本記事の概要
かいてあること
- 音声認識についてざっくり
- 音声認識を実装するにあたってどのような API が提供されているか・何を実装しなければならないか
かかないこと
- 実装例
- 波形データの解析手法
モチベーション
音声認識とは?
波形データを分析して単語や文を認識し、テキストに変換する技術。英語では Speech-To-Text (STT)。
逆に、テキストを音声に変換する技術は 音声合成 と呼ばれます。英語では Text-To-Speech (TTS)。
音声認識は組み込み機器でも需要がある
キーボードの代わりとして音声認識を使ったり、議事録の自動生成、オンラインでの翻訳などといった用途もありますが、組み込み機器でも需要があります。
- 手が離せない状況下で操作を行いたい
- 自動車運転時や家事など
- キーの数に制約があり、操作の手間がどうしてもかかる
- 方向キーと決定キーだけでバーチャルキーボードを操作しテキストを入力するのは大変
- テレビなど
これまでは文字列マッチングによる言語認識が一般的で、想定される全ての表現を網羅するのは困難でした。近年では 大規模言語モデル (LLM) による応答型のサービスが普及し、自然言語が格段に扱いやすくなりました。
例えば、スマートスピーカーに部屋の証明を消すよう依頼する場合、「("部屋"/"リビング"/"天井の")("照明"/"ライト"/"電気")(を)(消して/オフにして/切って)」など複数の表現が考えられます。文字列マッチングによる言語認識の場合、これらの単語をすべてプログラミングする必要がありました。
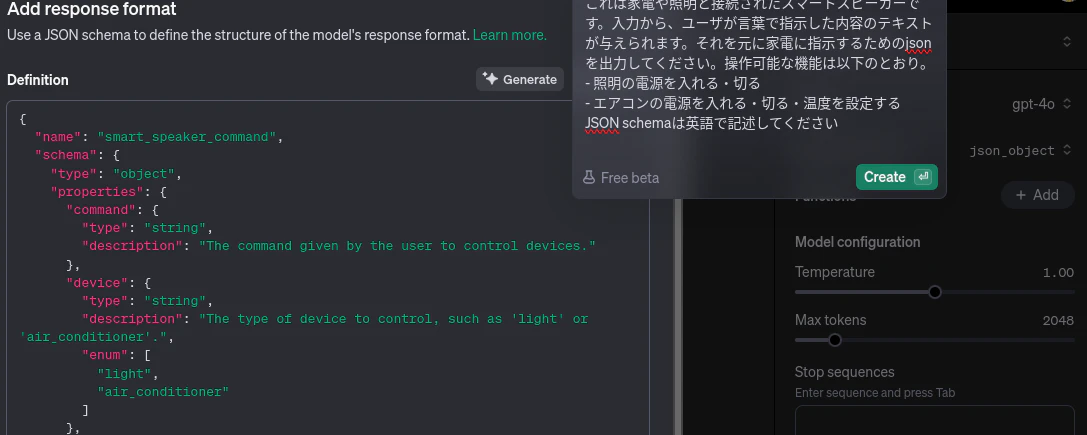
現在では、例えば OpenAI API には JSON Schema に従って出力する機能 ( https://platform.openai.com/docs/guides/structured-outputs ) があり、JSON Schema を設計して文章を投げるだけで文章解析を実現できるようになりました。
(JSON Schema 作成例の画像。schemaも自然言語から生成できる)
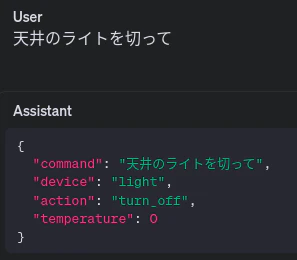
(実行例の画像)
実装方法
以下の 3 パターンが考えられます。
- プラットフォームの API を使う
- Web サービスに接続して利用する
- デバイス上で解析するライブラリを導入する
組み込み Linux のような環境であれば音声認識APIが存在しない場合が多いので、Web サービスやライブラリを導入する必要があります。
また、プラットフォームの API が既に存在していても、音声認識の精度が直接サービスの品質に直結するような場合や、音声認識の精度のカスタマイズを行いたいときなどには、プラットフォームの API を使用せず、Web サービスの利用の検討をすることもあります。
以降は、プラットフォームによる音声認識と Web サービスによる音声認識について説明します。
プラットフォームによる音声認識
音声認識 API は WebAPI や Android 等のプラットフォームでも提供されています。例えば、Android だけでも以下のような API が用意されています。
- SpeechRecognizer
- RecognizerIntent
- SearchBar (Leanback)
音声解析はもちろん、音声の録音等の実装もカプセル化されています。
Android SpeechRecognizer
https://developer.android.com/reference/android/speech/SpeechRecognizer
startListening すると録音を開始し、解析が完了すると、設定した RecognitionListener のインスタンスに結果が返ってきます。
Android RecognizerIntent
Intent を発行すると、画面手前に「お話しください」等のようなダイアログが表示されます。発話して認識されると、Activity に認識結果が返ってきます。
(お話しくださいの画像)

Android SearchBar (Leanback)
Leanback とは、Google が提供している Android TV 向けの UI ライブラリです。
SearchBar はそのライブラリに含まれるコンポーネントの 1 つで、EditText と音声入力ボタンが一体化した ViewGroup です。音声入力ボタンを選択すると、SpeechRecognizer を呼び出して音声による文字入力が行われます。
(SearchBarの画像)

Web サービスによる音声認識
大きく分けて REST API、Streaming API の 2 種類あります。
どちらの方法でも、ライブラリが特に提供されていない限り、自前で録音及び波形データのアップロードの実装を行う必要があります。
REST API
録音データを Web サーバにアップロードし、解析結果を1度受け取る方式。
メリット
- 多言語対応、高度な圧縮形式のサポートなど、高性能
- REST API なので通信に関する実装は単純。写真のアップロードと同じ
デメリット
- 録音中の解析はできず、録音が終了するまで解析を始められない
- 音声区間検出(録音終了タイミングの実装)は API でカバーできない
サービス例
- OpenAI Whisper https://platform.openai.com/docs/guides/speech-to-text/quickstart
- Google https://cloud.google.com/speech-to-text/
- 一旦ストレージに音声データをアップロードしてから、その ID を API サーバに伝える
- AssemblyAI https://www.assemblyai.com/docs/speech-to-text/
Streaming API
録音しながら同時に音声データを Web サーバにアップロードし、会話を認識したら都度レスポンスを返す。
メリット
- 最初の音声データを送信した時点で解析が開始されるため、レスポンスが高速
- 音声区間検出や継続的な応答など、REST APIでは実現できない機能を実現できる
デメリット
- 言語検知機能や、高度な圧縮形式をサポートしないことがある
- ストリーミングを扱うため、通信の管理が複雑。音声区間検出もサーバ側で行うため、発話していない領域も送信されることになり、通信量が増える
サービス例
- Google https://cloud.google.com/speech-to-text/
- gRPC を使用。flac 形式が利用可能
- AssemblyAI https://www.assemblyai.com/docs/speech-to-text/streaming
- WebSocket を使用。音声は PCM
- REST API と異なり英語のみサポート
まとめ
- 音声認識の用途について。翻訳のような音声解析の他に、既存の入力インターフェースを拡張する用途もある
- 入力インターフェースとしての音声認識は LLM の登場により扱いやすくなった
- プラットフォームで用意されている API の多くは、録音操作や UI の実装と一体化している
- Web API で提供される API は、自身で録音の実装を行わなければならない
- REST API の場合は音声区間検出の実装が必要になる。Streaming API の場合は通信量が増える可能性あり