はじめに
2023/3/14にOpenAIがGPT-4という新しいAIモデルを公開しました。
このモデルはさまざまなタスクにおいてChatGPT(GPT-3.5)を大幅に上回る結果を示しています。
この記事ではGPT-4を用いて競技プログラミングがどのくらい解けるのかについて調べてみました。
下馬評
OpenAIが公開した論文によると、GPT-4のCodeforcesレーティングは392だそうです。
これはパーセンタイルでいうと下から5%らしいので、
そこまで競技プログラミングが得意なわけではないようです。
ただし、おそらくこれはGPT-4が完全自動でチャレンジした場合のことだと思われます。
GPT-4が書いたコードを人間がレビューすることでバグを修正し、より難しい問題が解ける可能性があると
筆者は考えました。
TL; DR
ChatGPTを用いてAtCoder Beginners Contest 294に参加したところ、以下のような結果になりました。
- A問題からE問題の5問を30分で解くことができた。
- 正の点数を獲得した参加者(6575人)のうち上位15% に相当する成績
- AtCoderレーティングだと1400程度(水色コーダー)
- A, B, C問題は完全自動で解けた。
- D問題もほぼ自動で解けた
- E問題は人間がレビューしバグの箇所を指摘するだけで解けた。
- F, Gについては解くことができなかったが、AIをアシスタントに問題を考察することの可能性を感じることができた。
解いたコードの一覧
全自動解法
ChatGPTを用いてAtCoderの問題を自動解答するための簡単なツールを作りました。
- 問題文のHTMLをスクレイピングして日本語の問題文を抜き出す。
- 問題文のHTMLをPandocでMarkdownに変換する
- 変換したMarkdownをChatGPTに渡して、末尾に「Pythonで実装してください。プログラムだけを出力し、説明はしないでください。」というプロンプトをつける
- 返ってきた出力をそのままAtCoderに提出する。
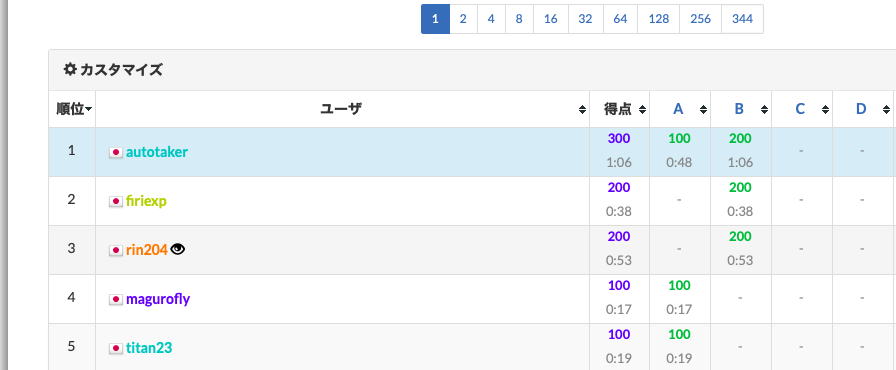
このやり方で過去問を試したところABC293,292のA,B問題は自動で解くことができました。
またABC294ではA,Bを解いた時点で順位表で一位を獲得することができました。
早解き問題では人類を超えた能力を発揮することができます。
半自動解法
全自動で解けなそうな問題は対話を通して解いていきます。
- 問題文をスクレイピングしてMarkdownにするところまでは全自動解法と同じです。
- 問題文の末尾に「この問題を解く方法を簡潔に説明してください」とつけます。こうするとAIは自然言語でアルゴリズムを説明してくれます。
- アルゴリズムがうまくいかなさそうな場合は、問題文を言い換えたり、解法のヒントを与えたりします。(例:二分探索を用いて解いてください、クエリはオフラインで処理できます)
- アルゴリズムが問題なさそうであれば、プログラミング言語を指定して「〇〇で実装して」と指示して、AIにコードを書かせます。
- 出てきたコードが計算量的にまずそうであれば、「〇〇の部分を高速化して」と言う指示を出します。
- 出てきたコードを実行してみます。
- サンプルが合わない場合は人間がデバッグして「〇〇の部分が▲▲のように間違っているので修正してください」と言う指示を出して修正してもらいます。軽微な修正であれば人間が直接直すこともあります。
- サンプルが通ったら提出します。
このようなやり方で過去問を試したところ、C,D問題は割と解くことができました。
ABC294でもD問題とE問題はこのやり方で解くことができました。
例1
プロンプト
この問題を解く方法を簡潔に説明してください。
解答
この問題を解くためには、イベントをシミュレートしながら、次の 2 つのデータ構造を使用します。
- まだ呼ばれていない人の番号を管理するためのキュー
- すでに呼ばれているが受付に行っていない人の番号を管理するためのプライオリティキュー(最小値が先頭にくる)
次に、以下の手順で問題を解決します。
- N 人をまだ呼ばれていない人のキューに追加します。
- Q 個のイベントを順番に処理します。
- イベントが 1 の場合:まだ呼ばれていない人のキューから先頭の人を取り出し、呼ばれているが受付に行っていない人のプライオリティキューに追加します。
- イベントが 2 x の場合:呼ばれているが受付に行っていない人のプライオリティキューから人 x を削除します。
- イベントが 3 の場合:呼ばれているが受付に行っていない人のプライオリティキューから先頭の人を取り出し、その人の番号を出力します。ただし、その人はプライオリティキューに残します。
