はじめに
株式会社 RetailAI X Advent Calendar 2022 の 8 日目の記事です。
昨日は@tanabe_shogoさんの『Node.jsを使って、BigQueryからデータを取得するWebAPIを作る』でした。
本日は ML エンジニアの@atsukishが担当します。普段は機械学習モデルの開発以外にも、機械学習モデルの安定的な開発・運用基盤である MLOps の開発も担当しております。MLOps については以下の弊社テックブログでわかりやすい解説がありますので、こちらも参照ください。
機械学習モデルを安定的に開発・運用していくためには、MLOps のような機械学習向けの運用基盤が必要となります。次の図に示すように MLOps において機械学習モデルのアルゴリズムに該当するソースコード(ML Code)はごく一部であり、必要となる周辺要素は膨大で複雑です。ML エンジニアなら親の顔より見た図ですね!
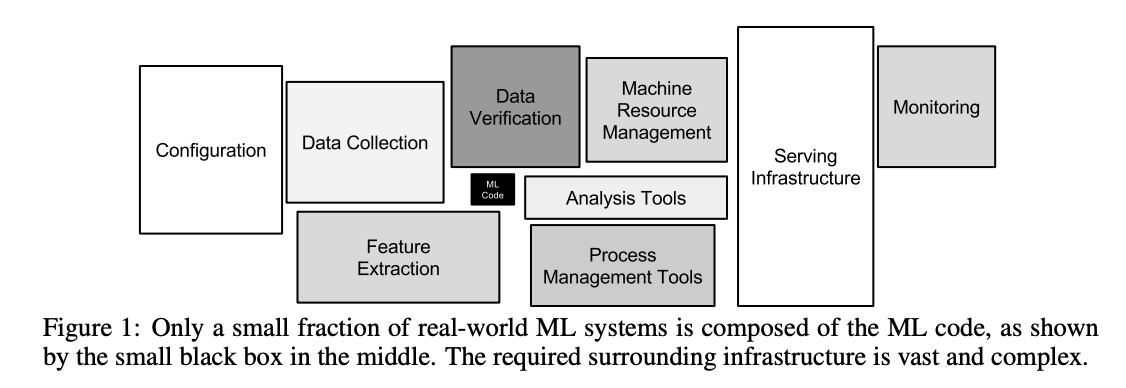
引用:Hidden Technical Debt in Machine Learning Systems
本記事ではこの図が示す周辺要素のうち、継続的なモデル開発のトリガーとなるMonitoringに関して、その重要性や Google Cloud の機械学習マネージドサービスである Vertex AI での導入方法について紹介します。
なお本記事で紹介する『モニタリング』は、機械学習のモデル性能監視を目的としたものを指し、運用基盤のマシンリソースの使用量やレスポンスタイム等のといったインフラリソースのモニタリングについては対象外とします(当然 MLOps で必要なモニタリングではあります)。
機械学習モデルの劣化
御存知の通り、機械学習は過去の経験(=過去のデータ)を元にパターンを学習し、未知のデータに対して予測する、というものです。通常のソフトウェアはエンジニアが実装した通りのアルゴリズムで動作しますが、機械学習はデータから自動的にその特徴を学んで賢くなり、通常のソフトウェアには実現できない高度な予測ができるようになります。
