1. 概要
Hiho氏のブログ・ニコニコ動画で紹介されている「ディープラーニングの力で結月ゆかりの声になってみた」を高音質化するために工夫したことを紹介します。
音声処理自体は専門外なので、『常識』のお話かもしれません。
音質の評価も主観によるものです。
紹介する手法は第1段目の変換(自声->ゆかり変換)に対してのもののみです。
2. どの程度まで高音質化できたの?
まず、第1段でどの程度の上手く変換できたのかを示します。
これより上手く変換できた方、情報ください!!
注: 第2段に使っている学習データは違うものを使っていますが、聴き比べても誤差程度でした。ちなみに筆者が使用している第2段の学習データは下記のものになります。
他の高音質化についての参考記事
音声ダウンロード & 再生方法
音声ファイルをクリックすると github のページに移動しますので、下記画像のように、ダウンロードボタンを押して、wavを取得してください。
また、再生には vlc を使用してください。どうやら、Windows標準のメディアプレーヤーでは、対応できないフォーマットのようです。
参考学習データ(第2段階)
利用規約に抵触する可能性があるので削除しました
音声: 柚月ゆかり
サンプリング:22050Hz
https://github.com/YoshikazuOota/become-yukarin_rt/blob/master/dat/model/yukari_2nd_22050/predictor_255000.npz
サンプル1 音声データ:500ペア、自声・ゆかりのf0推定法: harvest
4.1だけを行い、あとはほとんどデフォルトで実行。
ノイズ感があり、音声もこもった感じ。
第1段(predictor_120000.npz)
output/yukari_1st_w500_120k/test01.wav
第1段 + 第2段
output/myscript_05_25_1/test01.wav
