はじめに
Dataiku DSSユースケースのWeb Logs Analysisをやってみました。
ちなみに今回使ったDataiku DSSのメジャーバージョンは6です。
Use Case : Web Logs Analysis 概要
今回は、ウェブログ解析となります。Google Analyticsなどで用いられているイベントトラッキングデータを使って、商品を買いそうな顧客セグメントをみつけていき、今後の販売戦略に役立てます。
下準備
1.「Web Logs Analysis」という名前のプロジェクトを作成します。
2. 描画に必要なプラグインReverse Geocoding / Admin maps plugin をインストールします。
- 右上 Appsからplugin storeに行きます。
「Reverse Geocoding」で検索し、プラグインをインストールします。
確認画面がでますので、CONFIRM INSTALLします
しばし待ちます。

チャート作成時に、Administration mapが選択できるようになっていれば成功です。
データ
今回使うデータは以下の2種類です。
- Web Logs
Dataikuのウェブサイトログ。計測期間は2か月。ウェブサイトの各ページビュー情報。
- CRM
クライアントに関するトランザクションデータおよび統計データを含む、顧客関係管理(CRM)データベース。(シュミレーションデータ)
おおまかな流れ
ウェブサイトログデータを用いて以下の二つの分析を行います。
リンク元分析
どのリンク元からの訪問者が多いのか特定します。訪問者分析
サイトへの訪問者をクラスタリングし、それぞれのクラスタ(セグメント)の傾向から顧客をマーケティング対象か、販促対象か販促見込み対象か分類します。
分類した結果を、既存顧客データベースと対応づけ、マーケテイングや販促担当者に送付できるよう顧客リストを整えます。
データの読み込み
- ウェブサイトログデータをDataiku DSSにインポートし、「WebLog」という名前でデータセットを作成してください。
- CRMデータDataiku DSSにインポートし、「CRM」という名前でデータセットを作成してください。
前処理
WebLogデータセットに対しての前処理をpreareレシピを用いて行います。
prepareレシピを使ったデータ加工の詳しいやり方についてはこちらをご参照ください。
クリーニング
- br_width, br_height, sc_width and sc_heightの4カラムを削除
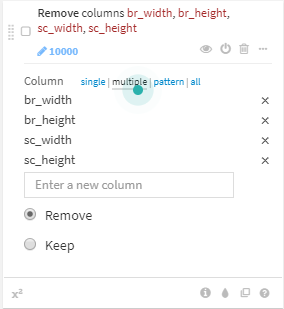
client_addr を ip_addressに項目名変更
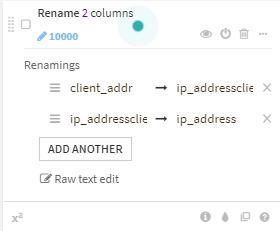
ip_addressのinvalid valueを削除
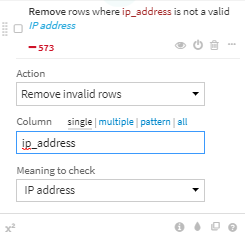
2020/11/16 追記:Dataiku社のDataiku AcademyサイトではRemoveではなくClearと指定しているため、この後の曜日ごとのグラフが異なってきます。Dataiku Academyサイトと合わせるためにはClearを指定してください。ちなみに、Removeは行削除ですが、Clearは空欄への変換となります。locationをurlに項目名変更
