はじめに
Dataiku DSSを使っていると、フローがぐちゃぐちゃになったり、見にくくなったりすることがあります。
もっとうまく使うコツは無いものかと思い、公式サイトのベストプラクティスのページを日本語訳してみました。
字ばかりでわかりにくい部分もあったので、操作説明多めにいれています。
Flow management
Anchoring
インプットとアウトプットが明確なパイプ状で無駄なブランチが無いFlowが理想的なFlowです。
しかし、実際は多くの短いブランチを含むFlowを作成するケースもあります。このようなFlowは、デフォルトの設定のままだと、Flow画面上の入力データセットと出力データセットの位置が自動的に調整されます。これにより、Flow画面上で短いブランチが長く右端まで延び、Flowの全体が把握しにくくなることがあります。

Anchoring設定をオフにすることで、Flowの表示を変えることができます。
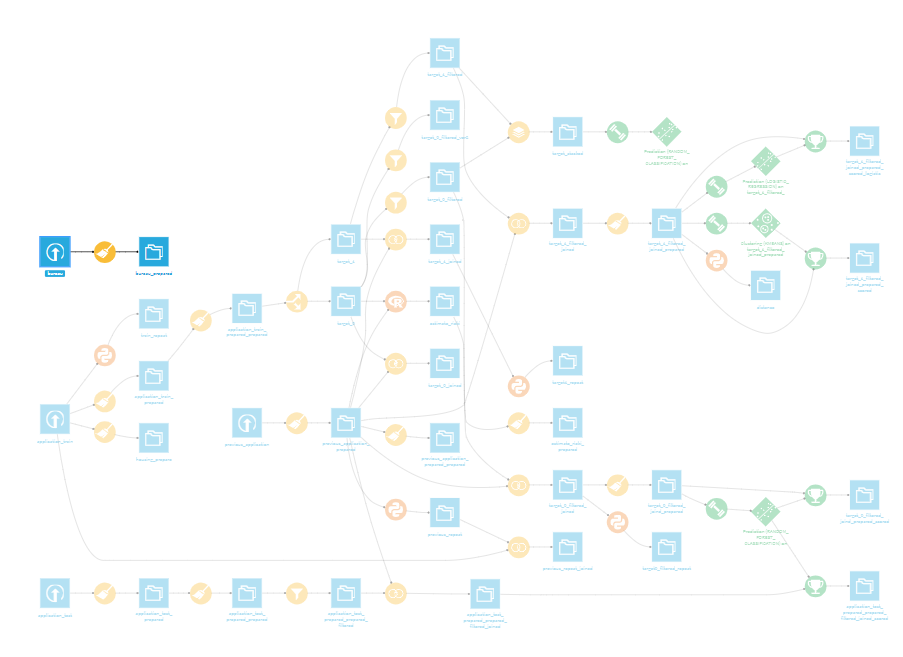
Anchoring設定は、プロジェクトの設定画面から変更することが可能です。
-
プロジェクト画面からsettingsを選択。