サンプル2 音声データ:660ペア、自声・ゆかりのf0推定法: dio
4.1, 4.2, 4.3を行った。
ノイズ感、音質がよくなったが今一歩な感がある。
また、語尾にノイズが交じるのは最期までなくすことができませんでした。
第1段(predictor_445000.npz)
output/yukari_1st_w550_f0c1_250_cut430_mdio_ydio_445k/test01.wav
第1段 + 第2段
output/myscript_06_01_1/test01.wav
サンプル3 音声データ:825ペア、自声・ゆかりのf0推定法: dio
サンプル2に 音声でデータを追加して音質向上を試みた。
しかし、音質はほぼ変わらず。
第1段(predictor_200000.npz)
output/yukari_1st_w825_f0c1_250_cut430_mdio_ydio_200k_/test01.wav
第1段 + 第2段
output/myscript_06_04_1/test01.wav
サンブル4 音声データ:139ペア、自声・ゆかりのf0推定法: dio
この手法は精度が安定しないケースが多かったため、非推奨といたします
4.1〜4.3、5.1を行った。
サンプル3で使用した 825ペアのデータを212ほどまで絞り込んだ。
サンプル2,3と同等の品質でデータを212まで減らすことができた。
第1段(predictor_130000.npz)
output/yukari_1st_w825_f0c1_250_cut430_mdio_ydio_select212_130k/test01.wav
第1段 + 第2段
output/myscript_06_20_1/test01.wav
3. 精度向上のための戦略
基本周波数の定義より、『同じ文章を同様に発音した場合、自声とゆかり音声の基本周波数(f0)の波形も同様になる(波高は違っても)』と考え、第1段階の音声データペアのf0検出精度をより一致させる工夫をしました。
