はじめに
自然言語処理において
・著作権
・データサイズの変動
の二つは大きな障壁ですが、和歌&俳句はほぼ固定長ですし著作権もあまりない(ただしデータベースの入力者には著作権が発生しうるので注意が必要)ため題材として扱いやすいのではないかと考え、句切れを見つけるプログラム作りに挑戦しました
(GitHub)
https://github.com/atuko315/program-to-divide-31-syllable-Japanese-poem./blob/main/README.md
実際にやったこと
とりあえず分かち書きするためにmecabと中古和文Unidic辞書を使いました。
from time import perf_counter_ns
import MeCab
import unidic
tagger = MeCab.Tagger('-d /content/drive/MyDrive/natural/20_chuko/ ') # 古文用辞書に変更
自分のディレクトリ(ここではgoogle colabのnaturalというフォルダに使うデータをまとめています)に辞書(https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chj)
を前もってダウンロードしておき、上記のようなコードで呼び出します。
そしてこのように歌を入れれば
sample_txt ="心あてに折らばや折らむ初霜のおきまどはせる白菊の花"
print(tagger.parse(sample_txt))
このように豊富な解析結果がでてきます。
心あて 名詞,普通名詞,一般,*,*,*,ココロアテ,心当て,心あて,ココロアテ,ココロアテ,和,心あて,ココロアテ,ココロアテ,ココロアテ,*,*,*,*,*,*,"0,5",C2,*,14867330043617792,54087
に 助詞,格助詞,*,*,*,*,ニ,に,に,ニ,ニ,和,に,ニ,ニ,ニ,*,*,*,*,*,*,*,名詞%F1,*,7745518285496832,28178
折ら 動詞,一般,*,*,文語四段-ラ行,未然形-一般,オル,折る,折ら,オラ,オラ,和,折る,オル,オル,オル,*,*,*,*,*,*,1,C1,*,1473637672690241,5361
ば 助詞,接続助詞,*,*,*,*,バ,ば,ば,バ,バ,和,ば,バ,バ,バ,*,*,*,*,*,*,*,"動詞%F2@0,形容詞%F2@-1",*,8384609419141632,30503
や 助詞,係助詞,*,*,*,*,ヤ,や,や,ヤ,ヤ,和,や,ヤ,ヤ,ヤ,*,*,*,*,*,*,*,*,*,26109836370518528,94987
折ら 動詞,一般,*,*,文語四段-ラ行,未然形-一般,オル,折る,折ら,オラ,オラ,和,折る,オル,オル,オル,*,*,*,*,*,*,1,C1,*,1473637672690241,5361
む 助動詞,*,*,*,文語助動詞-ム,連体形-一般,ム,む,む,ム,ム,和,む,ム,ム,ム,*,*,*,*,*,*,*,動詞%F4@0,*,10165818256138945,36983
初霜 名詞,普通名詞,一般,*,*,*,ハツシモ,初霜,初霜,ハツシモ,ハツシモ,和,初霜,ハツシモ,ハツシモ,ハツシモ,*,*,*,*,*,*,0,C2,*,53629512902124032,195103
の 助詞,格助詞,*,*,*,*,ノ,の,の,ノ,ノ,和,の,ノ,ノ,ノ,*,*,*,*,*,*,*,名詞%F1,*,7968444268028416,28989
置き惑わせ 動詞,一般,*,*,文語四段-サ行,命令形,オキマドワス,置き惑わす,置き惑わせ,オキマドワセ,オキマドワセ,和,置き惑わす,オキマドワス,オキマドワス,オキマドワス,*,*,*,*,*,*,5,C1,*,67697764213072673,246283
る 助動詞,*,*,*,文語助動詞-リ,連体形-一般,リ,り,る,ル,ル,和,り,リ,リ,リ,*,*,*,*,*,*,*,動詞%F4@0,*,10958016383951553,39865
白菊 名詞,普通名詞,一般,*,*,*,シラギク,白菊,白菊,シラギク,シラギク,混,白菊,シラギク,シラギク,シラギク,*,*,*,*,*,*,2,C1,*,4701795221905920,17105
の 助詞,格助詞,*,*,*,*,ノ,の,の,ノ,ノ,和,の,ノ,ノ,ノ,*,*,*,*,*,*,*,名詞%F1,*,7968444268028416,28989
花 名詞,普通名詞,一般,*,*,*,ハナ,花,花,ハナ,ハナ,和,花,ハナ,ハナ,ハナ,ハ濁,基本形,*,*,*,*,2,C3,*,8235900471484928,29962
EOS
このデータを用いてまずは57577に分けようとしたのですが、しかし
①百人一首との戦い
上の結果から読み仮名を取り出す
⇒5音もしくは7音のときに品詞が切れてたらそこで切る
⇒切れない場合は近いほうで
# 上のリンクで言うとこの辺
def loose_div(self, i):
# 句切れ分けの制約がすくないバージョン
letter = 0