一方で機械学習モデルは、時間の経過とともにモデルの予測精度が劣化することが知られています。その劣化の要因は様々ですが、機械学習モデルを運用している実社会などの環境が大きく変化することが大きな要因といえます。機械学習モデルは過去のデータから特徴を学習しています。当然ながらサービスを展開する本番環境(現在)と過去のデータの傾向が大きく変わってしまった場合、過去のデータで学習したモデルは役に立たず、期待した予測精度を下回ってしまいます。
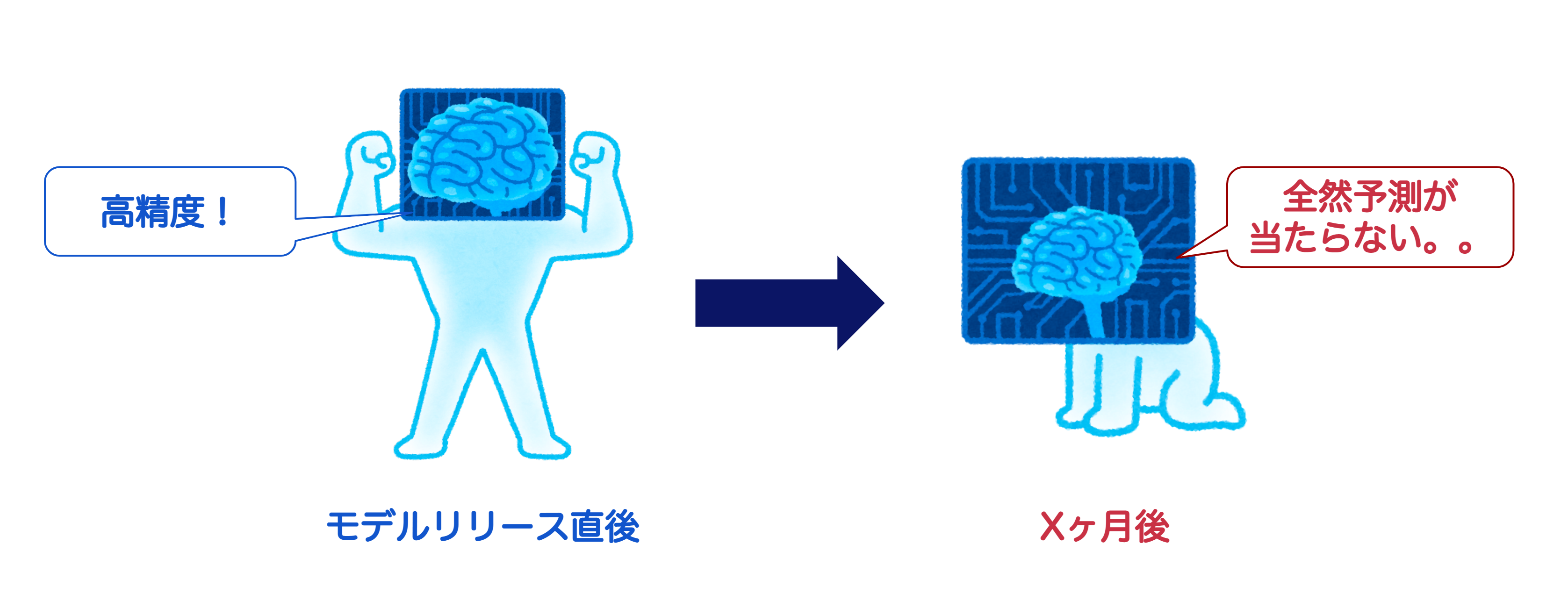
劣化の要因となるデータの変化
では機械学習モデルの劣化の要因となるデータの変化とはどういったものがあるのでしょうか。代表的なケースを紹介します。
Data-Drift
モデル学習時とサービス運用時のデータの統計的分布に予期せぬ違いが生まれて、予測精度が下がる問題です。Google の論文だと "Training-Serving Skew" という表現をすることもあります。例えばみんな大好き「ブラックフライデー」はもともとアメリカの感謝祭(Thanksgiving day)に合わせて開催される商戦イベントでしたが、近年日本でも広まってきました。このような前年までなかった新しい商習慣が登場した場合、以前のデータで学習したモデルでは正確に予測することが難しくなります。他にも Covid19 による人々の生活様式が大きく変わってしまったことで、変化に追従できないモデルも多いことが容易に想像できるかと思います。
また傾向の変化とは異なりますが、モデル学習時とサービス運用時で特徴量を生成するロジックが一貫していないといったシステム上の設計ミスやバグでも同様の問題が発生します。こういった人為的なミスにおいてもリカバリーできるような仕組みは DevOps の観点からも重要です。
Concept-Drift
もう一つは入力データとなる特徴量から予測しようとしている目的変数の意味や概念、特性が変化したことで予測精度が下がる問題です。この具体的例としては、ある決済サービスで不正取引を検知する機械学習モデルを開発し、モデルリリース直後は高い正解率で検知できていたが、時間経過とともに正解率が低下していった。その原因は入力データの統計的分布の変化ではなく、不正取引をするユーザー側の手口がより巧妙化したことで、検知できなかったケースです。このケースだと目的変数である「どういったものが不正取引か?」というデータの意味・解釈が変化したことで、モデルの予測精度の劣化を招いたといえます。
