概要
大学の研究でTacotron2のモデルを扱ったので、Pytorchを使った実装について解説します。あくまで私の理解に基づく記事ですので、誤りが含まれる可能性があることは承知の上で、読んでいただけると幸いです。また、初学者の備忘録として書いているので、蛇足もあるかと思います。
こちらが、大本の論文です。
https://arxiv.org/abs/1712.05884
また、Tacotorn2の前身である、Tacotorn2の論文も載せておきます。
https://arxiv.org/abs/1703.10135
参考
解説するプログラムは、NVIDIAが公開しているものを参考に、自分なりに解釈して書いたものになります。(関数名や変数名はほぼ真似ています)
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2
また、理解の助けになった書籍として、こちらを挙げておきます。Tacotron2以外についても載っており、理論も実装も非常にわかりやすく解説されているのでお勧めです。
https://r9y9.github.io/ttslearn/latest/
こちらはNVIDIAが公開されたプログラムをベースに解説した記事であり、処理の流れが分かりやすく図示されているので、参考にさせて頂きました。
https://akifukka.hatenablog.com/entry/tacotrn2_1
Tacotron2とは
Googleが発表したTTS(text-to-speech)アルゴリズムで、非常に高品質な音声を合成することができるモデルです。中間表現としてメルスペクトログラムを用いているのでEnd-to-Endではありませんが、テキストから音声波形までをニューラルネットワークで処理できるので、言語的なコンテキストを抽出することなく学習できます。
次に示す図はTacotron2の論文に掲載されているモデルの構成図です。

所謂、エンコーダ・デコーダモデルというやつで、アテンション機構を採用しています。この記事で解説するのは、メルスペクトログラムの予測までです。ボコーダについては触れません。内容について、
1. エンコーダ
2. アテンション
3. デコーダ
4. Post-Net
の4項目に分けて解説したいと思います。
エンコーダ

解説するのは上記の画像の部分になります。テキストから特徴量を抽出するためのモジュールです。Tacotron2のエンコーダは畳み込み層とLSTMから成っていることが分かります。
エンコーダに限らず、モデルの実装に必要な情報は、論文の2.2.の項目、Spectrogram Prediction Networkの部分で述べられています。これによると、エンコーダの処理の流れは次の様になります。
1. テキストを512次元の文字埋め込みベクトルに変換
2. 5×1の512個のフィルタをそれぞれ持つ、3層1次元の畳み込み層を通過
3. 片方向256、計512ユニットを含む単一の双方向LSTMで処理
Character Embedding
前提として、モデルの入力はテキストをIDに変換したものになります。pytorchでは、nn.Embeddingモジュールを用いて、IDごとに埋め込みベクトルに変換します。
また、学習時にはミニバッチごとに処理をおこなうため、系列長を揃えるためにパディングを行います。
import torch.nn as nn
# (バッチサイズ, 系列長)->(バッチサイズ, 系列長, 512)
nn.Embedding(num_embeddings="テキストIDの数の値", embedding_dim=512, padding_idx=0)
3 Conv Layers
畳み込みによって期待できる効果についてはTacotronの論文に記載があります。大きさ5のフィルターで畳み込むことによって、局所的、文脈的な情報を明示的にモデル化でき、層を重ねることで局所的な不変性を高めることができるとのことです。音声のような隣り合う要素が大きな関連性を持つ情報に対して、畳み込みは相性が良いのだと思います。
また、time resolution(日本語だと時間分解能?)を維持するために、stride=1とします(デフォルトが1なので定義する必要はありませんが)。これについては畳み込む前後で系列長が変化することを防ぐためにstrideは1にする、といった程度にとらえました。系列長が短くなってしまうと、その分だけアテンション(後ほど説明します)で注目するテキストに対する範囲が煩雑になってしまいますし、実装も面倒です。
同様の目的で、パディングを行います(カーネルサイズ5の場合は2)。
1層ごとにバッチ正規化とReLU関数による活性化、Dropoutによる学習の安定化が行われます。
# 1層の処理
nn.Sequential(
nn.Conv1d(in_channels=512, out_channels=512, kernel_size=5, stride=1, padding=2, bias=False),
nn.BatchNorm1d(num_features=512),
nn.ReLU(),
nn.Dropout(0.5))
Bidirectional LSTM
Tacotronの論文には、双方向LSTM(Tacotronでは双方向GRU)を実装する意味について、「連続的な特徴を抽出できる」としか記述がありませんでしたが、LSTMは長期の時系列を考慮したRNNなので、広域的な対応関係をとらえるためと理解しました。
