はじめに
アドバンスト・メディアで音声認識の研究開発に取り組んでいる小島淳嗣と申します.この記事では,音声認識APIを実行する環境の準備とAPIの実行方法について述べていきます.
音声認識APIを比較された投稿 にインスパイアされ,多くの方に,自前の音声で実際に認識結果を比較してみてほしい,といった考えがモチベーションになっています.
基本的には公式のマニュアルをそのまま実行すれば動きますので,自前の音声から認識結果を得るまでの簡単な手順をまとめていきます.
取り上げる音声認識API
アドバンスト・メディアのAmiVoice Cloud Platform,AmazonのAmazon Transcribe,GoogleのCloud Speech-to-Text,IBMのIBM Watson Speech to Textの4つを取り上げます.いずれも2019 12/11 時点で,トライアル期間が存在し,回数制限はあるものの期間内であれば無料で使えます.それでは,まとめてきます!
AmiVoice Cloud Platform (アドバンスト・メディア)
1)公式サイト
https://acp.amivoice.com/
 |
|---|
2) 準備
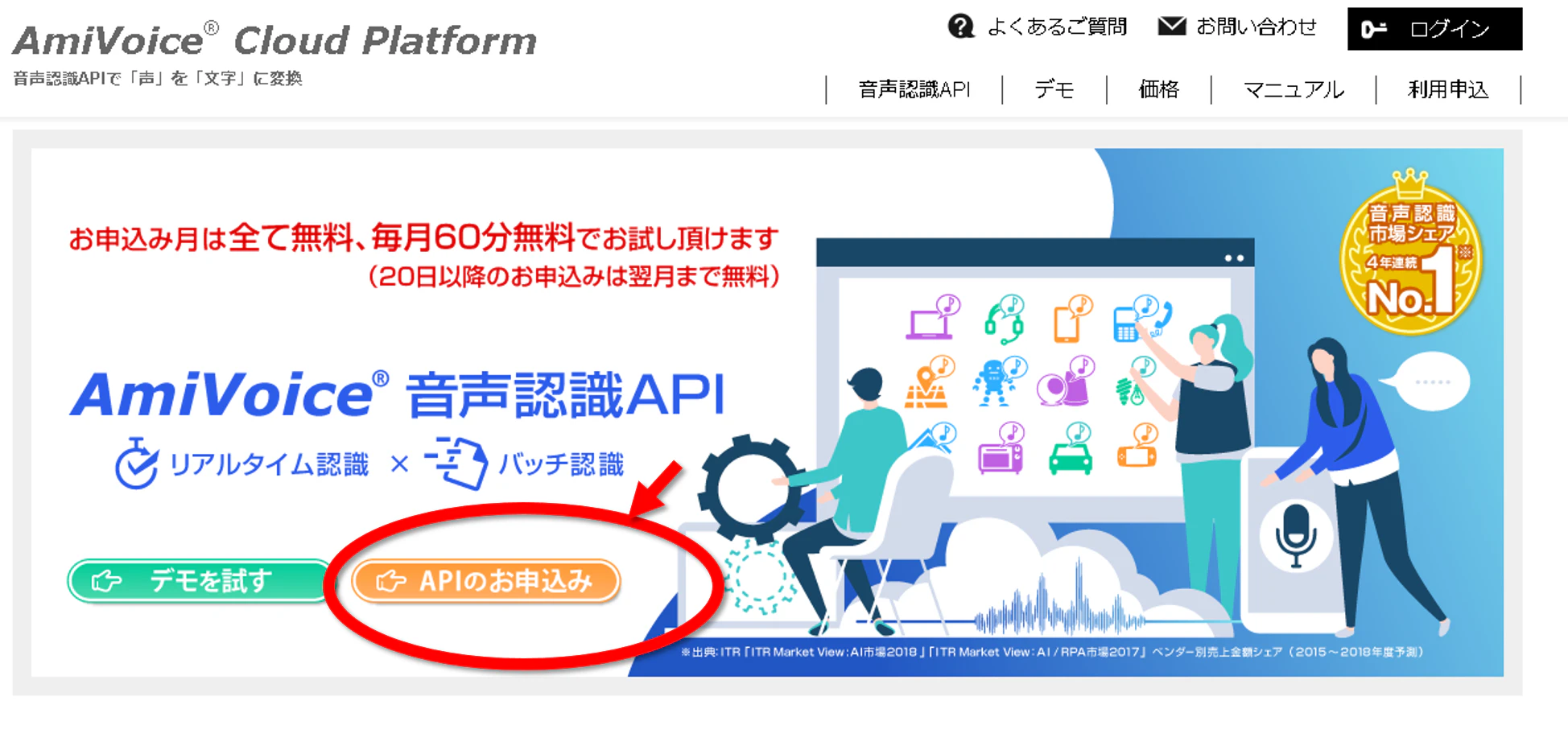
step1. 下の画像の赤で囲んだところをクリックし,ユーザ登録に進む
 |
|---|
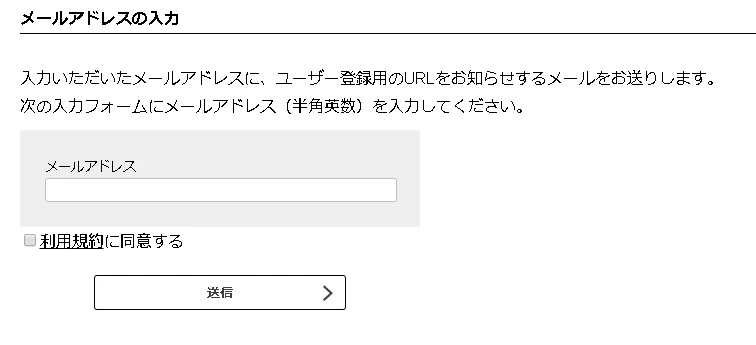
step2. 登録ページの下にある送信フォームにアドレスを入力する
 |
|---|
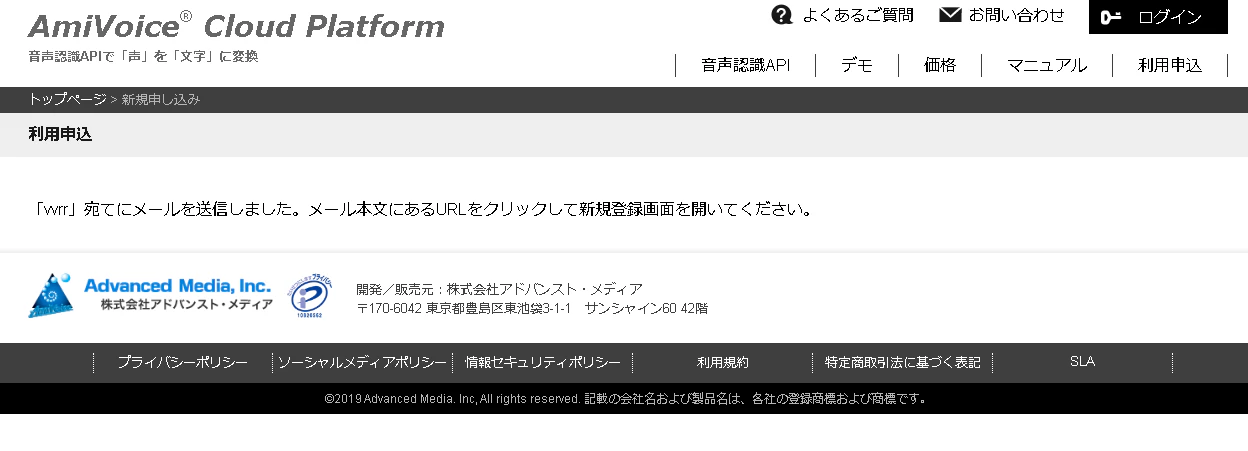
step3. アドレスにメールが来るので,リンクをクリックし,登録する
 |
|---|
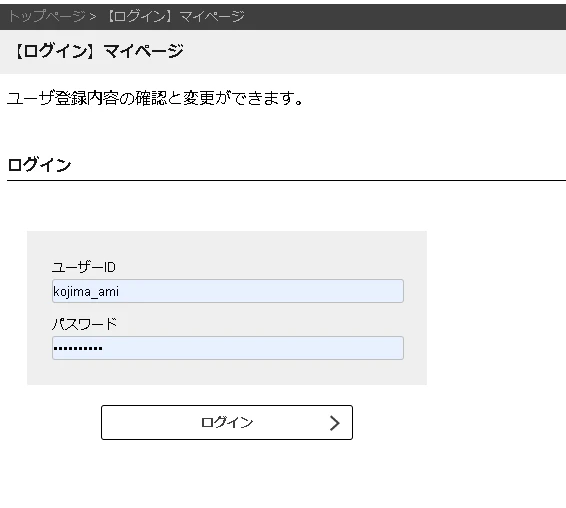
step4. 登録したユーザIDとパスワードを使って[マイページ](https://acp.amivoice.com/account/login.php) にログイン
 |
|---|
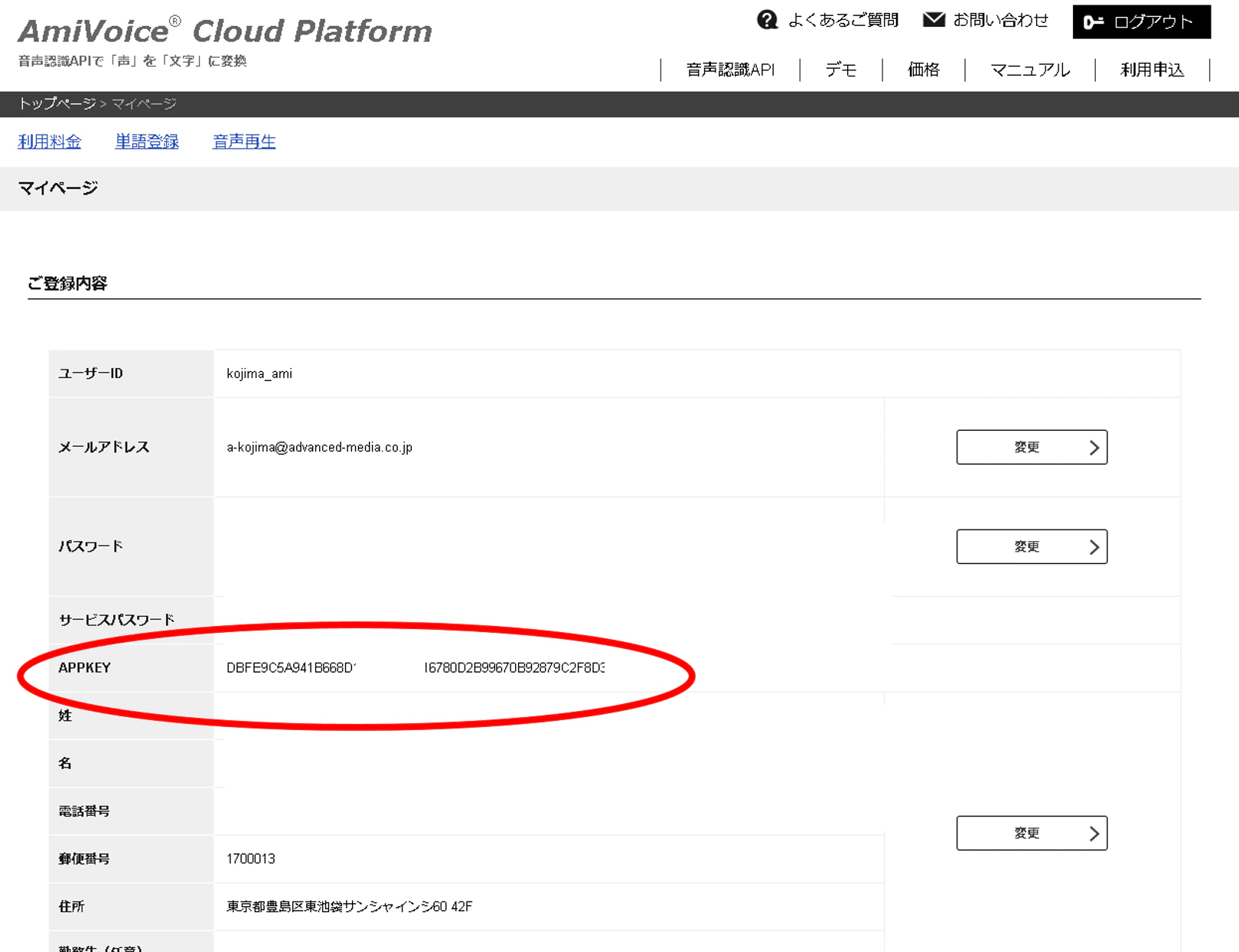
step5. APPKEY は音声認識するときに使うのでメモっておく
 |
|---|
3) APIの呼び方
step1. 用意されたサンプルプログラムの入ったzipをダウンロードし,解凍する
step2. 好きな開発言語のディレクトリに行き,batを実行する
Amazon Transcribe (Amazon)
1)公式サイト
https://aws.amazon.com/jp/transcribe/
2) 準備
step1. AWS アカウントを作る
step2. 認識させたい音声をS3バケットに置く
step3. バケットにおける音声のオブジェクトURL をメモする(マネジメントコンソールから見るのが楽です)
3) APIの呼び方
# json をPOST
aws transcribe start-transcription-job --cli-input-json file://json.json --region <REGION>
# 認識結果をゲット
aws transcribe get-transcription-job --transcription-job-name <JOB_NAME> --region <REGION>
jsonのサンプルは以下になります.
