コメントを集めるには?
コメントを集めるのって、至難の業ですよね。
少し考えたのですが、Twitterからニュースをツイートしているコメントから、
抜き取ればいいんじゃないかと閃きました💡
PythonでTwitterのニュースに対する、コメントを抽出しました。
import tweepy
import re
from collections import Counter
import unicodedata
import string
consumer_key = "twitterapiのconsumer_key"
consumer_secret = "twitterapiのconsumer_secret"
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
api = tweepy.API(auth)
title = "ニュースのタイトル"
url = "ニュースのURL"
site_domain_name = "配信元"
title1 = r"" + re.escape(title) + r"(.|\s)*#\S+(\s|$)"
title2 = r"" + re.escape(title) + r"\s(.{0,40})https?://[\w/:%#\$&\?\(\)~\.=\+\-]+"
title3 = r"" + re.escape(title) + r"(.{0,40})https?://[\w/:%#\$&\?\(\)~\.=\+\-]+"
title4 = r"" + re.escape(title)
tweets = api.search(url, count=100, exclude='retweets', tweet_mode='extended', lang = 'ja', result_type='recent')
for tweet in tweets:
text = re.sub(title1, "", tweet.full_text)
text = re.sub(title2, "", text)
text = re.sub(title3, "", text)
text = re.sub(title4, "", text)
text = re.sub(r'((.*?))', "", text)
text = re.sub(r'\((.*?)\)', "", text)
text = re.sub(r'【(.*?)】', "", text)
text = re.sub(r'\[(.*?)\]', "", text)
text = re.sub(r'〔(.*?)〕', "", text)
text = re.sub(r'#\S+(\s|$)', "", text)
text = re.sub(r'#\S+(\s|$)', "", text)
text = re.sub(r'@[a-zA-Z0-9_]+さんから', "", text)