すべてのイベントを処理し終わったら、アルゴリズムを終了します。
プロンプト
C++で実装してください
解答
以下に、C++ での実装例を示します。
#include <iostream>
#include <queue>
#include <set>
int main() {
int N, Q;
std::cin >> N >> Q;
std::queue<int> not_called;
std::set<int> called_not_attended;
for (int i = 1; i <= N; ++i) {
not_called.push(i);
}
for (int i = 0; i < Q; ++i) {
int event;
std::cin >> event;
if (event == 1) {
int person = not_called.front();
not_called.pop();
called_not_attended.insert(person);
} else if (event == 2) {
int x;
std::cin >> x;
called_not_attended.erase(x);
} else if (event == 3) {
int person = *called_not_attended.begin();
std::cout << person << std::endl;
}
}
return 0;
}
このコードは、先程説明したアルゴリズムを C++ で実装したものです。not_called は std::queue を、called_not_attended は std::set を使用しています。std::set は要素をソートされた状態で保持し、重複を許さないため、最小値を効率的に取得することができます。イベント 3 で最小値を出力するだけで、削除は行わないため、この実装が効率的です。
例2
プロンプト
この問題を解く方法を簡潔に説明してください。
解答
この問題を解くには、連長圧縮された2つの列を元の形に戻し、それぞれの位置で一致する数字があるかどうかを調べます。
- まず、与えられた連長圧縮された2つの列から、元の2行L列のマス目を再現します。これは、各(v, l)ペアについて、l回繰り返すことでvを生成することで実現できます。
- 2つの行が生成されたら、それらの各列を比較して一致する数字があるかどうかを調べます。一致する数字がある場合、カウントを1つ増やします。
- 最後に、カウントされた一致する数字の数を出力します。
このアプローチは効率的であり、与えられた制約の下で実行可能です。
プロンプト
連長圧縮から元の文字列を復元すると非常に長くなります
解答
すみません、確かにその方法は非効率的で、長い文字列の場合は実行可能でないことがあります。代わりに、次の方法を使用して、2つの連長圧縮された列を効率的に処理できます。
- 2つの連長圧縮された列に対して、それぞれの列のインデックスと対応する値と長さの残りを保持する2つの変数を使用します。初期値はインデックス0、対応する値は最初のペアの値、残りの長さは最初のペアの長さです。
- 2つの列を同時に走査します。現在の値が一致している場合は、一致する部分の長さをカウントに加算し、両方の列の残りの長さを一致した部分の長さだけ減らします。
- 現在の値が一致しない場合、残りの長さが短い方の列のインデックスを次のペアに進め、残りの長さを更新します。もし両方の列の残りの長さが同じ場合は、両方のインデックスを進めます。
- どちらかの列が終了するまで、手順2および3を繰り返します。
- 最後に、一致する部分のカウントを出力します。
この方法は、連長圧縮された列を直接処理するため、大幅に効率が向上し、制約内で実行可能です。
プロンプト
アルゴリズムをC++で実装してください
解答
以下に、C++でのアルゴリズム実装を示します。
#include <iostream>
#include <vector>
using namespace std;
int main() {
long long L;
int N1, N2;
cin >> L >> N1 >> N2;
vector<pair<int, long long>> compressed1(N1), compressed2(N2);
for (int i = 0; i < N1; i++) {
cin >> compressed1[i].first >> compressed1[i].second;
}
for (int i = 0; i < N2; i++) {
cin >> compressed2[i].first >> compressed2[i].second;