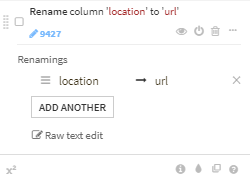
データ加工(dates, locations, and user agents)
server_tsの日付情報を正しいフォーマットでパース
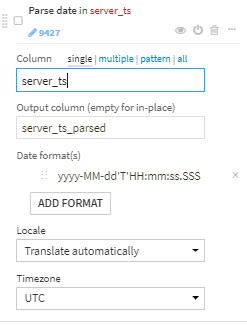
パースしたserver_tsから、month, day, day_of_week, hourを取り出す。
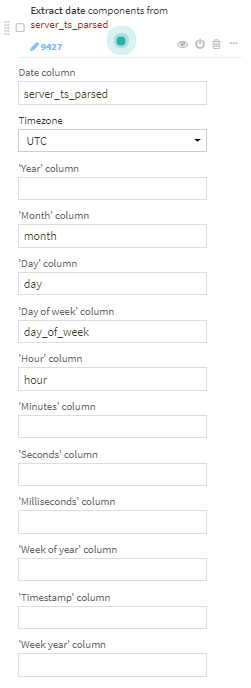
ip_addressから、country、city、GeoPointを抽出。
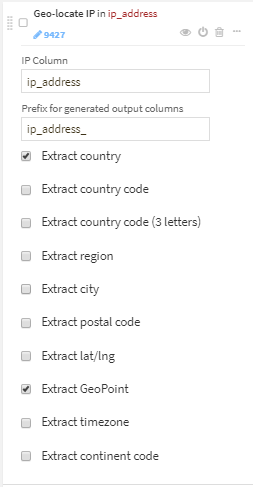
- user_agentをパースし、user_agent_type以外を削除
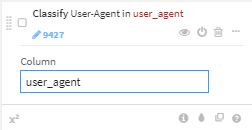
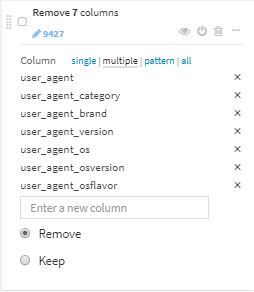
データ加工(Dataiku URLs)
- urlからpathのみ取り出します。url_pathという新たな項目ができます。
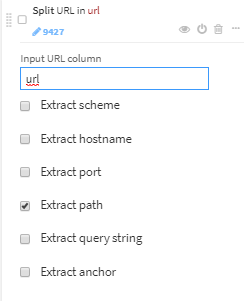
url_pathを"/"でパースし、最初の要素のみ取り出します(url_path_0)。
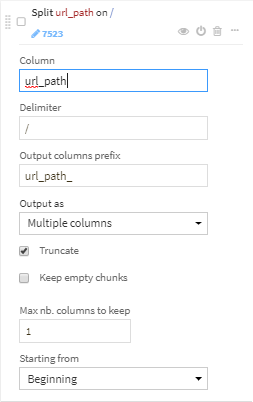
url_path_0の空行をhomeで埋めます。
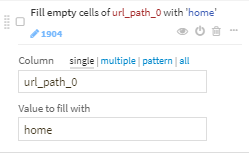
Unfoldを使ってurl_path_0のダミーカラムを作成します。
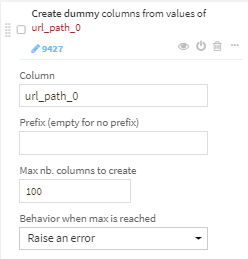
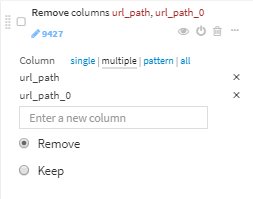
url_pathとurl_path_0を削除します。
データ加工(referrer URLs)
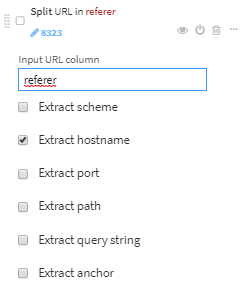
refererに記載されたURLからhostnameのみ抽出します(referer_host)。
-
referer_hostに記載されているデータに以下の処理をします。
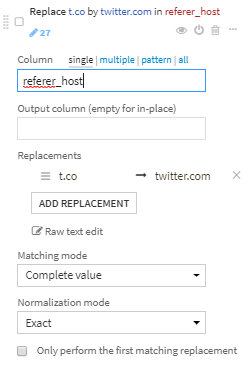
- t.coに完全一致するものをtwitter.comに変換します。
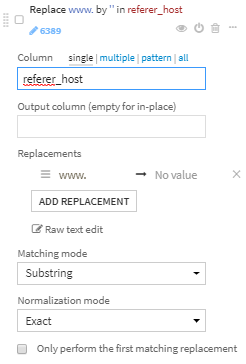
- www. に一致する部分を削除します。
- 正規表現..*に一致する部分を削除します。.comなどが削除されます。
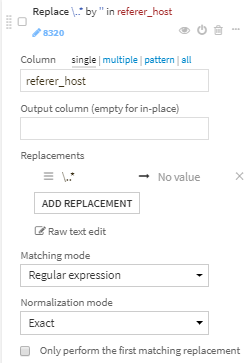
- 次の8カラムを削除します。
- server_ts
- referer
- type
- visitor_params
- session_params
- event_params
- br_lang
- tz_off