{
"TranscriptionJobName": "<JOB_NAME>",
"LanguageCode": "ja-JP",
"MediaFormat": "wav",
"Media": {
"MediaFileUri": "<FILE_PATH_IN_S3>"
}
}
<JOB_NAME> には適当な文字列を入れてください.ただし,スペースはNGなようです.<FILE_PATH_IN_S3>は,準備の step2 でメモったオブジェクトURLを書いてください.<REGION>はS3が立っているregion を書いてください.
Cloud Speech-to-Text (Google)
1)公式サイト
https://cloud.google.com/speech-to-text/?hl=ja
2) 準備
step1. Google Cloud Platformに登録
step2. 1)のマニュアルに沿ってAPI keyを取得する
3) APIの呼び方
curl -s -X POST -H "Content-Type: application/json" -d @sync-request.json "https://speech.googleapis.com/v1/speech:recognize?key=<API_KEY>"
jsonファイルは以下の通り
{
"config": {
"encoding":"<ENCODE>",
"sampleRateHertz": 16000,
"languageCode": "jp-JP",
"enableWordTimeOffsets": false
},
"audio": {
"uri":"<AUDIO_PATH>"
}
}
<API_KEY> は準備のstep2 で取得したAPI_KEY,<ENCODE>は音声の拡張子,<AUDIO_PATH>は音声のパスを書く.
IBM Watson Speech to Text (IBM)
1)公式サイト
https://www.ibm.com/watson/jp-ja/developercloud/speech-to-text.html
2) 準備
step1. IBM Cloudに登録
step2. 1)のマニュアルに沿ってAPI鍵を取得する
3) APIの呼び方
curl -X POST -u "apikey:<API_KEY>" ^
--header "Content-Type: audio/<ENCODE>" ^
--data-binary @<AUDIO_PATH> ^
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/recognize?model=ja-JP_BroadbandModel"
<API_KEY> は,準備の step2で得た API鍵,<ENCODE>は音声の拡張子,<AUDIO_PATH> は音声のパスを書く.
おわりに
音声認識APIを実際に皆様が試し,認識結果を見て比較できるよう,API実行までの手順について紹介しました.大体どれも流れは同じですね.大体わかったところで,皆様も手持ちの音声を使って音声認識の結果を見比べてみてください.
なお,ご紹介しきれませんでしたが,実はAmiVoice Cloud Platform(以下ACP)には,他のAPIにはない機能があります.以下の4つの特徴をすべて満たすのはACPだけです!!
①リアルタイム/バッチ認識ともに対応
③ビジネスシーンにおけるNGワードを自動除去
④製品名・固有名詞等は認識結果に出るように自分で辞書に単語追加可能
⑤様々な開発言語や開発環境を想定した豊富なサンプルプログラムを準備
AmiVoiceは,日本で最も使われている音声認識のブランドです.ACPに関する問い合わせ,あるいは一緒に研究開発したい!という方はぜひご一報ください.
a-kojima[at]advanced-media.co.jp
[at]は@に変えてください.
おまけ: いくら頑張ってもあの単語が認識されない? ACPで単語追加する方法!!
さて,創業以来蓄積されてきた20年分の大量のデータと最新技術を駆使し,高精度な認識率を誇る ACP ですが, 音声認識の仕組み上,どうしても認識できないケースが存在します.具体的には,音声認識には, 弊社ページ「音声認識の仕組み」の図 にあるような辞書を必要とし,これに含まれていない単語は残念ながら認識できません.これはどんな音声認識エンジンも同じです.ACPでは,できるだけ多くの皆様にお使いいただけるよう,汎用的なものをご用意しておりますが,珍しい苗字や一般的でない専門用語は,辞書に含まれていない可能性があります.そのような場合,ACP なら単語追加を行うことで,それらの単語を認識させることができます.それでは単語追加をしてみます!
