はじめに
機械学習をプロダクトに取り込むのはわりかし普通になってきていますが、
モバイルアプリで動かすにはちょっと敷居の高さを感じたり、負荷や機種が限定されそうだったり、大手をふってGoとはなりにくいものだと思います。
その中で今年MBaaSのFirebase内プロダクトであるFirebase MLとMLKit周りでちょっとした変化があったのもあり、
機械学習機能の組み込みがどれだけやり易くなってるのか、調べて触ってみることにしました。
機械学習というよりはMLKitの紹介と考慮すべきポイントの視点で書いてみたいと思います。
(私自身は機械学習分野には明るくありません。)
MLKitとは

MLKitとはモバイルアプリで機械学習を利用した機能を提供可能にするためのSDKというところで、Andnroid/iOSで利用できます。
今年半ばにFirebase MLからオンデバイス部分がMLKitに分離すると発表されました。
- クラウドでの推論はFirebase ML
- オンデバイス(オフライン)での推論はMLkit
として使い分けするようになるようです。
GoogleI/O 2020が中止になってなかったら、もっと何かしらアピールがあったんですかね。
説明によればMLKitは速度重視でクラウド推論の方が認識率は高いとのこと。
出来ること
簡単にいうと機械学習を用いて画像、文字からデータを抽出(推論)します。
MLKit自体には学習させる機能はないです。
Tensorflowなりで学習させたモデルを使って推論する。
(利用可能なモデルファイルはTensorflow lite形式)
- Vision: 画像からの推論
- テキスト
- バーコード
- 顔
- イメージラベリング
- オブジェクト検出
- ポーズ(Beta)
- Natural Language: 文字からの推論
- 言語
- 翻訳
- スマートリプライ
- エンティティ検出(Beta)
これらを使うことでできるアプリ機能の例でいうと、
- snowみたいな顔画像編集
- ショッピングアプリでカメラ画像による検索
- アプリ内翻訳
- メッセージへの自動返信
などなど。
使いこなせるようになれば、アプリ機能の幅が広がったり利便性向上に繋がると思います。
ここで取り扱う範囲
- MLKit(android版)
- 今回はわかりやすいものとしてVisionのオブジェクト検出を取り上げます。
- Camera(ちょっとだけ)
- Flutter(ちょっとだけ)
オブジェクト検出を行うためのコード
でも、機械学習とか難しいんでしょう。。。。?
モデル用意したり手順が複雑だったり。。。。
-
アプリのbuild.gradleにライブラリへの参照を追加
dependencies { implementation 'com.google.mlkit:object-detection:16.2.2' } -
分類機の作成
val option = ObjectDetectorOptions.Builder() .setDetectorMode(ObjectDetectorOptions.STREAM_MODE) .setExecutor(analysisExecutor) .enableMultipleObjects() // 複数のオブジェクト検出する場合 .enableClassification() // Classification(ラベル分類)する場合 .build() val objectDetector = ObjectDetection.getClient(option) -
画像内のオブジェクト検出
objectDetectoror.process(image) // 推論対象の画像を指定 .addOnSuccessListener() { results:List<DetectedObject> -> // 成功時 // results内に検出したオブジェクトの位置(Rect)なりが入っている } .addOnFailureListener { e: Exception -> // 失敗時 } -
終わり
くっそ簡単でした。ありがとうございます。
モデルを特に用意することもなく、難しい設定も入りません。
これはMLKitにGoogle謹製の素晴らしいTraining済みモデルが組み込まれているからです。