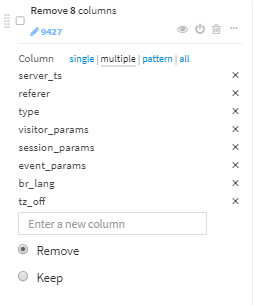
以上、19のステップで、21カラムのデータ加工後のデータセットが作成できました。
データ傾向把握
前処理後のデータに対して、チャートを描きながらデータ傾向を把握します。
以下3つの観点でデータ傾向を把握します。
- 曜日ごとのページ閲覧者数の違い
- フランスとアメリカからの訪問者数の比較
- 地域ごとの訪問者数の分布
曜日ごとの閲覧者数の違い
曜日で、閲覧者数に違いがあるか確認します。
LogsDataiku_preparedデータセットに対し、チャートを書いていきます。
y軸:count of record
x軸:server_ts_parsed
x軸のすぐ左にある「▼」をクリックして「Date Ranges」を「Day of Week」に設定します。
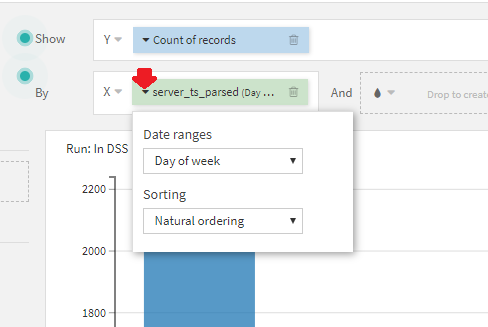
このDate Rangesは非常に便利で、Date型にパースしてある項目ならば、年ごとや月ごとなど、様々な切り口での可視化が容易に行えます。
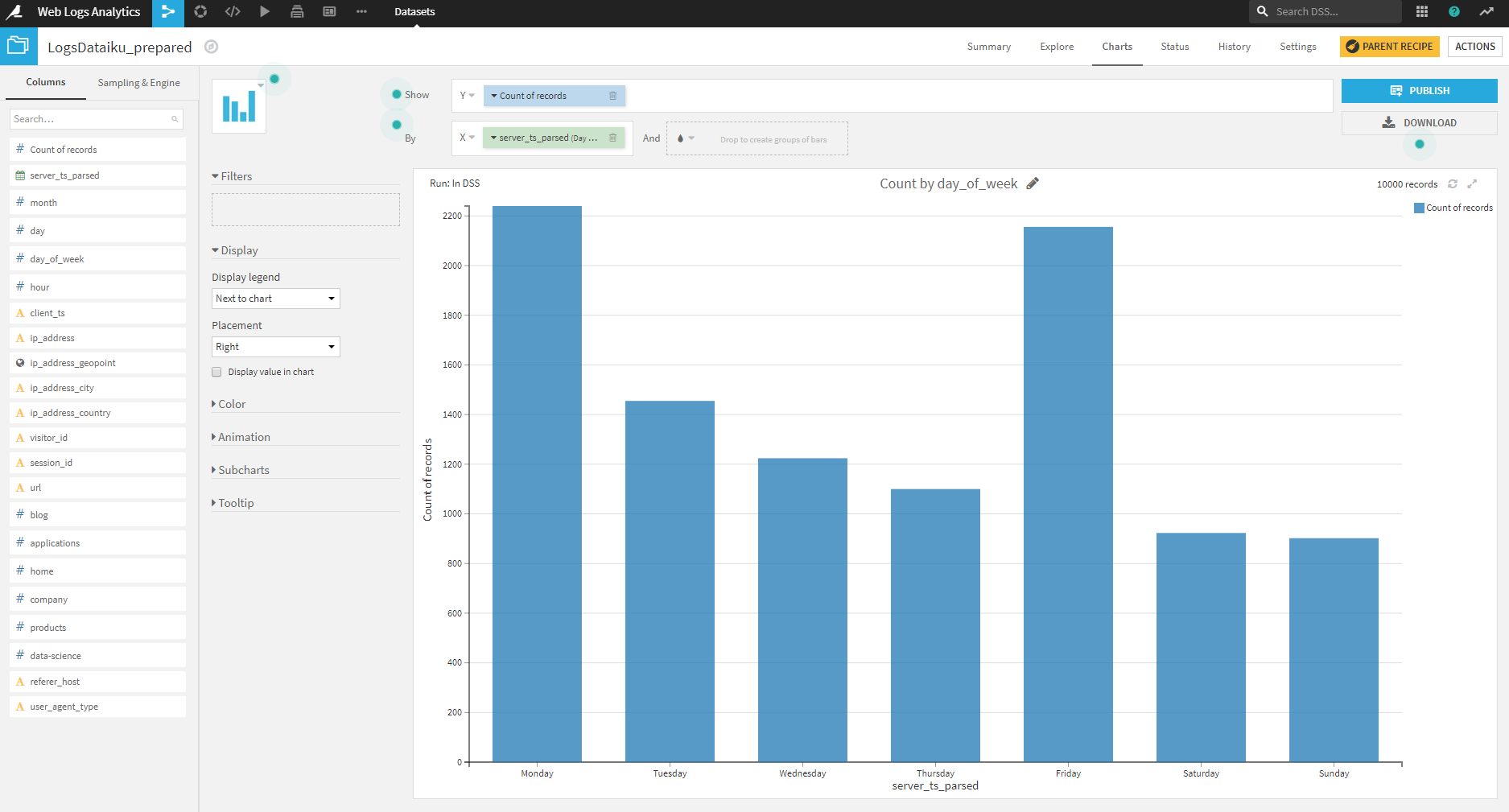
得られたチャートから、月曜日と金曜日が訪問者数が多く、土日が少ないことがわかります。
金曜日にスパイク状にピークがありますが、月曜から木曜にかけては徐々に訪問者が減少している傾向にあります。
フランスとアメリカからの訪問者数の比較
次に、フランスとアメリカからの訪問者数を比較してみます。
先ほどのチャートを修正しながら新たなチャートを作ります。
左下の小さいチャートの部分のコピーボタンをクリックしてください。
全く同じ、新しいチャートができました。このままで新しいチャートが選択されている状態なので、このチャートを変更する形ですすめていきます。
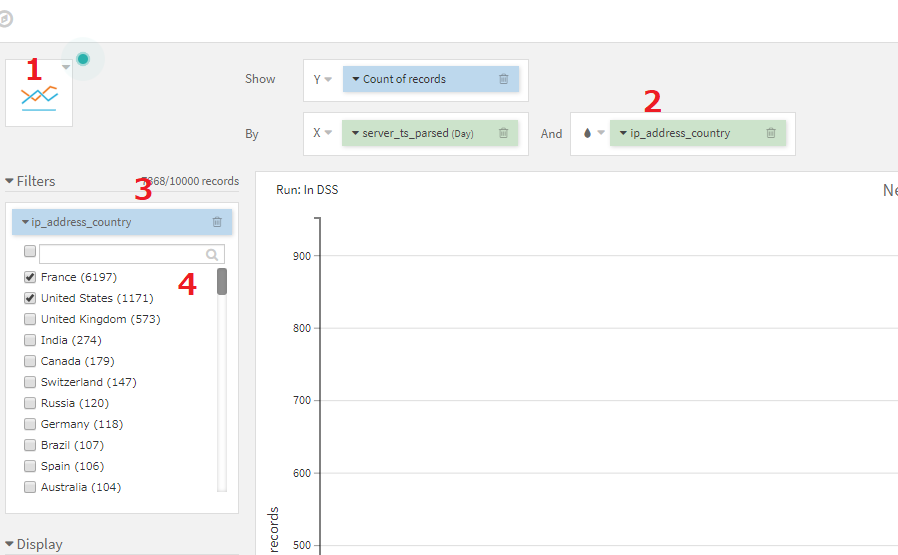
さきほどのコピーしたチャートに以下の変更を加えます。
- チャートの種類を線グラフ(Lines)に変更
- Andの右側にグルーピングする項目としてip_address_countryを指定
- Filterにip_address_countryを指定
- Filterのうち、FranceとUS以外チェックを外す。
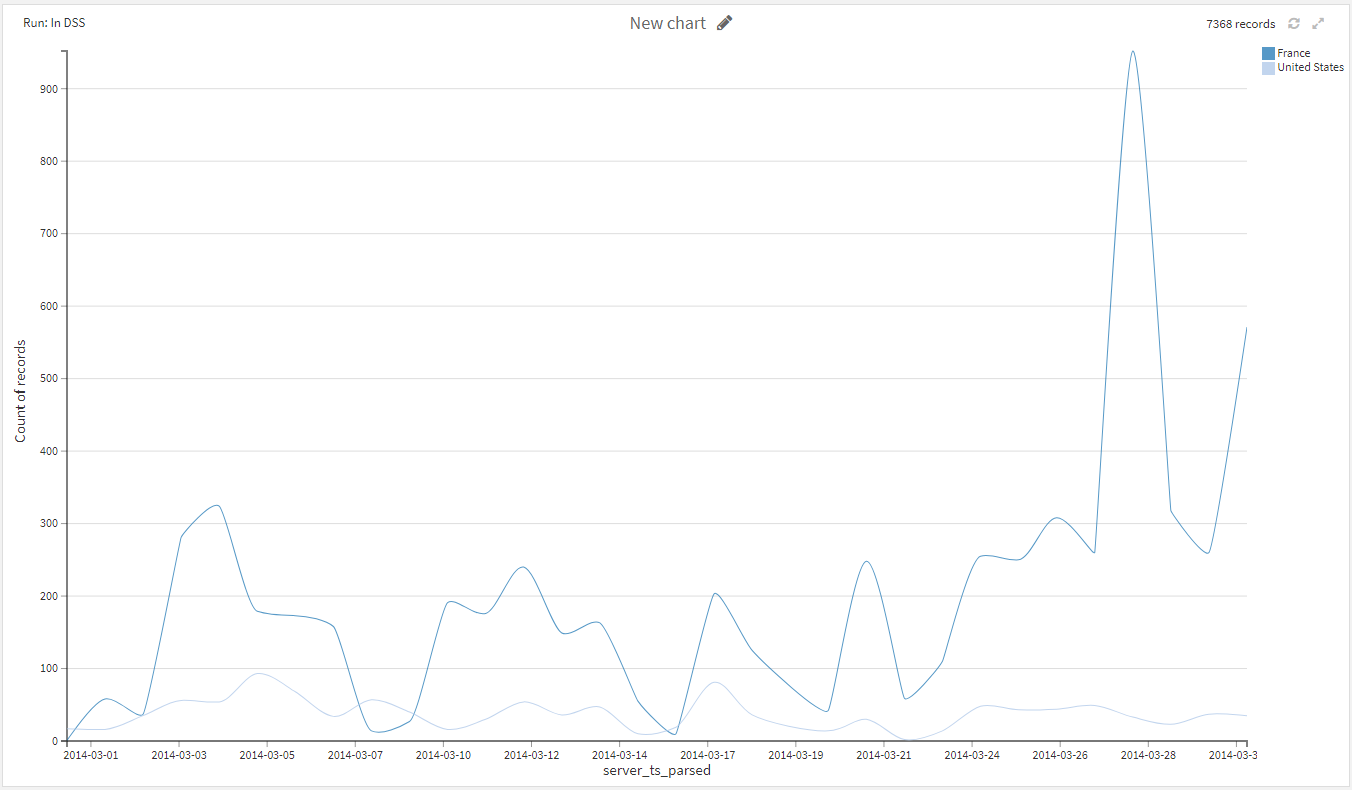
得られたチャートから、全体的にフランスの訪問者数がアメリカの訪問者数を上まわっていることがわかります。
また、特定の日に大きく値が変動していることも見て取れます。
3/28に大きなピークがありますが、これを除けばだいたい1日の訪問者数は400以下ということが言えます。
地域ごとの訪問者数の分布
次は訪問者が地図上でどのように分布しているかみていきます。
新たにチャートを作りたいので、左下の+CHARTボタンをクリックして新しくチャートを作成します。

以下のようなチャートを作成します。
1. チャートの種類は、Administrative Mapを選んでください。
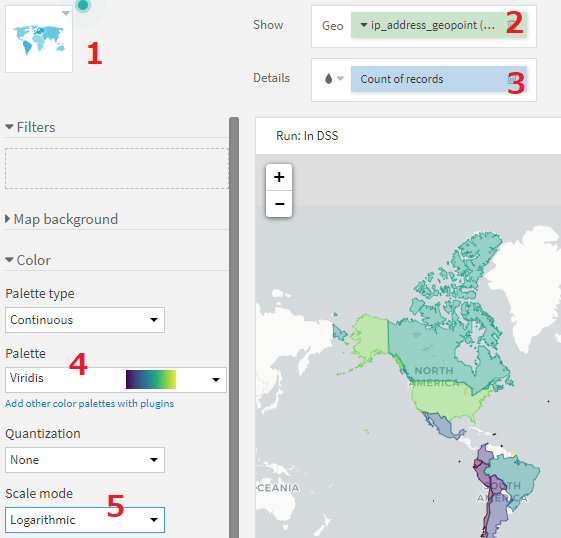
2. Showにip_address_geopointを指定
