2021年08月05日更新
以前のコードが古くなり、ヘッドラインが取得できなくなっていたので、
修正しました。また、8トピックスバージョン(head_line_short())と25トピックスバージョン(head_line_long())の2つを切り替えられるようにしました。
はじめに
ヤフーニュースのサイトからヘッドラインの一覧とURLを取得して、各項目を1行で表示するプログラムを作成していたのですが、URLの列をきれいに揃えるのにちょっと苦労したので、今後のために記事を書いておこうと思います。
以下のようなサイトからデータを取得します。
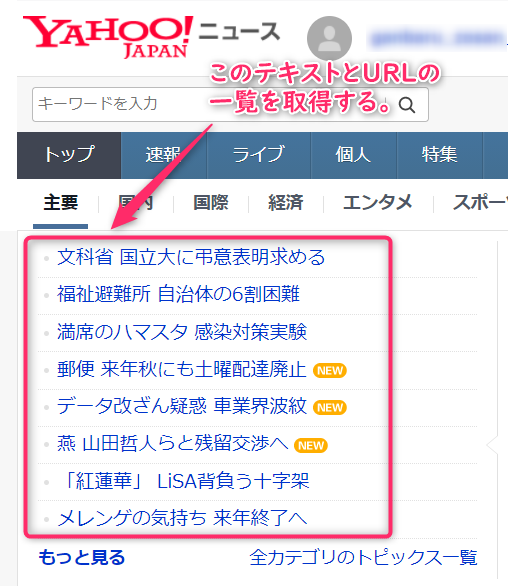
最終的に取得するテキストは以下の通りです。

開発環境
Python 3.7 を使用します。
開発環境はVisual Studio Community 2019です。
コード
import requests
import unicodedata
import sys
from urllib.parse import urljoin
from bs4 import BeautifulSoup
def head_line_long():
base_url = 'https://news.yahoo.co.jp/topics/'
categories = {
'主要': 'top-picks',
'国内': 'domestic',
'エンタメ': 'entertainment',
#'国際': 'world',
#'経済': 'business',
}
# カテゴリーごとにループ処理する
for cat in categories:
url = urljoin(base_url, categories[cat])
r = requests.get(url)
soup = BeautifulSoup(r.content, 'lxml') # html.parser
div_tag = soup.find('div', class_='newsFeed')
if (div_tag is None):
print('div_tag.newsFeed is None.')
sys.exit()
ul_tag = div_tag.find('ul', class_='newsFeed_list')
if (ul_tag is None):
print('ul_tag is None.')
sys.exit()
print(f'==={cat}===')
for item in ul_tag.find_all('li', class_='newsFeed_item'):
a = item.find('a')
if a is None: continue
topic_url = a['href']
div_tag = a.find('div', class_='newsFeed_item_title')
if (div_tag is None):
print('div_tag.newsFeed_item_title is None.')
sys.exit()
topic_headline = div_tag.text.strip()
text = text_align(topic_headline, 30)
print(f'{text}[{topic_url}]')
print()
def head_line_short():
base_url = 'https://news.yahoo.co.jp/'
categories = {
'主要': '',
'国内': 'categories/domestic',
'エンタメ': 'categories/entertainment',
#'国際': 'categories/world',
#'経済': 'categories/business',
}
# カテゴリーごとにループ処理する
for cat in categories:
url = urljoin(base_url, categories[cat])
r = requests.get(url)
soup = BeautifulSoup(r.content, 'lxml') # html.parser
div_tag = soup.find('div', class_='sc-dXLFzO')
if (div_tag is None):
print('div_tag is None.')
break
ul_tag = div_tag.find('ul')
if (ul_tag is None):
print('ul_tag is None.')