逆説的に言うと、f0が自声とゆかり音声で同様の水準で推定できなければ、スペクトル包絡の推定値も比較対象にならないのではないかと思ったためです。
この仮定のもといくつかの工夫をしたところ、音質が改善されました。
以下で、実際に行った工夫(戦術)を紹介します
*補足: 音声特徴量 1
第1段の音声特徴量に基づく音声変換は、音声は下記の3つに別けられると言う理論に基づいています。
乱暴に説明すると下記の3つの成分に別けられます
- 基本周波数(f0): ベースとなる声の高さ。声の基本的な高さ(発音中は値を持ち、値は声の高さに応じて高くなる)
- スペクトル包絡: その人の声の特徴を表します。ゆかりっぽい声の情報の殆どはこのデータになります。
- 非周期性指標: ゆらぎ・雑音を表します。この成分が無いと機械的な声になります。
4. 音質向上の戦術
4.1 自声の収録をゆかり音声にできるだけ近づける
自声のf0とゆかり音声のf0をより一致させるため、発音タイミングなどをより近づけるようにしました。
また、音響特徴量切り出し工程(前記事参照)では、地声とゆかり音声の発音タイミングのゆらぎを調整する処理がありますが、この処理精度が高くなれば音質向上も望めると思いました。
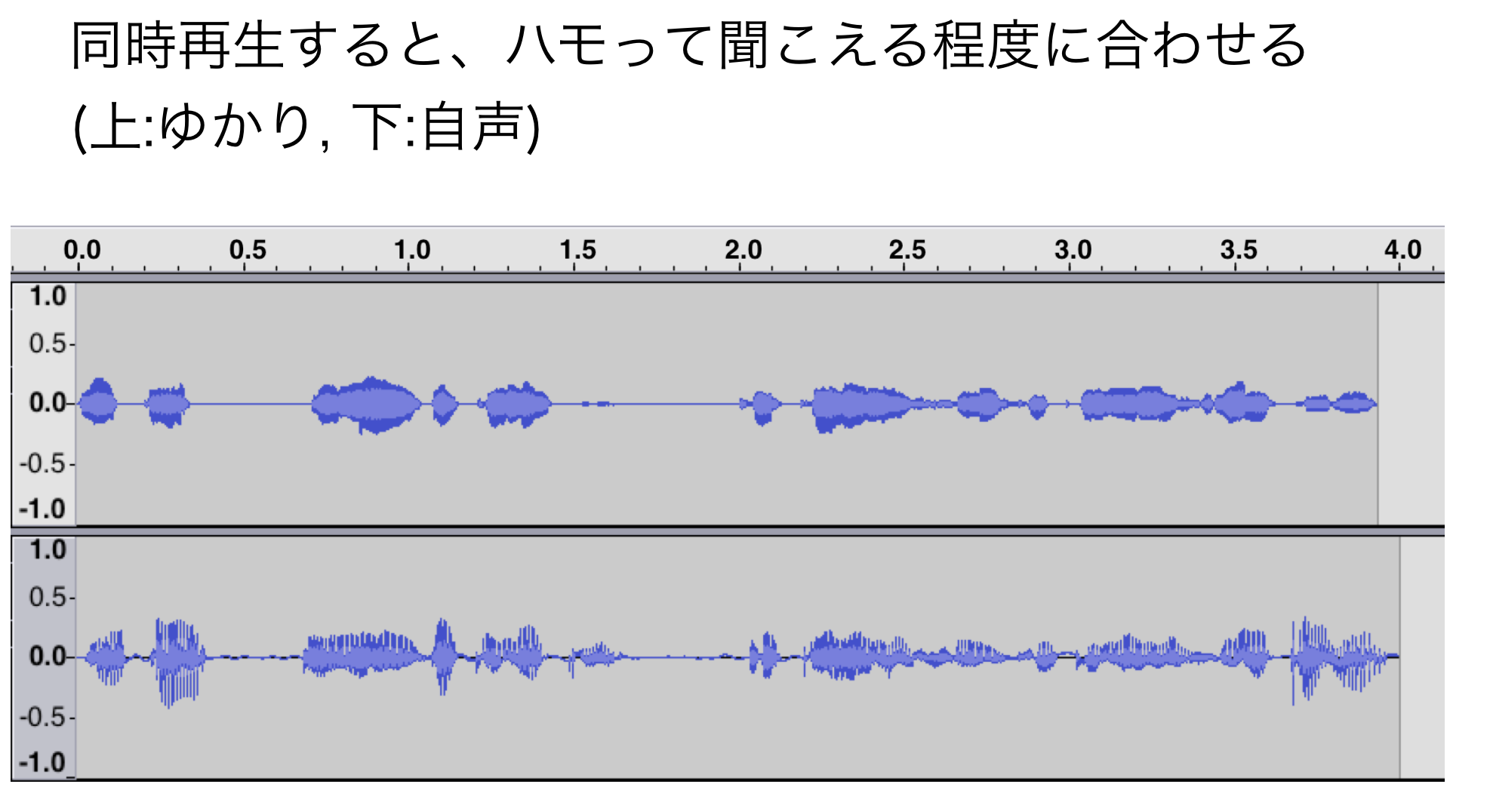
評価
音質向上は多少あるが、収録の手間がかかる。
ただ、以下の手法を適用する際に比較検討しやすくなるメリットがあります。
4.2 基本波形(f0)の検出しきい値の変更
自声のf0推定のしきい値を変えることで、ゆかり音声のf0波形に近づけることができます。
自声は低いためか、f0の推定値がゆかり音声が大きく異なる場合が多くありましたが、このような場合、有効なようです。
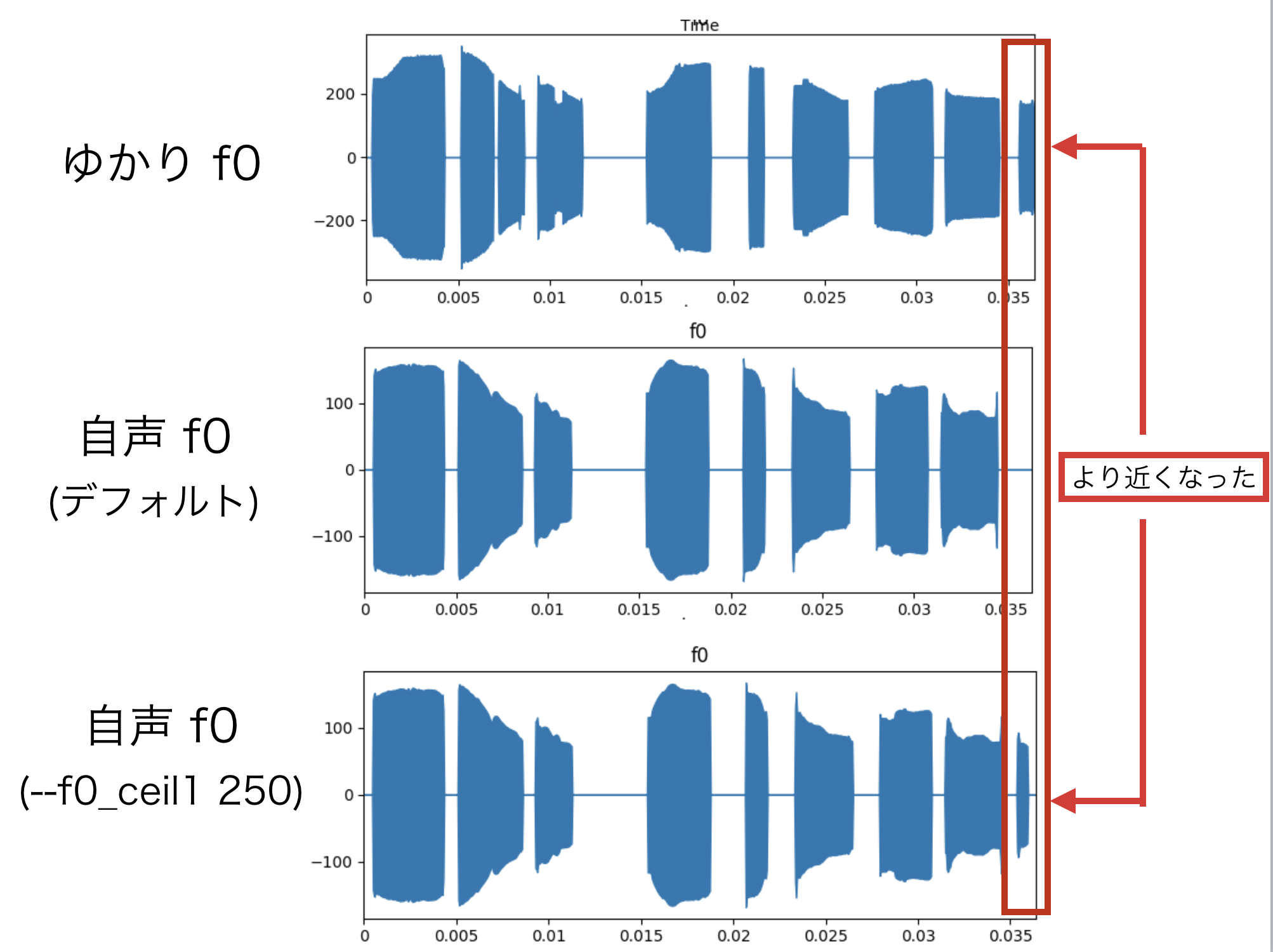
評価
こもったような声が、少し通るようになりました。
やり方
