DataikuのDrift Pluginについてちょっとまとめました。
Dataikuのversion 10.0.2で試しています。
うかうかしている間にversion11がでてしまいましたね。でもこのへんは大きくかわってないはず。
Drift Plugin
Evaluation Storeは便利ですが、以下の欠点があります。
- モデルを作成しないと使えない。一旦作成したモデルに対して評価用データの精度を出すことは可能です。
- 正解データがわからないと使えない
そこで、モデルを作成しないような場合や、正解データがわからないと使えない場合でも、データドリフトを検出したいときに使えるのがDrift Pluginです。DataikuのPluginsからダウンロードして使うことができます。
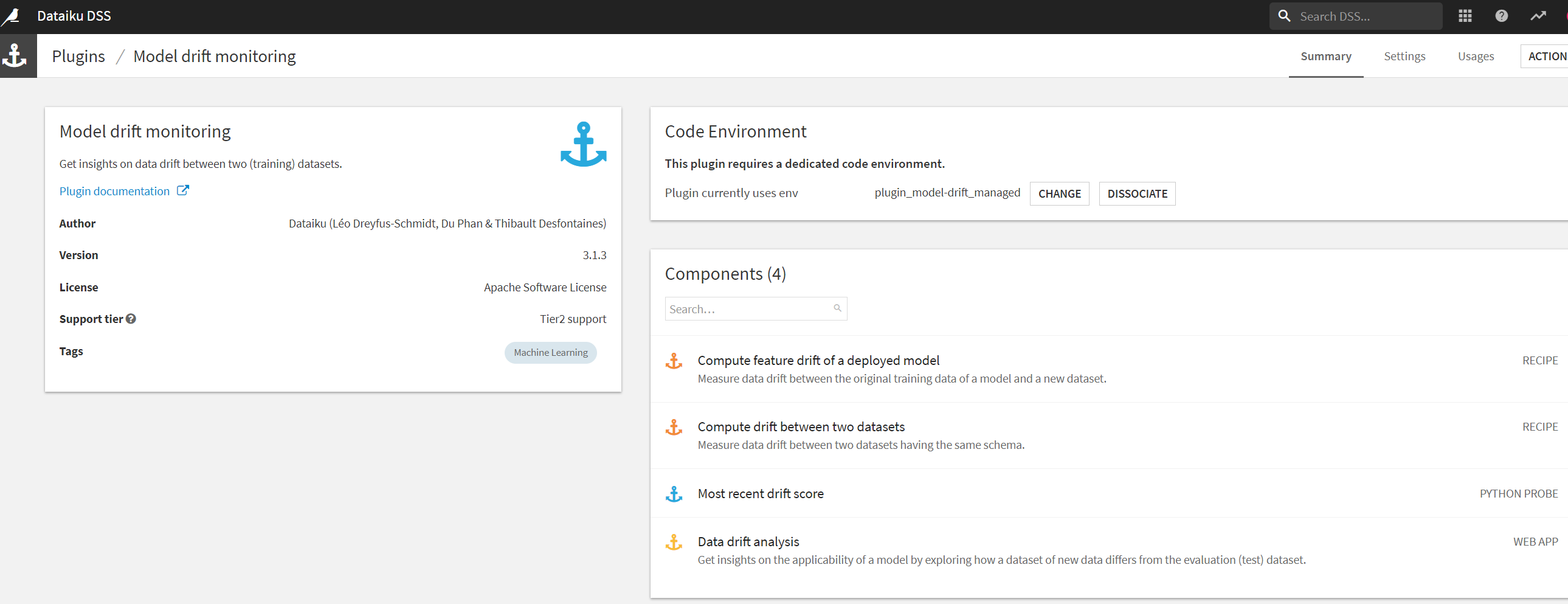
プラグインの中には以下の4つの機能が入っています。
- Compute feature drift of a deployed model
デプロイされたモデルの特徴ドリフトを計算する
モデルの元の学習データと新しいデータセットとの間のデータドリフトを測定。 - Compute drift between two datasets