機械学習サービスを実現するため
残念ながら実社会は絶えず変化するため、時間経過に伴う機械学習モデルの劣化を防ぐことはできません。モデルの精度劣化はサービスの質の低下につながるため、本番環境で適切なタイミングでモデルの再学習・デプロイを継続的に行い、運用を続けることが重要です。
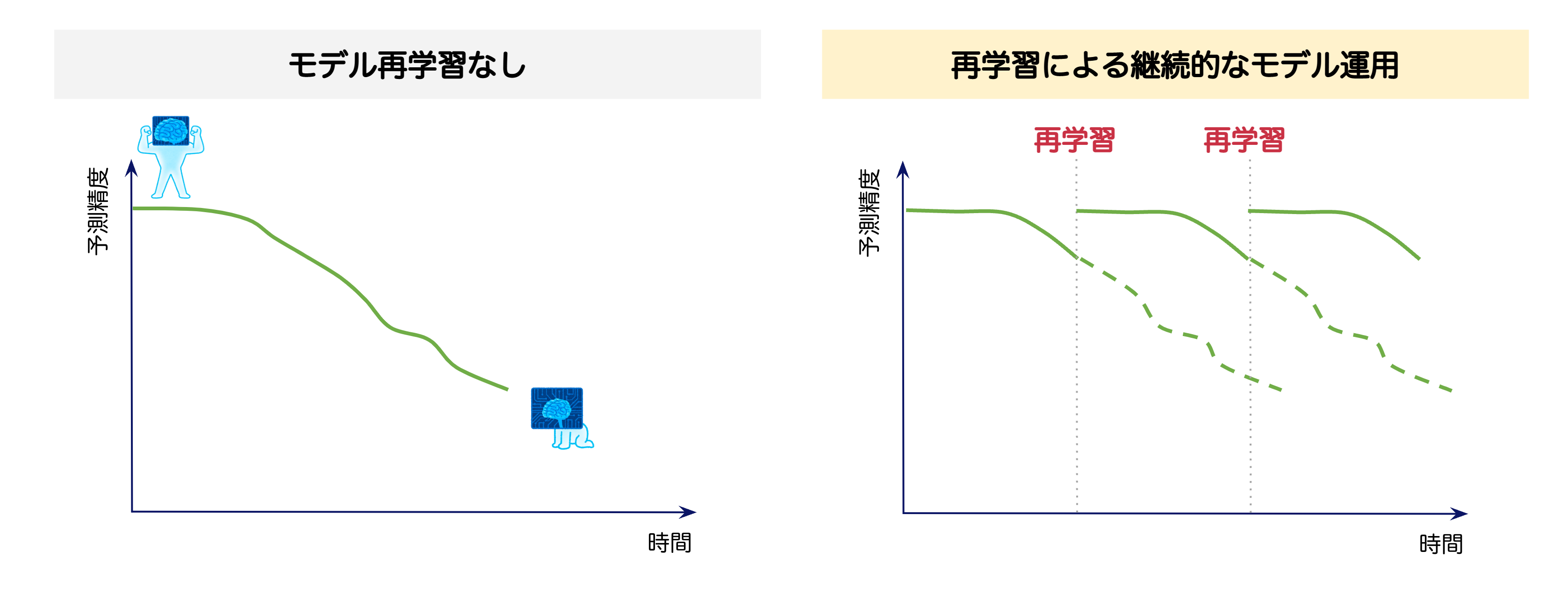
この継続的なモデルの再学習、デプロイを効率的に安定的に実現する仕組みが MLOps というわけです。
機械学習モデルの開発は通常のシステム開発と比較してパラメータチューニングなどの試行錯誤が発生しやすいため、モデル開発プロセスをパイプライン化して効率的したり、DevOps と同様に CI/CD の仕組み等が必要になります。更に再学習のトリガを検知するために、本番環境で運用中のモデルへの入力データや予測結果を常時モニタリングし、データの統計的分布に想定以上の差が生じた場合、アラートを出す仕組みが重要になります。
- 機械学習モデル開発プロセスのパイプライン化
- 継続的インテグレーション、継続的デリバリーの構築(CI/CD)
- 継続的なデータ収集・加工プロセスの構築、データストアの用意
- 運用モデルの入力データや予測結果のモニタリングによる再学習トリガーの検知
Vertex AI を活用したモデルモニタリング
ここからは運用を想定した機械学習モデルのモニタリングを Google Cloud の機械学習・AI 向け統合プラットフォーム Vertex AI で実現する方法を紹介します。このモニタリングを実現する Vertex AI Model Monitoringというサービスでは、以下の 3 つの特徴があります。
- Vertex AI のオンライン予測サービス Vertex Predictionにデプロイされたモデルの性能変化を検出
- 推論リクエストである特徴量のドリフトを検出し、アラートを送信
