テーブルデータを使うときに、pandasaiが便利そうだったので使ってみました。
サンプルを触りつつ、日本語がどれくらいいけるのか試します。
ライセンスがMITなので、自由度高くてよいですね。本家pandasとは無関係のプロジェクトだそうです。
TL;DR
- pandasaiを実際に動かして試してみました。
- テーブルデータに対して、自然言語で返してくれたり、グラフを描いてくれたりしてくれますが、日本語に対してはいまひとつ。
- 日本語の文章で、うまく答えられない時がある。
- データの項目名が日本語だと、うまく動かない
- テーブルデータそのものは、opanAI APIに送らず、ヘッダのみを送っている。ヘッダも加工して送っているため、データが外に漏れない安心仕様。
- google colabのサンプルデータが雑
- 出てきた結果が適切かどうかは、人の判断が必要(あたりまえ)
PandasAIとは?
読み込んだデータフレームのヘッダとユーザープロンプトから、pythonのコードをLLMに生成させて、その処理結果を返すライブラリ。処理結果は、図がかえってくることもあれば、自然言語の場合もります。
基本的に、ヘッダしかLLM側に送らないので、プロンプトにのらないような巨大なデータも扱えます。
環境
google colabで試しました。
openAIのgpt-3.5-turboを利用。
インストール
PandasAIのインストールは簡単です。以下のコマンドを実行するだけでインストール可能です。公式サイトにもかいてありますが、どうみてもenv整備必須ですね。
! pip install --upgrade pandas pandasai
下準備
公式サイトのデモそのまんまです。コピペ。
データは、十か国のGDPと幸福度指数の架空データです。
インポートのところで、OpenAI用のモジュールを呼んでいますが、pandasai自体は、他のLLMにも対応しているようです。
# ライブラリのインポート
import pandas as pd
from pandasai import PandasAI
from pandasai.llm.openai import OpenAI
# データ作成
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [21400000, 2940000, 2830000, 3870000, 2160000, 1350000, 1780000, 1320000, 516000, 14000000],
"happiness_index": [7.3, 7.2, 6.5, 7.0, 6.0, 6.3, 7.3, 7.3, 5.9, 5.0]
})
# openAIの設定
OPENAI_API_KEY = "OPENAI_API_KEY"
llm = OpenAI(api_token=OPENAI_API_KEY)
これで設定完了。非常に簡単です。
使ってみる。
公式サイトに載っている、google colabの公開サンプルを使っていきます。
英語で試す
幸福度が高い国を5つあげてもらいます。
公式サイトが英語なので、こちらも英語で。
pandas_ai = PandasAI(llm)
pandas_ai.run(df, prompt='What are the 5 happiest countries')
[結果]
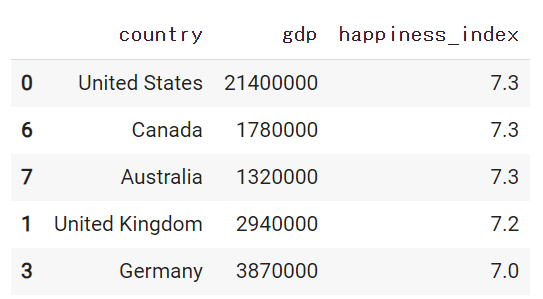
ちゃんと表でだしてくれました。
pandasらしくグラフを描くこともできます。
pandas_ai.run(df, "Plot the histogram of countries showing for each the gpd, using different colors for each bar")
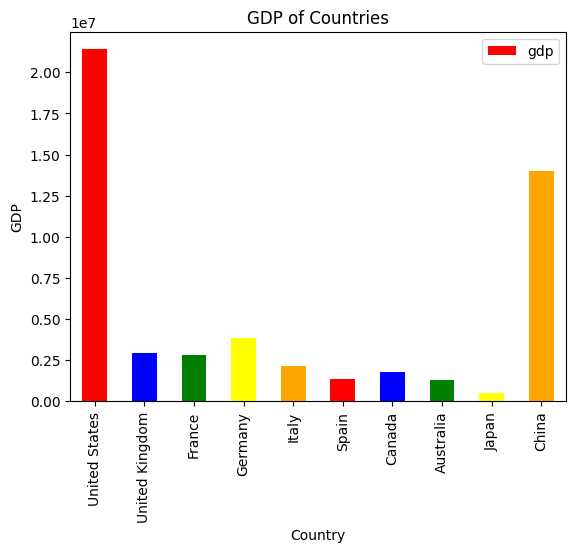
可視化して明るみにでる、サンプルデータの雑さ。
JapanのGDPが低いです。
公式サイトには、THE WORLD BANKの2022年の値をとってきたと書かれていて、githubのサンプルコードは実際の値に近いです。しかし、google colabのサンプルデータは、いい加減に作っているようで、値は適当なんだと思います。
日本語で試す
日本語で質問しても、きちんと答えが返ってきます。ちなみに、日本語で答えてほしいときは、その旨、明記しないと英語で返ってきます。※何回かやってみましたが、うまく文章にならず国名だけ返ってくるときもあり
pandas_ai.run(df, prompt='住むのにおすすめな国はどこですか?理由を添えて日本語で述べてください')
United Statesは住むのにおすすめです。幸福指数が最も高く、経済的にも安定しています。
グラフもかいてくれます。
pandas_ai.run(df, prompt='gdpのグラフをかいてください。国ごとに色を変えてください')
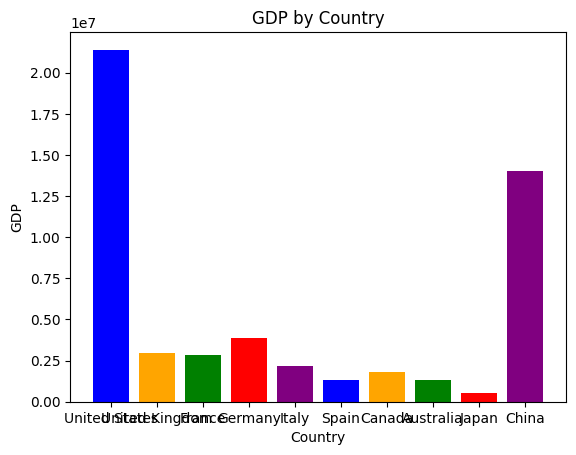
雑に円グラフを指示しても、描いてくれます。
pandas_ai.run(df, prompt='生産性の円グラフを描いてください')