音響特徴量切り出しをする(前記事参照)際に、追加でオプションを付けることで指定できる
オプション(単位や目安の付け方などはわかりませんでした *2)
- f0_floor1 : 自声のf0を推定する処理の上限閾値(デフォルト 71)
- f0_ceil1 : 自声のf0を推定する処理の下限閾値(デフォルト 800)
- f0_floor2 : ゆかり音声のf0を推定する処理の上限閾値(デフォルト 71)
- f0_ceil2 : ゆかり音声のf0を推定する処理の下限閾値(デフォルト 800)
自分は男性で声も低いほうなので、f0_floor1 だけを 250ほどにしました。
(4つともいろいろな値を試してみましたが、f0_floor1を変更するだけに落ち着きました)
該当オプション指定例
--f0_floor1 61 --f0_ceil1 230 --f0_floor2 400 --f0_ceil2 2200
フルコマンド例(必須オプション + 該当オプション指定例)
python scripts/extract_acoustic_feature.py -i1 dat/in_myVoice -i2 dat/in_yukariVoice -o1 dat/out_myVoice -o2 dat/out_yukariVoice --f0_floor1 61 --f0_ceil1 230 --f0_floor2 400 --f0_ceil2 2200
4.3 ゆかり基本波形の検出アルゴリズムを dio に変更
音響特徴量の推定手法を dioにすることで、ゆかり音声のf0計算ノイズを排除できた。このf0計算ノイズ(スパイク)は「Voiceroid+ Ex 結月ゆかり」固有の現象だと思うが、同様の現象があれば参考にしてください。
結月ゆかり+ Ex の音響特徴量の推定を harvest(worldデフォルト)で行った場合、図のようなスパイクが発生する場合が散見された。*3
