はじめに
在庫を予測、分析し、”見える化”するSaaSサービスを提供しているフルカイテンでは、Redshiftを使用してデータ分析基盤を構築しています。当初はアカウント数やデータ量が少なかったので正常に稼働していましたが、アカウント数やデータ量が増えるにつれて、バッチ処理に掛かる時間が長くなり、速度の改善が必要になりました。
マルチテナント構成による大規模顧客の影響
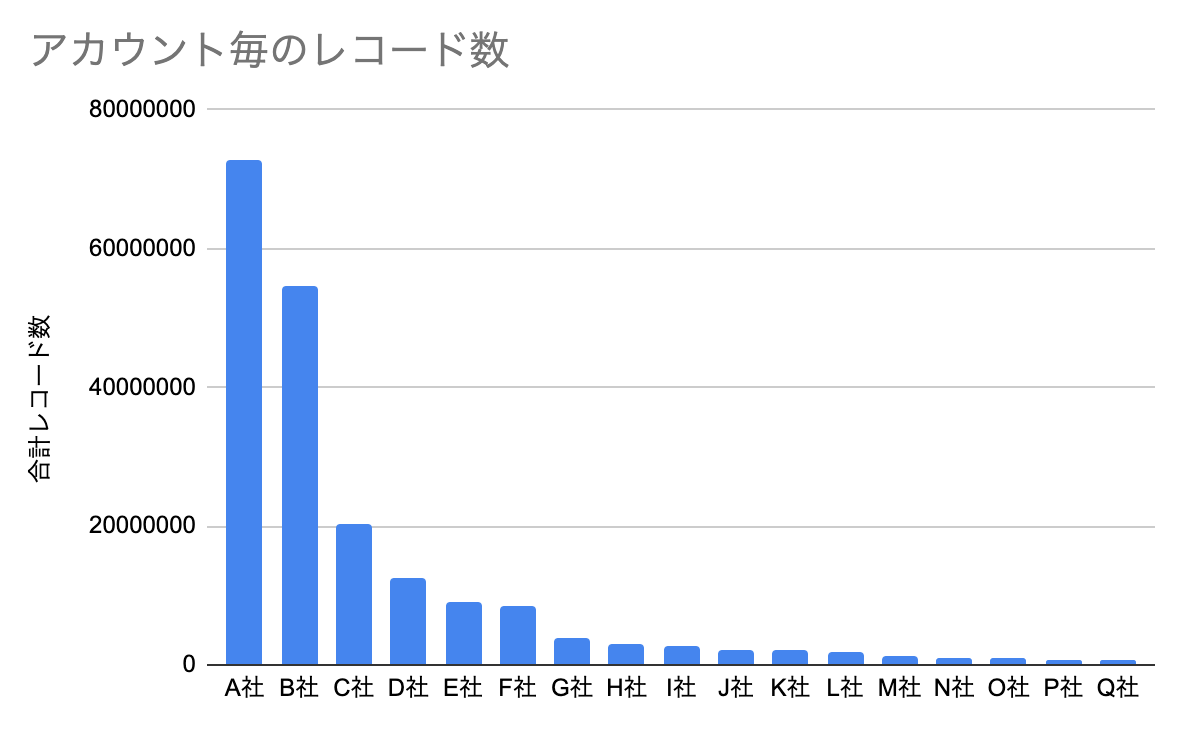
データ量が大きいアカウントが増え、他のアカウントの処理に影響を与えてしまうビックデータ特有の問題が発生していました。下記のグラフはアカウント毎のデータ量を一部抜粋したものです。大きいアカウントと小さいアカウントの間には100倍近くデータ量に違いがあります。当社のRedshiftは、同一クラスター内に複数のアカウントが同居するマルチテナント構成になっているため、データ量が大きいアカウントの処理の重さによって、データ量の小さいアカウントの処理に時間がかかっていました。
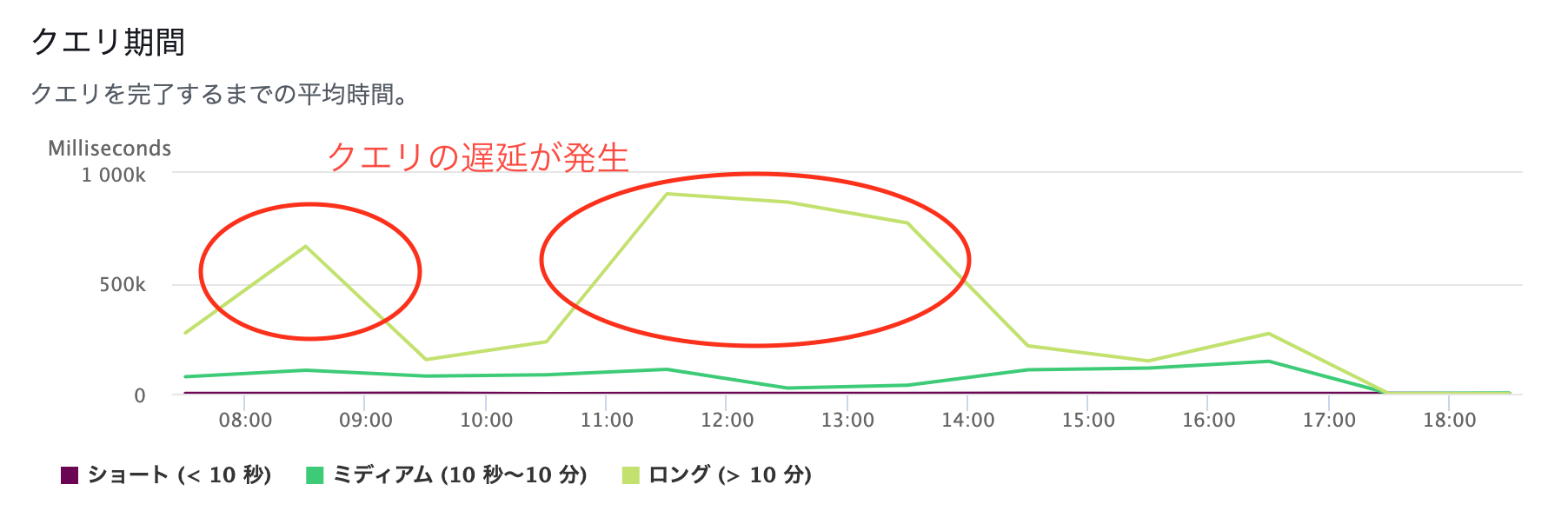
バッチ処理の集中によるクエリの遅延
アカウントから送信されるデータは、大半が早朝に連携されています。このため、バッチ処理の起動処理が午前中に集中し、Redshiftのクエリに遅延が発生していました。
Redshiftには、Concurrency Scalingという、負荷に応じて自動的にノード数を増減できる機能がありますが、以下の理由から、PySpark on Glueへ移行しました。
PySpark on Glueへの移行理由
- サーバレスのGlueを使うことで他のアカウントの影響を受けることなく、並列処理が実行可能
- アカウント毎にワーカー数を指定することで、インフラコストの最適化が可能
- たとえユーザーが急増しても、インフラを気にすることなくスケールすることが可能
- 集計処理で多数の中間テーブルを生成する際に、書き込みが必要なRedshiftより、メモリ上で集計するPySparkの方が処理速度が早い
PySpark on Glueを効率的に使用する3つのポイント
1. ワーカー数の適正化
