はじめに
この記事では、ペースターというテキスト入力支援ツールを使用してPythonのコードを簡単に入力する方法をご紹介します。Jupyter LabやVS Codeなどのエディターで使用します。
更新(Ver1.03)
2022年8月03日:1.03にバージョンアップしました。
なお、ペースター自身もVer7.19にバージョンアップしました。
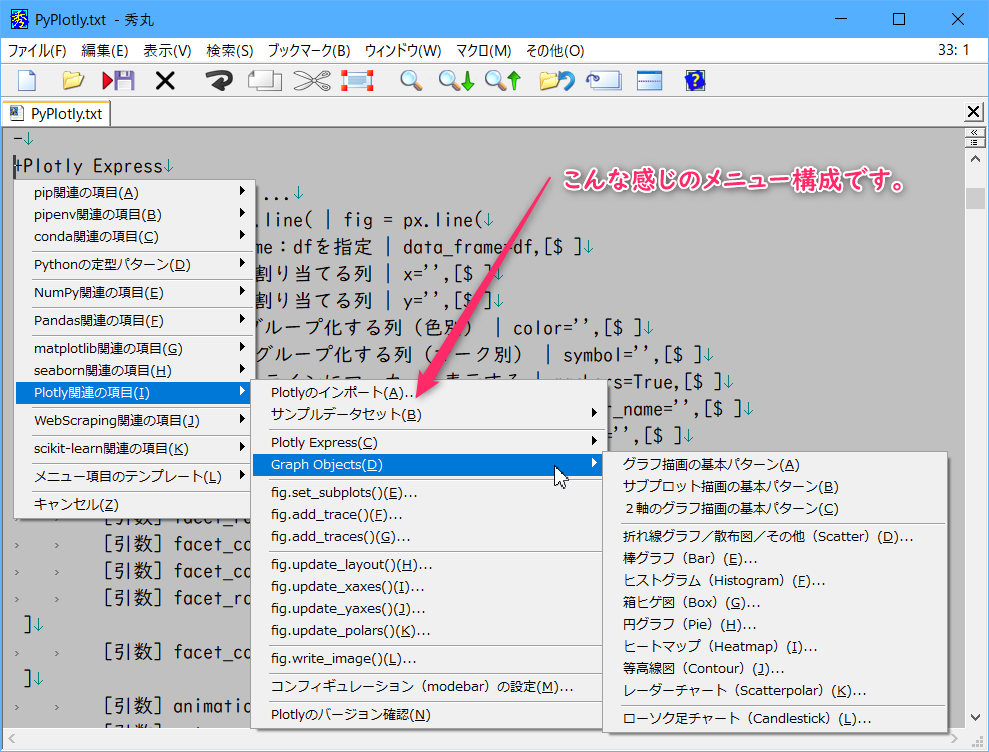
今回は可視化ライブラリのPlotlyのサブメニューを追加しました。
ペースターの新しいリストメニューから必要な引数をマウスで選択しながら入力することができます。
Plotly以外の部分もちょこちょこ改変しています。
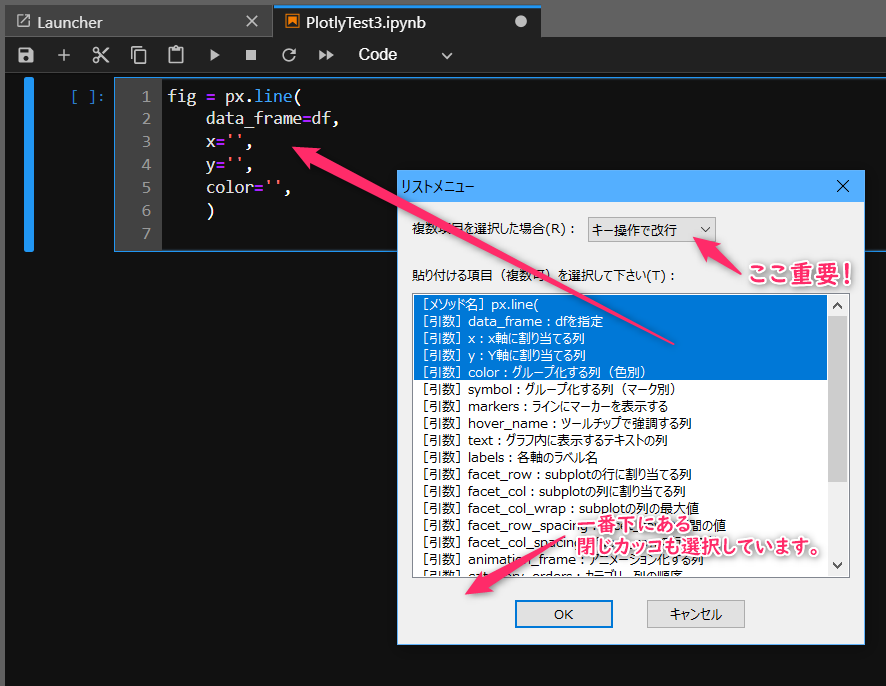
上部にある「複数の項目を選択した場合」で、「キー操作で改行」を選ぶことで、Jupyter LabやVS Codeのインデント調整が自動で行われるので便利です。
更新(Ver1.02)
2021年8月02日:1.02にバージョンアップしました。
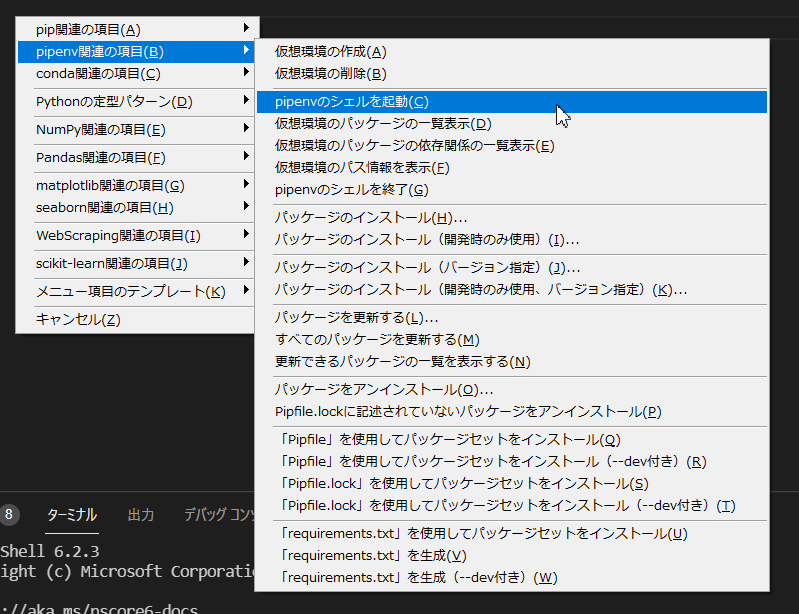
前回のバージョンで追加できなかったスクレイピング関連のパッケージ(BeautifulSoup, Selenium)のスニペット(定型パターン)を追加しました。
また、「pip, pipenv, conda」関連のコマンドのスニペットも追加しました。
