Haskellで効率の良いコードを書くためにはいかに不要なサンクを潰すか、ということが重要だと言われています。しかし、そもそもなぜサンクが増えると効率が悪くなるのでしょうか。
Haskellのメモリ確保は高速
まず、Haskellにおいてメモリの確保はどの程度コストがかかるものなのでしょうか。次のプログラムを使って確かめてみましょう。
{-# LANGUAGE BangPatterns #-}
{-# OPTIONS_GHC "-ddump-simpl" #-}
module Main2 where
bench :: Int -> (a -> a) -> a -> a
bench n f i = go n i
where
go 0 !i = i
go k !i = go (k-1) (f i)
{-# NOINLINE bench #-}
main :: IO ()
main = print (bench 100000000 (\x -> x + 1 :: Int) 0)
このプログラムはちょうど1億個のInt型の値を生成するようにデザインされています。このプログラム(heap-light)を実行して実行の統計情報を取ってみましょう。
stack exec heap-light -- +RTS -s
100000000
1,600,051,368 bytes allocated in the heap
62,504 bytes copied during GC
44,576 bytes maximum residency (2 sample(s))
29,152 bytes maximum slop
0 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 1524 colls, 0 par 0.003s 0.003s 0.0000s 0.0000s
Gen 1 2 colls, 0 par 0.000s 0.000s 0.0001s 0.0001s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.474s ( 0.476s elapsed)
GC time 0.003s ( 0.003s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.477s ( 0.479s elapsed)
%GC time 0.0% (0.0% elapsed)
Alloc rate 3,373,401,097 bytes per MUT second
Productivity 99.4% of total user, 99.4% of total elapsed
0.474秒で実行できました。Alloc rateの欄に書かれていますが、これはおよそ3.38GB/sの速さでメモリを確保できているということであり、十分な速さであると考えられます。比較としてCのメモリ確保(malloc/free)と比べてみましょう。