ワーカー数をアカウント毎に指定するようにします。
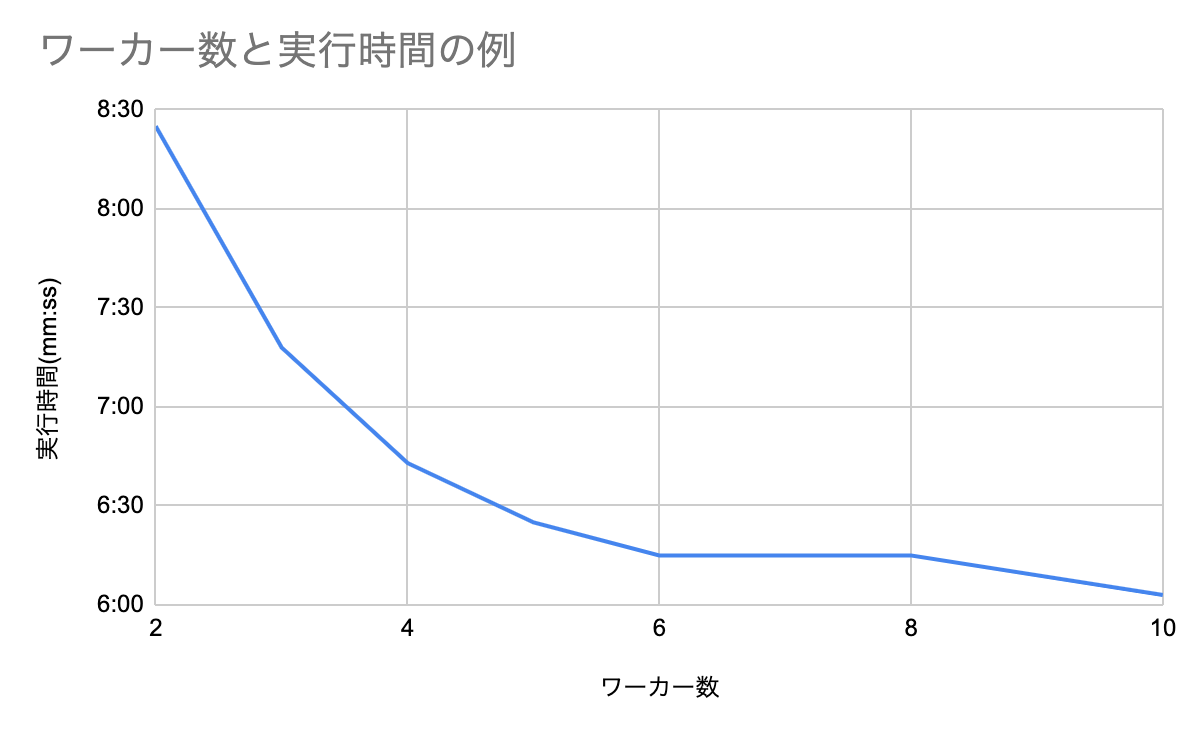
下記のグラフのようにワーカー数を増やせばGlueの実行時間は短くなりますが、ワーカー数の増加に比例して実行時間が短縮されるわけではありません。ワーカー数が多すぎるとタスクを実行していないexecutorが発生します。
Glueのメトリックス(Job Execution: Active Executors, Completed Stages & Maximum Needed Executors)や実行時間を加味しながら、最適なワーカー数を確認し、executorをフル活用するようにします。
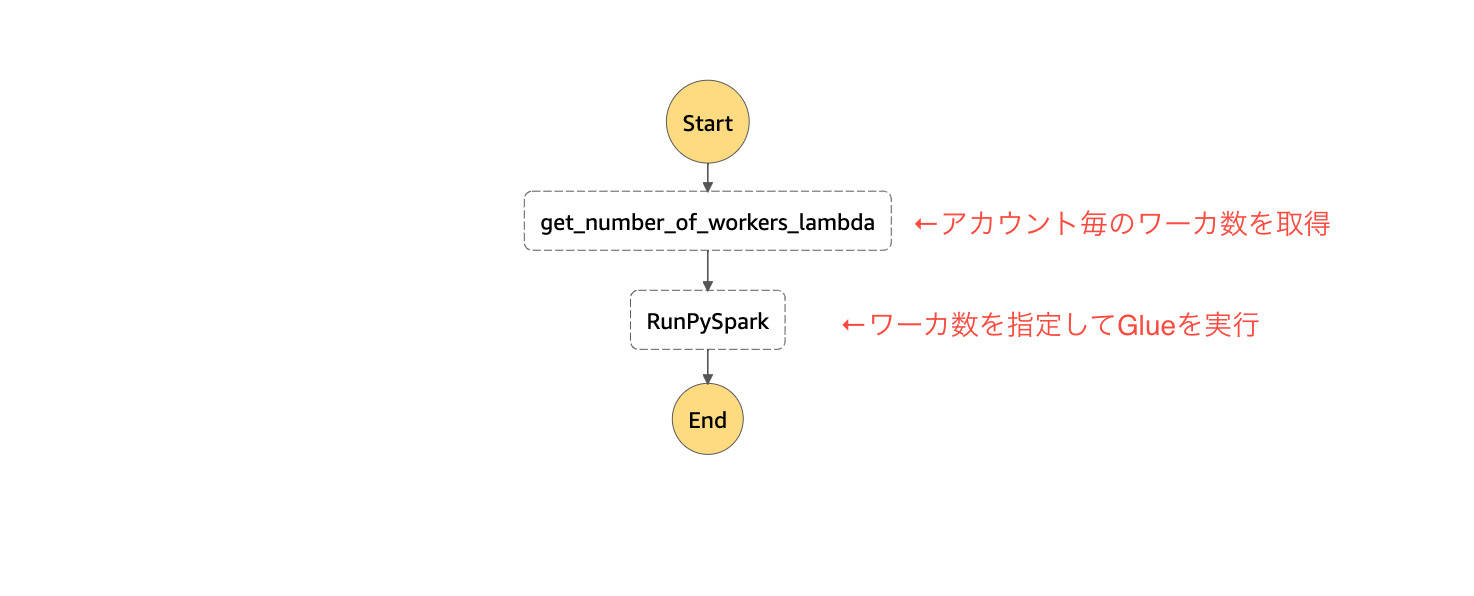
フルカイテンではアカウントのデータ量に応じて、ワーカー数を3つに分類しています。GlueのJobをStepFunctionから起動する前に、Lambdaから事前に決めたワーカー数を取得し、StepFunctionsでパラメーター(NumberOfWorkers)を指定するようにしています。
- StepFunctionsからの起動例
2. パーティションの適正化
複数のノードで効率よく分散処理させるために、JOINするDataFrameにパーティションカラムの指定とパーティション数の指定を行います。データの偏り(skew)が大きい場合、実行時間の長いタスクがボトルネックになり、実行時間が伸びてしまいます。これを回避するために、ワーカー数に合わせて、パーティションの分割数を指定し、並列で実行できるタスク数とパーティションの適正化を行います。パーティションの適正化は下記のようにrepartitionを使用し、ワーカー数を元に分割するようにしています。
def execute(worker_num, df_orders, df_analysis_period):
df_period_orders = df_orders.join(
other=df_analysis_period.hint('BROADCAST'),
on=df_orders['selling_dt'].between(