2つのデータセット間のドリフトを計算する
同じスキーマを持つ2つのデータセット間のデータドリフトを測定。 - Most recent drift score
直近のドリフトスコア - Data drift analysis
データドリフト解析
新しいデータセットと評価(テスト)データセットがどのように異なるかを調べるためのツール。
順番に使ってみます。
まずは、レシピとして使える以下2つから。
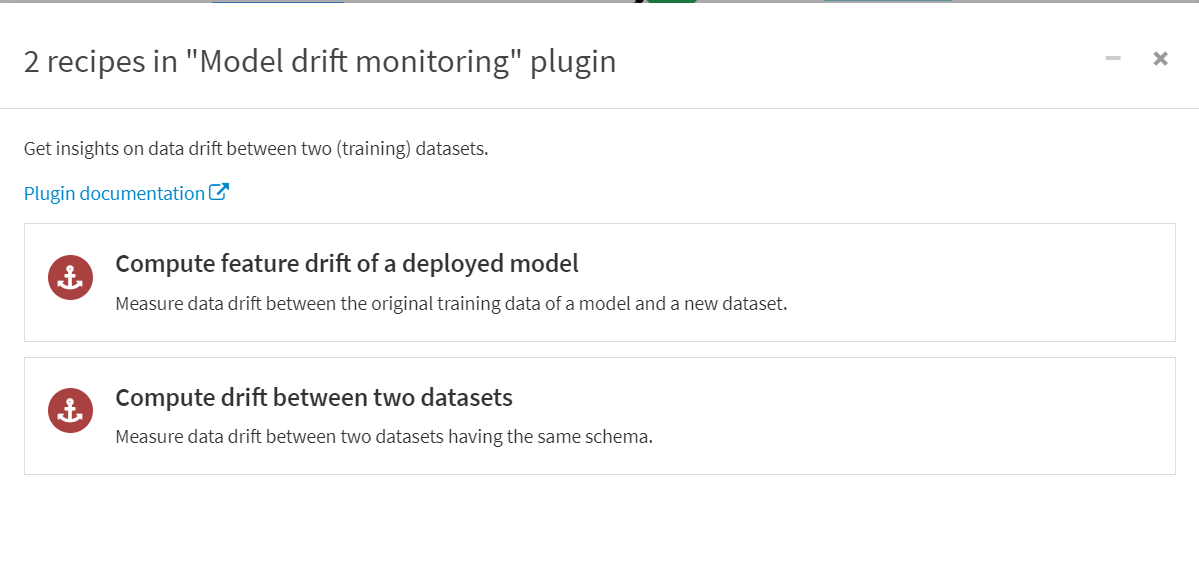
Compute feature drift of a deployed model
新しいデータセットと、モデル、評価値の出力先データセットを指定します。
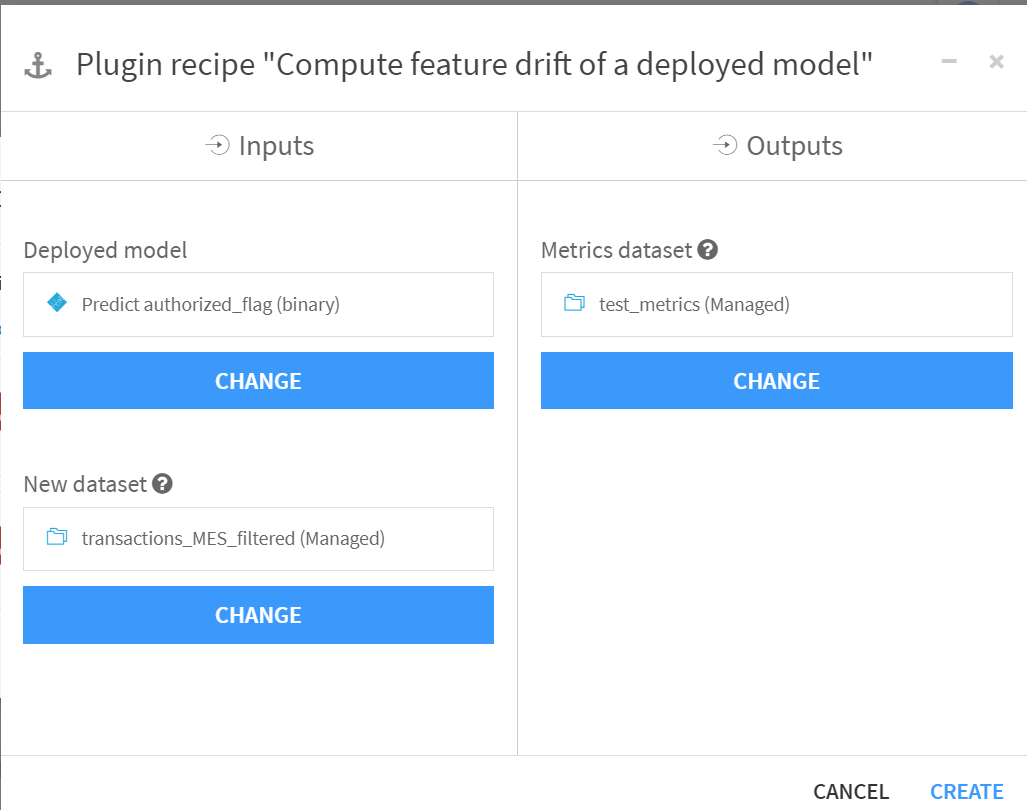
算出する評価値を指定して、左下のRUNボタンを押下します。
出力先データセットとして指定したデータセットに、評価値が算出されました。
drift_model_accuracyがドリフトスコアに対応します。

Compute drift between two datasets