# include <stdio.h>
# include <stdlib.h>
int main(void)
{
int i, n;
n = 100000000;
long long* ptr = malloc(16);
for( i = 0; i < n; i++) {
free(ptr);
ptr = malloc(16);
ptr[1] = i;
}
printf("%lld\n", ptr[1]);
free(ptr);
return 0;
}
多少不自然なプログラムになっているのはgccの最適化を欺くためです。(ループ内でmallocとfreeを行うコードを書いたら最適化でループごと消去されてしまったので)
このプログラムを実行すると0.834秒かかりました。すなわち、C言語よりも1.8倍程度速いということになります。
gcc -O main.c && time ./a.out
99999999
real 0m0.834s
user 0m0.833s
sys 0m0.000s
HaskellのGCが遅い
ではなぜHaskellのプログラムは遅くなるのでしょうか。
先程の例では本質的に必要なメモリは再帰関数の引数iの2wordsだけであるので、より多くのメモリを必要とするプログラム(heap-heavy)で実験してみましょう。
{-# LANGUAGE BangPatterns #-}
{-# OPTIONS_GHC "-ddump-simpl" "-fspec-constr" #-}
module Main where
import Debug.Trace
import qualified Data.Vector as V
import System.Environment
bench :: Int -> Int -> V.Vector Int
bench n i = V.unfoldrN n (\ !x -> Just (x, x+1)) i
main :: IO ()
main = do
[n] <- fmap (map read) getArgs
let k = 100000000 `div` n
putStrLn $ "iteration: " ++ show k
let go i !x | i == 0 = print $ V.last x
| otherwise = traceMarker "tick" $ go (i - 1:: Int) (bench n i)
go k (bench n 0)
このプログラムは標準入力から整数nを受け取り、「長さnのInt型の配列を生成する」という手続きを100000000/n回だけ繰り返します。したがって、合計で3 * 100M words = 2.4G byteのメモリを確保します。また、再帰関数go i xの実行中は長さnの配列を開放できないので、常にn * 3 wordsのメモリを必要とするプログラムになっています。このプログラムのnを1000から4,096,000まで2倍ずつ変化させて実行時間をグラフにしてみましょう。