おもに仮想環境の管理とパッケージのインストール関連です。
使用するツール
今回はフリーソフトとして公開しているWindows用の「ペースター」というソフトを使用します。
このソフトは「定型文入力の機能」と「クリップボード履歴を管理する機能」を持っている常駐タイプのソフトになります。テキストエディター、ワープロ、Webブラウザなど、いろいろなアプリから使用することができます。ただし、ストアアプリでは使用できません。
通常使用するカスタムメニューでは、日付、署名、会員サイトのログインなどに使用するユーザー名やパスワードなどを登録しておいて、必要な時にポップアップメニュー形式でキャレット位置にペーストして使用します。テンプレートファイルの特定のフィールドを指定されたテキスト項目に置き換えて貼り付ける、というような機能もあります。
このカスタムメニューは、用途に応じてユーザーの方が自由に作成することができます。
HTMLやCSSのタグを入力するためのメニュー、LaTeXの数式を入力するためのメニュー、ヤフオクでの定型処理を簡単に行うためのメニュー、などをご自分で作成することができます。
今回はPythonのコードを簡単に入力するためのメニューを作成しましたので、こちらを紹介したいと思います。
ちなみに、今回ペースターのリストメニューを拡張して複数の項目を選択してまとめてペーストできる機能を追加しました。この機能を利用するためには、9月9日に公開した「Ver7.10」以降を使用する必要があります。