nn.LSTM(input_size=512, hidden_size=256, num_layers=1, batch_first=True, bidirextional=True)
nn.LSTMの出力は、各隠れ層ベクトルと最後の隠れ層ベクトルを出力します。batch_first=Trueとすることで、入出力の形状を(系列長, バッチサイズ, 隠れ層の次元)という形状から、(バッチサイズ, 系列長, 隠れ層の次元)という形にすることができます。
出力について、隠れ層の次元は256ですが、bidirextional=True(双方向)とすることで前方向と後ろ方向の出力が結合され、計512次元となります。
また、エンコーダのLSTMは1層のみなので、num_layers=1とします(デフォルトは1なので定義の必要なし)。
エンコーダクラスの実装
以上の内容をまとめた実装を以下に示します。
import torch.nn as nn
from torch.nn.modules.batchnorm import BatchNorm1d
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class Encoder(nn.Module):
def __init__(self,
num_vocab="IDの数",
encoder_n_convolutions=3,
encoder_embedding_dim=512,
encoder_kernel_size=5,
dropout=0.5):
super(Encoder, self).__init__()
# 文字埋め込み
self.embed = nn.Embedding(num_vocab, encoder_embedding_dim, padding_idx=0)
# 3層1次元の畳み込み
convolutions = nn.ModuleList()
for _ in range(encoder_n_convolutions):
convolutions.append(
nn.Sequential(
nn.Conv1d(encoder_embedding_dim,
encoder_embedding_dim,
encoder_kernel_size,
padding=int((encoder_kernel_size - 1) // 2),
bias=False),
nn.BatchNorm1d(encoder_embedding_dim),
nn.ReLU(),
nn.Dropout(dropout))
)
self.convolutions = nn.Sequential(*convolutions)
# 双方向LSTM
self.bi_lstm = nn.LSTM(encoder_embedding_dim,
int(encoder_embedding_dim // 2), 1,
batch_first=True, bidirectional=True)
def forward(self, x, input_lengths):
x = self.embed(x)
# 3層1次元の畳み込みの計算
x = self.convolutions(x.transpose(1, 2)).transpose(1, 2)
# 双方向LSTMの計算
x = pack_padded_sequence(x, input_lengths, batch_first=True)
outputs, _ = self.bi_lstm(x)
outputs, _ = pad_packed_sequence(outputs, batch_first=True)
return outputs
NVIDIAのプログラムでは、エンコーダクラス内でEmbeddingの処理は行われていませんでしたが、ここではエンコーダクラス内に定義してしまいます。
畳み込み層のモジュールは、1層の処理をnn.Sequentialで定義し、3層をnn.ModuleListでまとめます。nn.ModuleListは定義した層が接続されないので、forwardで繰り返し処理を行わない場合はnn.Sequentialで層を結合します。
その他に、計算を行う際(forwordの処理)の注意点として、以下が挙げられます。
・nn.Conv1d、nn.BatchNorm1dの入力は、(バッチサイズ, 入力チャンネル数, 系列長)なので、畳み込み層の計算時には、1次元目と2次元目をtranspose関数で入れ替える必要がある。
・paddingが出力に影響を及ぼさないように、pack_padded_sequence関数とpad_packed_sequence関数を使用
アテンション
アテンションは簡単に言うと、入力データのどこに注目するべきかを特定する仕組みです。自然言語処理の分野で発展してきた技術ですが、現在では様々な分野で使用されています。
Tacotron2で用いられているアテンションは、エンコーダ、デコーダ双方から情報を受け取るSource-Target型のアテンションと呼ばれるものです。Seq2Seqのようなモデルで用いられる場合、1つ前の時刻の出力をQuery、エンコーダからの出力をKeyとし、これらの関連度を調べてValue(大抵はKeyと同じ)と掛け合わせることで、時刻ごとの重要度を考慮したベクトル(コンテキストベクトル)を得ることができます。
イメージとしては、次のような式で計算されます。
Attention(Q,K,V) = Softmax(Score(QK))V