3. Detailsにcount of recordsを指定
4. 色が見にくいので、ColorのPaletteをViridisに変更
5. より国同士の違いをわかりやすくするために、Scale modeをLogarithmicに変更
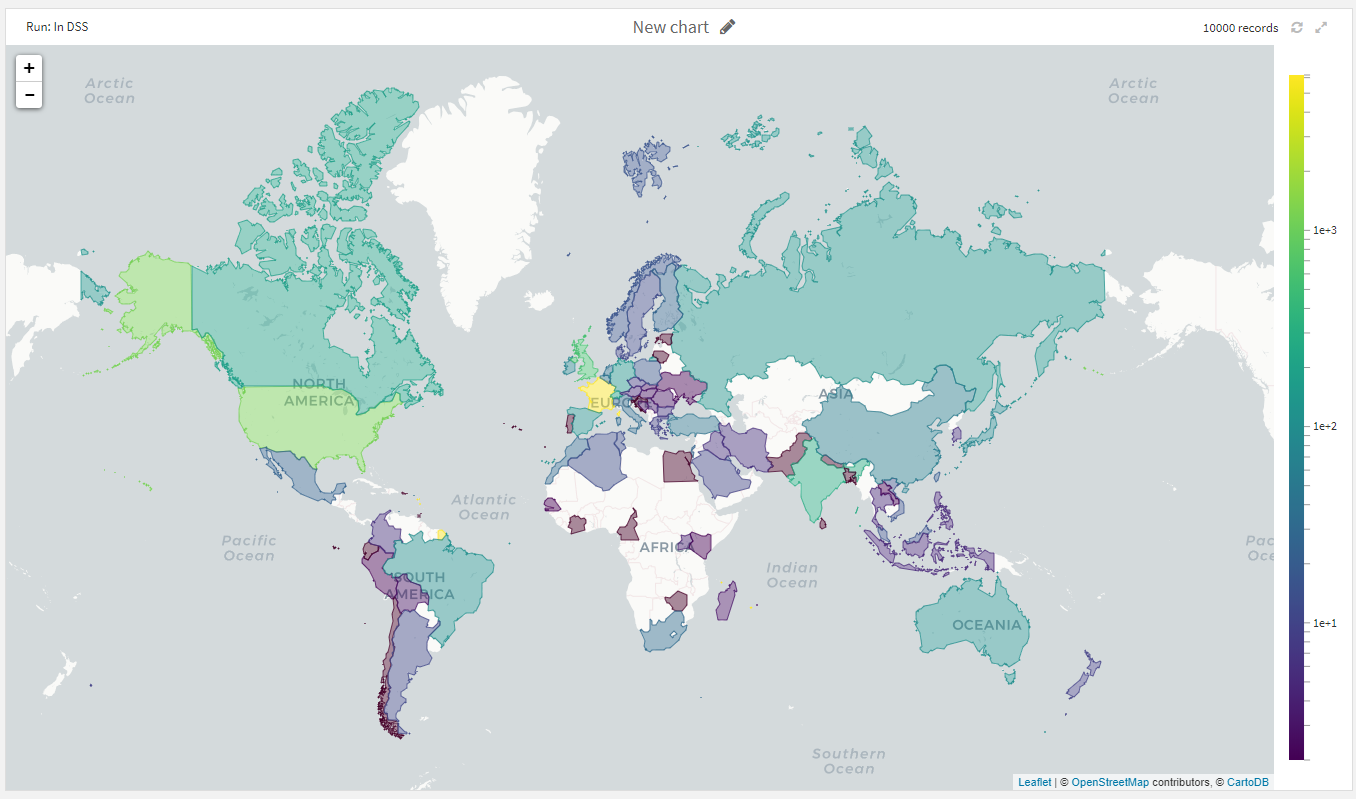
作成したチャートから、フランスとアメリカ以外では、イギリス、インド、カナダからの訪問者が多いようです。日本からはさほど多くないことがよみとれます。
ログスケールにしているので、訪問者が多い国からは3桁以上きており、日本は2桁程度、といったところでしょうか。
リンク元URLの分析
以下の3つの観点から、上位のリンク元URLを特定します。
- ページ閲覧数
- 訪問者数
- 参照したURL数
まず、リンク元URLごとにページ閲覧数や訪問者数、参照したURL数を計算します。これには、Groupレシピをつかいます。
LogDataiku_preparedデータセットをreferer_host項目ごとにグルーピングします。Output dataset名はデフォルト(LogDataiku_prepared_by_referer_host)のままとします。設定できたらCREATE RECIPEボタンをクリック。
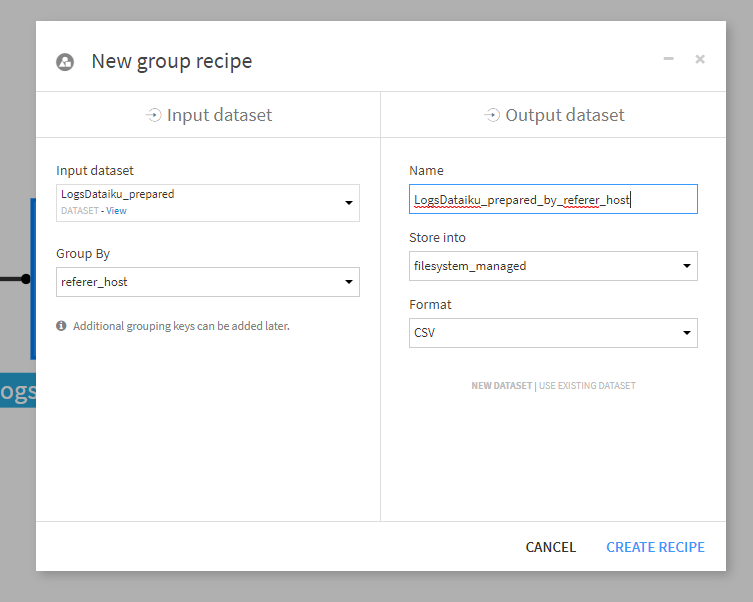
どの項目をどのようにグルーピングしていくか設定します。
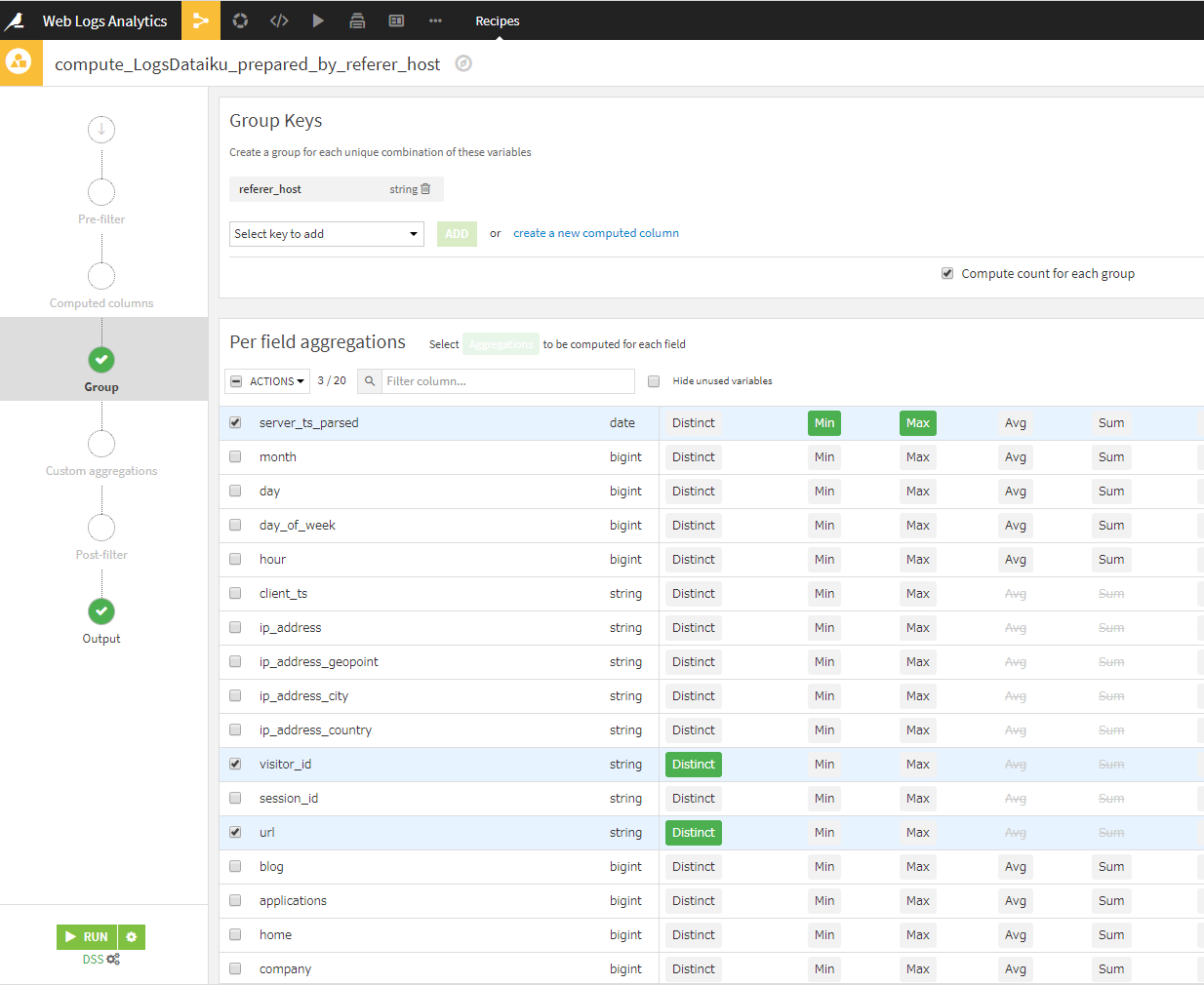
server_rs_parsedにMin、Maxを指定、visitor_idとurlにDistinctを指定します。
RUNボタン⇒UPDATE SCHEMAで、グルーピング処理が適用されます。
作成されたLogDataiku_prepared_by_referer_hostは、以下のような6項目からなるデータセットです。
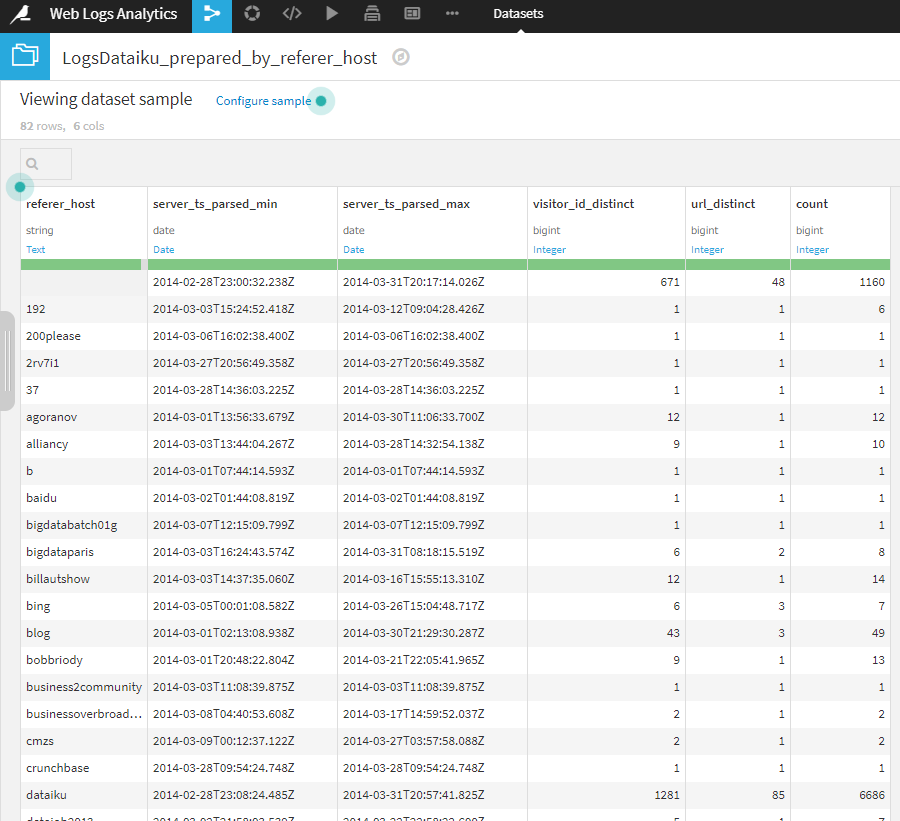
このデータセットから二つのチャートを作成しておきます。
一つは、リンク元URLごとの訪問者数などの一覧表です。
もうひとつは、リンク元URLごとのページビュー数を棒グラフで可視化します。
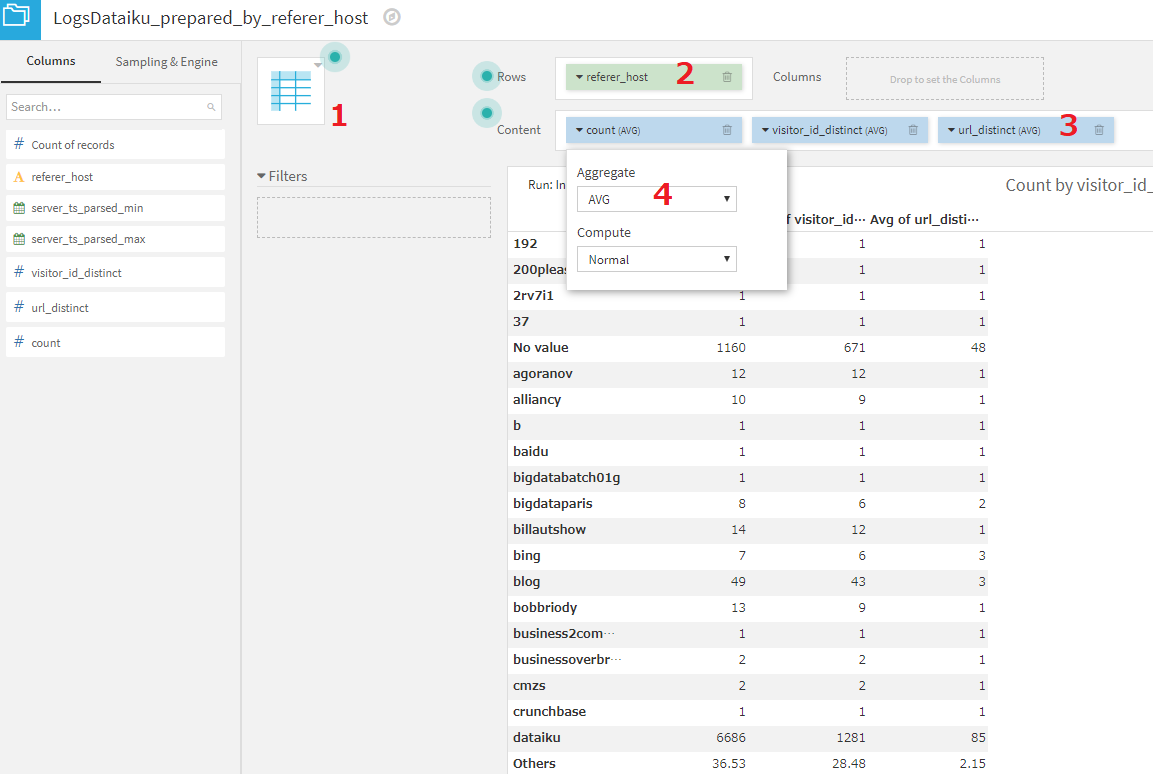
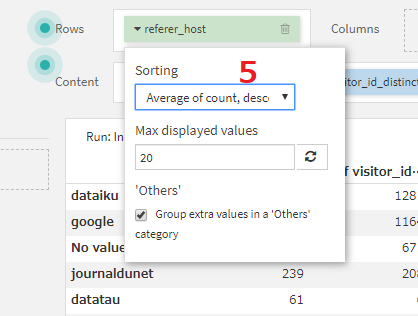
リンク元URLごとの一覧表
- LogDataiku_prepared_by_referer_hostのチャート画面で、pivot tableを選択します。
- rowsにreferer_hostを設定します。
- contentsに、count,visitor_id_distinct,url_distinctを設定します。
- contentsに指定した項目は全て、aggregateをAVGに設定します。基本的に、各referer_hostごとの値なので、AVG以外にしても多くの行で値は変わりません。ただし、Othersのみ、複数のreferer_hostの値を統合した値となりますので、aggregateの設定を変えることにより数値が変化します。