ペースターのインストールと簡単な使い方
(注意)ペースターはWindows専用のソフトです。大変申し訳ありませんが、Macのユーザーの方はお使い頂けません。
ペースターは下記のサイトからダウンロードすることができます。
・オータムソフト
なお、今回使用するカスタムメニュー(PythonMenu.txtとその他のファイル)は、上記のオータムソフトのサイトのペースターのダウンロードページから取得できるようになっています。
カスタムメニューのイメージ
それでは、実際にどのようなイメージでPythonのコードを入力していくのかを説明します。
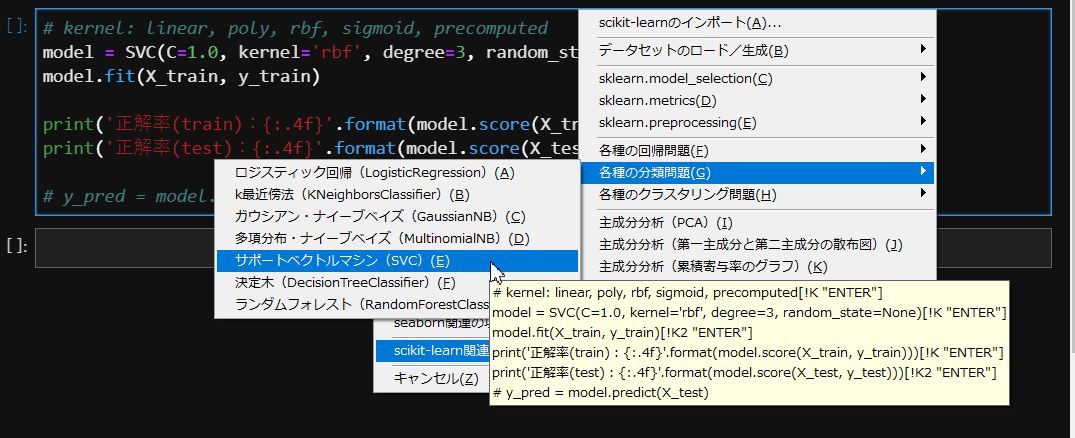
今回使用するメニューファイル(PythonMenu.txt)をペースターに登録して呼び出すと、以下のようなポップアップメニューが表示されます。
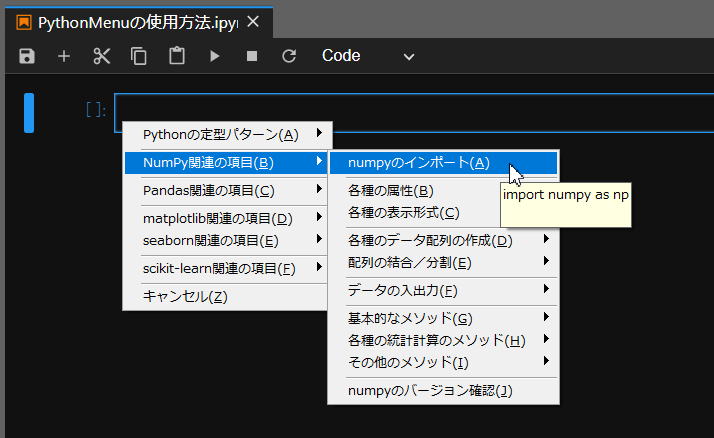
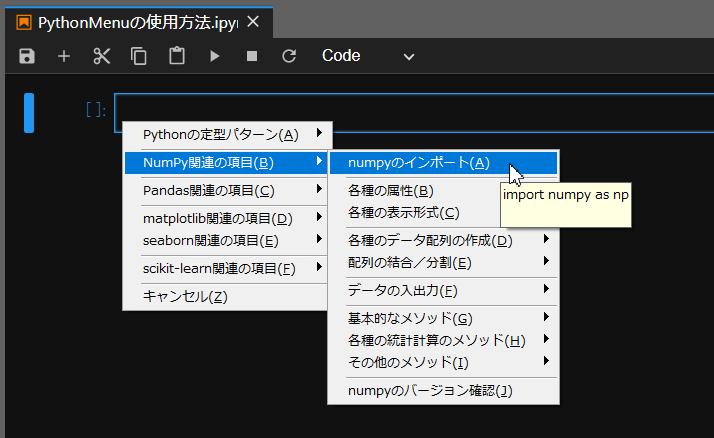
ここで、例えば「NumPyのインポート」を選択すると、以下のようなコードが貼り付きます。
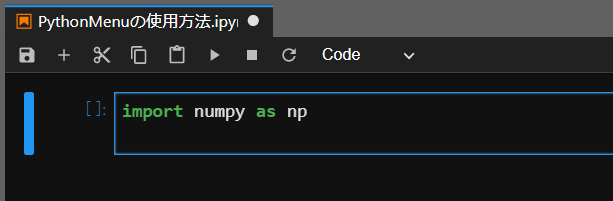
また、複数のインポート文を一度に貼り付けることもできます。
この場合はリストメニューという方法で複数の項目を選択します。ダイアログの右上にある「改行結合」というチェックボックスをオンにしておきます。