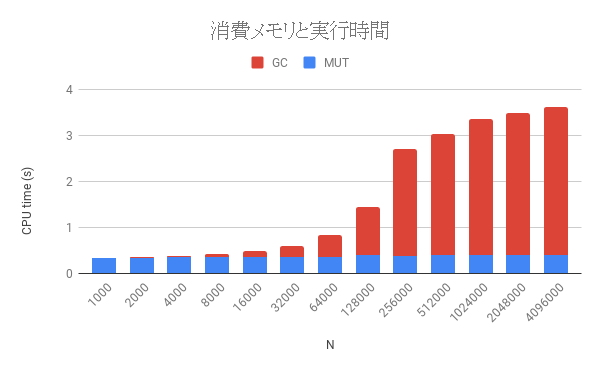
MUTはプログラム本体の計算に必要としたCPU時間で、GCはガーベッジコレクションに要したCPU時間です。ここからわかるようにMUTの時間はほとんど変わりませんが、nが64Kを超えたあたりから急激にGCの時間が増えて、実行時間も遅くなっています。
この挙動を理解するためにはGHCのランタイムシステムとそこで行われているガーベッジコレクションの仕組みについて理解する必要があります。
GHCの世代別GC
GHCでは(デフォルトで)以下の3つの世代にヒープオブジェクトを分けて確保します。
- Nursery blocks: Nurseryとは託児所のことで、新しく作られたヒープオブジェクトはまずここに確保されます。nursery blocksは各物理スレッドに1列ずつ作られます。このため、Haskellでは複数のスレッドが同時にメモリを確保してもロックせずに済みます。
- Gen-0 blocks: 比較的若いヒープオブジェクトが住まう領域です。グローバルに1列のブロックとなっています。
- Gen-1 blocks: 長く生きるヒープオブジェクトが住まう領域です。これもグローバルに1列のブロックになります。
Aging (成長)/Promotion
世代別GCでは各ヒープオブジェクトはGCが走るたびに年を取ります。これをAgingまたはPromotionと呼びます。年を取ると、そのヒープオブジェクトは次の世代のブロックに移動します。つまり、Nurseryに住んでいたオブジェクトはGen-0に移動し、Gen-0に住んでいたオブジェクトはGen-1に移動します。Gen-1に住んでいるオブジェクトはもう年を取りません。
世代別GC
GHCではMinor GCとMajor GCという2種類のGCが行われます。
- Minor GCではNusery blocksとGen-0 blocksのオブジェクトがGCされます。
-
Major GCではすべてのブロックのオブジェクトがGCされます。
どちらのGCもデフォルトではCopy GCが走るようです。
いつGCが起こるか
あるスレッドでnursery blocksを使い果たすと、HeapOverflowとなり、GCがトリガされます。この際、Gen-1 blocksの長さがしきい値を超えているとMajor GCが走ります。超えていない場合はMinor GCが走ります。このしきい値は前回のGCで生き残ったオブジェクトのブロック数にFactor(+RTS -Fで指定できる、デフォルト値2)をかけたものになります。
nursery blocksのサイズは+RTS -Aで指定できます。現在のデフォルト値は1M byteです。