QueryとKeyの関連度(ここではScoreの式で求めるものとする)を調べた後、Softmax関数で正規化してValueと掛け合わせてアテンションを求めます。ただし、関連度を調べるScoreの式には種類があり、代表的なものとしては次の2つが挙げられます。
・Additive Attention(加法注意)
・Dot-Product Attention(内積注意)
論文によると、Tacotron2で用いられるアテンションは、Additive Attention をもとに拡張した、"Location-sensitive attention"です。
こちらの論文で提案されています。
https://arxiv.org/abs/1506.07503
Additive Attentionは、QueryとKeyを Feed Forward Network(情報が順伝播するニューラルネットワーク)に通し加算することでアテンション重みを求めます。Location-sensitive attention(上記の論文ではhybrid attention mechanism)は、これに前回までの累積のアテンション重みの情報もあわせて加算するようです。
hybrid attention mechanismを用いた時刻$i$のコンテキストベクトル$c_i$の求め方は、次のような式になります。
f_i=F*α_{i-1}\tag{1}
e_{i,j}=w^\top \mathrm{tanh}(Ws_{i-1} + Vh_j + Uf_{i,j} + b)\tag{2}
α_{i,j}=\frac{\mathrm{exp}(e_{i,j})}{\sum_{k=1}^L\mathrm{exp}(e_{i,k})}\tag{3}
c_i = \sum_{j=1}^Iα_{i,j}h_j\tag{4}
$h = $ { $h_1, h_2 … , h_I$ } はエンコーダの隠れ状態、$s_i$はデコーダの隠れ状態、$w$、$W$、$V$、$U$は重み行列、$b$はバイアス、$F$は畳み込みのカーネルを表しています。
hybrid attention mechanismは、音声認識のために提案された仕組みのようですが、RNNを用いた生成器を利用する際に、入力シーケンス内から正しく次の位置を選択してデコードするために考えられました。
以上の式のようにアテンションを実装します。論文より、重要な情報は以下の通りです。
1. 入力とlocation features(おそらく、入力はエンコーダとデコーダからの情報、location featuresが累積のアテンション重みの情報)は、128次元の隠れ表現に投影したのち計算。
2. location featuresは、カーネルサイズ31の32個の1次元畳み込みフィルタを用いて計算される。((1)式の処理)
まずは、(1)式の畳み込みの内容について示します。
nn.Conv1d(in_channels=2, out_channels=32, kernel_size=31, padding=15, bias=False)
入力チャンネル数が2になっている理由なのですが、NVIDIAの実装を見てみたところ、累積アテンション重みに加えて、前ステップのアテンション重みもくっつけて処理しているっぽいです。論文内では言及がなかったのですが(自分が見逃しているだけかもしれませんが)、参照する情報が多い方が精度が上がるような気がするので、NVIDIAの実装に倣います。(累積アテンション重みのみを参照する場合は入力チャンネルは1になります)
次にtanh関数の中身です
nn.Linear(in_features=1024, out_features=128, bias=False) # W
nn.Linear(in_features=512, out_features=128, bias=False) # V
nn.Linear(in_features=32, out_features=128, bias=False) # U
「128次元の隠れ表現に投影する」とあるので、out_features=128の全結合層で処理します。また、バイアスについてですが、NVIDIA実装ではFalseになっていたものの、(2)式を見る限りTrueでも問題ないような気がします。
各表現を足し合わせてtanh関数で処理した後は、1×系列長のベクトルを得るためにout_features=1の全結合層で処理します。
nn.Linear(in_features=128, out_features=1) # w
そして、Softmax関数で正規化し、エンコーダ出力と掛け合わせて、コンテキストベクトルを得ます。
これらの話を踏まえて、(1)~(4)の式をクラスとして定義すると、以下のようになります。
import torch
# Location Sensitive Attention
class Attention(nn.Module):
def __init__(self,
attention_rnn_dim=1024,
embedding_dim=512,
attention_dim=128,
attention_location_n_filters=32,
attention_location_kernel_size=31):
super(Attention, self).__init__()
self.location_conv = nn.Conv1d(2, attention_location_n_filters,
kernel_size=attention_location_kernel_size,