(画像では2つの項目だけが選択されていますが、実際には5つの項目を選択しています)
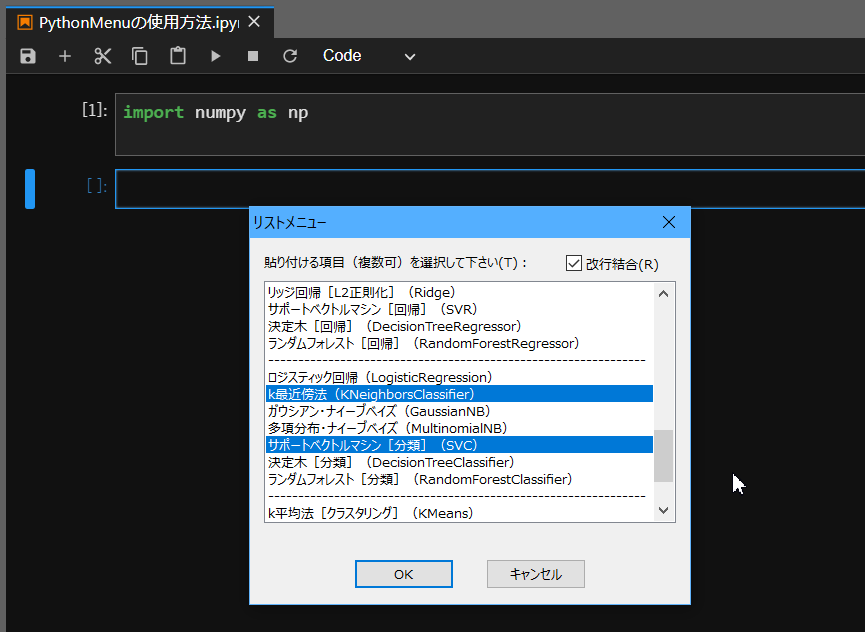
すると、以下のような項目が1度に貼り付きます。
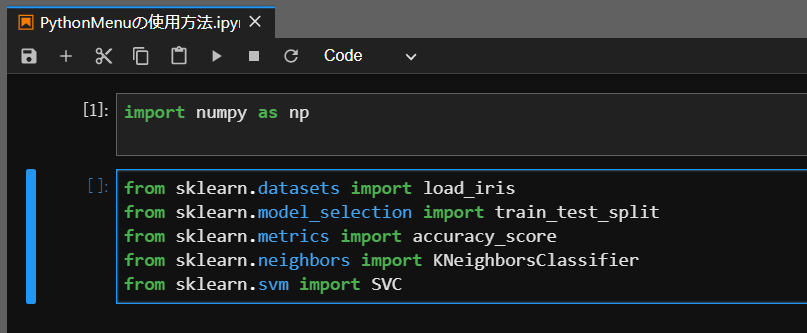
このような感じで、Pythonの定型コードをどんどん貼り付けていくことができます。
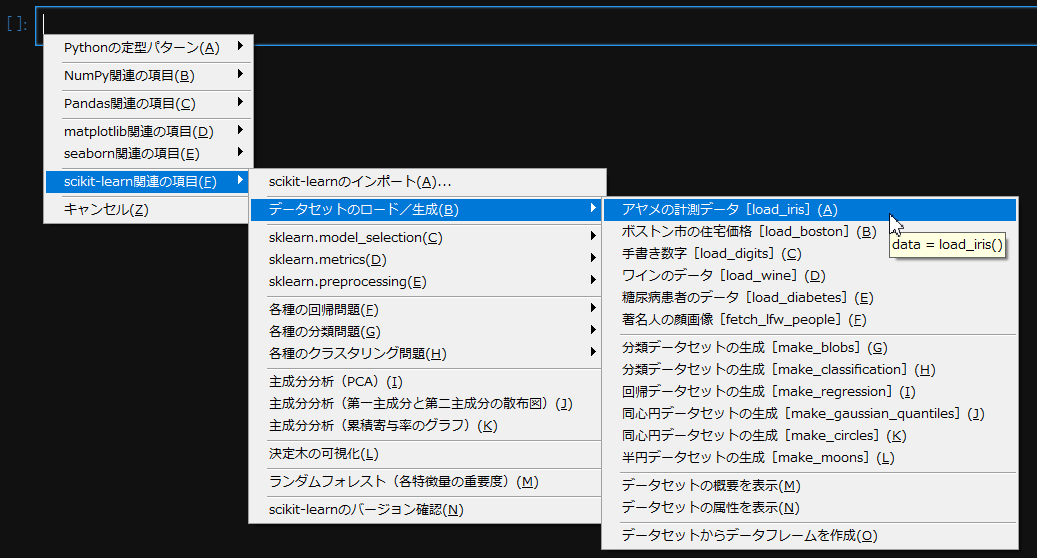

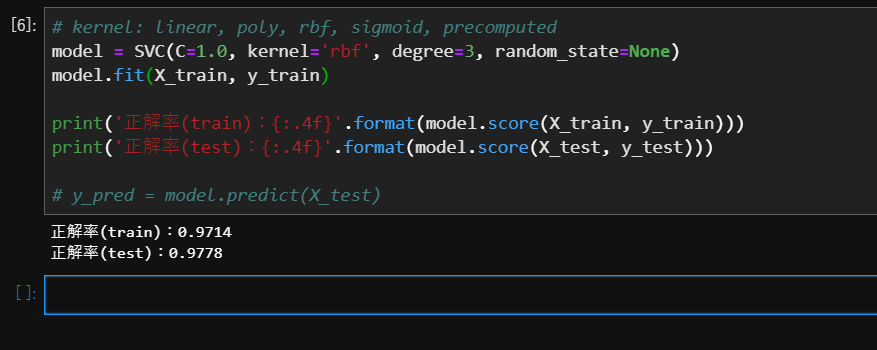
定型文を貼り付けた後で引数などの細かい部分を調整していきます。
上の例ですと、自分で入力したのは、
X = data.data
y = data.target
の部分だけです。
scikit-learnなどの機械学習系のコードはインターフェースが統一されているので、このような方法で入力していくと特に効率的です。
メニューファイルの構成
ここで、メニューファイルの構成を説明しておきます。
まずは、「PythonMenu.txt」というファイルを作成して、その中からインポート文を使用して各種のパッケージ用のメニューファイルを取り込んでいきます。
================================================================
+Pythonの定型パターン
@import "PyBasic.txt"
..