GCの計算時間
GCにかかる時間のほとんどは生きているヒープオブジェクトを次の世代にコピーするのに費やされます。したがって、各世代の生きているオブジェクトのサイズ に比例した実行時間がかかります。たとえ各世代に大量のオブジェクトがあったとしても、そのほとんどが死んでいる場合にはGCはほとんど時間を消費しません。
GCの気持ちになって考える
先程の2つのベンチマークプログラムの振る舞いをGCの気持ちになって考えてみましょう。
heap-light
bench :: Int -> (a -> a) -> a -> a
bench n f i = go n i
where
go 0 !i = i
go k !i = go (k-1) (f i)
{-# NOINLINE bench #-}
このプログラムは大量のヒープオブジェクトを生成しますが、それらはすべて、再帰関数が1段進むと死にます。したがって、nursery blocksがいっぱいになるたびにMinor GCが呼ばれますが、このとき、生きているヒープオブジェクトは現在の再帰関数goの引数iのみです。したがってGCはほとんど時間を消費しません。
heap-heavy
bench :: Int -> Int -> V.Vector Int
bench n i = V.unfoldrN n (\ !x -> Just (x, x+1)) i
main :: IO ()
main = do
[n] <- fmap (map read) getArgs
let k = 100000000 `div` n
putStrLn $ "iteration: " ++ show k
let go i !x | i == 0 = print $ V.last x
| otherwise = traceMarker "tick" $ go (i - 1:: Int) (bench n i)
go k (bench n 0)
このプログラムは長さnのV.Vector Intを生成する部分がボトルネックとなります。このVectorはn個のInt型へのポインタを格納しています。また、Int型の値もn個あるので、bench n iはサイズn * 8 byteの大きなヒープオブジェクト一つと、サイズ16byteの小さなヒープオブジェクトn個を生成します。
thread-scopeというプログラムを使ってGCがいつ起こっているかを見てみましょう。
n=16kの時
このときは、GCは高速に動作し、全体の実行時間のおよそ25%を占めていました。
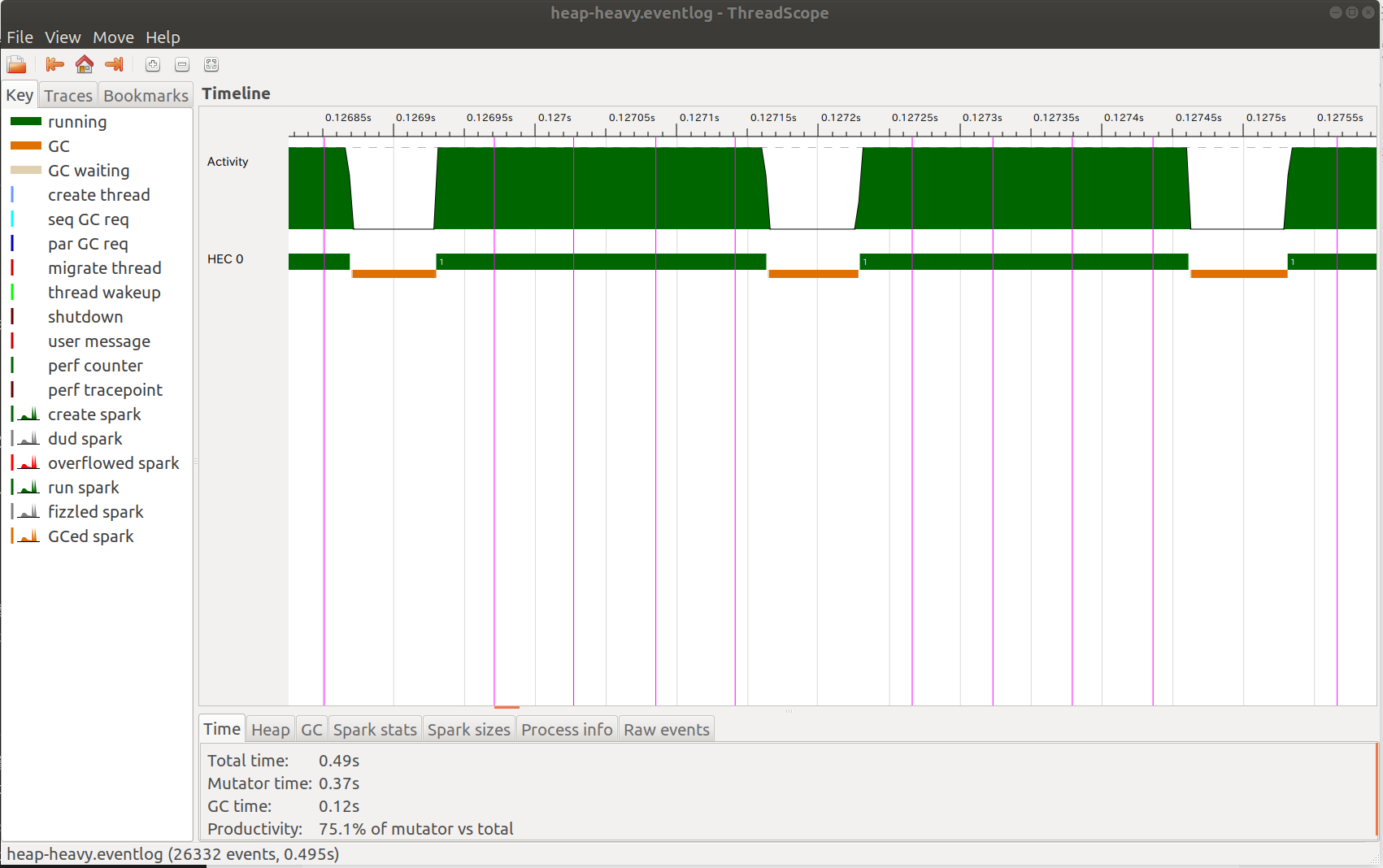
このグラフの緑色が計算を行っている部分、赤色がGCを行っている部分となります。
