自己紹介
オンプレ出身インフラエンジニア、AWS初心者のため勉強中
Qiita初投稿
概要
やりたいことは単純で、S3内のjsonデータをAthenaで検索したり、加工してS3にエクスポートしたい!
他部署の方に最新のデータを提供して色々分析して貰いたい!
実装方法
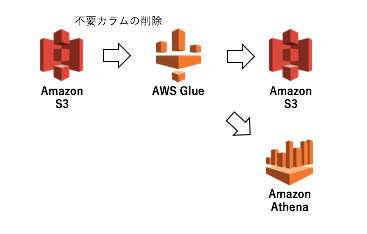
Glueのクローラーを毎日実行
↓
Glueのテーブルを毎日更新
↓
jobを毎日実行(不要なカラム削除)
↓
S3にエクスポート
問題点
あるカラムの中にint型とdouble型が混在しているので、エクスポートした時にどちらかの方がnullになってしまう。提供した他部署の方に指摘されて気付きました。
その節はご迷惑お掛けしました。。この場を借りてお詫びします。
実施したこと
複数の型があった場合はchoice型が選択されていい感じにやってくれるらしいので 、出力方法を変更してみる
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "int", "columnA", "string")]
でstringで出力、でもできない!
ならばdouble型で色々試してみる
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "int", "columnA", "double")]
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "double", "columnA", "double")]
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "double", "columnA", "int")]
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "double", "columnA", "string")]
できない!!!
resolveChoice使えばできそう!!
サポートに聞いてみた。
ResolveChoice の第一引数は JSON ファイルの属性と一致させる必要がありますので、以下のように記述することで int 型へのキャストが可能でございます。
解決方法
datasource1 = datasource0.resolveChoice(specs = [('columnA','cast:int')])
applymapping1 = ApplyMapping.apply(frame = datasource3, mappings = [("columnA", "int", "columnA", "int")]
なるほど〜!
choice型で入っているので、一度型を揃えてから出力してあげればできるんですね。
今後の妄想
S3内のデータをAthenaでゴリゴリ検索できる、エクスポートして他部署に展開できる!
不要なカラムを削除することで検索時間の削減、料金削減もできる!
参考