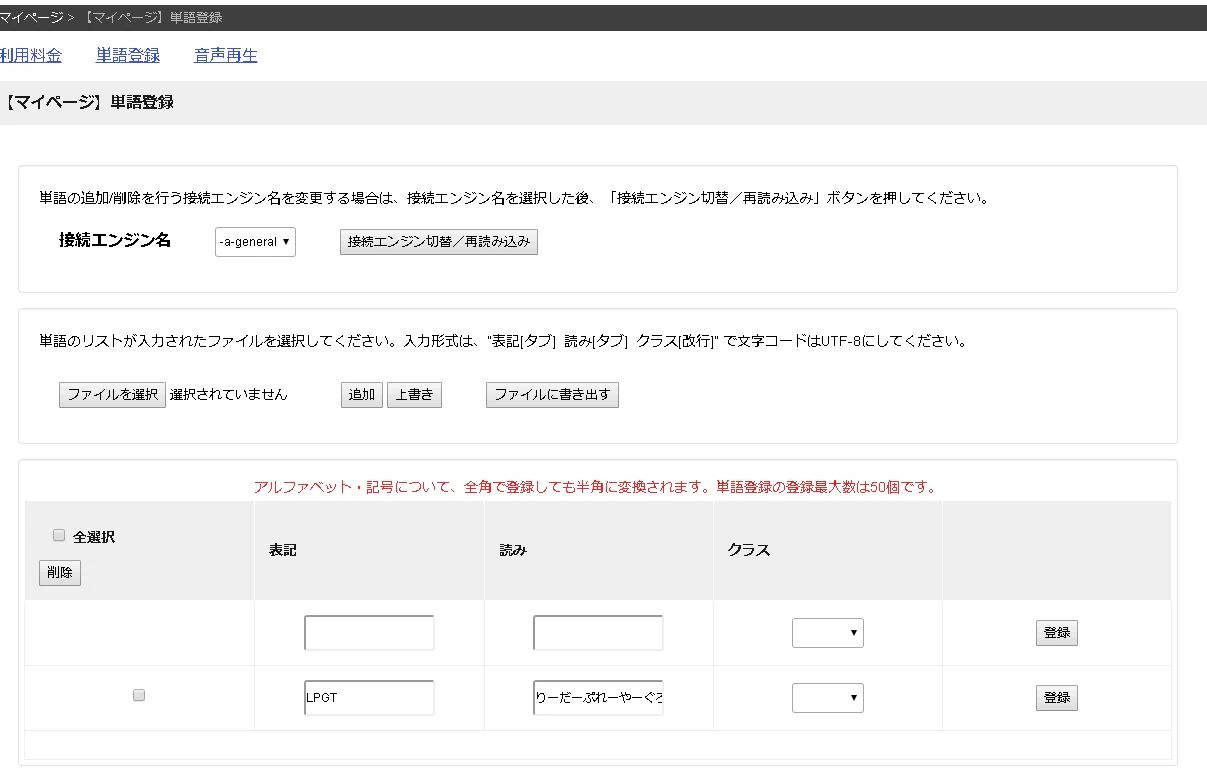
step1. マイページに行って赤で囲んだところをクリック
 |
|---|
step2. 赤四角で囲んだところから単語の表記と読みを登録する
 |
|---|
ここでは,弊社の社訓の1つである LPGT (Leader Player Growing Together と読みます)を登録してみます.
まず,登録前は,認識できないことを確認します.
ここでは,以下のようにpythonからAPIを実行してみます(好きな開発言語で問題ありません).
python HrpTester.py https://acp-api.amivoice.com/v1/recognize <AUDIO_PATH> c=16K g=-a-general u=<APP_KEY> > out.json
<AUDIO_PATH> には音声のパス,<APP_KEY>にはマイページのAPP KEYを書いてください.
なお,jsonはUnicodeで返ってきており,そのままでは結果が分からないため,パースして認識結果出すスクリプトを以下に用意しました.
import json
import sys
import re
FILE_PATH = sys.argv[1]
REGEX_PATTERN = r'\{.*\}'
# ============================================
# extract only json part
# ============================================
try:
f = open(FILE_PATH, 'r', encoding='shift_jis')
content = f.read()
except IOError:
f.close()
print('fail opening file:', FILE_PATH)
regex = re.compile(REGEX_PATTERN)
json_part = regex.findall(content)
if len(json_part) != 1:
print('invalid file:', FILE_PATH)
sys.exit(1)
# ============================================
# read as json
# ============================================
try:
content = json.loads(json_part[0])
except:
print('invalid file:', FILE_PATH)
sys.exit(1)
# ============================================
# recognize result
# ============================================
if content['message'] != "":
print('error:', content['message'])
sys.exit(1)
print('text:', content['text'])
スクリプトを適当な名前で保存(例えば readjson.py)して,
python readjson.py <JSON_FILE>
のように使ってください.