- count列が大きい順になるよう、テーブル全体をソートします。Rowsのreferer_hostのSortingをAverage of count, descendingに設定します。
リンク元URLごとのページビュー数
- Barチャートを選択します。
- X軸にcountを設定します。このとき、aggrigateはSUMを指定します。
- Y軸にreferer_hostを設定します。sortingに、Sum of count,descendingを指定します。
- Filtersにreferer_hostを設定し、dataiku、google、No valueの3つの値を除外します。チェックボックスからチェックをはずすことで除外できます。referer_host数が多いため、サーチボックスを使うと効率的にチェックを外すことができます。
- Show horizontal axisにチェックします。
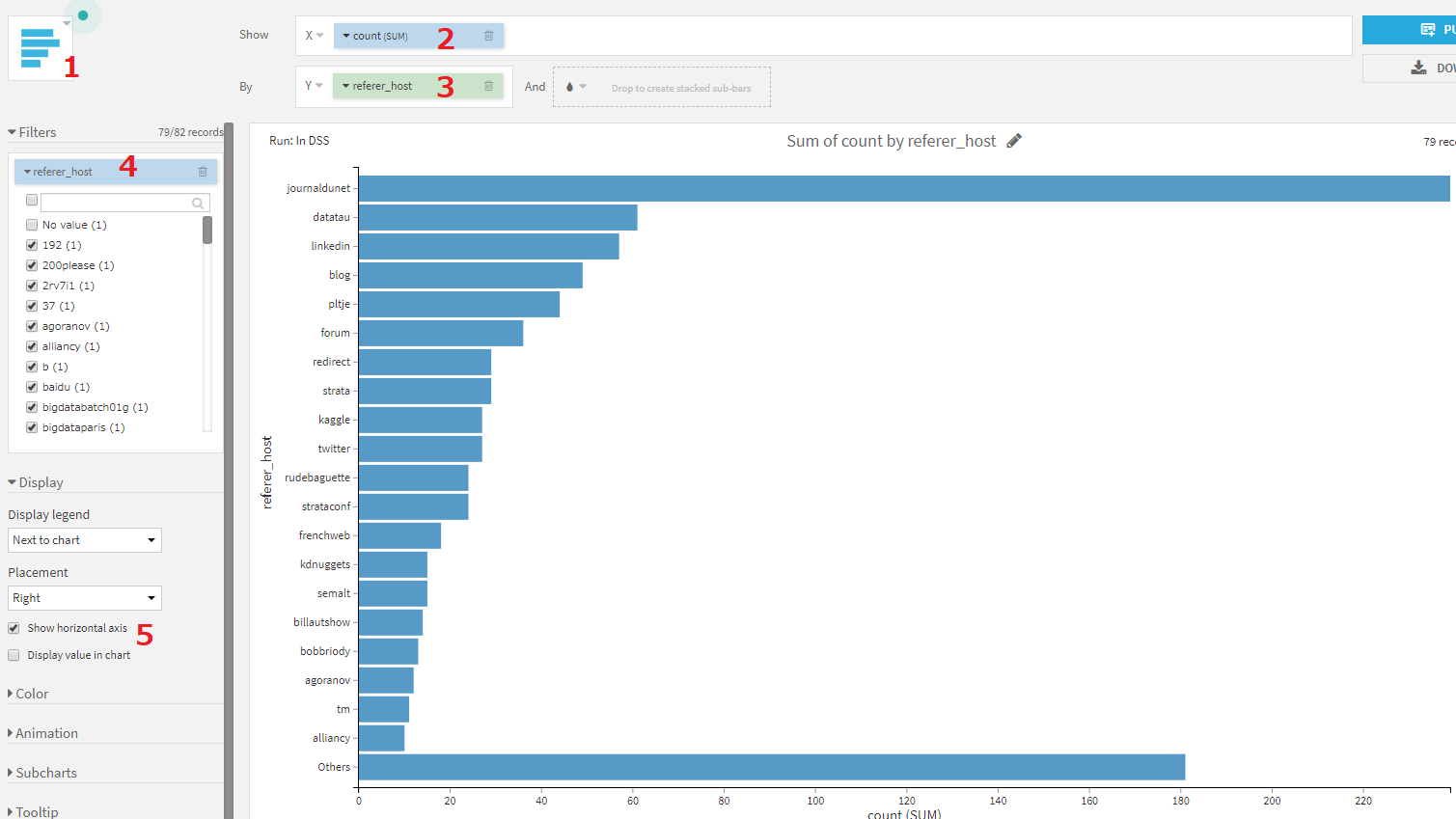
journaldunetからの訪問者が多いことがわかりました。
訪問者分析
訪問者をカテゴリに分類し、顧客を最も適切なチャネルに誘導してみましょう。
以下のステップですすめていきます。
- 訪問者ごとに情報をまとめる。
- クラスタリングアルゴリズムを用いて、訪問者のセグメンテーションを行う。
訪問者ごとに情報をまとめる。
リンク元URL分析で実施したようにGroupレシピを使って訪問者ごとに集計します。
LogDataiku_preparedをInput datasetとし、Group Byにvisitor_idを指定します。Output dataset名はデフォルトのままとします。
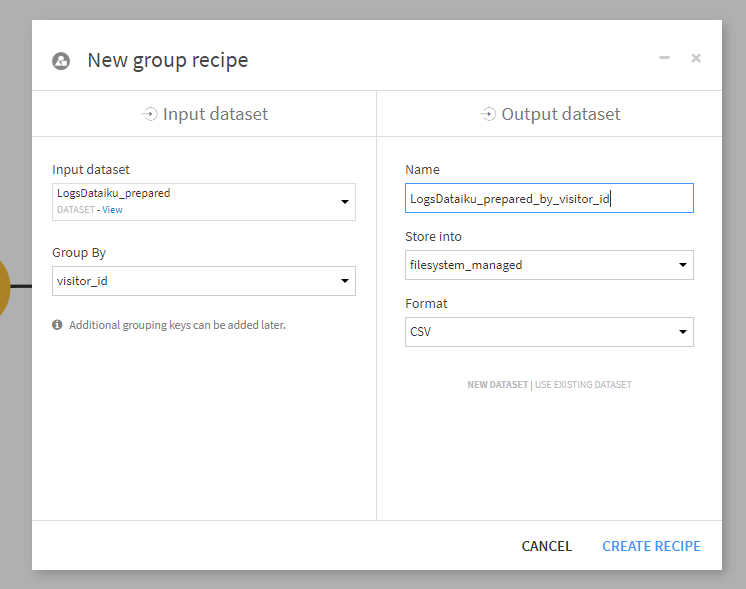
以下のように設定します
- 次の5項目をDistinct
day, day_of_week, hour, session_id,url - 次の2項目をFirst
ip_address_country, user_agent_type - 次の6項目をSum
blog, applications, home, company, products,data-science
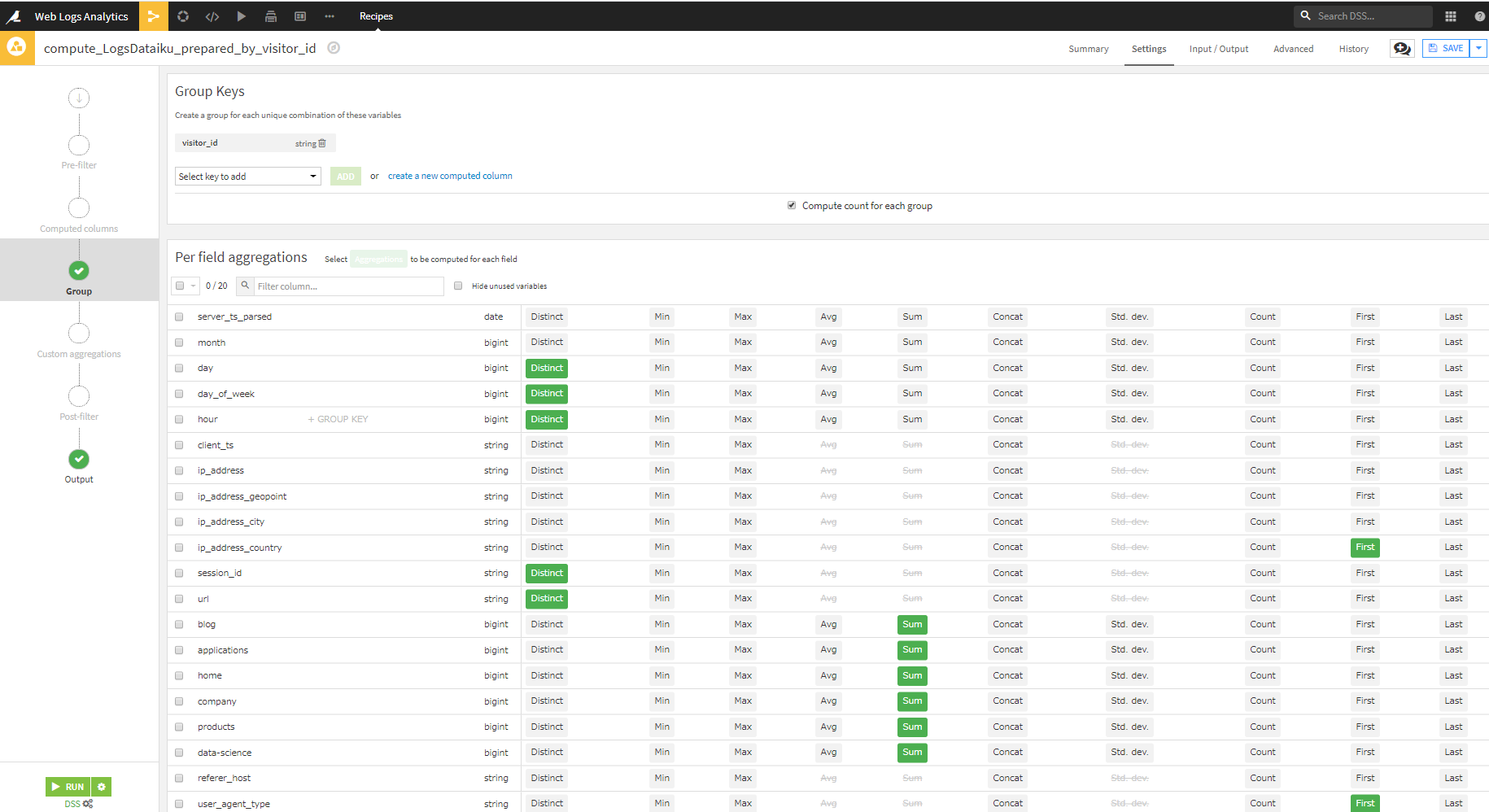
RUN押下後、UPDATE SCHEMAすることで、15列からなるデータセットが作成されます。
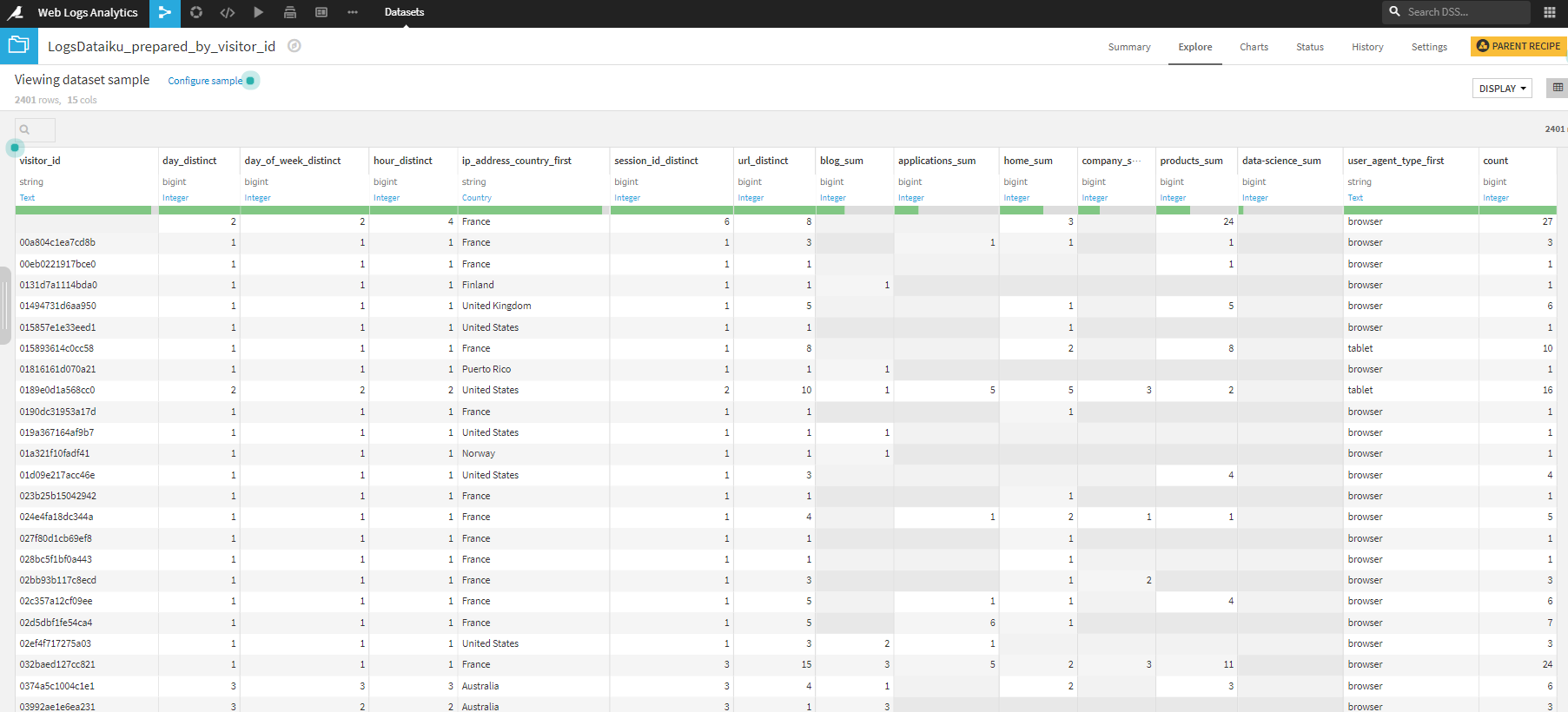
訪問者のセグメンテーション
クラスタリングにより訪問者のセグメンテーションを行います。
1. LogsDataiku_preapred_by_visitor_idを表示または選択した状態でLABボタンをクリック。
2. Visual analysisのQUICK MODELSをクリック
3. Choose your taskのCODElusteringをクリック
4. Choose your clustering styleでQuick modelsをクリック
5. K-Meansを選択
6. CREATEをクリック
7. TRAINをクリック。今回は特に設定はいじりません。ポップアップ画面が出てきますが、そこもデフォルトのままTRAINをクリック。
