はじめに
AWSについて調べていた際、音声を文字起こしできるサービス(Amazon Transcribe)に出会ったので試しに使ってみることに...
LINEの音声メッセージを文字起こしできたら便利かもと思ったので、試しにLINEBOTに導入してみます~
前提
- windows(macでもおそらくできますが今回はwindows)
- Heroku、flaskを用いておうむ返しボットが作れていること。おうむ返しボットはソフトウェア開発キット(https://github.com/line/line-bot-sdk-python) を参考にすると簡単に作れます。
仕組み
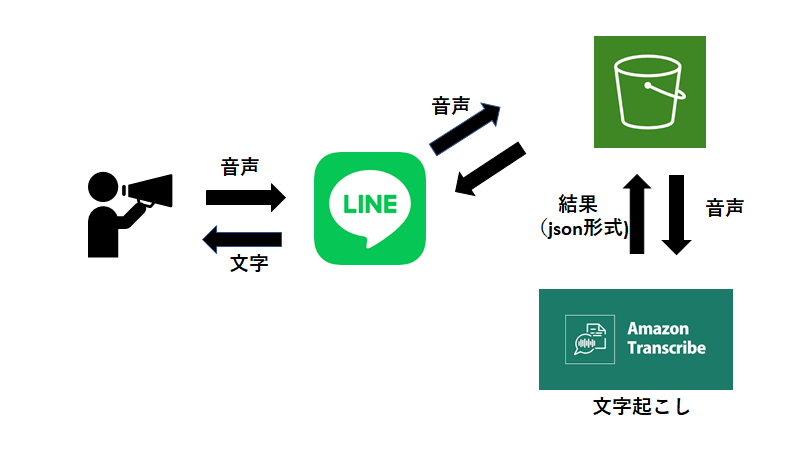
大まかな流れは図の通りです。
ユーザーが音声を送信。BOTが音声データをAmazonS3のバケットに保存。その音声データをAmazonTranscribeが文字起こし。結果を取得してBOTが返信。
環境変数の設定と確認
設定方法
$heroku config:set <環境変数名>=value -a <アプリ名>
確認
$heroku config -a <アプリ名>
AWS_ACCESS_KEY_ID: <AWS AMIから取得>
AWS_SECRET_ACCESS_KEY: <AWS AMIから取得>
S3_BUCKET: <使用するバケットの名前>
YOUR_CHANNEL_ACCESS_TOKEN: <LINE developersのサイトから取得>
YOUR_CHANNEL_SECRET: <LINE developersのサイトから取得>
以上が設定されていれば動くはず。
コード(基本はおうむ返しボットと同じです)
説明の前にメインとなるコードを書いておきます。
from typing import Text
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage
)
import os, json, boto3
import urllib
app = Flask(__name__)
# 環境変数取得
YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"]
YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"]
line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(YOUR_CHANNEL_SECRET)
aws_s3_bucket = os.environ['S3_BUCKET']
#テスト用
@app.route("/")
def hello_world():
return "hello world!"