-
Flow displayを選択し、Anchor Flow graphの☑をはずし、SAVEボタンを押下。
Dataset and models exposition
プロジェクトを利用した作業分割
Frowが複雑になる場合は複数のプロジェクトを使用して作業を分割するとよいです。
例えば、以下のように機能ごとにプロジェクトを分けることができます。
- データ収集用
- 次に機械学習と分析用
- 視覚化用
##### プロジェクト間のデータセットの共有 (有料版で確認してもこの機能は確認できなかったため古い情報である可能性有り)
別のプロジェクトでプロジェクトのデータセットを使用するには、データセット(またはモデル)を別のプロジェクトに公開します。公開されたデータセットは、他のプロジェクトのソース要素になります。
プロジェクトの公開方法は以下。
settings→config→exposed elements and expose datasets (or models) to another project
これは、大きな事業をいくつかのプロジェクトに分割し、各ユーザーが自分のプロジェクトで作業できるようにする方法です。
一部のユーザーは、他のプロジェクトに公開することを意図したデータセットを主に含む「データマート」プロジェクトも作成します。
プロジェクト間の依存関係はすぐに迷路になり、データセットを公開する前に全体像を把握できることに注意してください。
Refactoring
Refactoringについてはまだ改善予定ですが、現段階でも実施可能です。
フローをシンプルかつ見やすく保つために以下のことに気を付けてください。
- 時々リファクタリングしましょう。
- レシピを一時的にコピーすることは推奨されません。時間がある場合は、フローを組みなおす方が良いです。
- フローに新しくブランチを追加する場合は、それが何のために必要か、またいつ削除可能となるかについて明記しておきましょう。
- 自分の担当分は整理しておきましょう。メンバー間で使いまわし出来そうな実装については共有しておき、車輪の再発明をしないよに気をつけましょう。
- 他メンバーの作業について知っておき、それらが自分の担当分にも応用できるか尋ねましょう。
Doing exploratory work
新しいコードレシピ(Python、R、SQL…)が必要な場合、次のことをお勧めします。
意味のある名前で新しいノートブックを作成します。
必要なコードをインタラクティブに開発します。ノートブックでは、各ステップでコードを実行できます。正しい軌道に乗っているかどうかは常にわかります。
コードが満足のいくものになったら、それをレシピに変換します。
SQLの場合、ノートブックの「レシピに変換」をクリックします
Pythonの場合、「.pyとしてエクスポート」をクリックし、コードをコピーし、新しいPythonレシピを作成し、コードを貼り付けます(これは将来のバージョンで簡略化される可能性があります)
Flow navigation
常にフローに戻ってナビゲートする必要はありません。ショートカットボタンがあります。
データセットで、「Parent recipe」ボタンを試してください
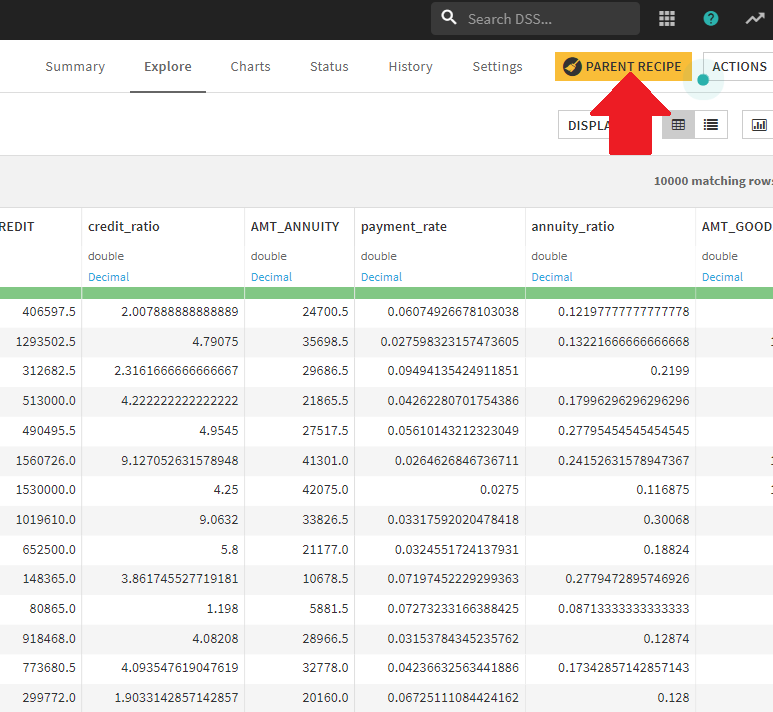
レシピで、「出力を入力」をクリックしてから、データセットの名前をクリックして開きます。
ショートカットShift + Aを使用するか、コンパス(作業中のレシピ/データセットの名前の横)をクリックして、ナビゲーターを表示します。
Rebuilding the flow
Rebuilding one element
データセットのビルドにはいくつかの種類があります。
データセットを右クリック、Buildボタンで以下のポップアップウィンドウが表示されます。

-
Build only this dataset(図の左側)
選択されたレシピのみ実行されます。 -
Recursive build(図の右側)
こちらはさらに3つのモードにわかれます。