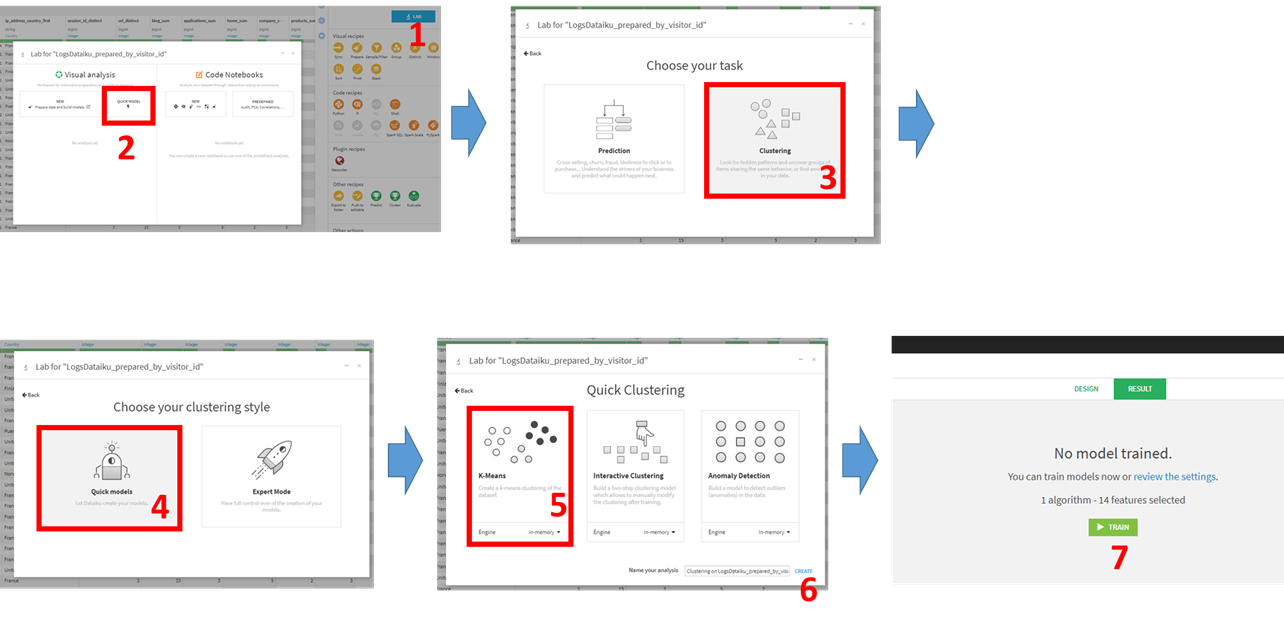
5つのクラスタとそのどれにも属さない外れ値的なグループの6つのクラスタに分かれます。
※環境や設定により、以下の表示と細かい部分では異なる可能性があります。
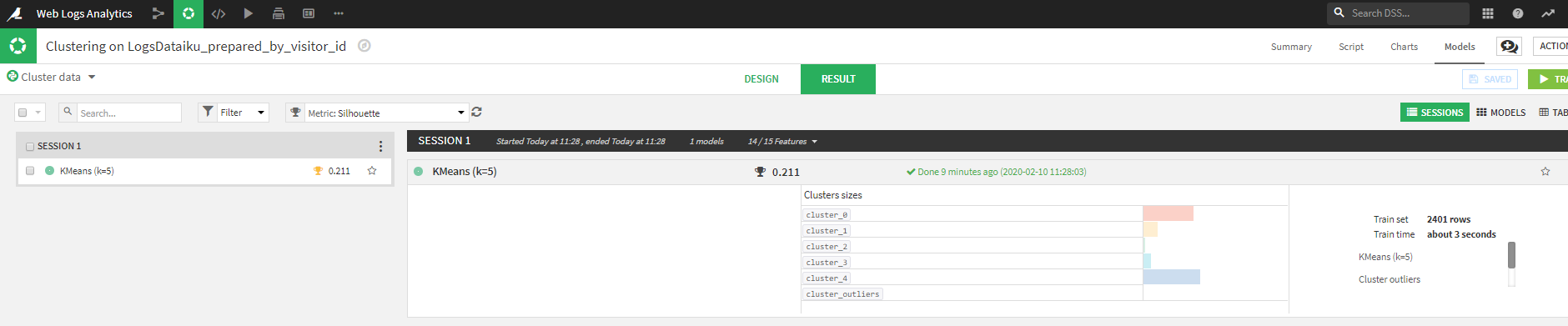
左側のKmeans(k=5)をクリックすることにより、Summaryページが開きます。
ここで得られる情報から、各クラスタの特徴をつかみます。
cluster_0は、フランスから来た訪問者が多いようです。このクラスタ名をFrench visitorsとします。ちなみに、右下のObservationsから傾向を把握しています。
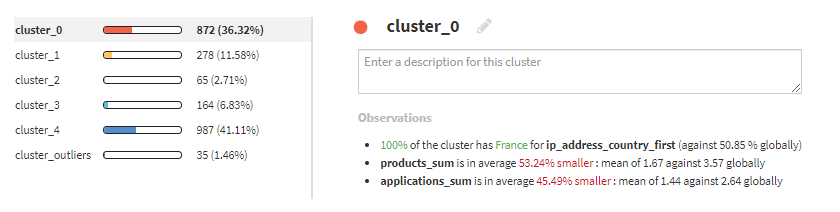
cluster_1は、いろいろなサイトに訪れています。Engaged visitorsと命名します。
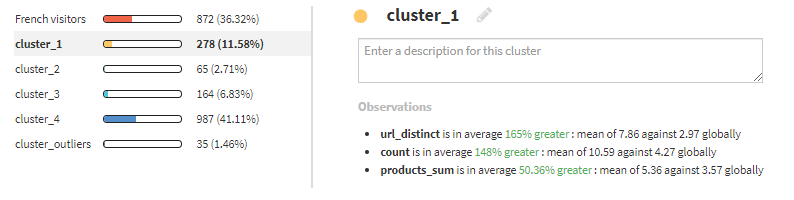
cluster_2は、products_sumが高いため、Sales prospectsとします。
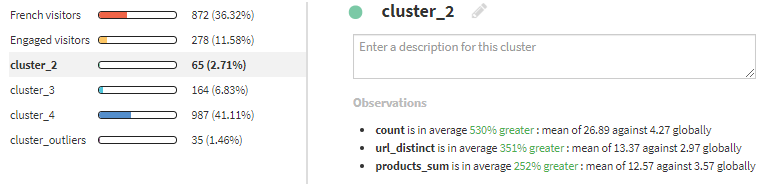
cluster_3は、訪問回数が多いため、Frequent visitorsとします。
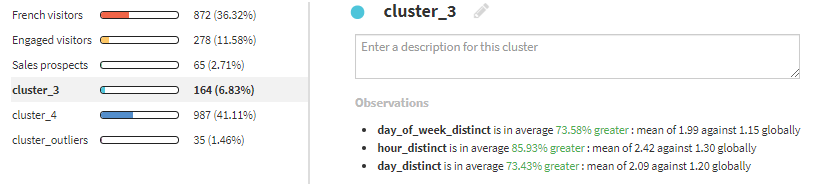
cluster_4は、アメリカからの訪問者数が多いため、US visitorsとします。
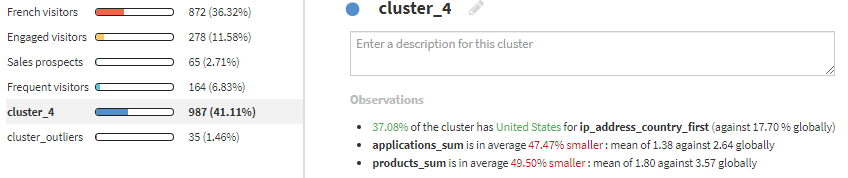
以上で、各クラスタに合った名前をつけることができました。
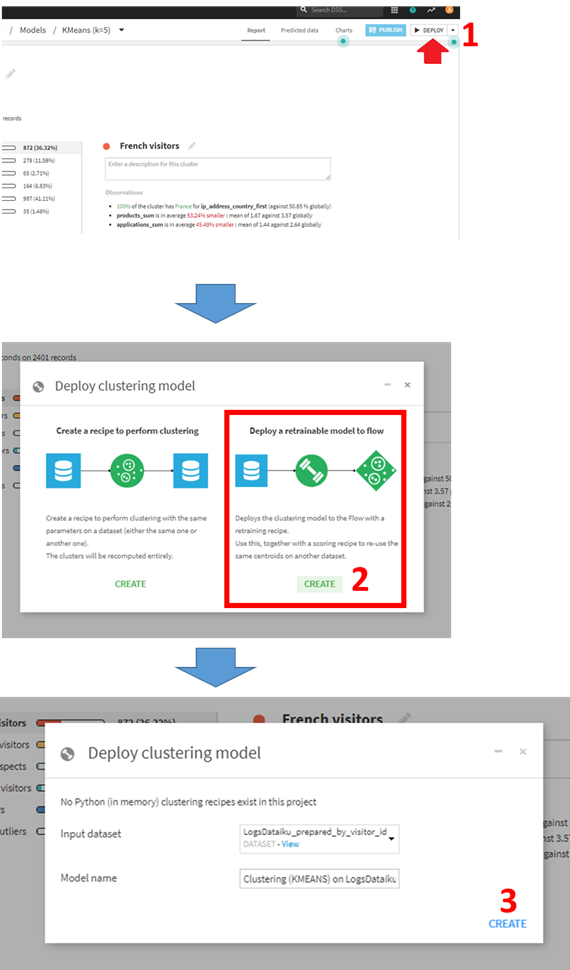
このモデルをフローから使えるようにデプロイします。
- Deployをクリック。
- retainable modelsを選択
デフォルトのままCREATE。フロー画面に遷移します。
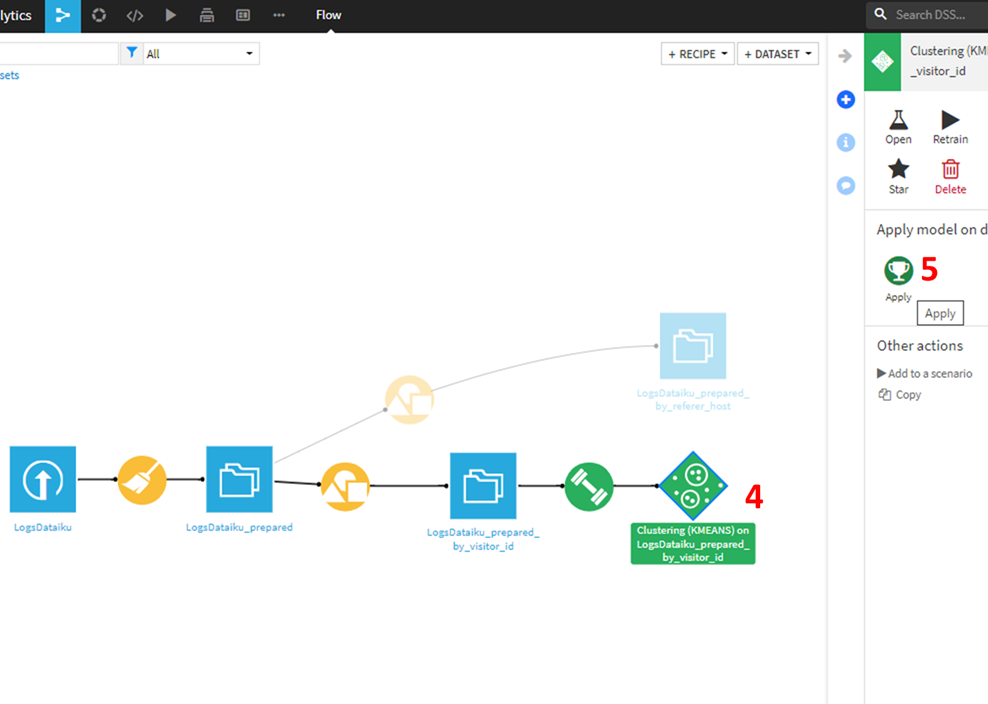
作成したモデルがフローに追加されていることがわかります。作成したモデルをクリックします。
右側に表示されたApplyをクリック。
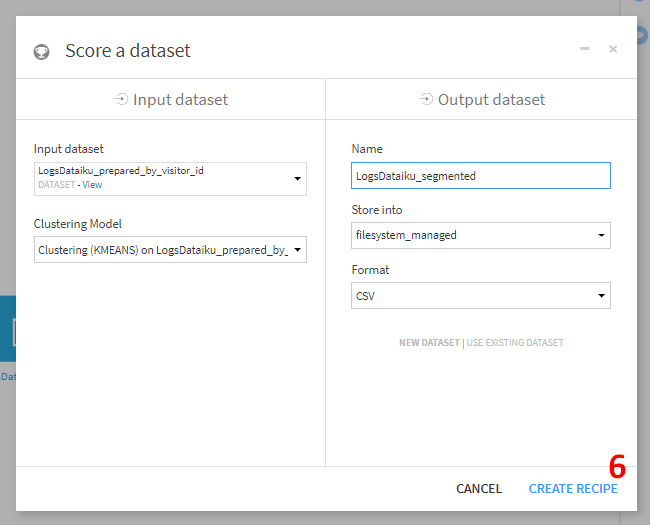
Input datasetに、 LogsDataiku_prepared_by_visitor_idを指定し、output dataset名をLogsDataiku_segmentedに変更し、CREATE RECIPEをクリック。次画面でRUNをクリック。
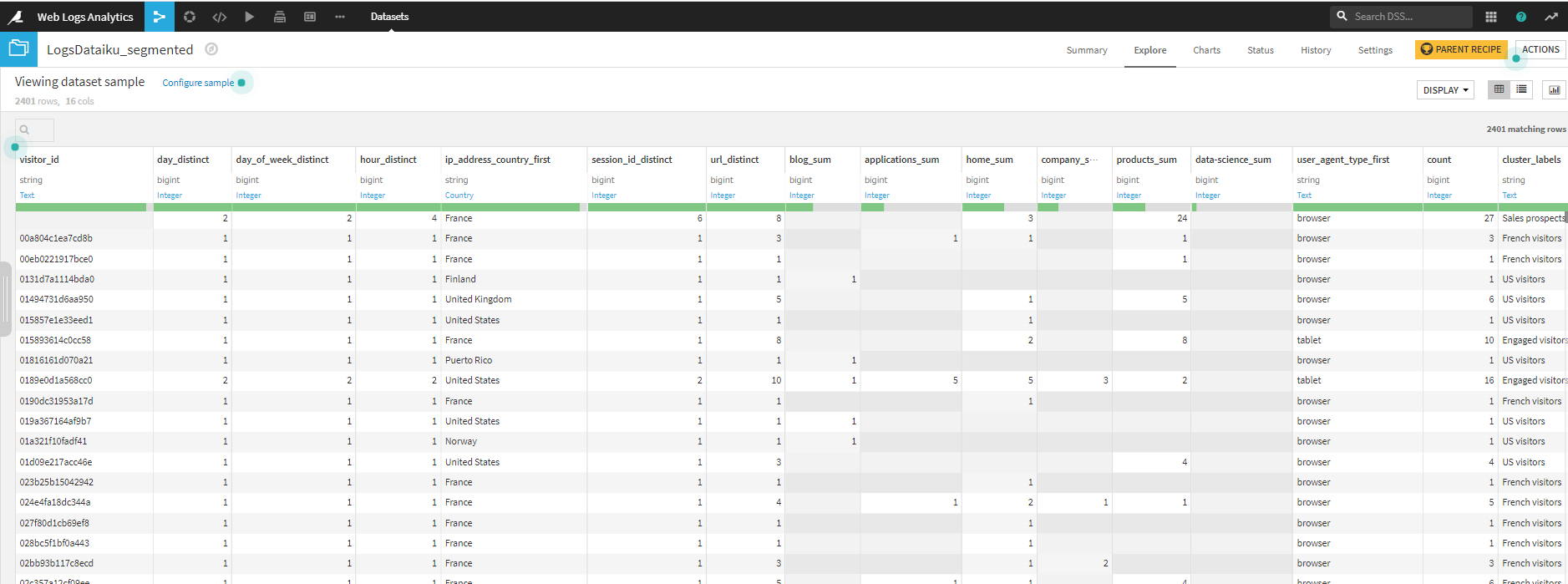
各顧客にクラスタラベルをつけたデータセットができました。
顧客情報とクラスタ情報の対応づけ
Joinレシピを用いて、顧客情報とクラスタ情報を対応づけます。
1. LogDataiku_Segmentedを選択。
2. Join withをクリック。
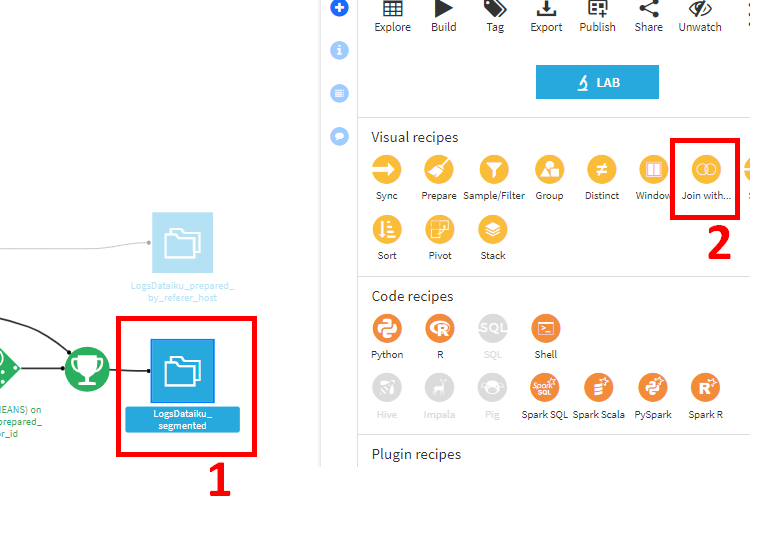