それでは登録前の状態で,認識させてみます.
認識結果は以下の画像のようになっており,うまく認識できていません(でもなんかおしい!).
 |
|---|
しかし,案ずることなかれ!ACPなら単語を自分で登録できるのです!
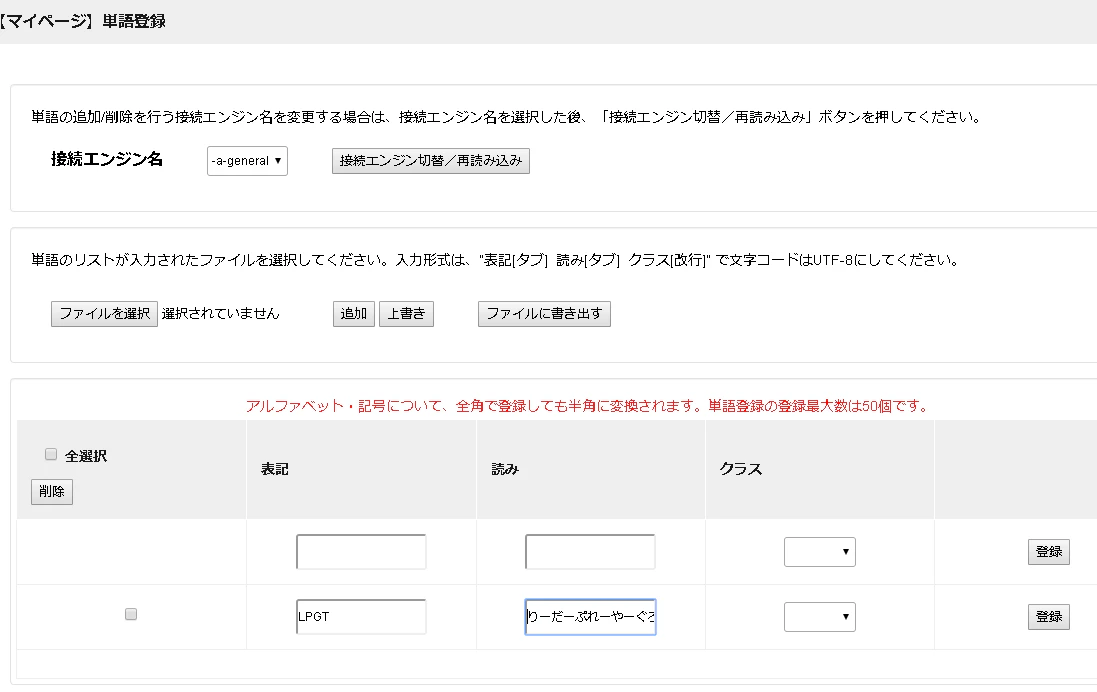
例えば,今回の例では
表記: LPGT
読み: りーだーぷれーやーぐろーうぃんとぅぎゃざー
になります.
下の画像のように表記と読みをそれぞれフォームに入力し登録ボタンを押します.
 |
|---|
登録ボタンを押すと,今まで追加した単語が以下のような画面から確認できます.
 |
|---|
それでは,登録で来たところで,LPGTが認識できるか試してみましょう!
今度は,若干先ほどと引数が変わって,以下のように実行します.
python HrpTester.py https://acp-api.amivoice.com/v1/recognize <AUDIO_PATH> c=16K g=-a-general i=<USER_ID> u=<APP_KEY> > out.json
※ 引数に i=<USER_ID> を付けてください.<USER_ID> はマイページで確認できます
※ HrpSimpleTester でなく,HrpTester を実行して下さい
がんばれAmiVoice Cloud Platform!未知語に負けるな!!
 |
|---|
LPGTが認識できました.
直観的でとても簡単ですね.皆様もぜひおためしください.
疑問やわからない点がございましたら,小島までご一報ください.
a-kojima[at]advanced-media.co.jp
[at]は@に変えてください.