padding=int((attention_location_kernel_size - 1) // 2),
bias=False)
self.query_layer = nn.Linear(attention_rnn_dim, attention_dim, bias=False)
self.memory_layer = nn.Linear(embedding_dim, attention_dim, bias=False)
self.location_dense = nn.Linear(attention_location_n_filters, attention_dim, bias=False)
self.v = nn.Linear(attention_dim, 1)
def forward(self, query, memory, processed_memory,
attention_weights_cat, mask):
"""
PARAMS
-------
query: デコーダの隠れ状態
memory: エンコーダからの出力
processed_memory: 処理済みのエンコーダからの出力、デコーダクラス実行時にmemory_layerを呼び出して個別に処理
attention_weights_cat: 前回のアテンション重み+累積のアテンション重み
mask: パディング部がTrue、それ以外がFalseのマスク
RETURNS
-------
attention_context: コンテキストベクトル
attention_weights: アテンション重み
"""
processed_query = self.query_layer(query.unsqueeze(1))
processed_attention_weights = self.location_conv(attention_weights_cat)
processed_attention_weights = self.location_dense(processed_attention_weights.transpose(1, 2))
energies = self.v(torch.tanh(
processed_query + processed_attention_weights + processed_memory)).squeeze(-1)
# マスクを適用
energies = energies.masked_fill_(mask, -float("inf"))
attention_weights = F.softmax(energies, dim=1)
attention_context = torch.bmm(attention_weights.unsqueeze(1), memory)
attention_context = attention_context.squeeze(1)
return attention_context, attention_weights
注意点として、パディング部分に注意が向くことを避けたいため、Softmax関数で処理する前にマスクを適用する必要があります。パディング部分を限りなく小さい値にすることで、Softmaxを通した後にパディング部分がほぼ0になり、適切な範囲内に注目したコンテキストベクトルを抽出することが可能になります。(今回実装したクラスでは、引数としてマスクを定義しています)
マスクを行う関数は、このようになります。(この関数に関しては、まんまNVIDIAからの引用になります)
def get_mask_from_lengths(lengths):
"""
マスクを生成する関数
"""
max_len = torch.max(lengths).item()
ids = torch.arange(0, max_len, device=lengths.device, dtype=lengths.dtype)
mask = (ids < lengths.unsqueeze(1)).byte()
mask = torch.le(mask, 0)
return mask
デコーダ
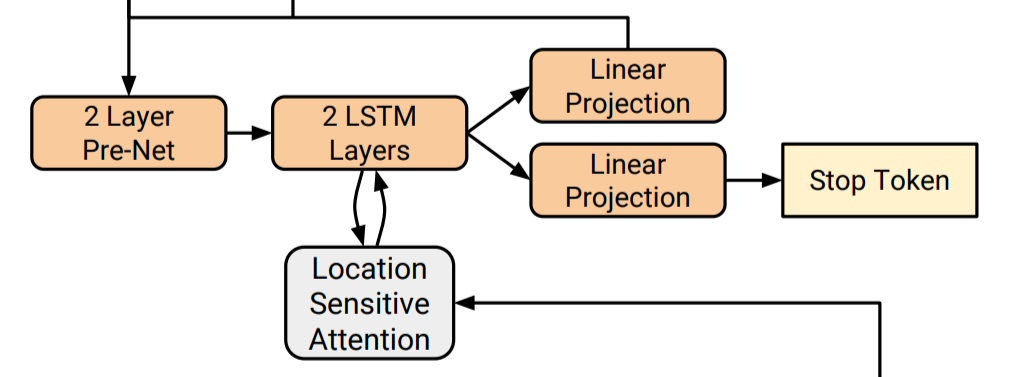
Tacotron2ではRNNベースのデコーダが用いられており、1ステップごとに1フレームのメルスペクトログラムを推論します。2層の片方向LSTM、全結合層、Pre-Netというモジュールから構成されています。また、自然言語処理では文章の終わりを表す特殊文字で出力の終わりを判断したりしますが、音声合成ではそうもいかないので、メルスペクトログラムと合わせて出力の終了を判断するStop Tokenの推論も行います。
デコーダの処理の流れは次のようになります。
1. 前回のステップの出力が、256個の隠れたReLUユニットを持つ2層の全結合層である"Pre-Net"を通過
2. Pre-Netの出力とアテンションのコンテキストベクトルを連結して、1024ユニットの2層の単方向LSTMを通過
3. 1フレームのメルスペクトログラムを予測するために、LSTM出力とアテンションのコンテキストベクトルをくっつけたものが、線形変換される(つまり全結合層)
2 Layer Pre-Net