}
long long ans = 0;
int idx1 = 0, idx2 = 0;
long long remaining1 = compressed1[idx1].second, remaining2 = compressed2[idx2].second;
while (idx1 < N1 && idx2 < N2) {
if (compressed1[idx1].first == compressed2[idx2].first) {
long long matched_length = min(remaining1, remaining2);
ans += matched_length;
remaining1 -= matched_length;
remaining2 -= matched_length;
if (remaining1 == 0) {
idx1++;
if (idx1 < N1) {
remaining1 = compressed1[idx1].second;
}
}
if (remaining2 == 0) {
idx2++;
if (idx2 < N2) {
remaining2 = compressed2[idx2].second;
}
}
} else {
if (remaining1 < remaining2) {
idx1++;
if (idx1 < N1) {
remaining1 = compressed1[idx1].second;
}
} else {
idx2++;
if (idx2 < N2) {
remaining2 = compressed2[idx2].second;
}
}
}
}
cout << ans << endl;
return 0;
}
このC++コードは、説明したアルゴリズムを使用して、2つの連長圧縮された列を効率的に処理して一致する部分の長さを求めます。この実装は制約内で実行可能です。
プロンプト
現在の値が一致しない場合の処理が間違っています。正しい手続きを説明した上で再実装してください。
解答
すみません、確かに現在の値が一致しない場合の処理が不適切でした。正しい手続きは次のようになります。
- 現在の値が一致しない場合、残りの長さが短い方の列のインデックスを次のペアに進め、残りの長さを更新します。両方の列の残りの長さが同じ場合は、両方のインデックスを進めます。
- どちらかの列の残りの長さがゼロになった場合、その列のインデックスを次のペアに進め、残りの長さを更新します。
これを反映したC++コードは次のようになります。
#include <iostream>
#include <vector>
using namespace std;
int main() {
long long L;
int N1, N2;
cin >> L >> N1 >> N2;
vector<pair<int, long long>> compressed1(N1), compressed2(N2);
for (int i = 0; i < N1; i++) {
cin >> compressed1[i].first >> compressed1[i].second;
}
for (int i = 0; i < N2; i++) {
cin >> compressed2[i].first >> compressed2[i].second;
}
long long ans = 0;
int idx1 = 0, idx2 = 0;
long long remaining1 = compressed1[idx1].second, remaining2 = compressed2[idx2].second;
while (idx1 < N1 && idx2 < N2) {
if (compressed1[idx1].first == compressed2[idx2].first) {
long long matched_length = min(remaining1, remaining2);
ans += matched_length;
remaining1 -= matched_length;
remaining2 -= matched_length;
} else {
if (remaining1 < remaining2) {
remaining2 -= remaining1;
idx1++;
if (idx1 < N1) {
remaining1 = compressed1[idx1].second;
}
} else {
remaining1 -= remaining2;
idx2++;
if (idx2 < N2) {
