はじめに
今回は、Pythonと現在勉強中のSeleniumを使用してWebスクレイピングを行いたいと思います。
ターゲットサイトはGoogleで、指定したキーワードで検索を行って、指定した数の項目を取得し、「タイトル、URL、概要」の3項目をデータベースに書き出す、というものです。
以下のような項目を取得します。
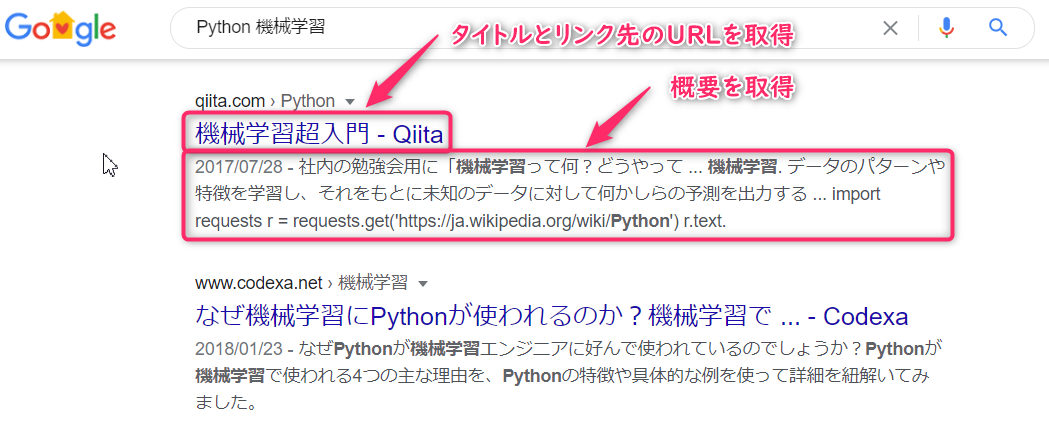
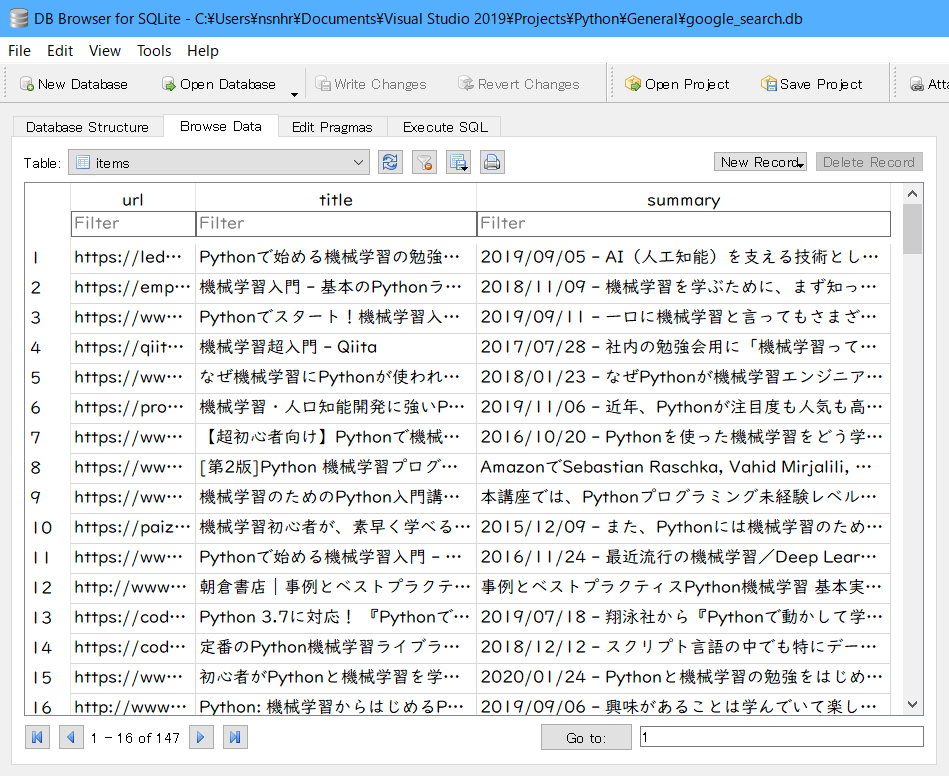
最終目標はSQLiteのデータベースに情報を書き込みます。
開発環境
Python 3.7.1 を使用します。
開発環境はVisual Studio 2019です。
Firefox用のドライバはgeckodriverからダウンロードしました。
コード
ソースコードは以下の通りです。
なお、下記のコードは「2020年4月23日」の時点で動作するものですが、今後のサイトの仕様変更などにより、動作しなくなる可能性もあるのでご了承ください。
import urllib.parse
import records
from selenium.webdriver import Firefox, FirefoxOptions
from sqlalchemy.exc import IntegrityError
# 以下のキーワードを使って検索する
keywd = ['Python','機械学習']
# 取得したデータを保存するファイルの名前
db = records.Database('sqlite:///google_search.db')
db.query('''CREATE TABLE IF NOT EXISTS items (
url text PRIMARY KEY,
title text,
summary text NULL)''')
def store_data(url, title, summary):
try:
db.query('''INSERT INTO items (url, title, summary)