縦線はtraceMarker "tick"の呼び出しを表していて、すなわち再帰関数go i xが一回分進んだということになります。すなわち、go i xが何回か進むごとにGCが発生しています。この時生きているオブジェクトは現在生成中のvectorのみなので、たかだか3 * 8 * 16k = 384 k bytes のメモリだけがnursery blocksからGen-0にコピーされます。コピーされたヒープオブジェクトも次のGCが呼ばれる頃には死んでいるので、Gen-0のブロック数は一定のままで、Major GCはほとんど呼ばれません。
n=128kのとき
このときはGCの実行時間は全体の75%を占めていました。すなわちn=16kの場合と比べると10倍近くGCが遅くなっています。
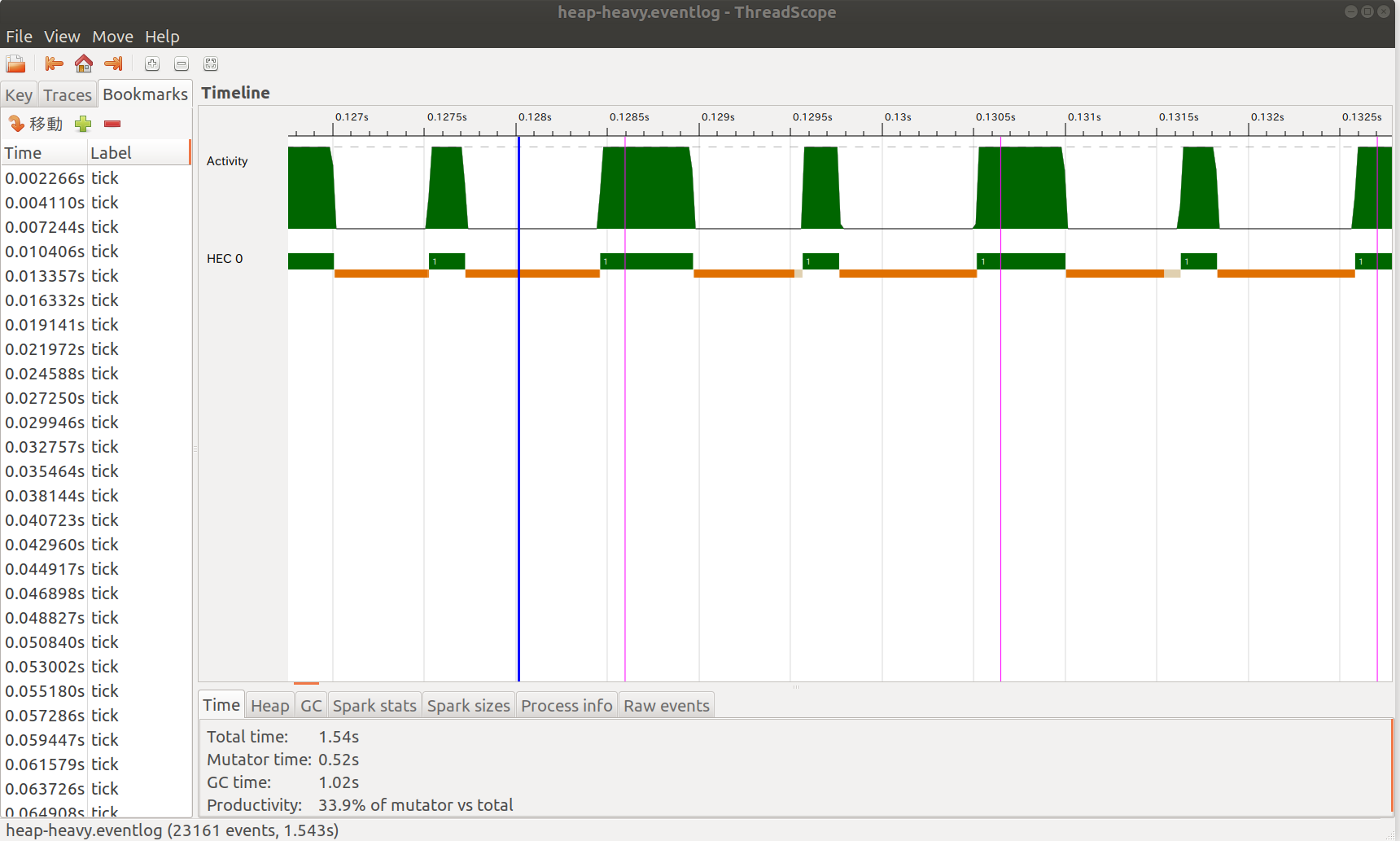
この場合ではgo i xが一回進むごとにGCが2回走っていることがグラフから読み取れます。調べてみると、実行時間の長いほうがMinor GCで短いほうがMajor GCとなっています。
この理由を考察してましょう。
現在生成中のvectorのサイズは3 * 8 * 128 k = 3M bytes となっていて、これはnursery blocksのサイズの3倍あります。
再帰関数の一つ前のVectorがGen-1にいたと考えます。traceMarker "tick"の呼び出しのあとの最初のGC(Major GC)が走るとき、プログラムは次のvectorを生成している途中だと考えられます。Gen-1にいたvectorはもう死んでいるので回収されます。一方で新しく生成中のvectorは生きているので、nursery blockからGen-0 blockにコピーされます。nursery blockのサイズは1M bytesなので1M bytesのコピーが発生します。GCが終わった際、生きているGen-1オブジェクトはほとんどないはずなので、Major GCのしきい値は更新されません。
つぎのGC(Minor GC)が走る時もまた、プログラムはvectorの生成途中です。このとき、先程Gen-0にいたオブジェクトたちはまだ生きているのでGen-1に移動し、nursery blocksで新たに確保されたオブジェクトたちはGen-0に移動します。(もしかしたらEarly Promotionという仕組みによってGen-1に移動しているかもしれない)
このようにGCが起こるたびに大量のメモリコピーが発生しGCに時間がかかってしまいます。またMajor GCとMinor GCが交互に発生してしまっているのも良くないでしょう
n=4096kの場合
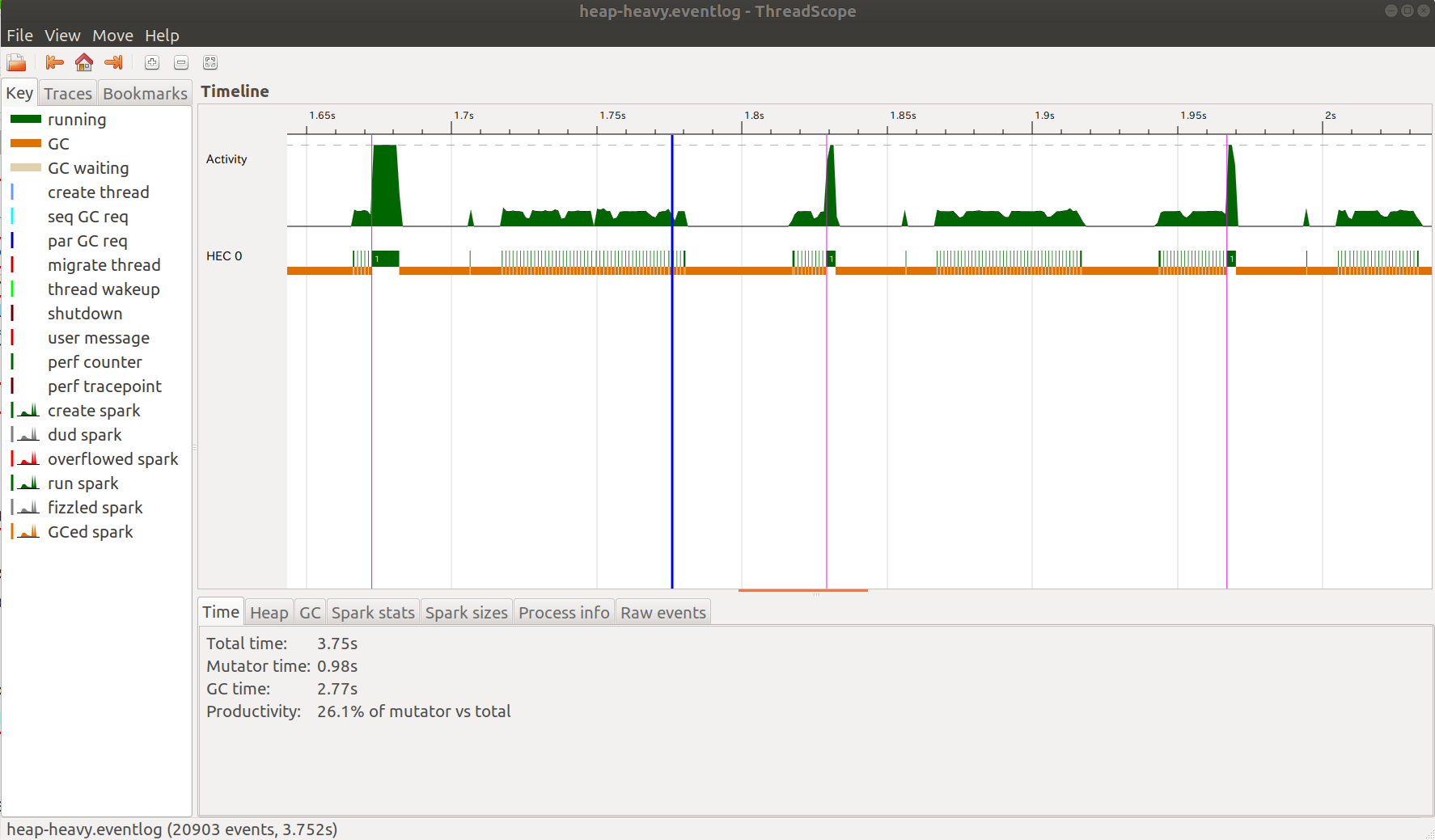
今回はvectorのサイズが極めて大きいので、再帰関数が呼び出されるたびにおよそ50回のMinor GCと1回のMajor GCが走っていました。GCの実行時間は全体の88%を占めています。nがこのあたりになるとGCの時間はあまりnに依存しなくなります。