Pre-Netの役割は、汎化性能の向上です。理由としては、「出力分布の複数のモダリティを解決するためのノイズ源を提供するから」というものです(Tacotronの論文に記載)。複数のモダリティというのは、おそらく時刻ごとのデコーダの出力だと思います。Pre-Netは情報ボトルネックとして働いているのだとか(このあたりはよくわかりませんでした)。参考にした書籍によると、同じようなメルスペクトログラムが連続して出力されるのを防ぐために必要なのだそうです。
実装は以下の通りです。Pre-Netはクラスとして定義します。
from torch.nn import functional as F
# Pre-Net
class Prenet(nn.Module):
def __init__(self,
in_dim=80,
layers=2,
hidden_dim=256,
dropout=0.5):
super(Prenet, self).__init__()
self.dropout = dropout
self.prenet = nn.ModuleList()
for layer in range(layers):
in_channels = in_dim if layer == 0 else hidden_dim
self.prenet.append(
nn.Sequential(
nn.Linear(in_channels, hidden_dim, bias=False),
nn.ReLU())
)
def forward(self, x):
for layer in self.prenet:
x = F.dropout(layer(x), p=self.dropout, training=True) # 推論時も行う
return x
入力80、出力256の2層の全結合層ですが、推論時でもドロップアウトを用いています。どうやら、ドロップアウトを用いることで、ベイズ的に事後分布を求めることができるようで、推論結果はそこからサンプリングした結果と同義なのだとか。おそらくそれがノイズなのだろうなぁと。あやふやな理解ですみません。
Location-sensitive attention
アテンションの内容については説明したとおりです。入力として与えられるデコーダの隠れ状態は、2層のLSTMの1層目の出力になります。
2 LSTM Layers
音声は基本的に過去の発話のみが現在の発話に影響を及ぼすので、双方向ではなく片方向のLSTMを用います。
アテンションを用いる関係上nn.LSTMモジュールは使えないため、nn.LSTMCellモジュールを用いてセルごとに定義を行います。Pre-Netの出力は256次元、コンテキストベクトルは512次元なので、1層目の入力はこれを合算した768次元、LSTMの隠れ層は1024次元なので、2層目の入力はこれとコンテキストベクトルを合算した1537次元になります。
# 片方向LSTM
# 1層目
nn.LSTMCell(input_size=(256+512), hidden_size=1024)
# 2層目
nn.LSTMCell(input_size=(1024+512), hidden_size=1024)
linear projection
LSTMの出力とコンテキストベクトルを結合して全結合層で処理します。
# メルスペクトログラムの推論
nn.Linear(in_features=(1024+512), out_features=80, bias=False)
# Stop Tokenの推論
nn.Linear(in_features=(1024+512), out_features=1, bias=True)
デコーダクラスの実装
以上をまとめた実装が以下のようになります。
class Decoder(nn.Module):
def __init__(self,
n_mel_channels=80,
encoder_embedding_dim=512, # エンコーダの隠れ層の次元数
attention_dim=128, # アテンション全結合層の次元数
attention_location_n_filters=32, # アテンション畳み込み層のチャンネル数
attention_location_kernel_size=31, # アテンション畳み込み層のカーネルサイズ
rnn_dim=1024, # LSTMの次元数
prenet_dim=256, # Pre-Netの次元数
prenet_layers=2, # Pre-Netの層数
max_decoder_steps=1000, # デコーダの出力上限、とりあえず1000に設定
gate_threshold=0.5, # 終了判定
dropout=0.1): # ドロップアウト率
super(Decoder, self).__init__()
self.n_mel_channels = n_mel_channels
self.encoder_embedding_dim = encoder_embedding_dim
self.attention_dim = attention_dim
self.attention_location_n_filters = attention_location_n_filters
self.attention_location_kernel_size = attention_location_kernel_size
self.rnn_dim = rnn_dim
self.prenet_dim = prenet_dim
self.prenet_layers = prenet_layers
self.max_decoder_steps = max_decoder_steps