- Input datasetesの上側のデータセットにはLogsDataiku_segmentedが入力されていますが、下側は選択されていない状態になっています。ここにCRMデータセットを設定します。
output dataset側は特に設定を変えないまま、CREATE RECIPEをクリック。Join処理の設定画面に遷移します。Dataiku DSSにより自動的にvisitor_idがキーであると判断されます。
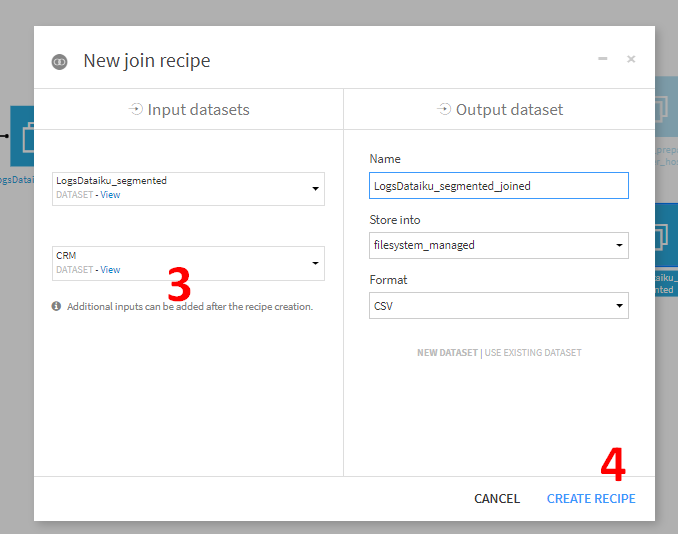
そのままだとLEFT JOINになっていますが、Webサイトを訪れた顧客のみにしぼりたいため、Inner joinに変更します。LEFT JOIN部分をクリックすると、JOINの設定が変更できるポップアップウィンドウが表示されます。
CONDITIONSタブが表示されていあmすので、JOIN TYPEタブに変更します。Inner joinを選択してCLOSEします。
RUNボタン押下により、JOIN処理が実行されます。
クラスタ情報のカスタマイズと他部署への展開準備
それぞれに合うチャネルへ誘導するために、顧客をマーケティング、販売見込み、販売に分類します。
クラスタ情報のカスタマイズ
本来の目的に合うように、クラスタをさらにカスタマイズします。
- LogsDataiku_segmented_joinedデータセットに対して、Prepareレシピを用います。右側のVisual recipesからPrepareをクリック。
Output datasetはデフォルトのままでCREATE RECIPEをクリック。
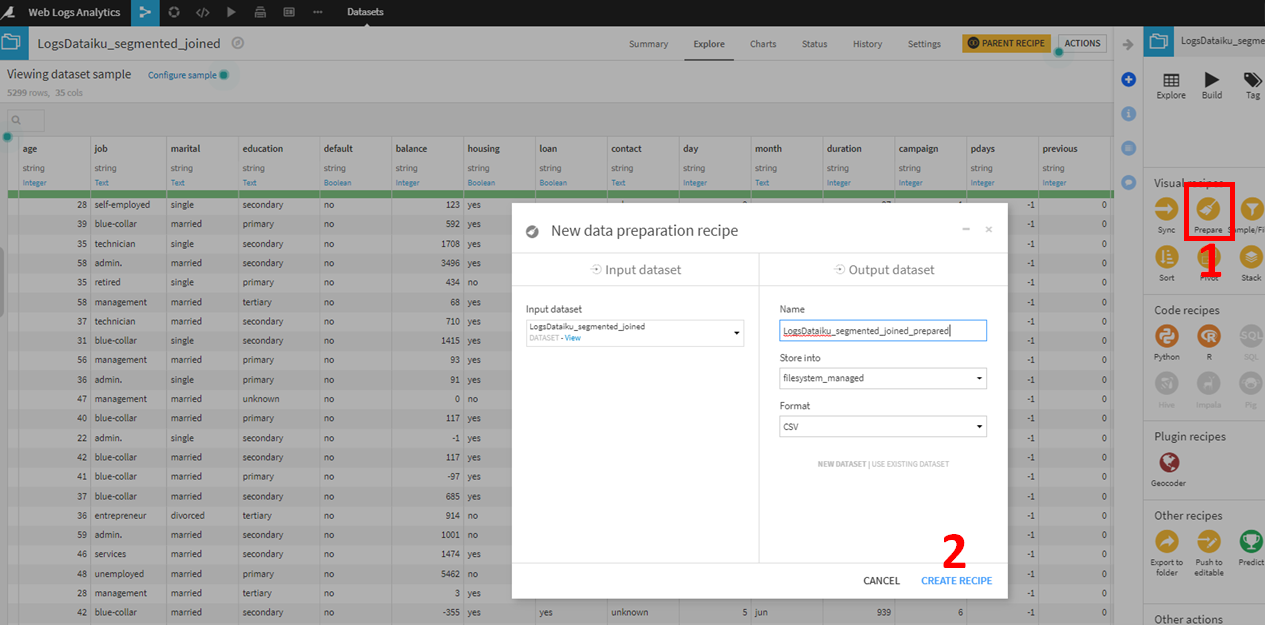
Formula Stepに以下を記載。
if(cluster_labels == "US visitors" || cluster_labels == "French visitors",
"Marketing" +
if(user_agent_type_first =="browser", " - browser", " - mobile"),
if(applications_sum >= 2 || products_sum >= 2,
"Sales", "Sales prospecting"))
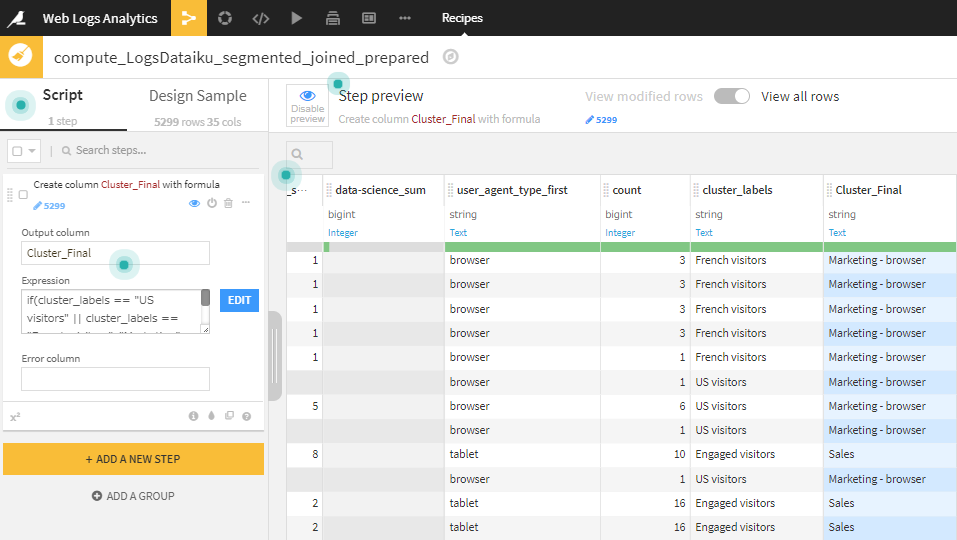
4.RUNボタンクリック。
これで顧客を、Marketing(browser or mobile)、sales、sales prospectiveにわけることができました。
Formulaに記載しているコードの意味ですが以下のようになると思います。
- US visitorsもしくはFrench visitorsはもれなくマーケティング対象
それ以外で、applicationsサイトもしくはproductsサイトに複数回訪れている顧客はセールス対象。
- applicationsサイトもしくはproductsサイトに訪れていないもしくは1回しか訪れていない顧客は販売見込み客。
なぜこのようなカスタマイズをしたのでしょうか。私の想像も踏まえて、例えば以下のように考えてみることができます。
まず、Dataiku社はフランスの会社でデータ分析ツールを販売している会社です。