VALUES (:url, :title, :summary)''',
url=url, title=title, summary=summary)
except IntegrityError:
# この項目はすでに存在するのでスキップ
print("it's already exist.")
return False
return True
def visit_next_page(driver, url):
driver.get(url)
items = driver.find_elements_by_css_selector('#rso > div.g')
for item in items:
tag = item.find_element_by_css_selector('div.r > a')
link = tag.get_attribute('href')
title = tag.find_element_by_tag_name('h3').text.strip()
summary = item.find_element_by_css_selector('div.s span.st').text.strip()
if store_data(link, title, summary):
print(title, link, sep='\n', end='\n\n')
def main():
# ターゲットサイトと検索個数(search_unit * search_loop)
base_url = "https://www.google.co.jp/"
search_unit = 20 # 1ページの表示件数(100以上を指定しても無理っぽい)
search_loop = 5
start = 0
# キーワードを1つの文字列に結合する
target = ' '.join(keywd)
# URLエンコード(デフォルトのエンコードは"utf-8")
target = urllib.parse.quote(target)
opt = FirefoxOptions()
# 自分でブラウザの動作を観察したければ、コメントにしてください
opt.add_argument('-headless')
driver = Firefox(options=opt)
# 待機時間を設定する
driver.implicitly_wait(10)
# 1ページ分づつ読み込んでいく
for i in range(search_loop):
url = "{0}search?num={1}&start={2}&q={3}".format(base_url, search_unit, start, target)
start += search_unit
print("\npage count: {0}...".format(i + 1), end='\n\n')
visit_next_page(driver, url)
driver.quit()
if __name__ == '__main__':
main()
解説
ソースにコメントを入れているのでだいたい分かると思いますが、スクレイピングの中心的な部分を解説します。
1件分のデータが入っている部分は以下のようになります。
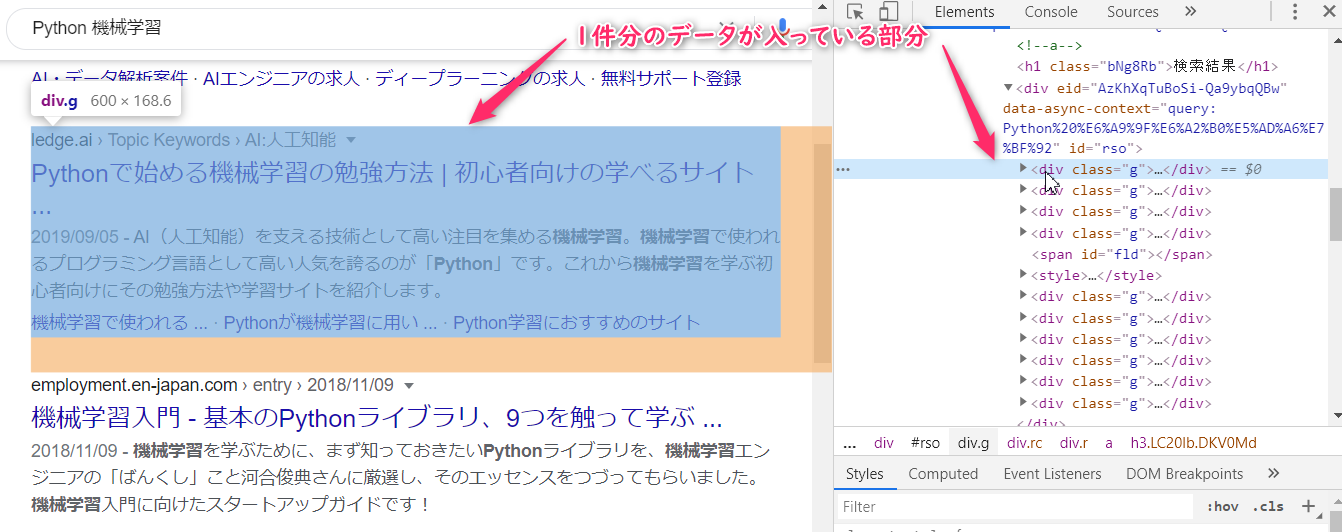
これを以下のようなコードで取得します。
items = driver.find_elements_by_css_selector('#rso > div.g')
タイトルとリンクのURLは以下のようになっています。
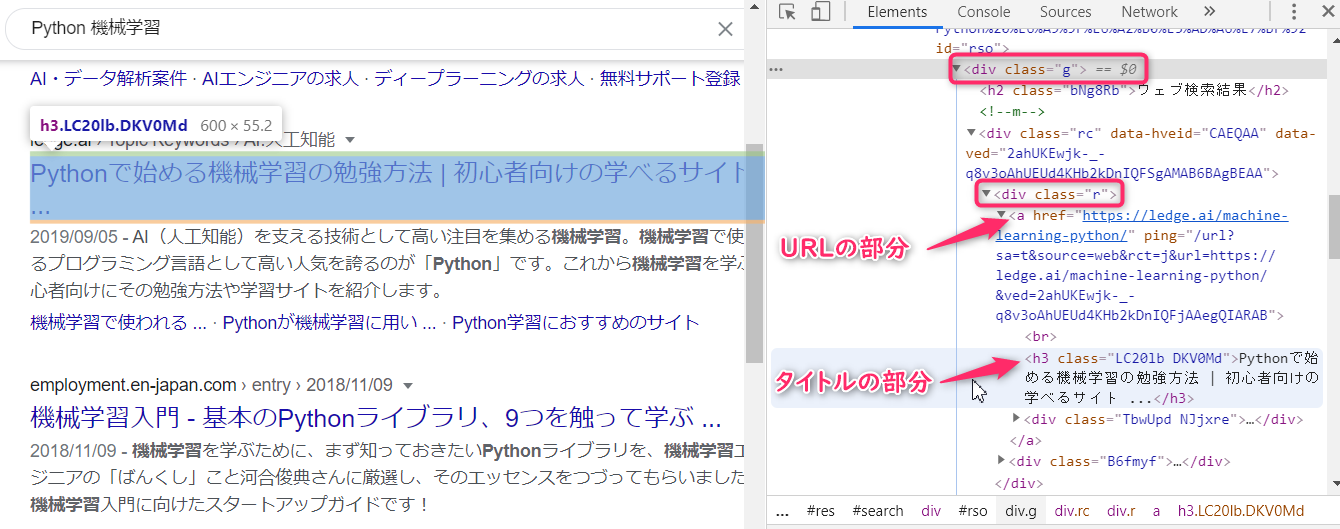
概要の部分は以下のようになっています。
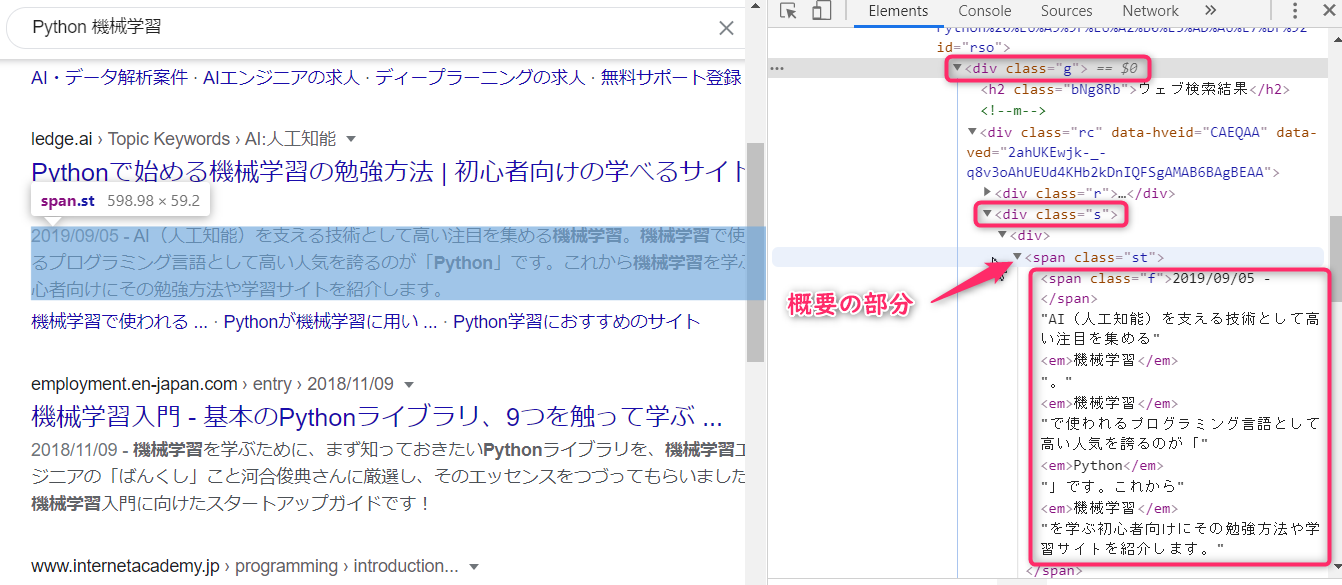
これを以下のようなコードで取得します。
tag = item.find_element_by_css_selector('div.r > a')
link = tag.get_attribute('href')
title = tag.find_element_by_tag_name('h3').text.strip()