self.gate_threshold = gate_threshold
self.dropout = dropout
# 注意機構
self.attention_layer = Attention(rnn_dim, encoder_embedding_dim,
attention_dim, attention_location_n_filters,
attention_location_kernel_size)
# Pre-Net
self.prenet = Prenet(n_mel_channels, prenet_layers, prenet_dim)
# 片方向LSTM
self.lstm1 = nn.LSTMCell(
prenet_dim + encoder_embedding_dim, rnn_dim)
self.lstm2 = nn.LSTMCell(
rnn_dim + encoder_embedding_dim, rnn_dim)
# 全結合層
self.linear_projection = nn.Linear(rnn_dim + encoder_embedding_dim, n_mel_channels, bias=False)
self.gate_layer = nn.Linear(rnn_dim + encoder_embedding_dim, 1, bias=True)
def forward(self, memory,
memory_lengths,
decoder_targets=None):
"""
PARAMS
-------
memory: エンコーダの出力、(バッチサイズ, パディングされた文字列の長さ, 各文字に対するベクトル表現の次元数)
memory_lengths: アテンションをマスクするためのエンコーダの出力長
decoder_targets: 正解のメルスペクトログラム(Noneの場合は推論)
RETURNS
-------
mel_outputs: 出力されるメルスペクトログラム(B, 80, 出力長)
gate_outputs: 終了判定信号(B, 出力長)
alignments: 推定場所を示すテンソル(B, 出力長, 文字数)
MEMO
-------
学習時と推論時で異なる処理を行う。decoder_targetsの有無でフラグを立てて判断。
学習時は正解のメルスペクトログラムを、推論時では一つ前の出力をprenetで処理。
"""
inference_flag = decoder_targets is None
B = memory.size(0) # バッチサイズ
MAX_TIME = memory.size(1) # パディング済みの文字列の長さ
dtype = memory.dtype
device = memory.device
prenet_input = memory.new_zeros(B, self.n_mel_channels, dtype=dtype, device=device)
if inference_flag:
max_decoder_steps = self.max_decoder_steps # 推論時は出力上限1000に設定
else:
# (B, 80, 系列長)-> (系列長, B, 80)
decoder_targets = decoder_targets.transpose(1, 2).transpose(0, 1) # 学習時におけるデコーダの入力(正解のメルスペクトログラム)
max_decoder_steps = decoder_targets.size(0) # 学習時の出力の長さは正解メルスペクトログラムと同じ
# 初期化
attention_weights = torch.zeros(B, MAX_TIME, dtype=dtype, device=device)
attention_weights_cum = torch.zeros(B, MAX_TIME, dtype=dtype, device=device)
rnn1_hidden = torch.zeros(B, self.rnn_dim, dtype=dtype, device=device)
rnn1_cell = torch.zeros(B, self.rnn_dim, dtype=dtype, device=device)
rnn2_hidden = torch.zeros(B, self.rnn_dim, dtype=dtype, device=device)
rnn2_cell = torch.zeros(B, self.rnn_dim, dtype=dtype, device=device)
# エンコーダからの出力は個別にFFNで処理する
processed_memory = self.attention_layer.memory_layer(memory)
# マスクの生成
mask = get_mask_from_lengths(memory_lengths)
mel_outputs, gate_outputs, alignments = [], [], []
t = 0
while True:
# Pre-Netの処理
decoder_input = self.prenet(prenet_input)
# アテンションの計算
attention_weights_cat = torch.cat((attention_weights.unsqueeze(1), attention_weights_cum.unsqueeze(1)), dim=1) # 前回のアテンション重み + 累積アテンション重み