break
print(f'==={cat}===')
for item in ul_tag.find_all('li', class_='sc-ksYbfQ'):
a = item.find('a')
topic_url = a['href']
topic_headline = a.text.strip()
#print(f'{topic_headline:<18}[{topic_url}]')
text = text_align(topic_headline, 30)
print(f'{text}[{topic_url}]')
print()
def get_han_count(text):
'''
全角文字は「2」、半角文字は「1」として文字列の長さを計算する
'''
count = 0
for char in text:
if unicodedata.east_asian_width(char) in 'FWA':
count += 2
else:
count += 1
return count
def text_align(text, width, *, align=-1, fill_char=' '):
'''
全角/半角が混在するテキストを
指定の長さ(半角換算)になるように空白などで埋める
width: 半角換算で文字数を指定
align: -1 -> left, 1 -> right
fill_char: 埋める文字を指定
return: 空白を埋めたテキスト('abcde ')
'''
fill_count = width - get_han_count(text)
if (fill_count <= 0): return text
if align < 0:
return text + fill_char*fill_count
else:
return fill_char*fill_count + text
if __name__ == '__main__':
head_line_short()
#head_line_long()
当初、出力テキストのフォーマットは以下のようにしていました。
for item in ul_tag.find_all('li', class_='topicsListItem'):
a = item.find('a')
topic_url = a['href']
topic_headline = a.text.strip()
# このコードではURLの列がずれてしまいます。
print(f'{topic_headline:<18}[{topic_url}]')
これですと、以下のように出力になってしまいます。
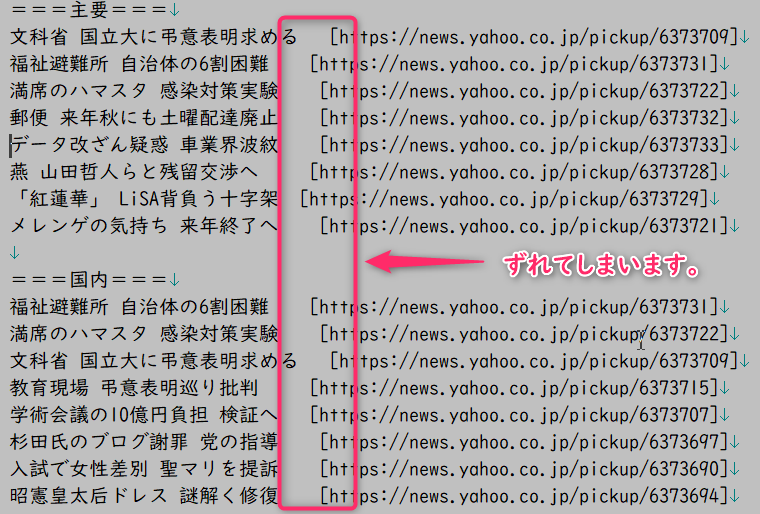
print(f'{topic_headline:<18}[{topic_url}]')のような指定では、全角文字と半角文字を区別せずに扱ってしまいます。
そこで、テキストの全角と半角を区別して必要な空白を挿入するための関数を作成しました。
def get_han_count(text):
'''
全角文字は「2」、半角文字は「1」として文字列の長さを計算する
'''
count = 0
for char in text:
if unicodedata.east_asian_width(char) in 'FWA':
count += 2
else:
count += 1
return count
def text_align(text, width, *, align=-1, fill_char=' '):
'''
全角/半角が混在するテキストを
指定の長さ(半角換算)になるように空白などで埋める
width: 半角換算で文字数を指定
align: -1 -> left, 1 -> right
fill_char: 埋める文字を指定
return: 空白を埋めたテキスト('abcde ')
'''
fill_count = width - get_han_count(text)
if (fill_count <= 0): return text
if align < 0:
return text + fill_char*fill_count
else:
return fill_char*fill_count + text
最終的には、以下のようなコードで書式を整えます。
for item in ul_tag.find_all('li', class_='topicsListItem'):
a = item.find('a')
topic_url = a['href']
topic_headline = a.text.strip()
text = text_align(topic_headline, 30)
print(f'{text}[{topic_url}]')
これで、無事解決しました。
text_align()は一応、左側に空白を入れるオプションと、空白以外の記号も指定できるようにしました。
テキストエディターなどに出力する方法
ところで、Pythonのプログラムからの出力は通常はコマンドプロンプトになると思いますが、今回のケースのような場合にはテキストエディターやワープロなどに書き出して保存したいと思うかもしれません。
そのような場合には、ペースターというソフトを使うとエディターなどのキャレット位置に直接ペーストすることができます。
すると、以下のように直接データがペーストされます。
終わりに
今回はテキストのフォーマットに関するテーマだったので、スクレイピングに関するコードの解説はしませんでしたが、ほぼfind()メソッドだけで事足りました。
なお、上記のソースコードは自由に使って頂いて構いませんが、その際には自己責任でお願いします。
参考サイト
全角と半角を区別する関数(unicodedata.east_asian_width())の使い方につきましては、以下のサイトを参考にさせて頂きました。
Pythonで半角1文字、全角2文字として文字数(幅)カウント
なお、Webスクレイピングを行う場合には、対象サイトのrobots.txtを必ず確認しておきましょう。
User-agent: *
Disallow: /comment/plugin/
Disallow: /comment/violation/
Disallow: /polls/widgets/
Disallow: /articles/*/comments
Sitemap: https://news.yahoo.co.jp/sitemaps.xml
Sitemap: https://news.yahoo.co.jp/sitemaps/article.xml
Sitemap: https://news.yahoo.co.jp/byline/sitemap.xml
Sitemap: https://news.yahoo.co.jp/polls/sitemap.xml