比べたい2つのデータセットを指定し、出力先データセットも指定します。
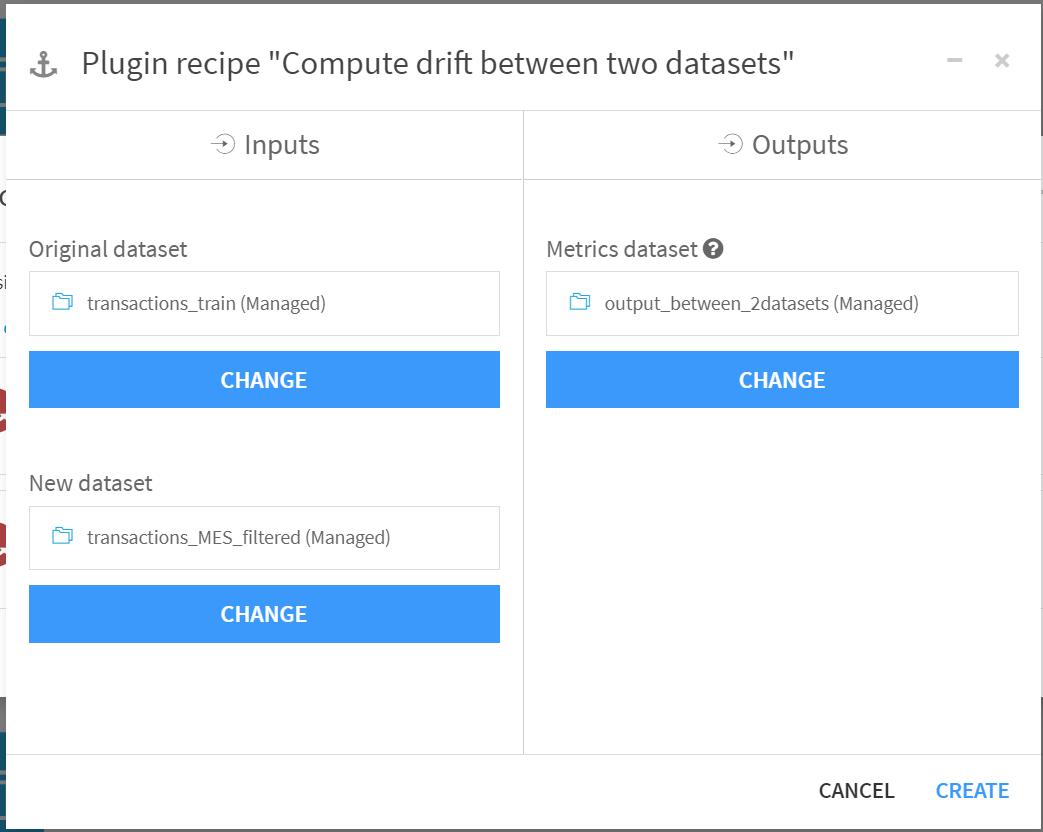
出力する評価値を指定します。ignore columnつまり、計算に使わないカラムを全く指定しなかったところpythonがメモリエラ―おこしてこけたので、とりあえず5カラムくらいまでに絞ってあとは全てignoreに指定しました。
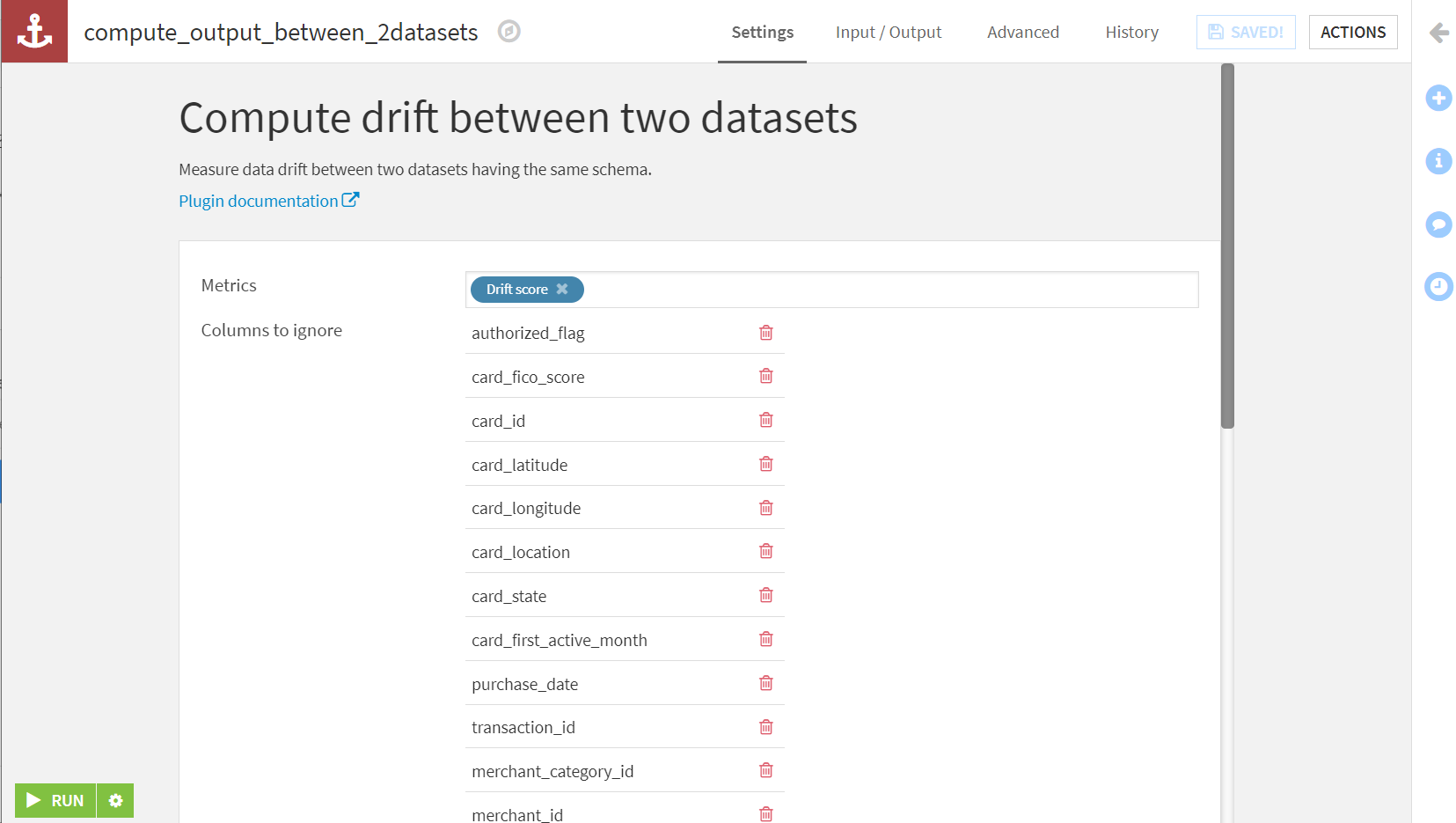
最終結果です。ドリフトスコア(drift_model_accuracy)が算出されています。
Most recent drift score
これは、Check&MetricsでDrift Scoreを監視する機能です。Evaluate Storeにも備わっているので、そっちが使えるときはそちらを使う方が簡単です。
まず、レシピのInput/Outputタブで出力先データセットをアペンドモードにしておきます。これにより、出力が追記になります。
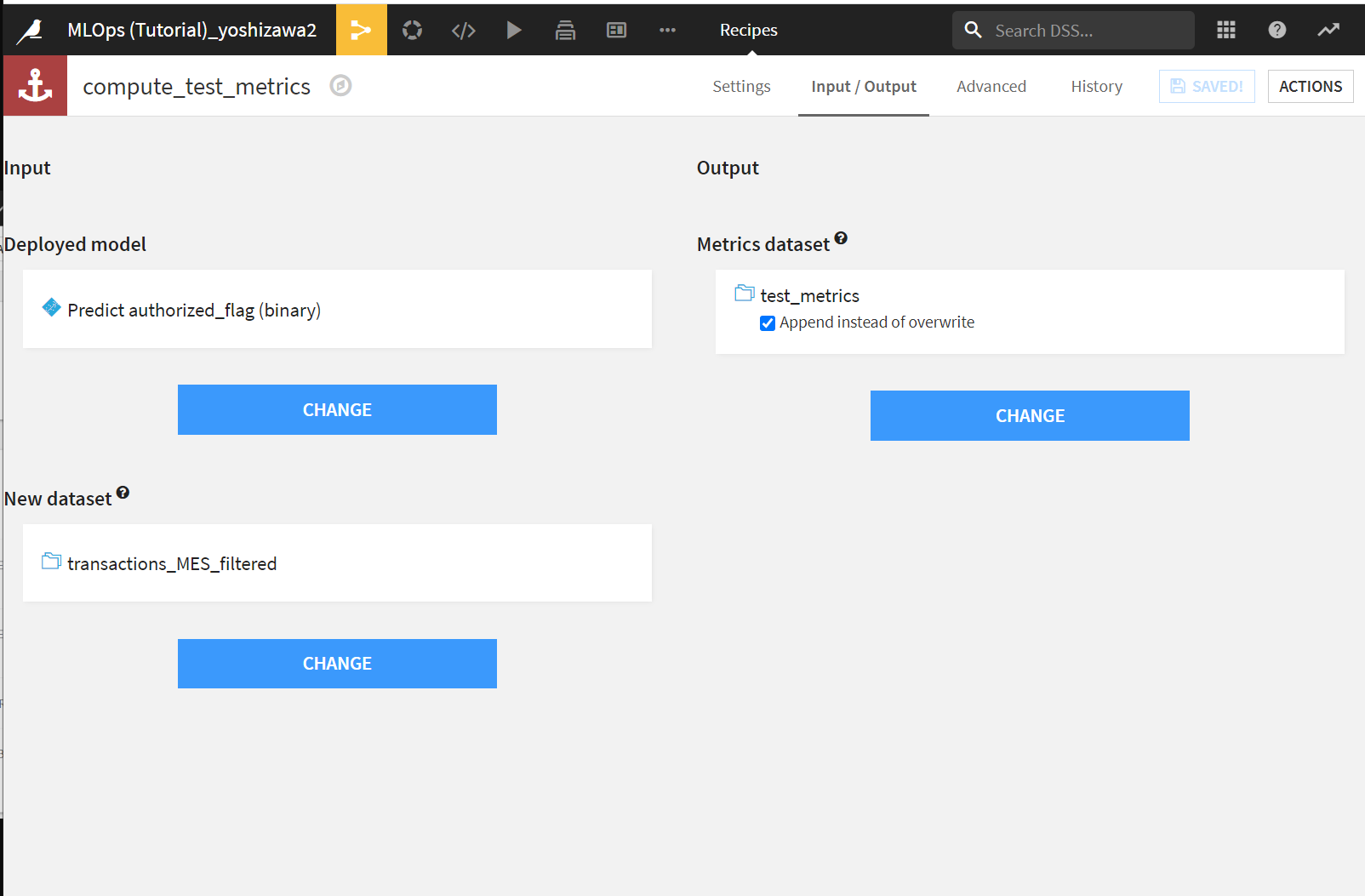
出力先データセットのStatus>Edit>Metricsの下の方にあるNEW CUSTOM PROBEをクリックします。