remaining2 = compressed2[idx2].second;
}
}
}
if (remaining1 == 0) {
idx1++;
if (idx1 < N1) {
remaining1 = compressed1[idx1].second;
}
}
if (remaining2 == 0) {
idx2++;
if (idx2 < N2) {
remaining2 = compressed2[idx2].second;
}
}
}
cout << ans << endl;
return 0;
}
この修正されたC++コードは、正しい手続きに基づいて、2つの連長圧縮された列を効率的に処理し、一致する部分の長さを求めます。この実装は制約内で実行可能です。
AIで解けない問題
過去問でいろいろ試していたのですが、半手動解法でABCのE問題は50%くらい、F問題以降は基本解けないと言う感じでした。
解けないケースは大きく二つに分けられます。
そもそも解法が思いつかないケース
C問題以降だと人間が解法を理解できていない場合、その問題を解くことはほぼできません。
なので、指示する人間あるいはAIが解法を思いつき、わかりやすく説明する必要があります。
「この問題を解く方法を簡潔に説明してください」や「この問題を解くのに使えるアプローチをいくつか挙げてください」などのプロンプトを駆使してヒントを探すことはできますが、
適切な解法が見つからないことも多いです。
AIがうまく指示を理解してくれないケース
人間が抽象的な解法を思いついたとしても、それをうまくAIに指示できず解答ができないことがあります。
GPT-4はGPT-3.5に比べると改善されていますが、特に論理を正確に追うことが苦手です。
適当に辻褄を合わされてしまうことがあり、結構細かく指示を出さないと思った通りには動いてくれません。
あまりやりすぎると自然言語でプログラミングしている気分になり、「これ自分で書いたほうが早くない」と言う感じになります。
特に苦手だったのは図形の問題でした。
この辺は画像をサポートすると改善されるかもしれませんね。
AIとのペアプロの可能性
ChatGPTを使った競技プログラミングは自らの競技プログラミング体験を変えてくれるものでした。
いきなりコードを出すよりも、まずは自然言語で解法の議論をAIとするのが人間とペアプロするようで楽しいです。
また、AIに雑な実装を出してもらってそれをベースに挙動や改善点を考えればよいので、
慣れてくればより解法を考えることに集中することができます。
ChatGPTを用いたテクニックで競技プログラミングに便利そうなものをまとめておきます。
「このプログラムが無限ループしているのはなぜですか」「〇〇というコンパイルエラーがでます」
プログラムの挙動に関するデバッグはなかなかうまくできませんが、
静的解析的なエラーについてはChatGPTは十分な精度でエラー修正できます。
「このPythonコードをC++で書き直してください」
これが今までになかった体験です。プログラミング言語の選択が競技プログラミングの成績に少なからず影響していたのですが、もうそんなことはなくなりました。
デバッグが簡単な言語でサンプルが通るまで実装して提出する前にC++で書き直せば良いのです。
「〇〇のデータ構造を実装して」
ライブラリを頑張って整備する必要は(あまり)なくなりました。UnionFindやセグメント木のような基本的なデータ構造なら問題に応じて微調整したものを自動生成してくれます。
「アルゴリズムの動作をサンプルを例にステップバイステップで説明して」
これも強力なプロンプトの一つです。デバッガを使わずともアルゴリズムがどのように動くのかをわかりやすく解説してくれます。
GPT-3.5だとコンテキストが短くてあまり長い動作はシミュレーションできなかったのですが、GPT-4ならかなり正確にシミュレーションできます。
おわりに
さてタイトルの通り、ChatGPTと競技プログラミングの今後について筆者の予想をまとめます。
- 現状のパフォーマンスだと水色コーダーあたりが限界なのでAIが青コーダーになるには更なるブレークスルーが必要。
- 今回示した半手動解法のような強化学習をすれば精度はだいぶ上がるのではないか
- 現時点でコンテストがAIによってぶっ壊れる懸念は少ない。
- ABCでは将棋AIのようにChatGPTを使いこなすプログラマーが増えて、使えないプログラマーが不利になる
- 黄色〜赤コーダーレベルになると人に指示するよりも自分で手を動かしたほうが早いのでCopilot程度の効果しかないだろう
今後もAIが進歩していくとは思うので競技プログラミングのゲーム性が壊れないように対策を考える時期にはきているのではないでしょうか。