- コンソール UI で特徴量の分布とその変化を可視化
なお Vertex AI のバッチ予測サービスである Vertex Batch Prediction 向けのモデルモニタリングは2022 年 12 月時点で Preview 版となっています
ドリフト検出方法
Vertex AI Model Monitoring では、数値型 or カテゴリ型の特徴量に対してドリフト検出が可能です。
まずモニタリング対象のベースラインとなる学習データから特徴量分布を計算します。学習データは以下のデータソースからインポートすることができます。
- Cloud Storage データファイル(csv 形式 or TFRecord 形式)
- BigQuery テーブル
- Vertex AI データセット
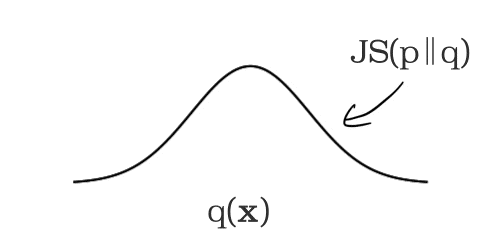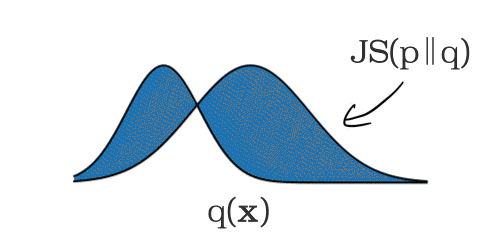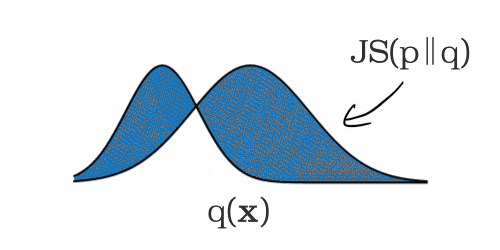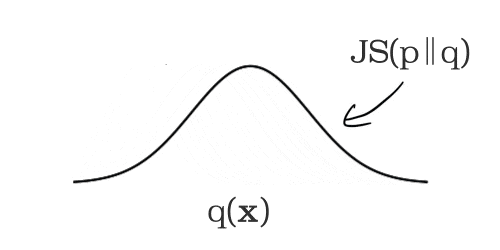
モデルのサービングが開始されると、予測リクエスト時に入力された特徴量データが指定した任意の時間間隔で記録されます。その時間枠においてモニタリング対象の各特徴量の分布が計算され、前述したベースライン分布との差(距離)が計算されます。このとき、数値型の特徴量には JS divergence を、カテゴリ型の特徴量には チェビシェフ距離(L∞ 距離)が用いられます。この距離が設定した閾値を超えた場合、モデル学習時と運用時でドリフトが発生したと判定します。
モデルモニタリングのデプロイ方法
このモデルモニタリング機能は、Vertex Prediction のエンドポイントとしてデプロイすれば、gcloud CLI によるコマンドを 1 回実行するだけでモニタリング機能が利用できます。自分たちで 1 からモニタリングサービスを構築するとなると、ドリフト検出のロジックや可視化ダッシュボードの実装からデータストア、マシンリソースのインフラの割当など色々必要になりますが、マネージドサービスだとすぐ開始できる点は素晴らしいですね!