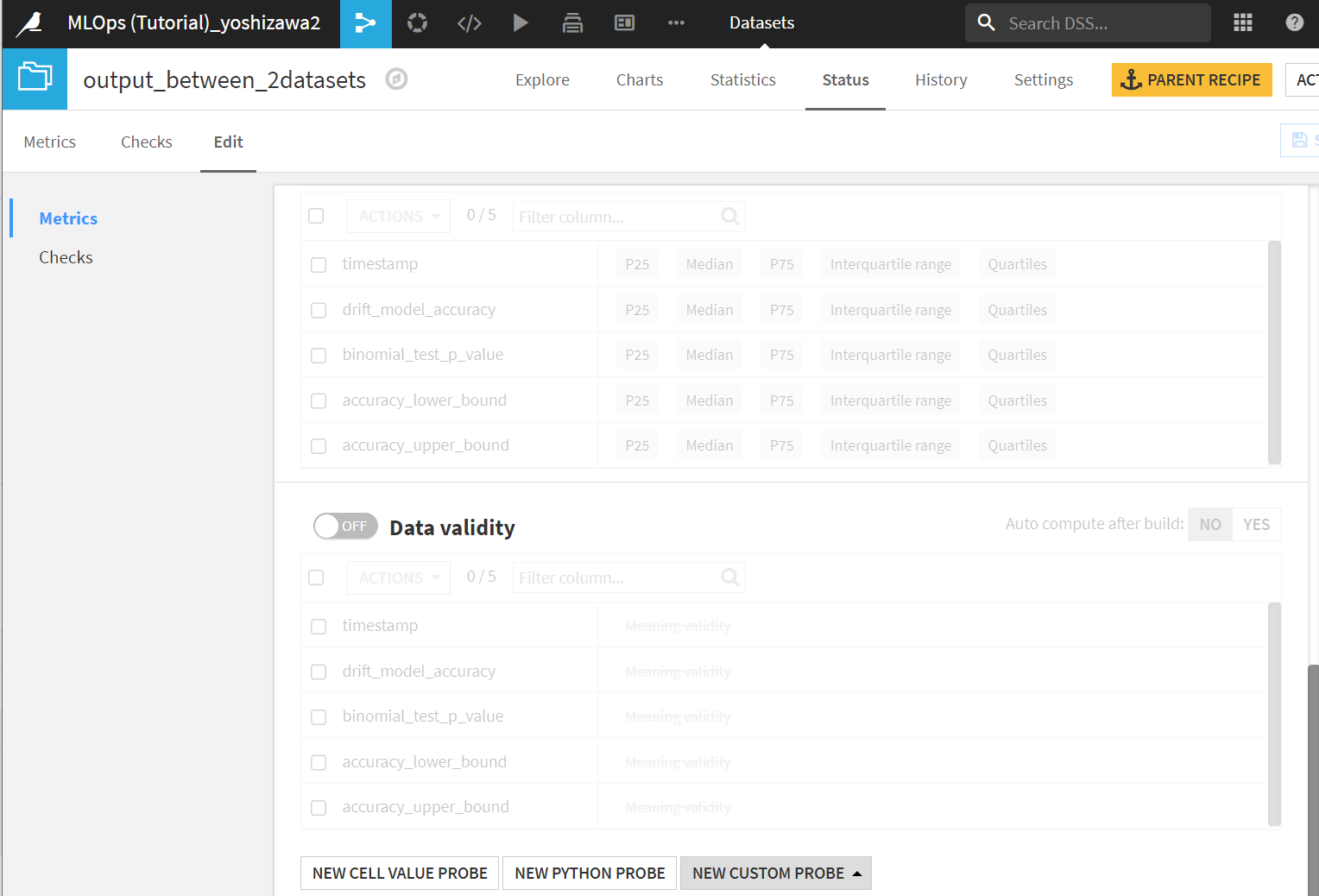
こんな風にでてくるので、Model drift monitoring>Most recent drift scoreを選択します

ONにします。
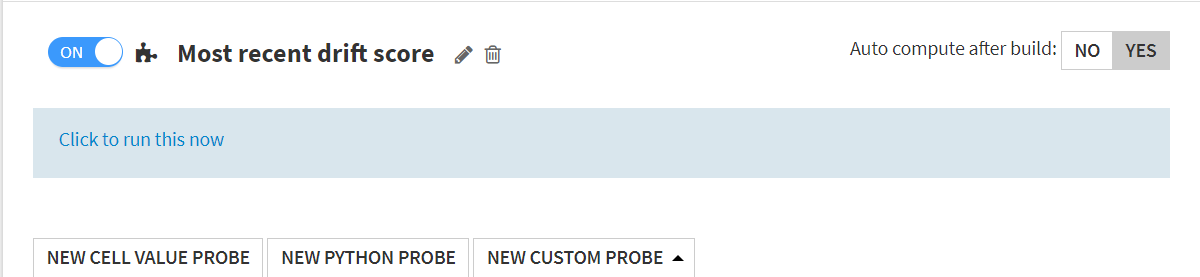
SAVEを押下します。あとは普通にCheckでデータドリフトスコアの範囲の設定などできますので、普通のMetricsと同じように好きなように料理します。
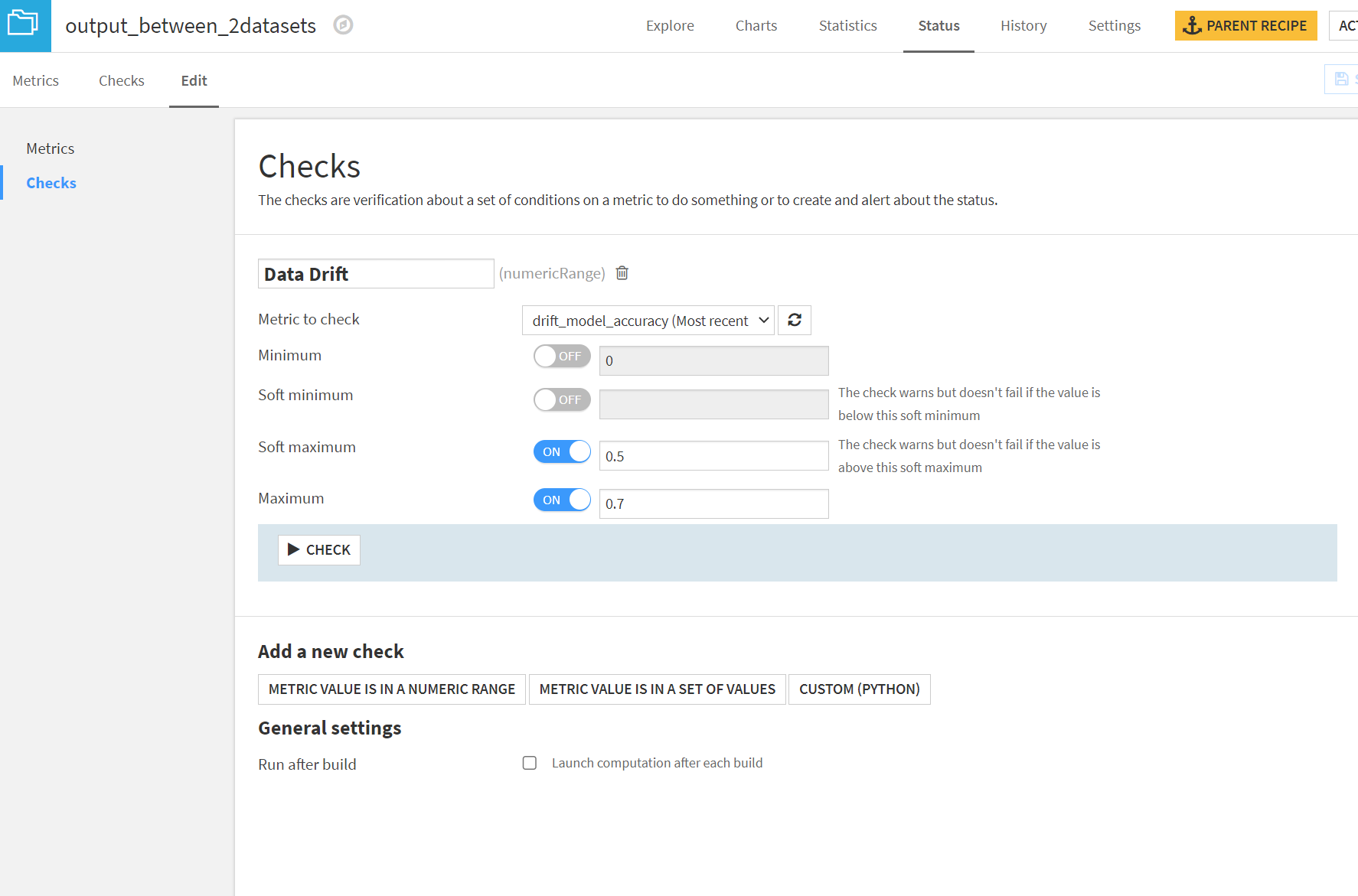
Data drift analysis
この機能はVersion10よりEvaluation Storeでも提供されています。Evaluation Storeを用いたほうが、Metrics&Checksに組み込めるので良いと思います。
ここでは、プラグインだと、こうといったことを説明しますが、Evaluation Storeとかなり被るし、向こうの方が上位互換って感じです。
モデルのReportのViews画面を開きます。
View model asでData drift analysisを押下します