text = re.sub(r'@[a-zA-Z0-9_]+さん', "", text)
text = re.sub(r'@[a-zA-Z0-9_]+から', "", text)
text = re.sub(r'@[a-zA-Z0-9_]+より', "", text)
text = re.sub(r'|(.*)(\s|$)', "", text)
text = re.sub(r'\|(.*)(\s|$)', "", text)
text = re.sub(r'-\s(.*)(\s|$)', "", text)
text = re.sub(r'■(.*)(\s|$)', "", text)
text = re.sub(r'@[a-zA-Z0-9_]+', "", text)
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', "", text)
text = text.replace("【","").replace("】","").replace(">","").replace("/","").replace(":","").replace(":","").replace("/","").replace("|","").replace(".","").replace("“","").replace("”","")
text = text.replace("via","")
text = text.replace(site_domain_name,"")
lists = title.split(" ")
for list in lists:
text = text.replace(list,"")
text = text.lstrip()
text = text.rstrip()
comp_a = unicodedata.normalize("NFKC", text)
table = str.maketrans("", "", string.punctuation + "「」、。・!")
comp_a = comp_a.translate(table)
comp_b = unicodedata.normalize("NFKC", title)
table = str.maketrans("", "", string.punctuation + "「」、。・!")
comp_b = comp_b.translate(table)
if text != "" and len(text) > 1 and comp_a not in comp_b:
print(text)
完成したニュースアプリ
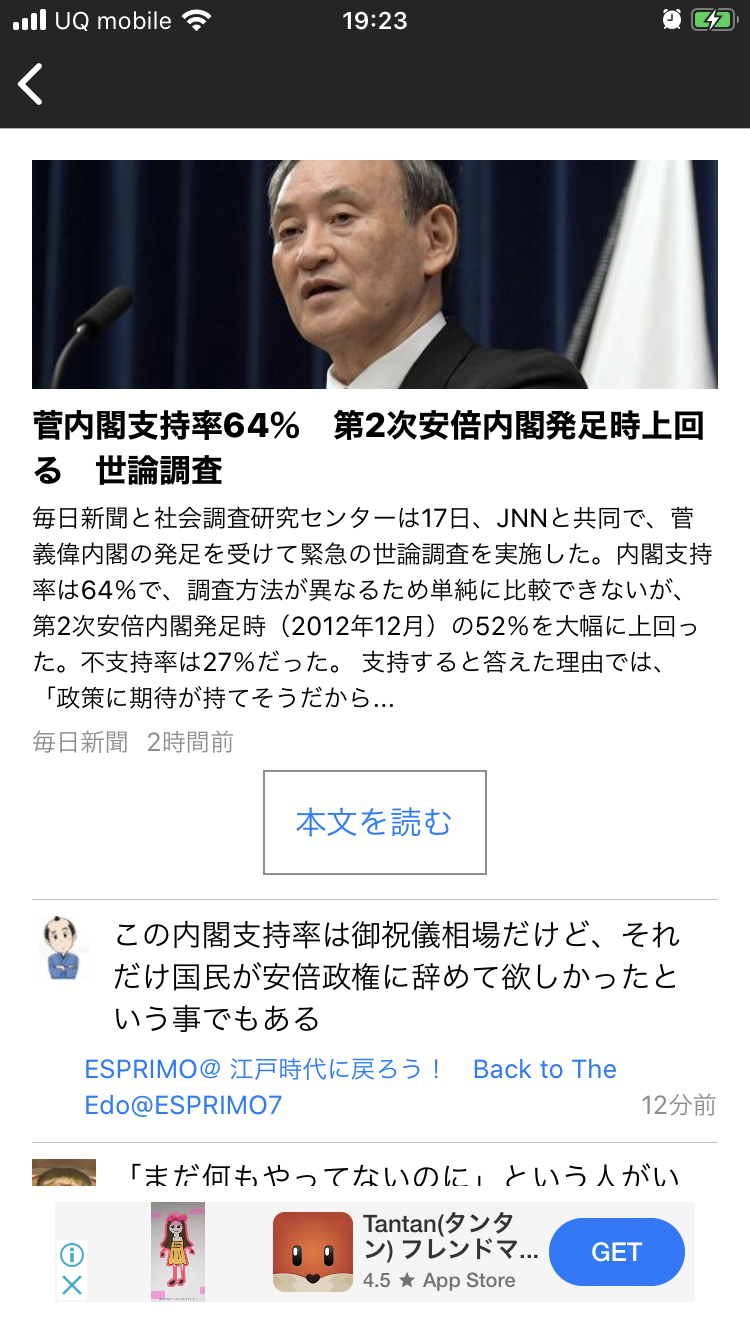
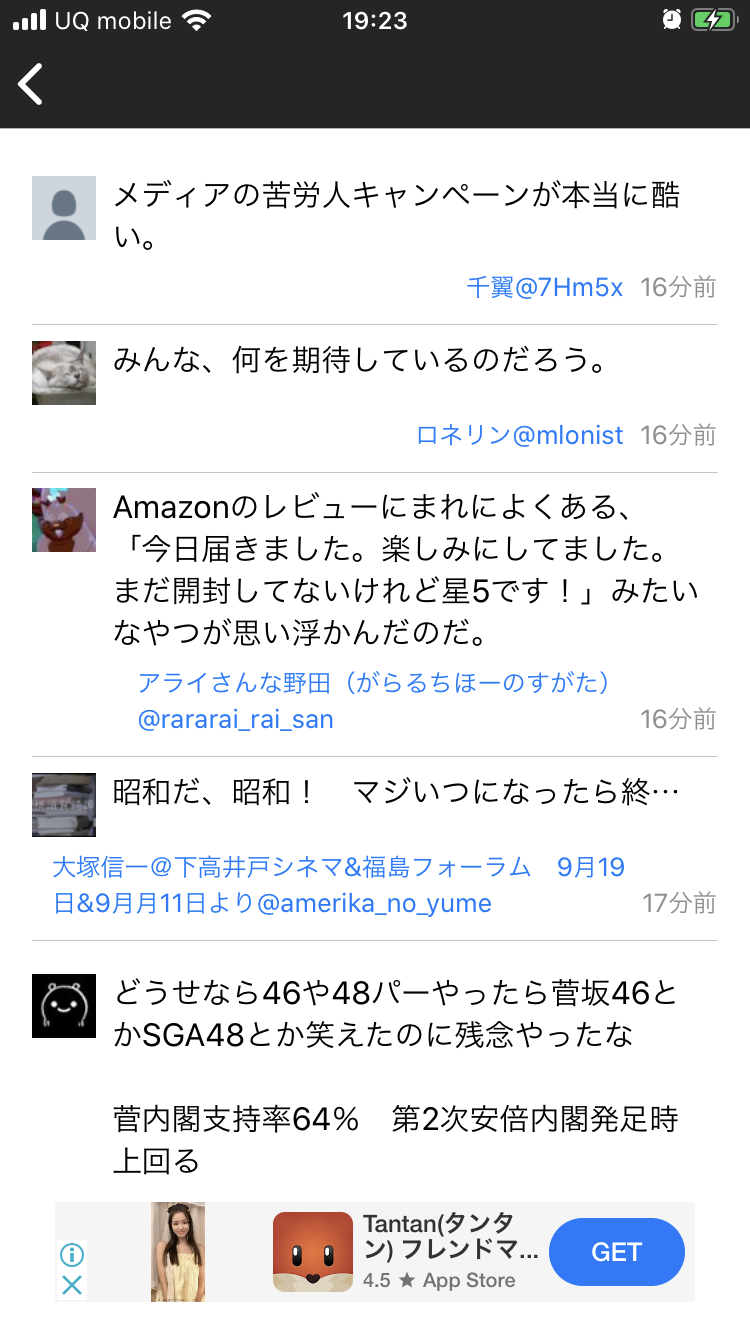
NewsTweet(ニューズツイート)
https://apps.apple.com/jp/app/newstweet-ニューズツイート/id1531315934