- Smart reconstruction
上流のデータセット(つまり選択しているデータセットの左側にあるすべてのデータセット)に対して、最近変更されたかどうかをチェックし、変更された場合は影響を受ている全データセットも再構築します。デフォルト推奨です。 - Forced recursive rebuild
すべての上流データセットを再構築するモードです。たとえば、1日の終わりに実行することで、全データセットを夜間のうちに再構築し、翌日ダブルチェックされた最新のフローで開始することができます。 - "Missing" data only
「Smart reconstruction」と同様ですが、データセットが空の場合にのみ(再)構築するモードです。
- Smart reconstruction
Propagate schema changes
新規項目追加や、特徴量作成実施等のように、フローの途中で、データセットのスキーマを変更する場合があります。そのようなときのために、「Propagate schema changes(スキーマ変更の伝播)」機能が準備されています。
データセットを右クリック⇒[Propagate schema across Flow from here]をクリック。
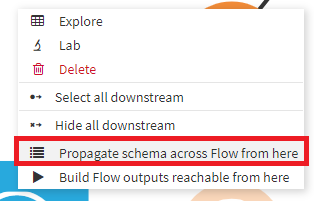
左下に小さなウィンドウが表示され、フローの色が変わります。ここではtestデータセットに対して実行したため、testデータセットのみが緑で、それ以外がグレーとなっています。ちなみに緑は「OK」、グレーは「未チェック」というように色によって各レシピやデータセットのステータスがわかるようになっています。testデータセットは緑ですがこれより上流にはチェックが入らないため常に緑であり「OK」にカウントされません。
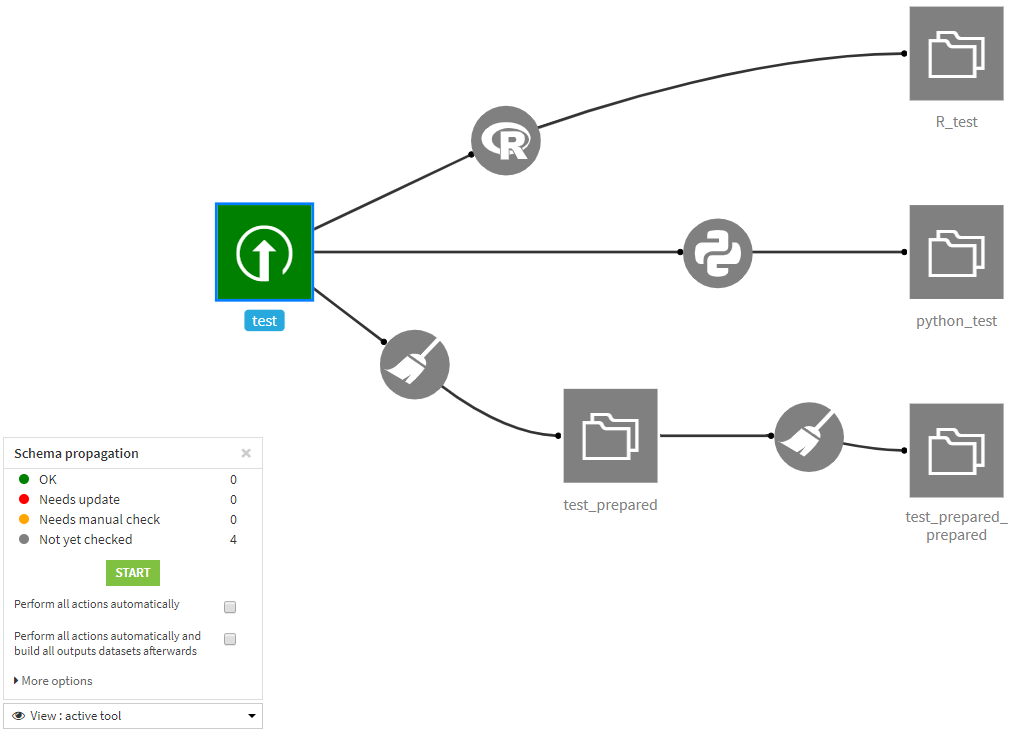
Startボタンクリックによりスキーマがチェックされます。
スキーマに問題がないデータセットやレシピは緑色に変化します。
Rやpythonのように自動でチェックが難しいものは、「要マニュアルチェック」扱いになりオレンジ色になります。
「要アップデート」が必要なレシピについては赤色になります。ちなみに、test_prepared_preparedまで作成したあと、test_preparedで1列減らしてビルドしたため、test_preparedとtest_prepared_preparedでデータセットのスキーマに矛盾が起きています。

test_preparedのスキーマに問題が無いようならば、「ACCEPT ALL CHANGES」押下によりスキーマの変更が下流のデータセットに適用されます。

ちなみに、pythonやRのような内部のコードを読まないとスキーマの変更がわからないようなものについては、チェックできません。その場合は、フロー上で手動チェックを意味するオレンジ色にレシピが表示され、その先のフローは未チェックを示すグレーとなります。
Build from here
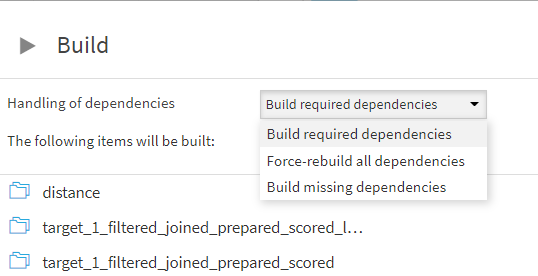
フローの途中にあるレシピに変更を加えた場合、そこから下流のみを再計算する機能として、「Build from Here」があります。
データセットを右クリック、[Build Flow outputs reachable from here]

下流の依存関係にあるデータセットが、再ビルド対象として一覧に出ますので、問題なければBUILDボタンを押下。

ちなみに、オプションでどのようなBuildを行うか選択可能です。各オプションの意味についてはRebuilding the flowの項をご参照ください。
以上です。
Anchoringやflow navigationは地味に便利な感じですね。
あとは、フローを作業ごとの分割するとか、フローがカオスにならないためには非常に大事な気がします。