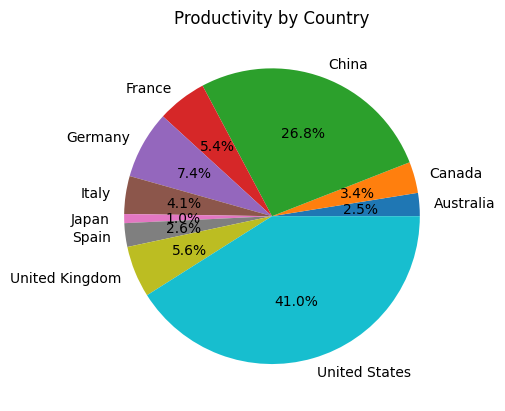
データに関係なさそうな質問をしてみます。
pandas_ai.run(df, prompt='泳ぐのにすすめなのはどの国ですか。理由を添えて日本語で述べてください')
泳ぐのにすすめなのはUnited Statesです。理由は幸福指数が最も高いからです。
ひねりだしてきました。chatGPTらしいですね。
さらにデータに関係ない質問をします。
pandas_ai.run(df, prompt='ビーチが最も綺麗な国は、どの国ですか。理由を添えて日本語で述べてください')
0 United States
6 Canada
7 Australia
Name: country, dtype: object
文章ではなく、候補を三つだしてきました。
データと全く関係ない質問をします。
pandas_ai.run(df, prompt='カレーの作り方を教えてください')
country gdp happiness_index
0 United States 21400000 7.3
1 United Kingdom 2940000 7.2
2 France 2830000 6.5
3 Germany 3870000 7.0
4 Italy 2160000 6.0
5 Spain 1350000 6.3
6 Canada 1780000 7.3
7 Australia 1320000 7.3
8 Japan 516000 5.9
9 China 14000000 5.0
カレーの作り方:
1. フライパンに油を熱し、タマネギとにんにくを炒めます。
2. 鶏肉や野菜を加えて炒めます。
3. カレールーを加え、よく混ぜます。
4. 水を加え、煮込みます。
5. 好みでスパイスや調味料を加えます。
6. ご飯と一緒に盛り付けて完成です!
表の一覧表を添えつつ、カレーの作り方を教えてくれました。中の仕組みが透けて見えますね。
日本語データにどれくらい対応できるのか
架空の日本語データを追加し、df2を作成しました。
新たに、「APRICOT社との取引状況」という項目を追加しています。APRICOTという架空の医療機器メーカーの、各国との取引状況を、chatGPTに生成してもらったものをコピペしています。
df2 = pd.DataFrame({
"国": ["アメリカ", "イギリス", "フランス", "日本"],
"gdp": [21400000, 2940000, 2830000, 3870000],
"幸福指数": [7.3, 7.2, 6.5, 5.9],
"APRICOT社との取引状況":["APRICOTはFDA(米国食品医薬品局)の承認を取得した革新的な医療機器を提供しています。医療技術の進歩が著しいアメリカでは、APRICOTの製品は先進的な医療施設で高く評価されています。",
"APRICOTは国民保健サービス(NHS)とのパートナーシップを築き、公的な医療システムにおける患者のケアに貢献しています。革新的な医療機器により、イギリスの医療現場における診断や治療の品質が向上しています。",
"APRICOTはフランスの医療専門家や病院との緊密な協力関係を築いています。製品の品質と信頼性が高く評価されており、フランスの医療機関における患者ケアの向上に貢献しています。",
"APRICOTは最新の医療技術を提供し、日本の医療機関や研究機関とのパートナーシップを強化しています。高齢化が進む日本では、APRICOTの医療機器が高品質な医療サービスの提供に寄与しています。"]
})
日本語で質問していきます。
答えを日本語の文章で、うまく解答してくれません。
pandas_ai.run(df2, prompt='人々が幸せに暮らしている国はどこですか')
アメリカ
グラフは描けませんでした
pandas_ai.run(df2, prompt='幸福指数のグラフをかいてください')
Unfortunately, I was not able to answer your question, because of the following error:
No code found in the response
pandas_ai.run(df2, prompt='gdpのグラフをかいてください')
Unfortunately, I was not able to answer your question, because of the following error:
No code found in the response
その他
- プライバシーとセキュリティ
- データはopenaiに送っていない。
- データフレームのヘッドをランダムに変更し、ヘッドのみを送信してchatGPTにコードを書かせている
- さらにプライバシー強化モードとしてヘッダすらも送信しないように設定できる(enforce_privacyオプション)
- 複数データフレームも扱える
- データ加工を行うための関数もいろいろ用意されている
まとめ
- pandasaiを触ってみました。
- 今回使ったのは小さいデータですが、プロンプトに収まらないような大きなデータにも適用できる仕組みなので、便利そうです。
- 日本語で使うには、工夫が必要です。
以上