-
================================================================
+NumPy関連の項目
@import "PyNumPy.txt"
..
-
================================================================
+Pandas関連の項目
@import "PyPandas.txt"
..
-
================================================================
+matplotlib関連の項目
@import "PyMatplotlib.txt"
..
================================================================
+seaborn関連の項目
@import "PySeaborn.txt"
..
-
================================================================
+scikit-learn関連の項目
@import "PyScikitLearn.txt"
..
そして、各パッケージの本体を別ファイルで定義します。
scikit-learnの場合ですと、、、
================================================================
#scikit-learnのインポート...
【データセットのロード】 アヤメの計測データ(load_iris) |
[/]from sklearn.datasets import load_iris
/E
【データセットのロード】 ボストン市の住宅価格(load_boston) |
[/]from sklearn.datasets import load_boston
/E
【データセットのロード】 手書き数字(load_digits) |
[/]from sklearn.datasets import load_digits
/E
【データセットのロード】 ワインのデータ(load_wine) |
[/]from sklearn.datasets import load_wine
/E
【データセットのロード】 糖尿病患者のデータ(load_diabetes) |
[/]from sklearn.datasets import load_diabetes
/E
【データセットのロード】 著名人の顔画像(fetch_lfw_people) |
[/]from sklearn.datasets import fetch_lfw_people
/E
【データセットの生成】 分類データセットの生成(make_blobs) |
[/]from sklearn.datasets import make_blobs
/E
【データセットの生成】 分類データセットの生成(make_classification) |