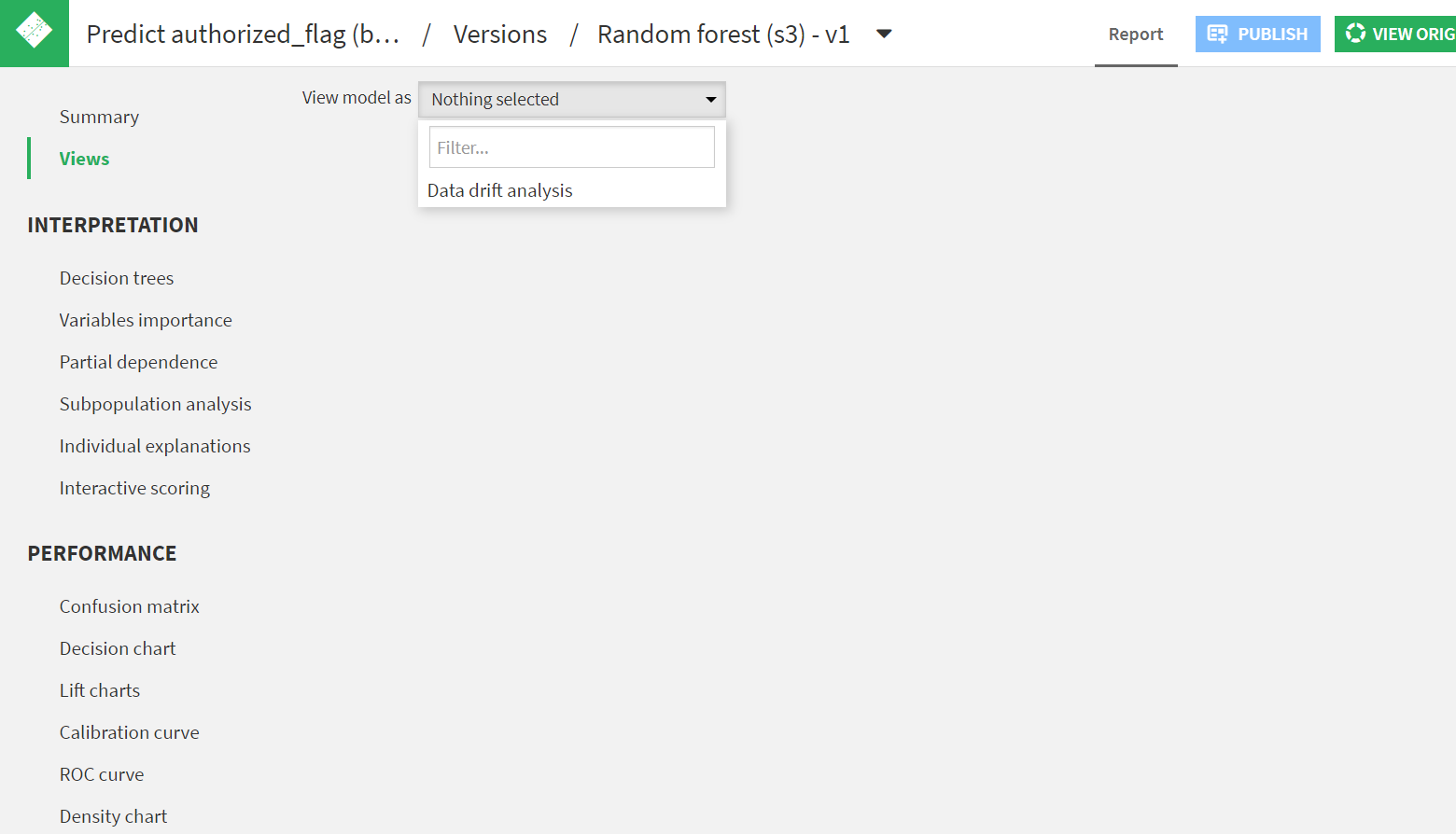
Select dataset containing new test dataを選択し、[COMPUTE DRIFT]を押下します。
いくつかの可視化画面が表示されます。次に順番に説明します。
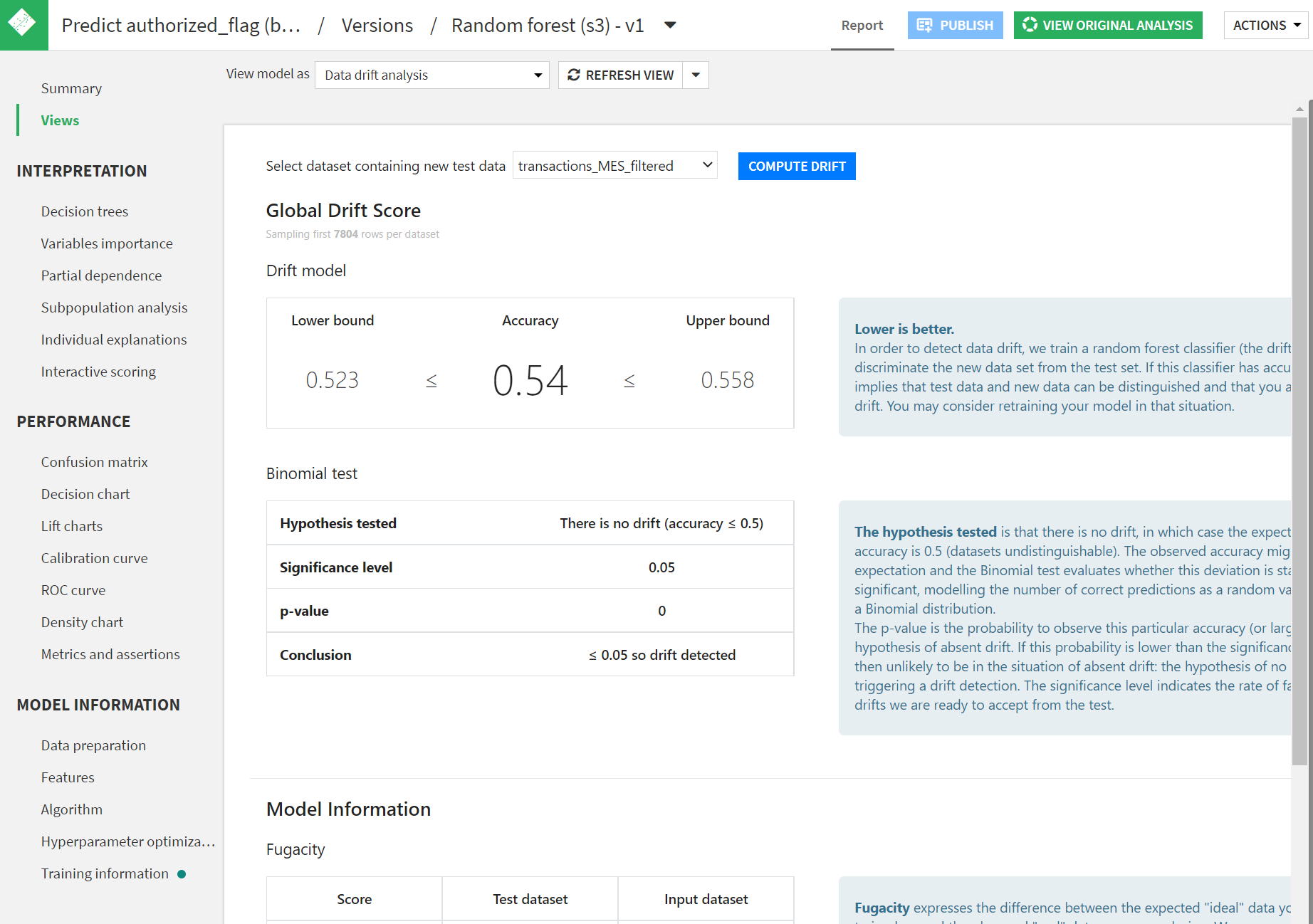
Global Drift Score
Drift model
データドリフトスコアを表示します。これは0.5付近だと良いスコアです。中身は、ランダムフォレスト分類器で新しいデータセットとテストセットを識別し、そのAccuracy(正答率)の値です。つまり高精度で判別できていたら新しいデータセットとテストセットが区別できてしまい、データドリフトを観測していることを意味します。ちなみにAccuracyが低すぎる値は基本的に出ないはずです(例えばaccuracy0はラベル逆転させればaccuracy1と同様なので)。
Lower boundとUpper boundはAccuracyの信頼区間を示しています。この範囲内に0.5が入っていればまあ大丈夫そうかと。