そして、事前の調査からDataiku社のサイトにはフランスとアメリカからの訪問者が多いという知見が得られています。
このことから、フランスとアメリカの人に対しては敷居が低く訪れやすいサイトであるといえます。もしかしたら、フランスやアメリカの企業には商品をすでにたくさん売っているため、彼らがreferenceページ閲覧や情報収集のために頻繁に訪れるのかもしれません。どちらにしろ、彼らに対しては今後の販売戦略を練るために、マーケティング部で分析してもらうのがよいでしょう。
逆に、それ以外の国からわざわざアクセスがあるということは、かなり真剣に製品について購入を検討している客であるといえます。特に、applicationsサイトやproductsサイトに複数回訪れている顧客は、購入意欲が高い客ということで販促メールを送れば商品を買ってくれるかもしれません。
applicationsサイトやproductsサイトにあまり着ていない顧客は、購入意欲はあまり高くないが、データ分析ツールに興味はあるという顧客かもしれません。いきなり販促メールを送るのかどうかは迷うところであり、別の戦略をとった方がよいかもしれません。
いずれにしろ、上記3パターンごとに異なる戦略でアプローチした方が良いと考えられます。
他部署への展開
分類済みの顧客リストですが、マーケティング、販売、販売見込みで担当者や担当部署が異なるケースがあります。そのため、それぞれ別々のリストに分けて、各担当へ送付します。
ここでは、データセットをDataiku DSS上で分割する方法について学びます。
- フロー画面でLogsDataiku_segmented_joined_prearedを選択
- Splitをクリック。
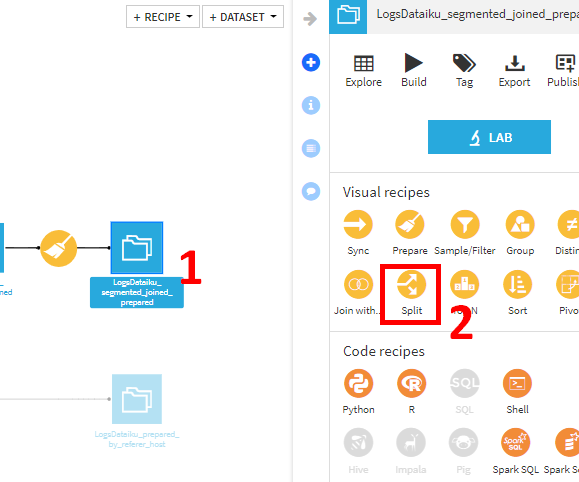
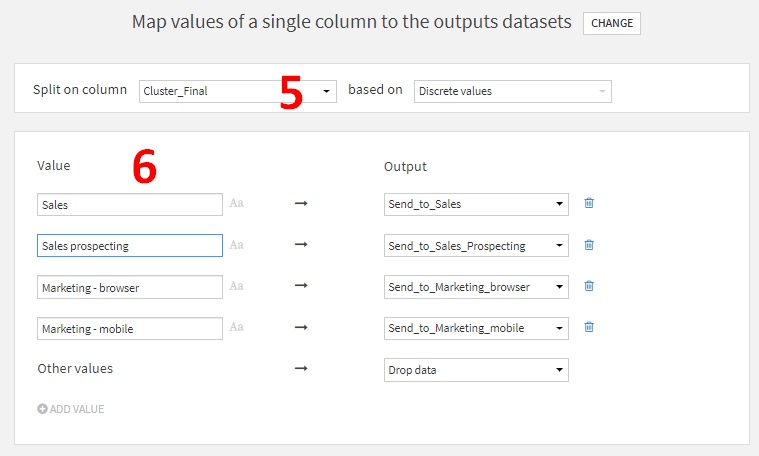
- +ADDクリックで分割先のデータセットを追加できるので、以下の4データセットを追加してCREATE RECIPE.
- Send_to_Sales
- Send_to_Sales_Prospecting
- Send_to_Marketing_browser
- Send_to_Marketing_mobile
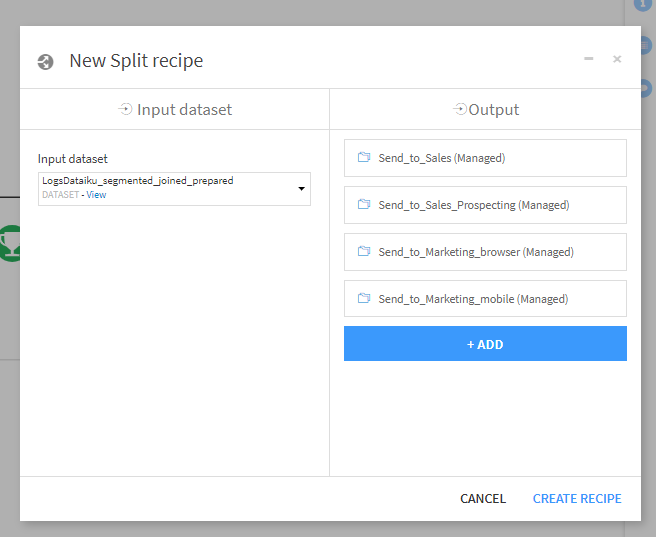
- select splitting methodでMap values of a single columnを選択。
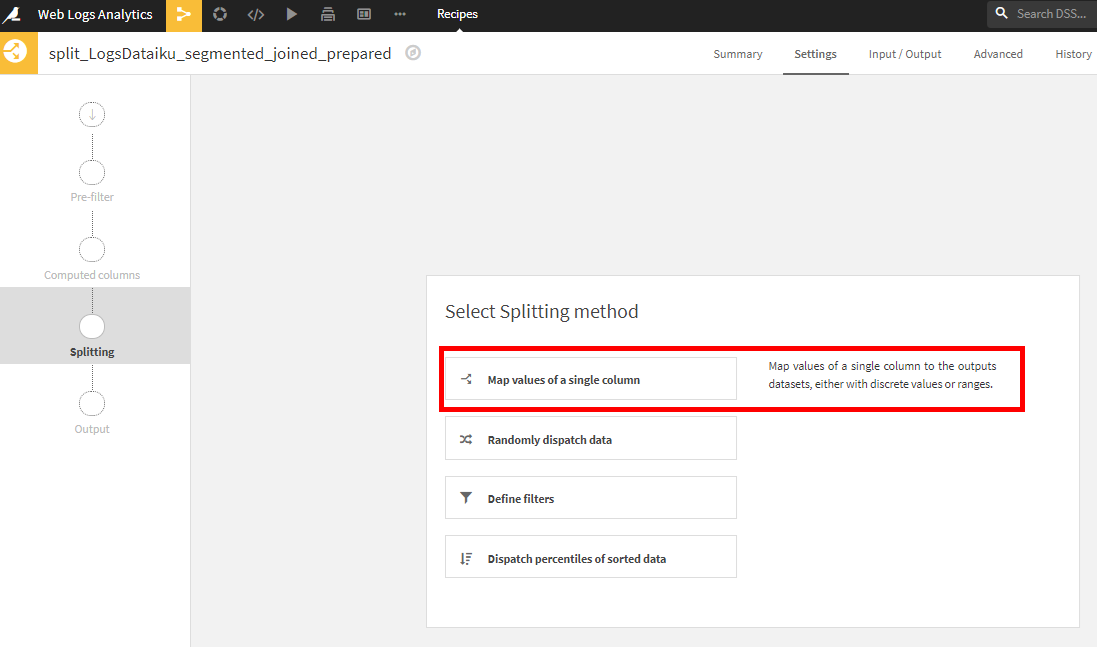
- Split on columnにCluster_Finalを指定。
- それぞれのOutputに合うように、Cluster_Finalの値をValueに入力。たとえば、Cluster_Finalの値がSalesの行をSend_to_Salesデータセットに分けるといったようにデータが分割されます。
フローを確認してみると、4つのデータセットに分割されていることがわかります。
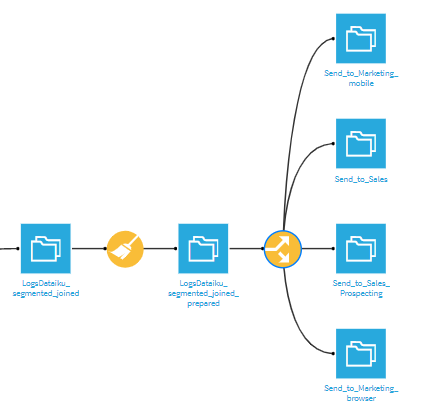
これらのデータセットを担当部署ないし担当者に送付すれば、販促メールなどの対応に使ってもらうことができるでしょう。