df_analysis_period['start_date'], df_analysis_period['end_date']
),
how='inner',
).select(
F.col('order_id'),
F.col('seller_id'),
F.col('total_selling_price'),
F.col('total_cost_price'),
F.col('aggregation_period'),
).alias(
'period_orders',
).repartition(
worker_num * constants.COEFFICIENT, # ワーカー数を元に分割数を指定
['seller_id']
)
3. DynamicFrameの適切な利用
PySparkで集計した結果は、Parquet形式でS3に出力してAthenaで読み込んでいます。
各種集計処理はDataFrameを使用し、出力前にDynamicFrameに変換をします。
DynamicFrameには、Glueに最適化されたParquetライターがあります。DynamicFrameのformat_optionsでuseGlueParquetWriterを指定することでParquetファイルの書き込み速度が向上し、実行時間の短縮を行うことができます。
## DataFrameからDynamicFrameへ変換
dyf_product_code_aggregation = DynamicFrame.fromDF(df_product_code_aggregation, glueContext, "product_code_aggregation")
## DynamicFrameを使用した、S3へのParquet出力
glueContext.write_dynamic_frame.from_options(
frame=dyf_stock_distribute_analysis_product_code_aggregation_company,
connection_type="s3",
connection_options={
"path": path,
'groupFiles': 'inPartition',
