロック
data_pool = bytes()
# ストリームの現在地
index = 0
# 1ブロックあたりのサイズ上限
block_size = 1000000000
# 対象ファイルのブロックリスト
blocks = client.get_block_list('committed').pop()
for block in blocks:
# 指定したサイズ上限まで仮想ブロックにデータを溜め込む
# サイズ上限に達した場合は仮想ブロックをアップロードし、再度溜め込む
if block.size != block_size:
if len(data_pool) > block_size:
data = data_pool[:block_size]
data_pool = data_pool[block_size:]
id = base64.b64encode(str(datetime.datetime.now()))
client.stage_block(id, data)
ids.append[id]
# 仮想ブロックに移した分だけ次のデータ範囲を読み込む
data = client.download_blob(index, block.size)
data_pool += data.content_as_bytes()
else:
ids.append(block.id)
index += block.size
# 余剰分のデータをアップロードする
id = base64.b64encode(str(datetime.datetime.now()))
client.stage_block(id, data_pool)
ids.append(id)
# アップロードしたデータを反映する
client.commit_block_list(ids)
終わりに
ログをBlob Storageに出力したい・ログファイルは分割せずに1つのファイルに全て出力したい、という要望に応えるためにStep4のブロックマージ処理は作成された。
当初は追加Blobを使用して逐一追記していく予定だったが、最大50000回までしか書き込めない事、内容の変更が出来ない事が分かり、急遽ブロックBlobを用いての対応となった。
今考えると要望に対し考え無しにイエスを返すのではなく、分けた方が使いやすいですよ、といった方向で提案するべきだったかもしれない。