このスパイクはゆかり音声の合成アルゴリズムとharvestアルゴリズムの相性が悪いためと考え、もう一つの dioでf0を推定したところ、スパイクはほぼなくなった。
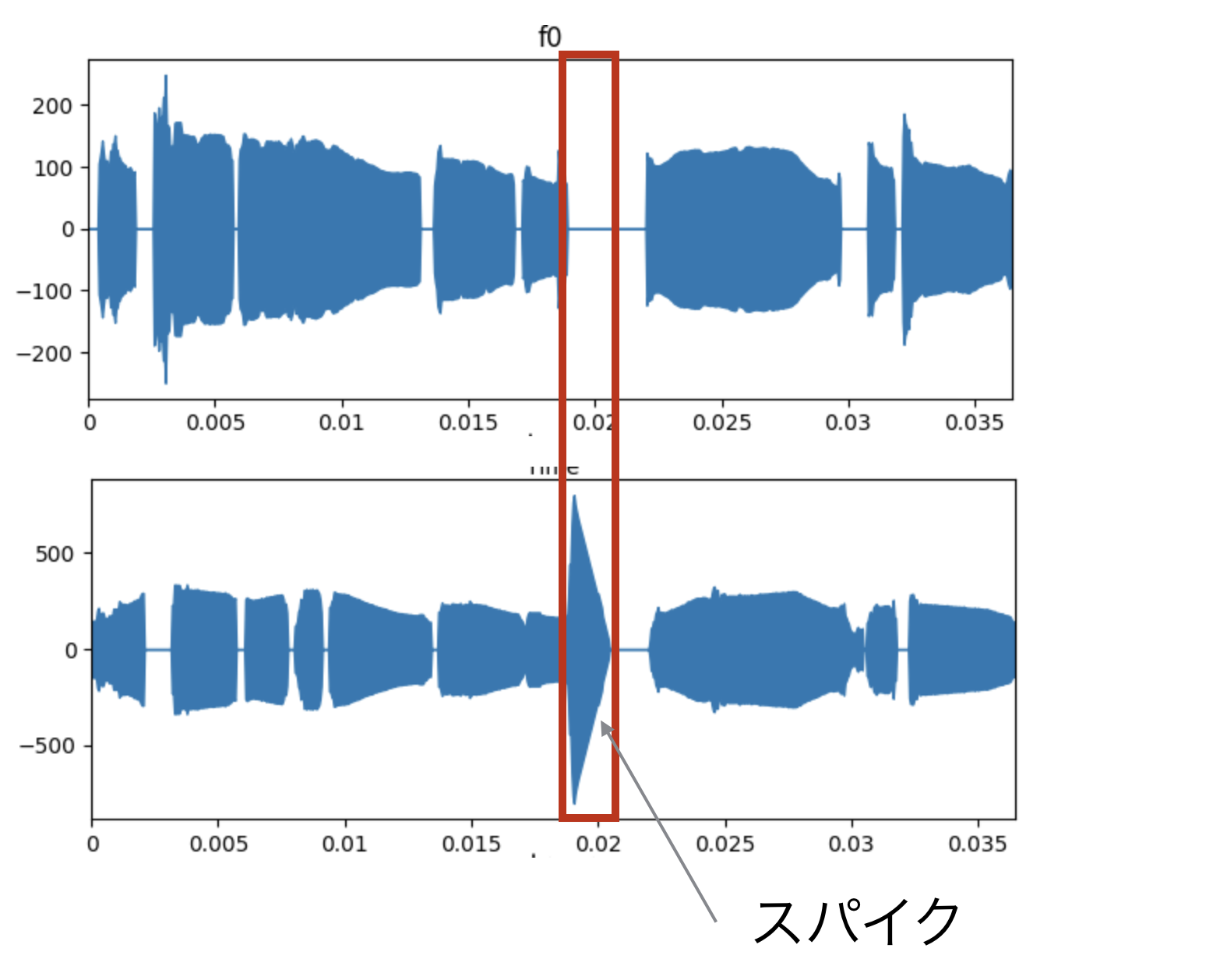
補足
world の f0 推定アルゴリズムは 'harvest'と'dio'の 2種類があります。
下記のツイートであるように、2015年時点では、'StoneMask' という補正処理を使った場合、'dio' の方が精度が良いようです。
現時点でも'dio'の方が優位性があるのかは不明ですが、試す価値はあると思います。
評価
ノイズ感が減った。
やり方
音響特徴量切り出しをする(前記事参照)を実行する前に、become_yukarin/param.py の下記部分を書き換える。
この場合は、自声のf0推定方法も同じく変更されます。
f0_estimating_method: str = 'dio' # dio / harvest
補足
dioはharvestに比べてノイズに弱いとされています。ゆかり音声ならばノイズの問題は無いですが、自声についてはお気をつけください。
自声とゆかり音声でそれぞれ別手法をしたい場合はソースを修正するしか無いようです。
私が試した限りでは、自声・ゆかり音声ともにdioにした場合が一番音質が良かったです。
5. 試したけどあまり効果がなかった
5.1 学習データを目視チェックして、一致度が低いデータを省く
自声とゆかり音声のf0をプロットして、一致度が低いデータを間引くことで学習精度を向上させることを狙った。
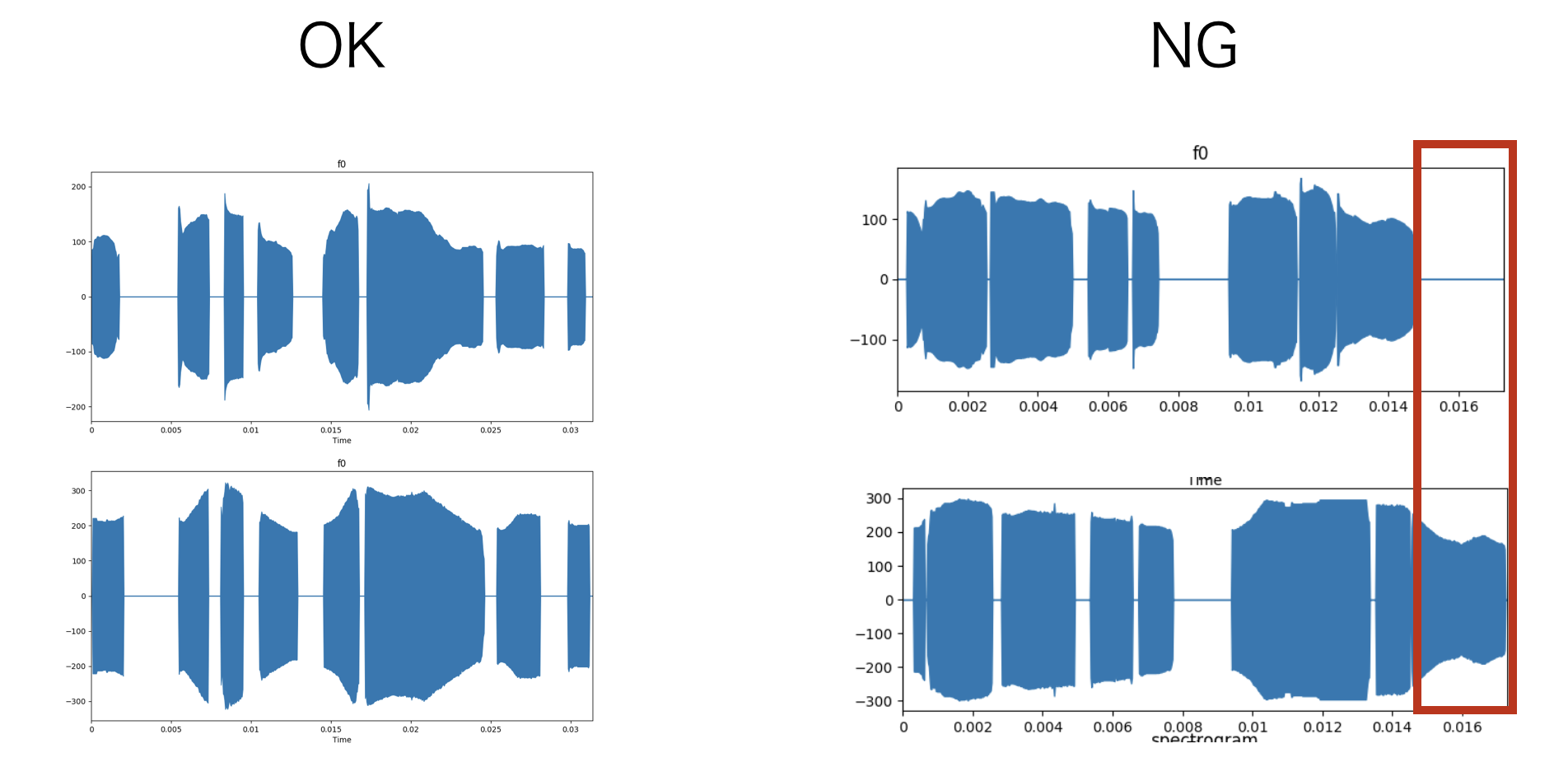
評価
わずかにノイズが減る場合があったので、効果が全くないわけではないと思われう。
しかし、機械学習のメリットを相殺するような方法で、労力もかかるため、最後の手段的な位置付けだと思う。
やり方