'groupSize': constants.GROUP_SIZE,
},
format="parquet",
format_options={
"useGlueParquetWriter": True,
"compression": "snappy",
"blockSize": constants.BLOCK_SIZE,
"pageSize": constants.PAGE_SIZE,
}
)
おわりに
今回は、データ分析基盤をRedshiftからPySpark on Glueに移行した経緯と、Glueを効率的に使うための3つのポイントを紹介しました。当社のような、アカウント毎にバッチ処理を実行するSaaSサービスの場合、並列処理が可能なPySpark on Glueは強力な味方になってくれると思います。
フルカイテンでは、ビックデータを活用したプロダクト開発に興味のあるエンジニアを募集しています。
「フルカイテンってどんな会社?」か分かるnoteを多数公開していますので、是非ご覧ください!
参照サイト
- https://aws.amazon.com/jp/blogs/news/load-data-incrementally-and-optimized-parquet-writer-with-aws-glue/
- https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-programming-etl-format-parquet-home.html#aws-glue-programming-etl-format-parquet-reference
- https://docs.aws.amazon.com/glue/latest/dg/monitor-debug-capacity.html
- https://aws.amazon.com/jp/blogs/news/optimize-memory-management-in-aws-glue/
- https://d1.awsstatic.com/webinars/jp/pdf/services/202108_Blackbelt_glue_etl_performance1.pdf