while(letter < self.joint[len(self.divided)-1]):
letter += len(self.yomi[i])
if(letter == self.joint[len(self.divided)-1]):# 57577の区切れと単語の区切れが一致した際はそこで分ける
return i
elif(letter > self.joint[len(self.divided)-1]):# 7577の区切れと単語の区切れが一致せず、それより字数が多くなってしまった場合は字数が近い方で分ける
if((letter - self.joint[len(self.divided)-1]>=
self.joint[len(self.divided)-1] - (letter-len(self.yomi[i])))):
return i-1
else:
return i
i+=1
こんなものかな…と思ったのですが
大江/山、手向/山のように単語を途中で分けてしまったり
意外と字余り、字足らずが多かったりで制度は7割ほどとなりました
そんなわけで二つの名詞が連続した際はもとは一つの単語であったとし、「て」や「と」など各句がそこでは終わらなさそうな語の時は次の単語を見るルールを追加しました。
# この辺
self.not_start = ["助詞","助動詞","み 接尾辞"]# 句が始まらない語
# 瀬をはやみ、風をいたみ用の"み 接尾辞"
def divide(self, i):
letter = 0 # 何文字目かを示す
while(letter < self.joint[len(self.divided)-1]):
letter += len(self.yomi[i])
if(letter == self.joint[len(self.divided)-1]):
# 57577の区切れと単語の区切れが一致した際も次の単語がnoneselfである場合は今の句に含む
flag = find5.judge_joint(self, i+1)
if(flag == 0):
return i
else:
while(flag == 1):
i += 1
flag = find5.judge_joint(self, i+1)# not_startに含まれない語の直前まで進む
return i
elif(letter>self.joint[len(self.divided)-1]):# 57577の区切れと単語の区切れが一致せず、それより字数が多くなってしまった場合
if(find5.judge_joint(self, i) == 1):# 今注目している要素はnot_start、not_startに含まれない語の直前まで進む
flag = find5.judge_joint(self, i+1)
while(flag == 1):
i += 1
flag=find5.judge_joint(self, i+1)
return i
else: # not_start+not_startまたはそれ以外+それ以外
if("名詞" in self.mecab_result[i-1][0]
and "名詞" in self.mecab_result[i][0]):# 両方とも名詞のときはもとは一つの名詞であると判断
return i
elif(find5.judge_joint(self, i+1) == 1 or
(letter-self.joint[len(self.divided)-1] >=
self.joint[len(self.divided)-1] - (letter-len(self.yomi[i])))):# 次がnot_start内の単語なら前の方を取る。次もそれ以外なら音数が近い方で判断
return i-1
else:
return i
i += 1
精度は0.96に
さあ、この厳しい判定を勝ち抜いた4組のファイナリストの登場です
1.筑波嶺の 峰より落つる 男女川 恋ぞつもりて 淵となりぬる
(原因:男女川を「みなのがわ」と読めない )
2.玉の緒よ 絶えなば絶えね ながらへば 忍ぶることの よわりもぞする
(原因:「寝ながら」と判断される、睡眠をとればストレスが軽減し忍ぶ力はむしろ強くなりそうですが…)
3.わが袖は 潮干に見えぬ 沖の石の 人こそ知らね かわく間もなし
(原因:「知らねか」という謎の呼びかけ)
この三つはmecabの精度や語彙に起因するものではあり不可避的ですが次が曲者です。
(辞書に歌枕を追加すると楽しそうなのでいつかやりたいです)
4. 今はただ 思ひ絶えなむ とばかりを 人づてならで 言ふよしもがな
この歌が完全なコーナーケースとなっており、
「思ひ絶えなむ」が七音で一見きれいに切れそうなのですが「と」(助詞)で終わらないルールのせいで二句目が「思ひ絶えなむとばかり」になってしまいます。
たったの100首で詰むとは想定しておらず、思わず筆者も思ひ絶えかけましたが苦肉の策として四句以下にしか分けられていないときは最も長い句を二つに分けることでこのような「句またがり」に対抗することとしました
# この辺
def warning(self):