attention_context, attention_weights = self.attention_layer(rnn1_hidden, memory, processed_memory, attention_weights_cat, mask)
attention_weights_cum += attention_weights # 累積アテンション重み
# 1層目LSTM
rnn1_input = torch.cat((decoder_input, attention_context), -1)
rnn1_hidden, rnn1_cell = self.lstm1(rnn1_input, (rnn1_hidden, rnn1_cell))
rnn1_hidden = F.dropout(rnn1_hidden, self.dropout, self.training)
# 2層目LSTM
rnn2_input = torch.cat((rnn1_hidden, attention_context), -1)
rnn2_hidden, rnn2_cell = self.lstm2(rnn2_input, (rnn2_hidden, rnn2_cell))
rnn2_hidden = F.dropout(rnn2_hidden, self.dropout, self.training)
# LSTMからの出力(B, 1024)とattentionからの出力(B, 512)をくっつけて全結合層に突っ込む
decoder_hidden_attention_context = torch.cat((rnn2_hidden, attention_context), dim=1)
mel_output = self.linear_projection(decoder_hidden_attention_context) # (B, 80)
gate_output = self.gate_layer(decoder_hidden_attention_context) # 終了フラグ(B, 1)
mel_outputs += [mel_output]
gate_outputs += [gate_output.squeeze(1)]
alignments += [attention_weights]
if inference_flag:
prenet_input = mel_output
else:
prenet_input = decoder_targets[t]
t += 1
if t >= max_decoder_steps:
if inference_flag:
print("Warning! Reached max decoder steps")
break
if inference_flag and (torch.sigmoid(gate_output) >= self.gate_threshold).any():
break
mel_outputs = torch.stack(mel_outputs, dim=2) # (B, 80, 出力長)
gate_outputs = torch.stack(gate_outputs, dim=1) # (B, 出力長)
alignments = torch.stack(alignments, dim=1) # (B, 出力長, 文字数)
return mel_outputs, gate_outputs, alignments
学習時と推論時で処理が異なり、これらの処理の違いは正解メルスペクトログラムの有無でフラグを立てて判断しています。
学習時には正解となるメルスペクトログラムが、推論時には1ステップ前のメルスペクトログラムがPre-Netに渡されます。
また、デコーダの出力長について、推論時はStop Tokenによって決定されますが、Stop Tokenが適切に推論されない場合を考えて、上限を定めておきます。
他には、以下の点に気を付けます。
・一番最初のPre-Netへの入力を定義する必要がある
・アテンション重みと、LSTMの状態を初期化
・アテンションへ渡すエンコーダの出力の処理を、アテンションクラスから呼び出して個別に処理
・推論時にはStop Tokenをシグモイド関数に通し、基準を超えたら出力を終了する
Tacotronの論文では、一度に複数個のメルスペクトログラムフレームを予測することによる影響についても述べられています。単純にステップ数が、1 /(一度に予測するフレーム数)になるため、学習時間や推論時間が大幅に短縮されることはわかりますが、それに加えて、収束速度も大幅に向上させることができるようです。
理由としては、音声の特性上隣接するフレームが相関していることと、通常は各文字が複数のフレームに対応しているためです。1ステップに1フレームだけだと複数のステップで同じ入力トークンに注意を向ける必要があり、複数フレームの場合は早い段階で注意を前に進めることができるのだとか。
ただ、今回の実装ではこの機能については考えていません。NVIDIAやこちらの書籍の実装では、この機能について考慮されていたので、そちらも見てみてください。
Post-Net
Post-Netというモジュールを用いて残差を予測します。TacotronではGriffin-Limアルゴリズムを用いて音声波形を合成する関係上、振れ幅スペクトログラムを出力するためにPost-Netを用いていたようですが、Tacotron2ではWaveNetをボコーダとして扱うため、PostNetの出力もメルスペクトログラムです。PostNetを用いることでどの程度性能が向上するかについては、よくわかりませんでした。