vector自身はすぐにGen-1の住人になっているはずです。各minor GCでは生成したIntオブジェクトを次の世代に移すということが行われます。したがって、Gen-1のブロック数が次第に増大し、しばらくするとMajor GCが走ります。しかし、このMajor GCでもvectorは回収できず生き残るため、Major GCを起こすしきい値が徐々に大きくなってvectorのサイズくらいになります。この頃になると再帰の一つ前のvectorを回収できるので、ようやくGen-1のブロック数が減り、しきい値も小さくなります。したがって、このしきい値はvectorのサイズ程度に収束するでしょう。
考察
実行時間のグラフを振り返ってみましょう。
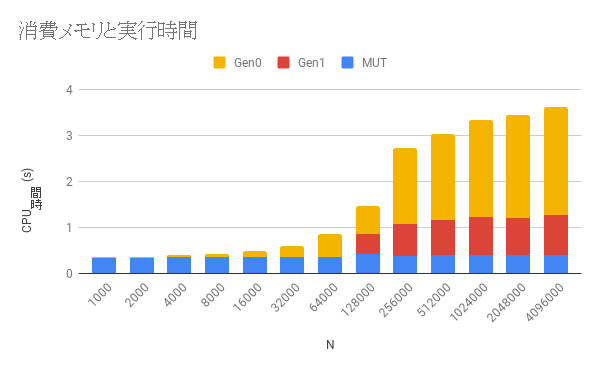
先程のグラフではGCとしてまとめていた部分を世代別の実行時間に分割しました。Gen-1の実行時間はnが256k以上になったあたりから一定でGen-0の実行時間が増えていることがわかります。これは以下のように説明できます。
- GCはnursery blocksがいっぱいになるたびに呼ばれ、GCが呼ばれるたびにnursery blocksは空になるので、(Minor GCの回数)+(Major GCの回数)は
nの大きさによらず一定(今回だと1500回程度)です。 - 一時オブジェクトのサイズがnusery blocksのサイズを超えると、一時オブジェクトをほとんどすべて次の世代にコピーする必要が出てくるため、Minor GCに時間がかかるようになります。今回だとn = 1 M byte / 24 byte = 41.7 kあたりが境界線です。
- オブジェクトがGen-1で生き残るようになると、Gen-1ブロックのサイズ上限は動的に変化し、プログラムが実際に必要とするメモリ量くらいに収束します。したがってMajor GCにかかる時間はプログラム全体で確保されたメモリを解放する時間であり、それは
nに依存しないのであまり実行時間は変化しません。 - 一方、全体のGC回数は一定なのでMinor GCの呼ばれる回数はMajor GCの回数が減るにつれて増えていきます。1回のMinor GCにかかる時間はnursery blockとGen-0ブロックのサイズはそれぞれたかだか1M byteなので、最悪でも定数時間(数ms程度)です。したがって、Minor GCにかかる時間も増加しますが、Minor GCの呼ばれる回数は1500回の上限があるのでその時間に収束します。
GCのパラメータ調整
さて、大きな一時オブジェクトを大量に生成する場合、GCに時間がかかることがわかりました。このようなプログラムを高速に動作させたいときはRTSのパラメータを渡してGCの挙動を変えてやる必要があります。