prev = 7
current = len(self.divided)
# 終了後5句に分けられていない場合、最も長い「句」を二つにくぎる
while(current < 6 and -2 not in self.divided):
# 二か所以上で区分できていない可能性を考慮
# もっとも長い句を二つに分けることを繰り返す
prev = len(self.divided)
self.divided = find5.modify_div(self)
current = len(self.divided)
self.complete = find5.output_complete(self)
if(-2 in self.divided):
print("句またがりが", str(find5.longest_div()+1),
"句目で起きていると考えられます")
if(len(self.complete) < 25):
print("俳句を入力していませんか?")
print(self.change_to_yomi())
結果として対百人一首での精度は0.97となりましたが
古今和歌集、新古今和歌集ではどうなったかというと...
前半結果発表
古今和歌集 0.746
新古今和歌集 0.740
..なんとも言えない結果です。
原因としては今回古今和歌集、新古今和歌集は全てひらがなのデータを使用したため「はな」や「やま」の誤認例が多いことが挙げられます。
②句切れを見つける
気を取り直していきましょう。
先ほどの57577と異なり、歌全体でどこを句切りとするかには様々な流儀があり、単一の正解がありません。
ここでは文法上の切れ目を基準として判断することにしました。
1.「終止形」「命令形」「已然形」の単語で終わる句
2.「係助詞」
3.疑問、禁止、詠嘆、感動等を表す終助詞
で終わる句のうち最初に現れるものの後を句切れとしました。
# この辺
class find1(find5):
def __init__(self,result): # コンストラクタと呼ばれる
super().__init__(result);
self.point = 0
self.stop = ["終止", "命令", "已然"]
self.kakari = ["ぞ", "なむ", "や", "か", "こそ"]
self.edge = ["な 助詞", "か 助詞", "かな 助詞", "かも 助詞", "かし 助詞", "ぞ 助詞", "よ 助詞", "ものを 助詞", "もや 助詞", "もよ 助詞", "やし 助詞", "ろ 助詞", "ゑ 助詞"]
self.candidate = []# 句切れになりそうなもの
def find_end(self):# ①
for i in range(1, 5):
for s in self.stop:
if(s in self.mecab_result[self.answer_divided[i]][5]):
self.candidate.append(i)
def find_kakari(self):# ②
flag_r = 0# 連体形
flag_e = 0# 已然形
for i in range(len(self.mecab_result) - 2):
for s in self.kakari:
if(s in self.mecab_result[i][0]):
if(s == "こそ"):
flag_e = 1
else:
flag_r = 1
if(flag_r == 1):
if("連体" in self.mecab_result[i][5]):
flag_r = 0
if(i in self.answer_divided):
self.candidate.append(self.answer_divided.index(i))
if(flag_e==1):
if("已然" in self.mecab_result[i][5]):
flag_e=0
if(i in self.answer_divided):
self.candidate.append(self.answer_divided.index(i))
def find_edge(self): # ③
for i in range(1, 5):
for s in self.edge:
if(s in self.mecab_result[self.answer_divided[i]][0]):
self.candidate.append(i)
def find_standard(self):
find1.find_kakari(self)
find1.find_edge(self)
find1.find_end(self)
self.candidate = sorted(set(self.candidate))
self.candidate = list(self.candidate)# 重複要素の削除
if(self.candidate == []):
self.point = 5
else:
self.point = self.candidate[0]
結果は...