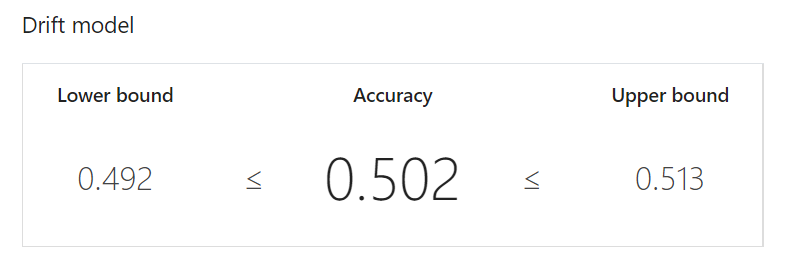
Binomial test
- Hypothesis tested :二項検定の検定結果です。「ドリフトがない」つまりデータセットが区別できないということを検証される仮説としています。今回はドリフトは無いという結果です。
- Significance level :p-valueにおける有意水準αです。
- p-value :ドリフトがないという仮説のもとで、このテストによってドリフトが誤って検出される確率を示します。今回の結果ではここの値がSignificance level(0.05)より大きいので仮説は棄却されません。
- Conclusion :結果どうだったかということで、今回はドリフトは検出されませんでした。
ここからは、この検定についてのちょっと補足です。何を検定しているかという話になります。
二項検定、つまり母集団比率の検定を行っています。
実際の確率が0.5である場合、このドリフトスコアが得られる確率は何%かを求め、その値に対して有意水準を用いて棄却されるかどうか判定しています。