処理の流れは以下の通りです。
デコーダが予測したメルスペクトログラムを5層の畳み込み(Post-Net)に渡す
Post-Netは5×1の512個のフィルターで構成され、バッチ正規化したのち、最終層を除くすべての層で、Tanh関数で活性化を行う。
なお、Post-Net前と後の平均2乗誤差の合計を最小化するように学習を行います。
実装は以下の通りになります。
# Post-Net
class Postnet(nn.Module):
def __init__(self,
in_dim=80,
layers=5,
embedding_dim=512,
kernel_size=5,
dropout=0.5):
super(Postnet, self).__init__()
postnet = nn.ModuleList()
for layer in range(layers):
# 入力80、中間512、出力80
in_channels = in_dim if layer == 0 else embedding_dim
out_channels = in_dim if layer == layers - 1 else embedding_dim
postnet.append(
nn.Sequential(
nn.Conv1d(in_channels, out_channels,
kernel_size=kernel_size, stride=1,
padding=int((kernel_size - 1) // 2),
dilation=1),
nn.BatchNorm1d(out_channels))
)
# 最終層はTanh関数なし
if layer != layers - 1:
postnet.append(nn.Tanh())
postnet.append(nn.Dropout(dropout))
self.postnet = nn.Sequential(*postnet)
def forward(self, x):
return self.postnet(x)
出力が80次元であることと、最終層のみTanh関数を用いないことだけは注意です。それ以外は特にありません。
Tacotron2クラス
今まで説明したモジュールをまとめたクラスです。学習時はinference関数を呼び出します。
class Tacotron2(nn.Module):
'''
エンコーダ、デコーダ、Post-Netの処理をまとめたもの
学習時と推論時で処理が異なる
'''
def __init__(self):
super(Tacotron2, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.postnet = Postnet()
def forward(self, inputs, input_lengths, decoder_targets):
"""
学習時の処理
PARAMS
-------
inputs: 入力となるテキスト情報(音素列)
input_lengths: 入力の長さ
decoder_targets: 正解となるメルスペクトログラム、(B, n_mel_channels, 系列長)
RETURNS
-------
mel_outputs: メルスペクトログラム
mel_outputs_postnet: メルスペクトログラム(残差接続済み)
gate_outputs: stop token
alignments: アテンション重み
-------
"""
# エンコーダによるテキストの潜在表現の獲得
encoder_outputs = self.encoder.forward(inputs, input_lengths)
# デコーダによるメルスペクトログラム、stop tokenの予測
mel_outputs, gate_outputs, alignments = self.decoder(encoder_outputs, input_lengths, decoder_targets)
# Post-Netによる残差の予測
mel_outputs_postnet = mel_outputs + self.postnet(mel_outputs)
# (B, 80, 出力長) -> (B, 出力長, 80)
mel_outputs = mel_outputs.transpose(2, 1)
mel_outputs_postnet = mel_outputs_postnet.transpose(2, 1)
return mel_outputs, mel_outputs_postnet, gate_outputs, alignments
def inference(self, inputs, input_lengths):
"""
推論時の処理
"""
mel_outputs, mel_outputs_postnet, gate_outputs, alignments = self.forward(inputs, input_lengths, None)
return mel_outputs, mel_outputs_postnet, gate_outputs, alignments
終わりに
最低限の実装について解説してきましたが、機会があれば、学習時や推論時の様子についてもまとめてみたいと思います。