$ gcloud ai model-monitoring-jobs create \
--project=<PROJECT_ID> \
--region=<REGION> \
--display-name=<MONITORING_JOB_NAME> \
--emails=<EMAIL_ADDRESS_1,EMAIL_ADDRESS_2> \
--endpoint=<ENDPOINT_ID> \
--feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \
--prediction-sampling-rate=<SAMPLING_RATE> \
--monitoring-frequency=<MONITORING_FREQUENCY> \
--target-field=<TARGET_FIELD> \
--bigquery-uri=<BIGQUERY_URI>
詳細はGoogle Cloud の公式ドキュメントを参照していただきたいのですが、主なパラメータは以下のとおりです。
-
emails: アラートを受け取るメールアドレスを指定 -
prediction-sampling-rate: モニタリング用にサンプリングする予測リクエストの割合を指定 -
feature-thresholds: モニタリングする特徴量とそのアラートを出す閾値を指定 -
monitoring-frequency: モニタリング間隔を指定(1 時間単位で設定可能) -
target-field: モデルが予測する目的変数のフィールド名(ラベル名)
モニタリング結果の可視化
ここからはオープンデータセットであるAdult Census Income Dataset を使った試作デモ結果を紹介します。
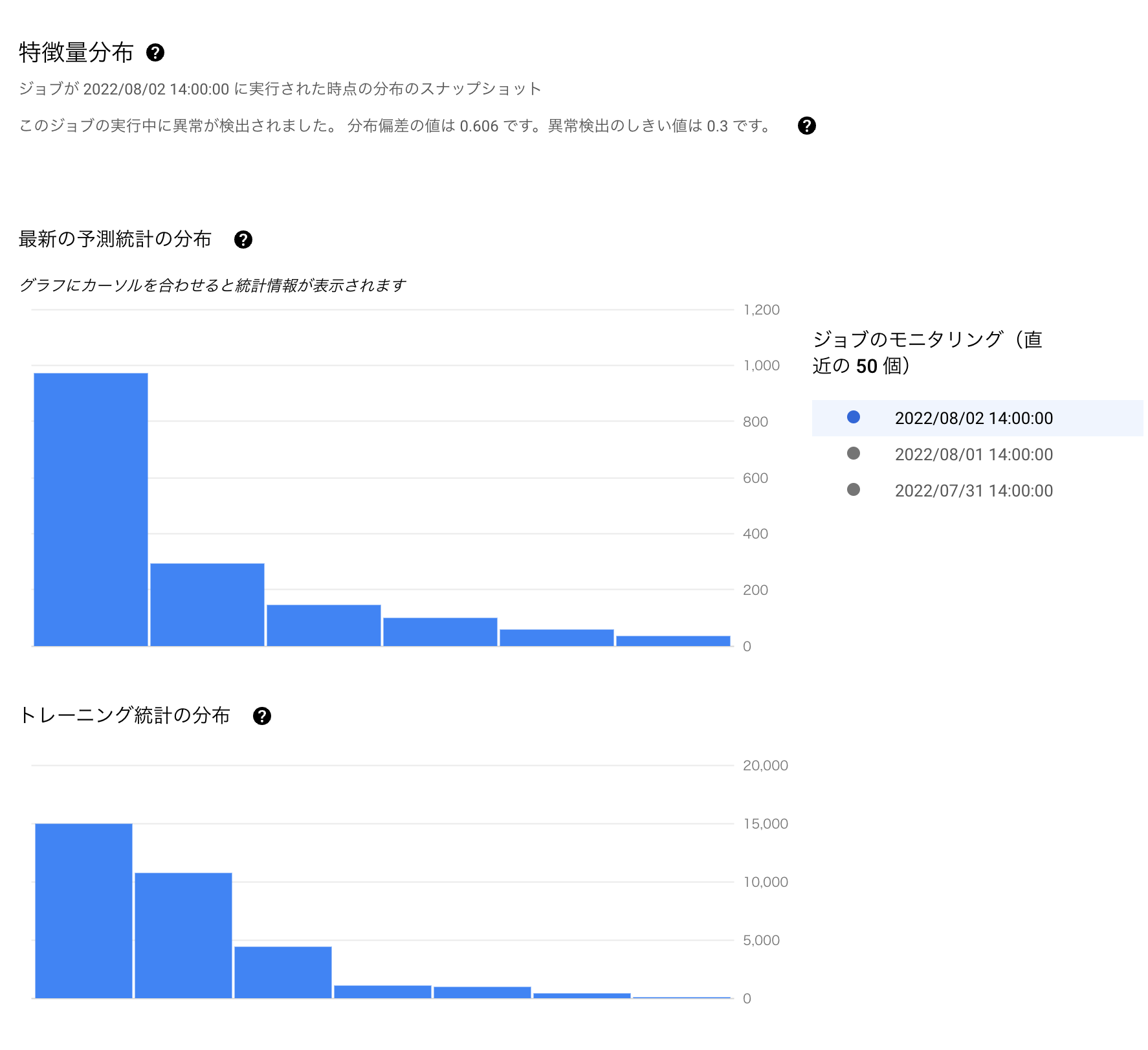
モニタリング結果は Google Cloud の Web コンソールからダッシュボードで確認できます。事前に特徴量ごとにモニタリング結果を表示し、設定した閾値を超えた場合、アラートとしてダッシュボードに表示します。以下は意図的に元のデータセットとは大きく特徴の異なるデータを予測リクエストした際のモニタリング結果です。