ここで母集団として仮定しているのは母集団比率が0.5(p=0.5)の二項分布。つまりランダムに母集団から1つサンプルをとってきた時に、それが新しいデータ由来か古いデータ由来かの確率が0.5という二項分布を仮定しています。
そして、標本比率にドリフトスコアを使っています。
p=ドリフトスコア、n=レコード数(新しいデータの数+古いデータの数)の事象が、仮定した母集団において有意水準αとしたときの棄却域に落ちるかどうかで検定をしています。
Model Information
このへんも、Evaluation Storeと被りますが、Evaluation Storeの方が機能が多いですね。
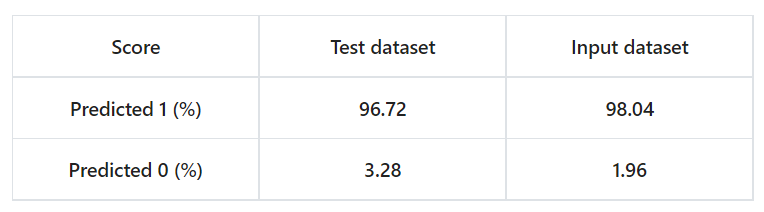
Fugacity
モデルが学習した期待される「理想的な」データと、解析している観測された「実際の」データとの差を表します。テストデータセットと入力データセットの両方でスコアリングしたときに、各クラスに予測されるサンプルの割合を比較できます。
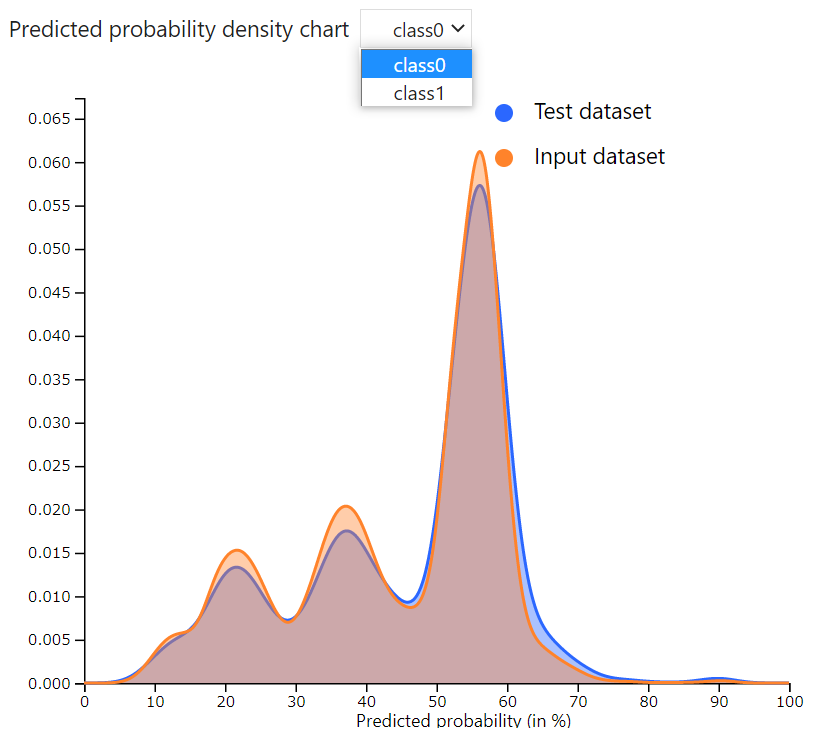
Predicted Probability density chart
テストデータセットと入力データセットのスコアの分布になります。見た目からも分布はかわらないことがわかります。