[/]from sklearn.datasets import make_classification
/E
【データセットの生成】 回帰データセットの生成(make_regression) |
[/]from sklearn.datasets import make_regression
/E
【データセットの生成】 同心円データセットの生成(make_gaussian_quantiles) |
[/]from sklearn.datasets import make_gaussian_quantiles
/E
【データセットの生成】 同心円データセットの生成(make_circles) |
[/]from sklearn.datasets import make_circles
/E
【データセットの生成】 半円データセットの生成(make_moons) |
[/]from sklearn.datasets import make_moons
/E
--------------------------------------------------------------- | [$]
パイプラインの生成(make_pipeline) |
[/]from sklearn.pipeline import make_pipeline
/E
--------------------------------------------------------------- | [$]
【model_selection】 データの分割(train_test_split) |
[/]from sklearn.model_selection import train_test_split
/E
【model_selection】 グリッドサーチ(GridSearchCV) |
[/]from sklearn.model_selection import GridSearchCV
/E
(以下省略・・・)
このような感じになります。
つまり、不足しているパッケージや私の作ったものが気に入らなければ(実際のところかなり不完全だと思います)、ご自分で自由にメニューファイルを作成してインポート文で取り込むことができます。
なお、これらのファイルはペースターのデータフォルダの中にサブフォルダを作って、その中にまとめて保存しています。
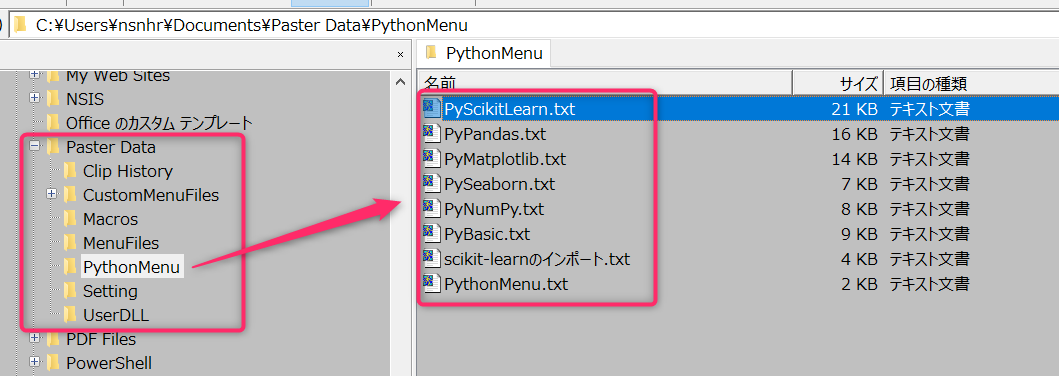
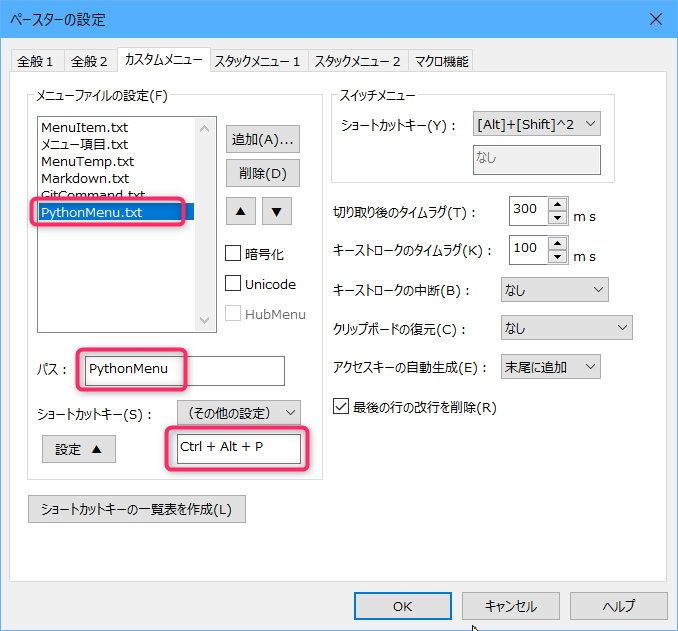
PythonMenu.txtの登録と呼び出しについては、以下のような設定になっています。
ショートカットキーの設定は、お好きなものを指定してください。
Pythonのコードを貼り付ける3つのパターン
Pythonのコードを貼り付けるにあたり、今回はおもに3つのパターンを使用しています。
- 関数やメソッドの引数に何かダミー数値を入力してコードを貼り付ける。
- ウィザード形式のダイアログを使用して各引数の値を入力してもらい、コードを貼り付ける。