ちょっとしたものなら難しい知識はいらずにアプリに組み込めると思います。
カスタムモデルを使って動作させることも可能です。(オブジェクト検出とイメージラベリングのみ)
また、モデルをapkに含めるか、後からダウンロードするかも選べる(Android版のvisionの一部のみ)。
demo
どんなものなのか、みた方がわかりやすいので先に動画を載せます。


左はうちのもずくちゃんが何かを訴えかけているところです。
その他、家にあるものもろもをオブジェクトとして認識してくれました。
動作のポイント
- カメラからフレーム画像を取得
- フレーム画像を分類機に渡して推論
- 結果表示
表示部分に関してはMLKit公式のdemoアプリを流用させてもらいました。
https://github.com/googlesamples/mlkit/tree/master/android/vision-quickstart
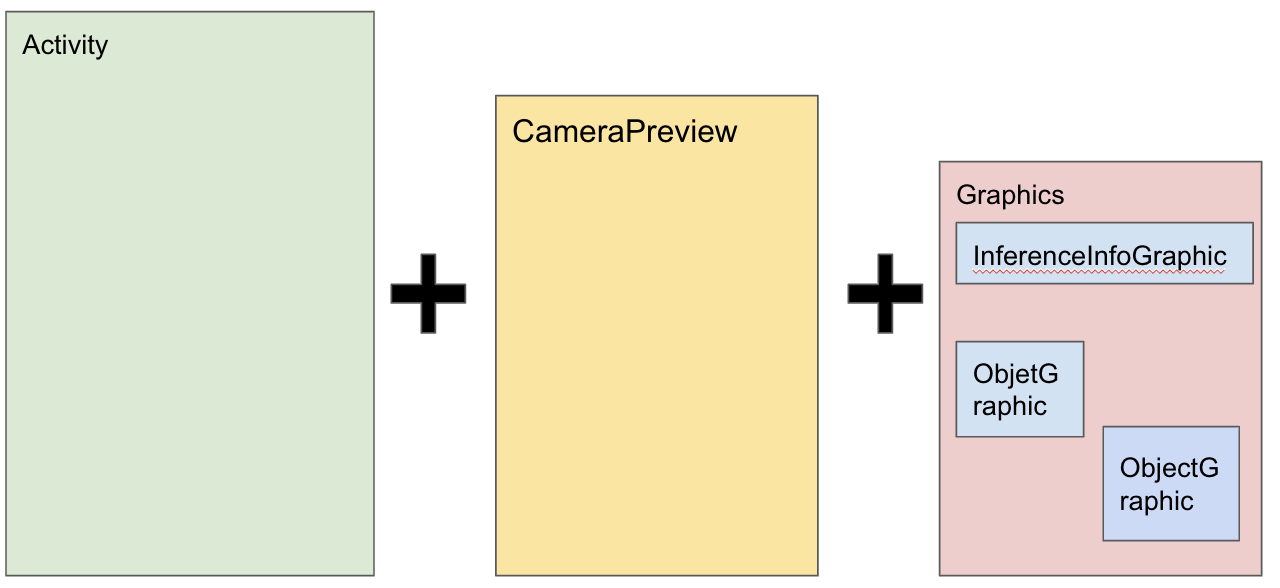
このアプリはVisionの各種分類機を詰め込んでいるところから、少し描画部分がわかりにくいところがあります。
ざっくり言うと複数レイヤを組み合わせて描画をしています。
- レイヤ1: Activity
- レイヤ2: カメラプレビュー
- レイヤ3: Graphicsレイヤ(各種情報表示Canvas)
- FPS等のテキスト(InferenceInfoGraphic)
- 検出結果
- テキスト認識なら認識したテキスト
- オブジェクト検出なら該当オブジェクト位置に短径box表示
 (フレーム画像をGraphicsレイヤで同時描画するオプションもあったりします。)
(フレーム画像をGraphicsレイヤで同時描画するオプションもあったりします。)
デモでは上の描画レイヤ構造と短径box表示の部分を流用しました。
カメラからフレーム画像を取得
CameraXのAnalysisUseCaseを使ってカメラ映像のフレームを取得します。
Camera/CameraProviderオブジェクトの生成等については省略します。
CameraX
cameraProvider?.apply {
// bind preview lifecycle
val previewUseCase = Preview.Builder().build().apply {
setSurfaceProvider(cameraPreviewView.surfaceProvider)
}
bindToLifecycle(this@CameraPreviewActivity, cameraSelector, previewUseCase)
// bind analysis lifecycle
val analysisUseCase = ImageAnalysis.Builder()
.build().apply {
setAnalyzer(analysisExecutor) { imageProxy: ImageProxy ->
// フレーム画像を分類機に食わせる
}
}
bindToLifecycle(this@CameraPreviewActivity, cameraSelector, analysisUseCase)
}
フレーム画像を分類機に渡して推論
ObjectDetector#processにてInputImageを指定します。
戻り値は最近のGoogle製AndroidSDKでよく使われるTask。
Task API
objectDetectoror.process(
// Cameraフレーム画像をMLKitへのInputモデルに変換
InputImage.fromMediaImage(imageProxy.image!!, imageProxy.imageInfo.rotationDegrees)
)
.addOnSuccessListener(analysisExecutor) { results: List<DetectedObject> ->
// 成功時
}
.addOnFailureListener { e: Exception ->
// 失敗時
}
.addOnCompleteListener {