Feature Drift Overview
各Featureに対して、縦軸に元のモデルに対する重要度、横軸にドリフトモデルに対する重要度を散布図でしめしています。
もしドリフトが発生していたら、右上にあるやつが原因かも、ということになります。
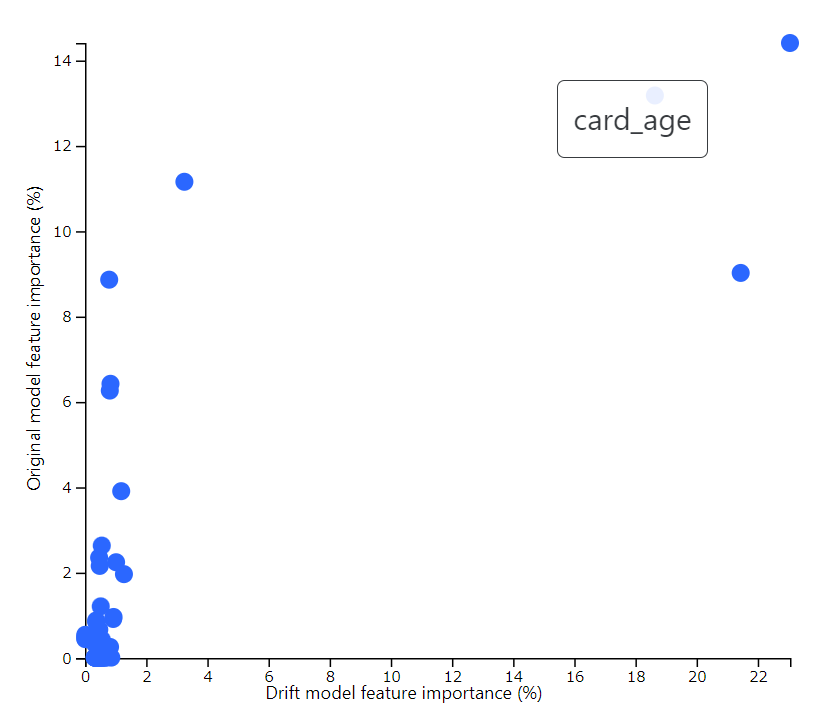
右側の英語のところにどの特徴が要注意かといったことがかかれています。
一番下の「We recommend you to check the following feature(s): card_age, purchase_amount」ですね。card_ageとpurchase_amountこれらは右上にある二つの青丸に相当します。といって、今回のデータはドリフトスコアからみればドリフトが発生していないので、特にここの結果は気にする必要はないでしょう

さいごに
Drift PluginのData Drift Analysisは完全にEvaluation Storeの下位互換ですね。Evaluation Storeの方が機能豊富なので、またそっちもまとめて整理しておきたいと思います。