ScyllaDBとは
ScyllaDB(スキュラDB)とは、Apache CassandraをJAVAからC++でリプレースし、Cassandraより10倍以上高速であり、その速さを利用してノード数を「1/5~1/10」に圧縮できる異次元のデータベースです。Cassandraとは、互換性があり、開発はCassandraのドライバ―やCQL、各種コネクター、CLIなどをそのまま利用できます。
高コア数/高帯域のネットワーク/高スループットのDISK I/Oという現代的なハイエンドサーバーの登場は、今日においてサーバーの最大の買い手であるクラウドプロバイダーの存在と、マルチメディア/ML/AIなど益々リッチな計算資源を求める時代的な背景が働いています。
しかし、これらのハイエンドサーバーに、DBのような従来のデータ集約的なアプリケーションをインストールして使おうとすると、機能性には問題がありませんが、CPUも、ネットワークも、DISK I/Oも、有効に働く限界を超えてしまう問題が発生します。簡単にいうと、大量のデータ処理やデータの流れが処処でボトルネックのような現象を引き起こします。
ScyllaDBの生い立ち
ScyllaDBの創業者は元KVMの開発者であるAvi Kivity氏。当初、DockerのようなUnikernelを開発していて、Dockerとは競合していたが最終的にはDockerの方が広がり、そこで製品化を断念。このUnikernelの基礎技術を使って、Hadoop、Cassandra、Kafka等のストレージエンジンの高速化に関わっていた。この時から開発言語として、C++をベースにし、最終的にCassandraに絞って製品化したのが、ScyllaDBである。2015年には、αリリースを出し、現在に至っている。
ー鈴木一平氏より

現代的なハイイエンドサーバーとは
ここでは、次のような計算資源を言っています。
数十コア以上のvCPU、数百GBを超えるメモリ、10GB以上のネットワーク帯域、 MAXスループットが「1GB/1Sec」を超えるストレージ
ScyllaDBのアーキテクチャー
ScyllaDBは、割り込みとロックに依存している、従来のthread pool型のアプリケーションが、現代的なハイエンドサーバーでは有効に働かないことを見抜いて、抜本的なアーキテクチャーの改革を行っています。
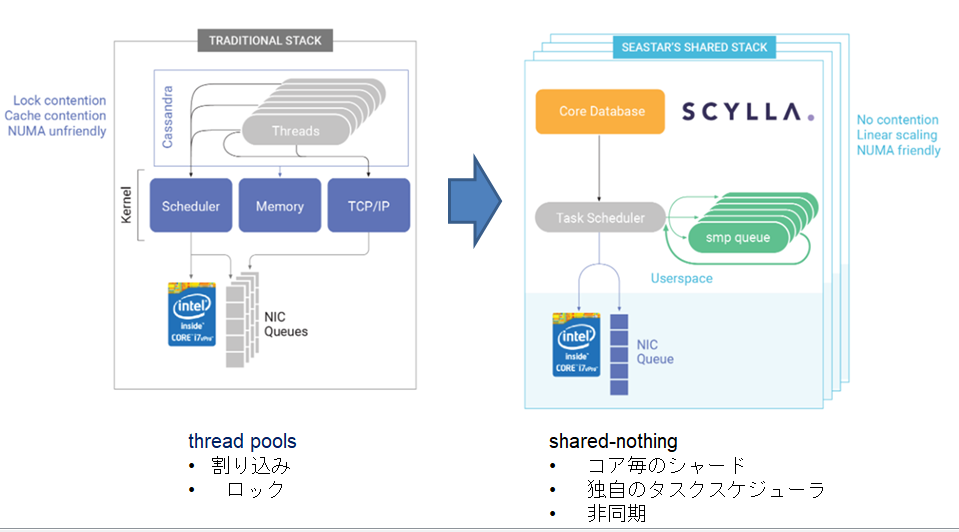
従来のアーキテクチャー(thread pool)
コア数が多く、ネットワーク帯域がリッチで、DISK I/Oが高スループットのマシンなら、データ処理は高速であり、通信も高速、大量に読み書きもできるから、いいこと尽くしのはずですが、実際には思わぬ落とし穴が待っています。
従来のアーキテクチャーでのデータ集約型処理では、CPU処理でも、ネットワークでも、DISK I/Oでも、ボトルネックのような現象を引き起こします。従来のアーキテクチャーでは、おおよそ、十数コアぐらいまでが限界だと言われています。
- CPUの処理で過剰なロックが発生し、遅延を誘発する
- CPUが直接ネットワークのパケットを処理する能力をもっておらず、OSに依存するために、さらに事態を悪化させる
- 高性能のDISKでも、最大の同時実行数を超えたI/Oが発生すると、失速を引き起こすが、OSに依存しているために制御できない
つまり、高コア数のマシンをデータ集約型処理で利用するためには、アプリケーションのアーキテクチャーを抜本的に変える必要があります。
ScyllaDBのアーキテクチャー(shared nothing)
ScyllaDBのアーキテクチャーは、現代的なハイエンドサーバのパワーを極限まで引き出します。
コア毎のシャード
- 各シャードは独自のメモリ、ネットワーク、I/O、自分のデータを持つ
- ロックレスのコア間通信
独自のタスクスケジューラ
- タスクは、自分に与えられたデータだけを集中して処理
すべて非同期
- ロックレス、データはすべてCPUにストリーム
- コア間で明示的にデータの引き渡し
この辺の説明は、次のPPTにまとめてみました。
ScyllaDBの特徴
技術的な難しい話しはともかく、ScyllaDBのユーザとしては、非常に嬉しいことがあります。
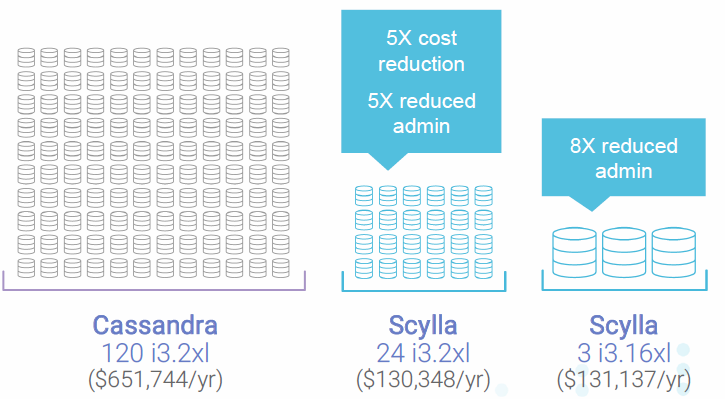
- 同規模のCassandra構築よりもノード数を「1/5~1/10」ぐらい圧縮できるためにトータルコストが下がる(スケールアップファースト)
- CassandraをC++でリプレースし、JVMの管理から解放される。