- リストメニューを使用して複数の項目を選択してもらい、それを貼り付ける。この時各項目を直接結合するか、改行しながら結合するかを指定します。
それでは、以下で個別に解説します。
コードを直接貼り付ける
メソッドなどに引数を指定する必要がある時に、ダミーの値をいれた状態でペーストします。
例えば、以下のようなケースがあります。

このようなメニュー項目を実行すると、以下のようなコードが貼り付きます。

先頭のコメント文は、もしまだjoblibをインポートしていなければ、コメントアウトします。
そして、ファイル名と圧縮率については、ダミーテキストが入力されているので、貼り付け後に何か適当なものに置き換えます。
ウィザード形式のダイアログを使用してコードを貼り付ける
メソッドなどに複数の引数を指定する必要がある時に、ウィザード形式のダイアログを表示して各項目を入力してもらいます。ちなみに、ペースターではこのような機能を[ユーザー指定]のタグと呼んでいます。
例えば、以下のようなケースがあります。
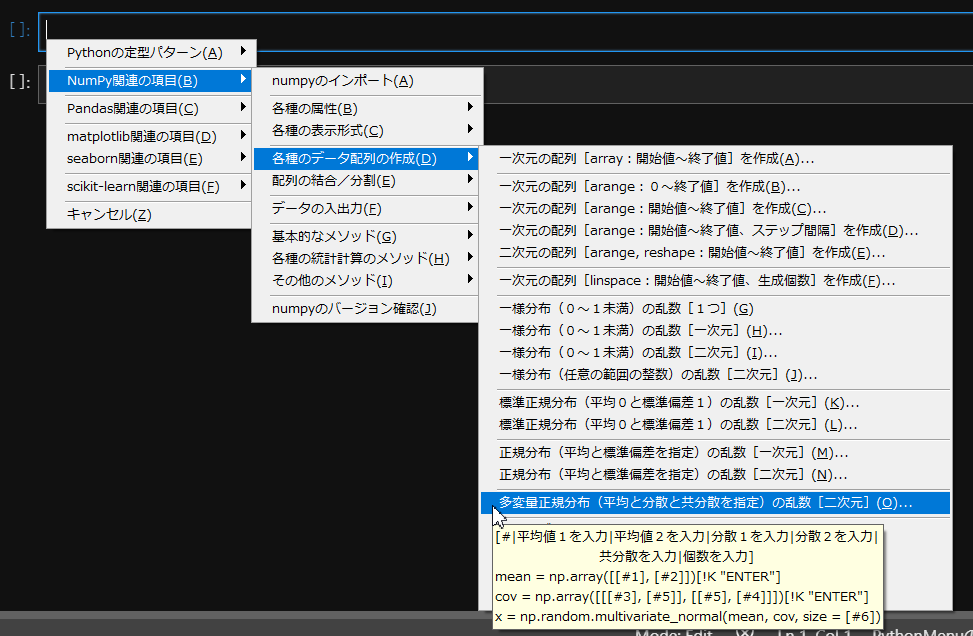
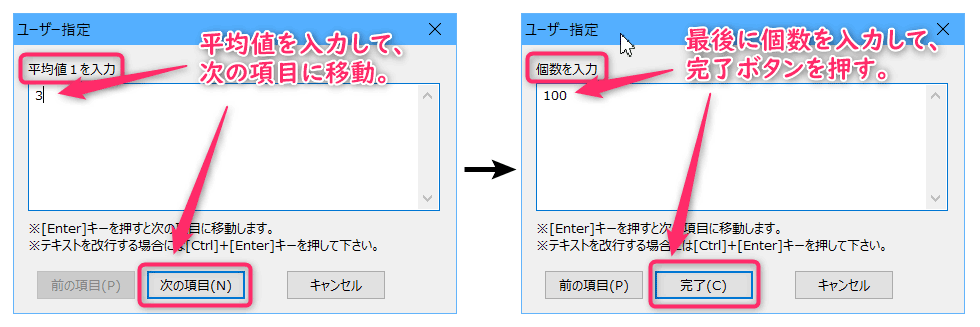
このメニュー項目を実行すると、以下のようなダイアログが表示され、平均値、分散、共分散、個数などを入力します。
すると、以下のようなコードが入力されます。
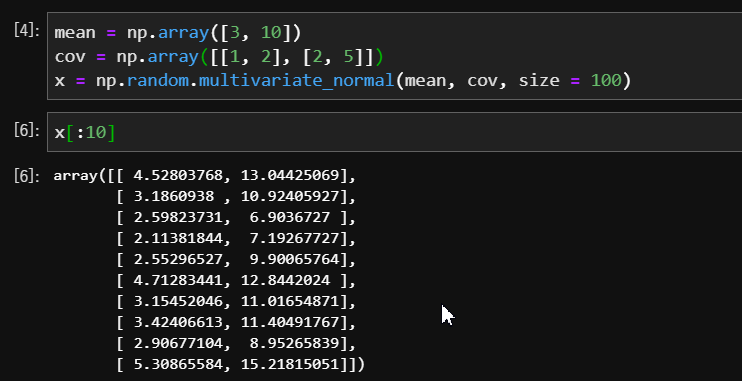
多変量正規分布のように引数が多いものは、このようなダイアログを使用すると、引数の指定方法を覚えていなくても簡単に入力することができます。
ちなみに、メニューファイルには以下のように記述しています。
多変量正規分布(平均と分散と共分散を指定)の乱数[二次元]... |
[/][#|平均値1を入力|平均値2を入力|分散1を入力|分散2を入力|
共分散を入力|個数を入力]
[/]mean = np.array([&1][#1], [#2][&2])[!K "ENTER"]
[/]cov = np.array([&1][&1][#3], [#5][&2], [&1][#5], [#4][&2][&2])[!K "ENTER"]
[/]x = np.random.multivariate_normal(mean, cov, size = [#6])
/E
リストメニューを使用して複数の項目を一括して貼り付ける。
メソッドなどに複数のオプション引数を指定する必要がある時に、リストメニューを表示して各項目を入力してもらいます。
例えば、以下のようなケースがあります。
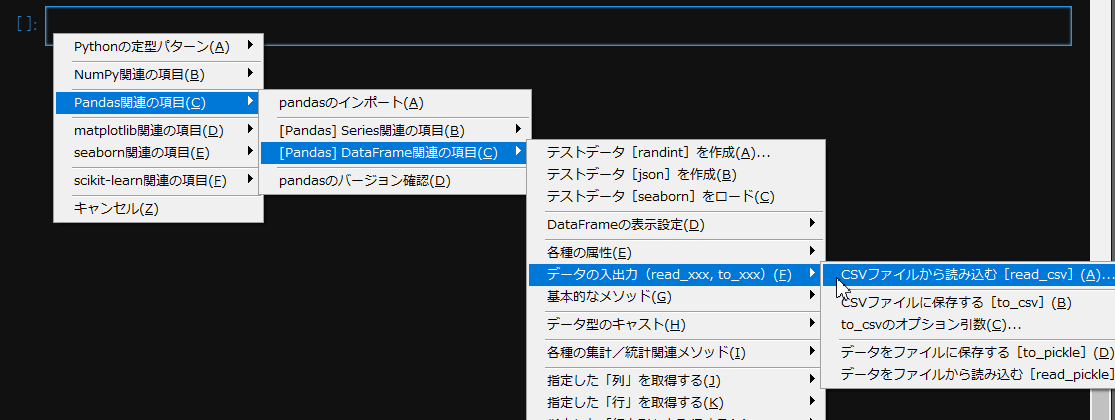
このメニュー項目を実行すると、以下のようなリストメニューが表示されますので、使用したい引数を自由に選択(Ctrlキーを押しながらクリック)します。
この時、最初の「メソッド名」と最後の「閉じカッコ」は必ず選択してください。
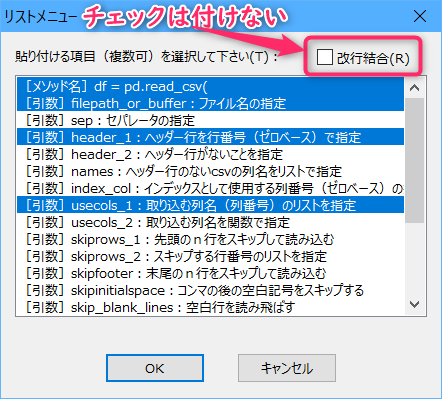
すると、以下のようなコードが入力されます。