②結果発表(人力との比較)
人力データは『紙宏行「新古今における三句切れの表現構造」(研究紀要 vol.29、1985)』
より
古今和歌集
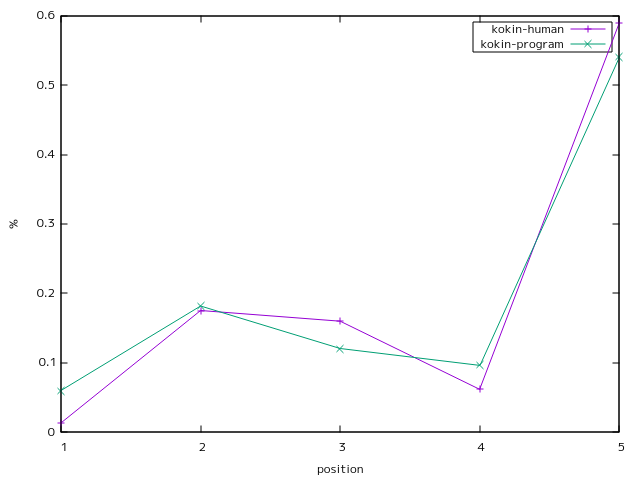
相関係数0.99
新古今和歌集
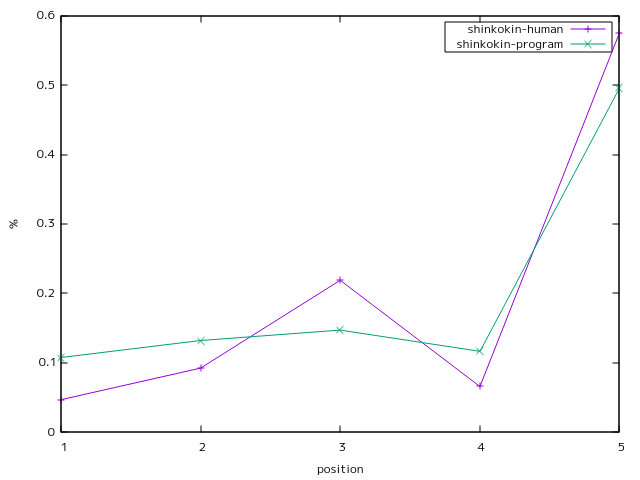
相関係数0.97
*プログラム同士の古今和歌集、新古今和歌集の比較
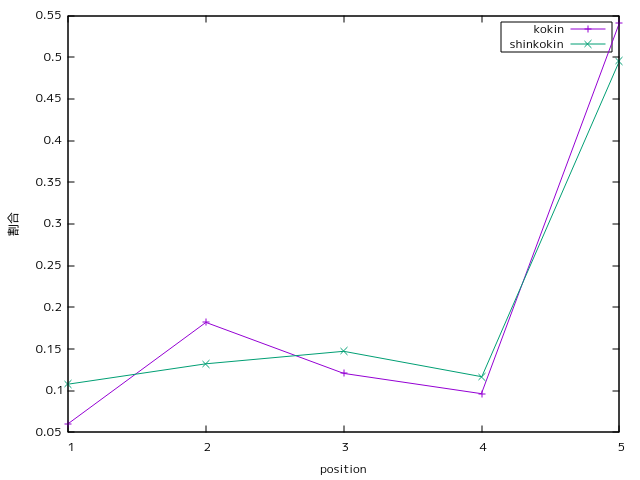
通説通り時代が下ると初句切れ、三句切れが増加しております!!!
(ただし4句切れも増加している。
作品中に句切れを入れる傾向自体が強まっているとも解釈可能)
まとめ
簡易的なものではありますが、和歌を57577に分けるプログラムと句切れを見つけるプログラムを実装できました。
特に後者については人力による評価と高い相関を見せ、他の歌集にも利用なので、今後も改善を重ねたいです。