// ImageProxyはCloseしないと次のフレームが取れない
imageProxy.close()
}
結果表示
分類が成功した場合、DetectedObjectのリストが返ってきます。
// Graphicsオーバーレイ表示レイヤをクリア、再描画
overlayLayerView.clear()
for (result in results) {
overlayLayerView.add(ObjectGraphic(overlayLayerView, result))
}
- 先述の通り、短径box表示部分は公式demoアプリのコードを流用しているため、省略します。
- 検出結果のオブジェクト座標をスクリーン座標に変換してBoxを描画しています。
動作
上の動画を参照。
コードはこちら
モバイルアプリに組み込む際に考えるべき要素
組み込み済みモデルで推論するだけならMLKitのコードは数行で済みますが、実際にアプリに組み込む場合には以下の要素を考えるべきかと。
- 機械学習モデル
- アプリに特徴を持たせるためには用途に沿ったカスタム機械学習モデルが必要。
- 組み込みモデルは汎用用途なものなので、色んなオブジェクトに反応してしまう。
- 例えばウチの猫だけに反応させたいとか、用途によって用意すべき。
- 有用なモデルを作るためにはやはり機械学習知識は必須。
- Data Augumentationなり、MobileNetとかの学習方式なり、Tensorfowなり、モデルファイル形式変換なり。(覚えたての言葉を使っています。)
- モデル生成は有識者やTensorflow Hubなどの協力を仰いだ方がよい。
- アプリに特徴を持たせるためには用途に沿ったカスタム機械学習モデルが必要。
- 負荷
- モデルやアプリの配布形態によっては処理負荷を考えるべき。
- マルチ/シングルオブジェクト検出など機能しぼり。
- 古い虚弱な端末への考慮。
- 今回はXperia XZやPixel5で試してます。
- モデルやアプリの配布形態によっては処理負荷を考えるべき。
- プレゼンテーション
- Input/Outputの可視化実装は別途必要。
- MLKit自体にはカメラの操作や、画像描画だったりの部分はノータッチ。
- 副次的に発生する結果表示(レンダリング)やカメラ/プレビューの管理の方が面倒。
- そこら辺のサポートライブラリなりがあるともっと使い勝手が良いかな。
- Input/Outputの可視化実装は別途必要。
Flutter対応

Flutterもぼちぼち人気を保っていると思うので、MLKitのFlutterライブラリの対応状況もついでに見てみました。
が、今現在(2020/12初)は公式から出ているものはなさそうです。
pubdev(Dartパッケージ管理)サイトを漁ると非公式ではあるみたい。
上の各種Detectorがそんなに複雑でもないから、お試しで自分で作ってみるのもありかも。
ちなみに、Firebase公式から出ているFlutterFireにflutter_ml_vision/flutter_ml_customライブラリが出ていますが、こちらは、Dependenciesみた限りではMLKitではなく、Firebase MLのライブラリを使っているので注意。
また、Tensorflow Liteパッケージがあるので、MLKit経由ではなくこちらを直接使ってしまうのもあり。
https://pub.dev/packages/tflite
まとめ/感想
-
今回はオブジェクト検出(ObjectDetector)を使ってみたが、Visionのテキスト認識、バーコード認識もMLKitのインターフェースはほぼ同じなので、流れそのままもほとんど同じで実装が可能。
-
モデルが組み込み済みかつ、MLKitのインターフェース自体がとても単純なのもありとても簡単。機械学習機能組み込みのきっかけによい。
-
逆を言えば単純だからこそ、あまり難しいことは出来ない。
-
感想
- こうやって扱いが簡単になってくると、組み込んでフィードバックもらいながら、その後を考えるという手順も踏めるかと思います。
- Natural Languageの方も使ってみたい。SmartReplyが面白そう。
- ちなウチの猫カスタムモデル作ろうとして間に合わなかったのは秘密な。
以上。