scripts/extract_acoustic_feature.py をソース修正して各種データプロットするようにして、目視判断する。
音声の各種データをプロット方法はプログラム修正はこちらのレポジトリを参考にしてください。
scripts/extract_acoustic_feature.py
また、下記のコマンドで matplotlib、librosa を追加してください
pip install matplotlib
pip install librosa
さらに、プロットデータを格納するディレクトリの追加も必要です。
使用する場合は自声の指定ディレクトリ名に"_ajst_plot"を書き加えたディレクトリを作成してください。
例えば オプションを -o1 dat/out_1st_my_npy とした場合は、「dat/out_1st_my_npy_ajst_plot」を作ればOKです。
注意: ajst は adjust を打ち間違え。お恥ずかしい...
2019/03/17 追記
プロットデータに追加して、プロットしている音声wavも出力するように修正しました。
[ファイル名]_my.wav : 話者の音声
[ファイル名]_yuka.wav : ターゲット音声
6. まとめ
自声とゆかり音声のf0推定値を揃えることで、音質が改善できることがわかった。
また、サンプル4にあるように学習に適した音声データが200程度あれば、800ペアの音声変換と同等の精度になった。適切な音声データペアが作れれば、収録する音声データはより少なくできる可能性がある。
もしかすると、中間層は減らしたほうが良いのかもしれない。
脚注
*1: この記事が参考になります(https://qiita.com/ohtaman/items/84426cee09c2ba4abc22)
*2: worldのオプションを調べればわかるかと思います。
*3: 余談ですが、world開発者様のTwitterを見る限り、dio/harvestの命名はジョジョをリスペクトしたものと思われます。