- とてもシンプルなキャッシュ―の仕組みを獲得し、Cassandraよりもクエリレスポンスが各段に高速であり、常に安定している
- Cassandraと互換性をと持っているので、開発ではCassandraのドライバ―やCQL、各種コネクター、CLIがそのまま利用できる。
- もし、Cassandraレプレースの場合、Cassandraの現在の実装を利用し、IPアドレスをScyllaDBクラスタに変更するだけで動作する
- Cassandraの高可用性、高拡張性はキープしている
- 最適なパラメーター設定を専用のユーティリティがやってくれる(scylla_setup)
スケールアップファーストのクラスター設計思想
ScyllaDBは、現代的なハイエンドサーバーを十分に働かせることができるために、スケールアップファーストの思想でクラスターを構築し、同規模のデータ処理では、ノード数を「1/5~1/10」に圧縮し、トータルコストを顕著に下げることができます。スケールアウトは、禁じ手ではありませんが、もはや唯一の選択筋ではなくなっています。
スケールアップファーストは、単に現代的なハイエンドサーバーに巨大なストレージを付けて大量のデータを持たせば良いというものではありません。クライアントとサーバー間、CPU間、ノードとノード間、ユーザ領域とDISK間で、桁違いの高速且つ高スループットのデータ処理を必要とします。ScyllaDBは、高速処理ができるからこそ、スケールアップファーストのクラスター実装を可能にしています。
仮に3レプリカ想定で1ノードに10TBぐらいのデータを持つ設計にすると、実際には1ノード当りに30TBのぐらいのデータを持つことになります。日頃のデータ処理から、高速且つ高スループットが求められます。
ストレージの障害でも起きると、復旧のためにノード間で数十TBのデータストリーミングが発生します。ScyllaDBは、独自のストリーミング技術を利用した最近のベンチマークで1.89TBを66分で復旧しています。これは、「765MB/1Sec」の実力です。
スケールアウトオンリーのクラスター設計思想
スケールアウトオンリーの思想の下で設計されたNoSQLは、現代的なハイエンドサーバーを働かせることができないために、計算能力の拡張はスケールアウトのみに依存しています。これは、故障率をわざわざ買うような設計思想であり、調達や開発、運用コストなど、すべてがノード数とともに膨らんでいきます。
スケールアウトオンリーのクラスター設計思想は、おそらく、2000年代にHadoopの登場とともに急激に流行りだし、現在の殆どのNoSQLのアーキテクチャーが影響を受けています。現代的なハイエンドサーバーが「絵のなかの餅」という時代、それは画期的な発想であり、正しい選択だったかも知れません。
しかし、今日においては、状況が変わりつつあります。まず、現代的なハイエンドサーバーが比較的に安価で調達できるようになっています。もう一つは、データ量の暴走です。秒間では大したことのないように見えるデータでも、あっという間にTB級になり、通年では数十TBや数百TBになることがざらにあります。
仮に、100TBぐらいのデータをCassandraのクラスタ―に持たせようとすると、おおよそ「8~16コア/64~128GBメモリ」のサーバー想定で50ノードから100ノード規模のクラスタ―が必要です。ノード当り1TB~2TBの試算になります。1ノードに、それ以上のデータを持たせることは非推奨となっています。
現代的なハイエンドサーバーにCassandraを入れてノード当たりのデータ量を増やし、ノード数を減らせないか、という相談も受けたりします。それは、自然な発想ですがCassandraは、ソフトウェアとして現代的なハイエンドサーバーを効率的に働かせることができないために無理があります。繰り返しになりますが、ノード数を圧縮すると、クライアントとサーバー間、CPU間、ノードとノード間、ユーザ領域とDISK間で、桁違いの高速且つ高スループットのデータ処理が必要になるからです。
ScyllaDBのスタンドアロンクラスタ―を構築してみる
とりあえず、ScyllaDBに触れてみたい方は、次のリンクを参照してください。
Schlla DBのマルチノードクラスタ―を構築してみる
もう少し、踏み込んでScyllaDBを勉強してみたい方は、次のリンクを参照してください。
まとめ
ScyllaDBの登場は、現代的なハイエンドサーバーの登場を先に読んだ一手とも言えます。データ量の暴走は、歯止めが利かない状況にあります。さらに、ビックデータをリアルタイムで処理したいという要求が益々強くなっています。ScyllaDBのスケールアップファーストの思想が新たな地平を開いてくれると、楽しみにしています。