@app.route("/callback", methods=['POST'])
def callback():
# get X-Line-Signature header value
signature = request.headers['X-Line-Signature']
# get request body as text
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
# handle webhook body
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
import time
@handler.add(MessageEvent, message=AudioMessage)
def handle_message(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd:
fd.write(message_content.content)
original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a'
#音声の保存 wav
file_name = f"{message_id}.wav"
urllib.request.urlretrieve(original_content_url,file_name)
# S3へ音声をアップロードする
s3_resource = boto3.resource('s3')
s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name)
#音声の認識
transcribe = boto3.client('transcribe', region_name="ap-northeast-1")
job_name = f"linewikipediabot-{message_id}.wav"
job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp4',
LanguageCode='ja-JP',
OutputBucketName = aws_s3_bucket
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(3)
print("DONE")
#jsonファイルの取得
s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json")
json_open = open(f"{job_name}.json", "r")
json_load = json.load(json_open)
print(json.dumps(json_load, ensure_ascii=False, indent=4))
#音声認識結果
replymessage = json_load["results"]["transcripts"][0]["transcript"]
print(replymessage)
replymessage1 = replymessage.replace(" ", "")
print(replymessage1)
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=replymessage1))
if __name__ == "__main__":
# app.run()
port = int(os.getenv("PORT", 5000))
app.run(host="0.0.0.0", port=port)
コードの解説(メインの「音声メッセージ→文字」の流れのみ)
- message_idについて
- メッセージにはぞれぞれ番号がついているため、識別するために取得。
- message_content
- 音声を取得(以下のコード)
- ファイル名にmessage_idを組み込み識別。
- リファレンスを参考にしました。
message_content = line_bot_api.get_message_content(message_id)
with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd:
fd.write(message_content.content)
original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a'
#音声の保存 wav
file_name = f"{message_id}.wav"
urllib.request.urlretrieve(original_content_url,file_name)
- バケットへアップロード
s3_resource = boto3.resource('s3')
s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name
- 音声を認識してくれるようにお願いを出す
- 自分の場合、region_nameを指定しないと動作しませんでした。
- while文は文字起こしが完了しているかどうかを判別。("Not ready yet..." → まだ)結果が出る前にコードが進行してしまうと当然エラーになる。
- 文字起こしの結果は音声を格納したバケットと同じバケットに格納されます(環境変数で設定したもの)
- print("DONE")が終了の合図
- AWSの開発者ガイドが参考になります
transcribe = boto3.client('transcribe', region_name="ap-northeast-1")
job_name = f"linewikipediabot-{message_id}.wav"
job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp4',
LanguageCode='ja-JP',
OutputBucketName = aws_s3_bucket #出力先を音声と同じバケットに設定
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(3)
print("DONE")
- 文字起こし結果の取得
- 結果はjson形式で返されます。(AWSの開発者ガイド)
- バケットからいったんダウンロード
s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json")
json_open = open(f"{job_name}.json", "r")
json_load = json.load(json_open)
- 文字の取得
- replymessageままだと単語と単語の間にスペースが開いてしまいます。
- スペースを取り除いた形をreplymessage1とします。(名前はなんでもOK)
- print文で結果を見てみるのもいいかもしれません
replymessage = json_load["results"]["transcripts"][0]["transcript"] #jsonファイルから特定の項目を取得
replymessage1 = replymessage.replace(" ", "") #スペースを除く処理
- 結果をラインで返信
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=replymessage1))
その他のファイル
requirements.txt(pip freezeで確認し、ご自身の使用しているバージョンを書いてください)
boto3==1.17.17
botocore==1.20.17
certifi==2020.12.5
chardet==4.0.0
click==7.1.2
Flask==1.1.2
future==0.18.2
idna==2.10
itsdangerous==1.1.0
Jinja2==2.11.3
jmespath==0.10.0
line-bot-sdk==1.18.0
MarkupSafe==1.1.1
psycopg2==2.8.6
python-dateutil==2.8.1
requests==2.25.1
s3transfer==0.3.4
six==1.15.0
urllib3==1.26.3
Werkzeug==1.0.1
Procfile
web: python main.py
runtime.txt(herokuにpythonのバージョンを認識させる)
python-3.9.2
GitHubにデプロイして終了(herokuアプリとGitHubを連携済みを想定)
応用
音声認識結果をWikipediaで調べ、結果を返してくれたら面白いなと思ったので機能を追加してみます。(以下のコード)
from typing import Text
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage
)
import os, json, boto3
import urllib
app = Flask(__name__)
#環境変数取得
YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"]
YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"]
line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(YOUR_CHANNEL_SECRET)
aws_s3_bucket = os.environ['S3_BUCKET']
#テスト用
@app.route("/")
def hello_world():
return "hello world!"