余談ですが、最後の右かっこの直前に余分なカンマが入ってしまうので、以下のようなキー操作(バックスペースキー2回)を実行して削除しています。
(前半は省略・・・)
[引数]squeeze:1列のcsvをSeriesに変換する | squeeze=True,[$ ]
[閉じカッコ]) | [!K2 "BACK"])
注意事項
メニューファイルを記述する際に、いくつか注意事項があります。
まず、**ペースターでは日付や時刻、選択テキストの修飾などを行うために、「タグ」という機能があります。**このタグというのは、以下のように角カッコを使用して記述します。
署名[日付版] | [Y1]/[T1]/[D1]([W3]) [H1]:[M2] ハンドルネーム<xxxxxx@xxxxx-soft.com>[&R]
これは、Pythonのリスト([1, 2, 3])を記述する際の記号とぶつかってしまいます。
そこで、ペースターでは角カッコそのものを入力する際には、以下のようなタグを使用します。([&1]と[&2])
; '[' --> [&1], ']' --> [&2] のように記述します。
テスト | [&1]1, 2, 3[&2]
次に、Pythonのインデントの調整についてです。
JupyterLabでもVSCodeでも、関数定義の中やfor文の中で改行を行うと、エディターが自動的に次の行のインデントを調節してくれます。
しかし、クリップボードなどから複数行のテキストを貼り付けると、この自動インデントがうまく機能しません。
したがって、今回作成したメニューファイルでは複数行のコードを貼り付ける時に、各行の行末で[Enter]キーを押しています。
多変量正規分布(平均と分散と共分散を指定)の乱数[二次元]... |
[/][#|平均値1を入力|平均値2を入力|分散1を入力|分散2を入力|
共分散を入力|個数を入力]
[/]mean = np.array([&1][#1], [#2][&2])[!K "ENTER"]
[/]cov = np.array([&1][&1][#3], [#5][&2], [&1][#5], [#4][&2][&2])[!K "ENTER"]
[/]x = np.random.multivariate_normal(mean, cov, size = [#6])
/E
ちょっと面倒ですが、自動インデントを機能させるためにはこのように記述してください。
まとめ
以上、簡単ではありますがメニューファイルの解説でした。
最初は1つのメニューファイルで作成していたのですが、パッケージを追加しているうちにどんどんファイルが大きくなってきてしまったので、各パッケージごとに分割しました。
本当はスクレイピング関連のパッケージも追加したかったのですが、体力がなくなってしまいました・・・今後追加したいと思います。(汗;
Ver1.02で追加済みです。
また、その他のパッケージについては有志の方を募っていますので、是非作成していただけると嬉しいです。
長々と書いてしまいましたが、ここまで読んでいただいてありがとうございました。