今回の説明で理解できるパラメータは+RTS -A<size>です。これはnursery blocksのサイズを指定します。このサイズを考えられる一時オブジェクトのサイズよりも大きくしてやれば、一時オブジェクトがnurseryを卒業することなく死ぬため、GCの時間が劇的に早くなります。
先程の例でn = 1024kのとき、一時オブジェクトのサイズは24 M byteくらいになるので-A32Mと指定してみましょう。
$ stack exec heap-heavy -- +RTS -ls -s -A32M -RTS 1024000
iteration: 97
1024000
2,408,004,448 bytes allocated in the heap
390,617,840 bytes copied during GC
10,163,184 bytes maximum residency (2 sample(s))
195,600 bytes maximum slop
9 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 47 colls, 0 par 0.252s 0.265s 0.0056s 0.0085s
Gen 1 2 colls, 0 par 0.008s 0.008s 0.0039s 0.0045s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.409s ( 0.431s elapsed)
GC time 0.260s ( 0.273s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.669s ( 0.705s elapsed)
%GC time 0.0% (0.0% elapsed)
Alloc rate 5,888,405,262 bytes per MUT second
Productivity 61.1% of total user, 61.2% of total elapsed
実行時間は669msとなりました。全体で5倍程度、GCの時間だけだと10倍以上高速になっています。
他にもGCの挙動を変える様々なパラメータがあります。
ドキュメントに色々書いてありますが、やはりGCの気持ちにならないとよくわからないのでGHCのソースとにらめっこしながらまた分かったら記事にまとめようと思います。
参考文献
- GHC/Memory_Management
- Parallel Generational-Copying Garbage Collection with a Block-Structured Heap (2008): 概念を理解するのには役立ちますが、今のGHCとは実装が異なるようです。
- ghc wiki:Commentary/Rts/Storage/GC: 実装よりのトピックがまとめてあります。
- ghc/ghc: ソース