@app.route("/callback", methods=['POST'])
def callback():
# get X-Line-Signature header value
signature = request.headers['X-Line-Signature']
# get request body as text
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
# handle webhook body
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
import time
@handler.add(MessageEvent, message=AudioMessage)
def handle_message(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd:
fd.write(message_content.content)
original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a'
#音声の保存 wav
file_name = f"{message_id}.wav"
urllib.request.urlretrieve(original_content_url,file_name)
# S3へ音声をアップロードする
s3_resource = boto3.resource('s3')
s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name)
#音声の認識
transcribe = boto3.client('transcribe', region_name="ap-northeast-1")
job_name = f"linewikipediabot-{message_id}.wav"
job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp4',
LanguageCode='ja-JP',
OutputBucketName = aws_s3_bucket
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(3)
print("DONE")
#jsonファイルの取得
s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json")
json_open = open(f"{job_name}.json", "r")
json_load = json.load(json_open)
print(json.dumps(json_load, ensure_ascii=False, indent=4))
#音声認識結果
replymessage = json_load["results"]["transcripts"][0]["transcript"]
replymessage1 = replymessage.replace(" ", "")
# 以下追加のコード
uri = "https://ja.wikipedia.org/wiki/" + replymessage
column = {
"title": replymessage,
"text": replymessage,
"action": {
"label": "Wikipediaでみる",
"uri": uri
}
}
columns = [
CarouselColumn(
title=column["title"],
text=column["text"],
actions=[
URITemplateAction(
label=column["action"]["label"],
uri=column["action"]["uri"],
)
]
)
]
messages = TemplateSendMessage(alt_text=replymessage, template=CarouselTemplate(columns=columns))
line_bot_api.reply_message(event.reply_token,
messages = messages)
if __name__ == "__main__":
# app.run()
port = int(os.getenv("PORT", 5000))
app.run(host="0.0.0.0", port=port)
応用の解説
追加したのは検索結果をカルーセルに格納し、返信するというシンプルなものです。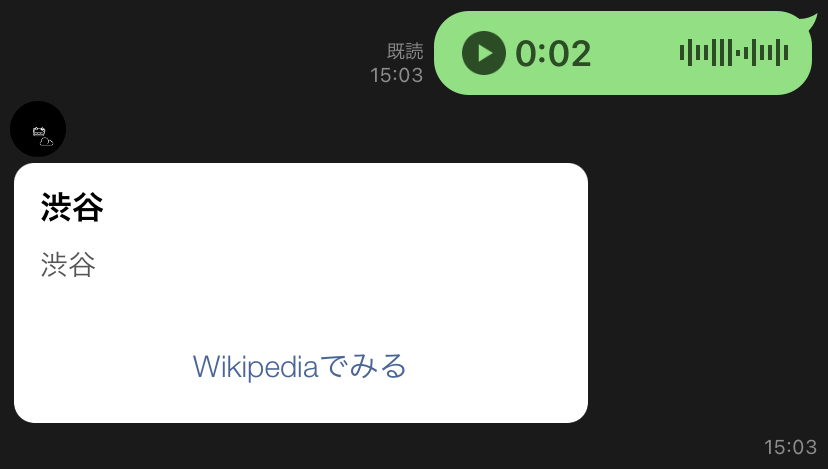
まとめ
やってみてなかなか面白いと感じました。それなりに長い文章でも精度はかなり高く、いろいろな応用先が思いつきそうですね~。(アプリに組み込むとか。。。)
ただ、あまり長い音声(文章)を送るとherokuがタイムアウトしてしまい、エラーが発生しました(音声の処理に時間がかかってしまうため)。どうやらherokuは30秒以下の処理のみ対応しているとのこと。一応解決策はあるようですが、今回はパスします。気になった人は以下のリンク(バックグラウンドジョブについて)を見てみるといいかもしれません。というかherokuの代わりにAmazonのサービスを使ったほうがよかったのかもしれません(笑)
ここまで見てくださりありがとうございました。PythonもQiitaも不慣れなので読みにくかったかもしれません。。。もし、なにか疑問や改善点などあればぜひコメントしてください~(LGTMしてくれると励みになります。。!)