summary = item.find_element_by_css_selector('div.s span.st').text.strip()
使い方
実際に使用する場合には、ソースコードの冒頭部分で検索したいキーワードと保存するファイル名を指定します。
# 以下のキーワードを使って検索する
keywd = ['Python', '機械学習']
# 取得したデータを保存するファイルの名前
db = records.Database('sqlite:///google_search.db')
また、同じプログラムを複数回実行しても同じURLは登録せずにスキップします。
def store_data(url, title, summary):
try:
db.query('''INSERT INTO items (url, title, summary)
VALUES (:url, :title, :summary)''',
url=url, title=title, summary=summary)
except IntegrityError:
# この項目はすでに存在するのでスキップ
print("it's already exist.")
return False
return True
補足
最初は1回のページ表示でまとめて1000件分くらい取得しようと思ったのですが、どうもGoogleの仕様で1ページあたり100件くらいが限度のようでした。
というわけで、search_unitとsearch_loopの2つの変数を使用して次のページに切り替えながらスクレイピングしています。
また、なんでBeautifulSoupを使わないの?
という声が聞こえてきそうですが、Seleniumを使った練習をしてみたかったのと、最近はJavaScriptを使用したサイトが多いのでSeleniumを使う機会が増えそうなので、今回はこのような方法でスクレイピングしてみました。
終わりに
今回紹介したソースコードは自由に使って頂いて構いませんが、その際には自己責任でお願いします。