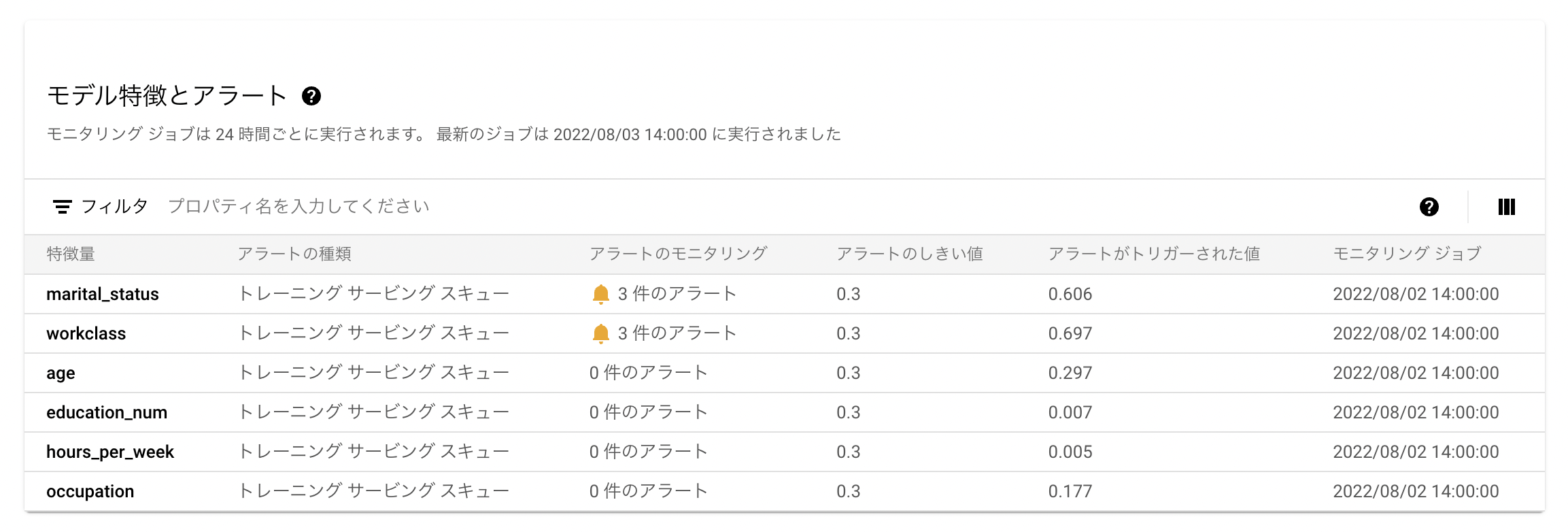
更に特徴量ごとに統計分布のヒストグラムも可視化され、ベースラインと予測リクエストの分布の比較もできます。アラートが出た場合、データサイエンティストや ML エンジニアはこのダッシュボードを参照することで、モデル再学習の要否の判断が可能となります。
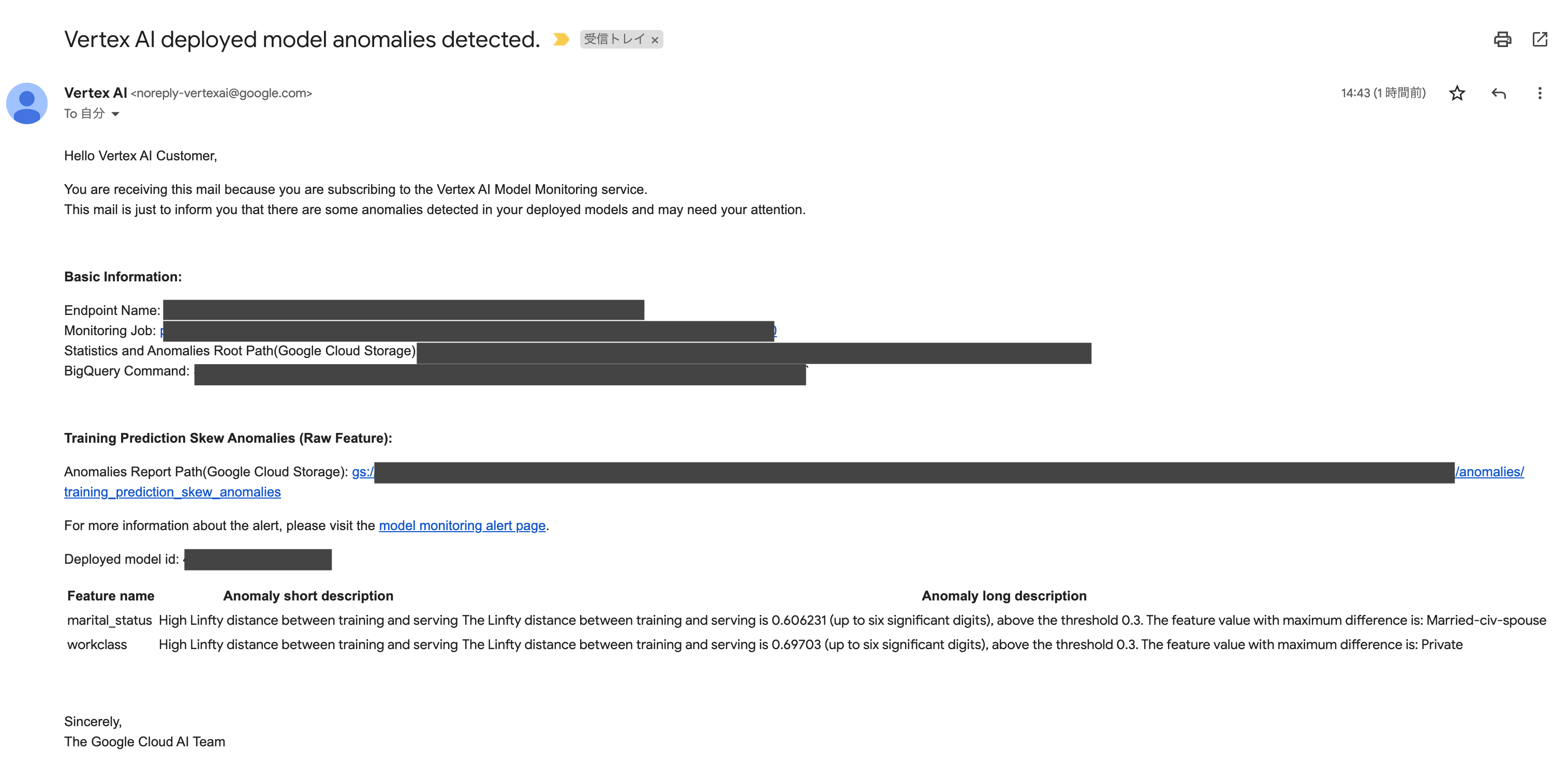
アラート通知
ドリフトを検知すると設定したメールアドレスにアラートの旨を伝えるメールが届きます。
モニタリングサービスを自作するには?
一方で、そもそも機械学習モデルの開発基盤を Google Cloud 上に構築していないケースや、予測サービングのエンドポイントを GKE や Cloud Run 等の他のサービスにデプロイしているケース、ドリフト検知手法を別のロジックにしたい、アラート通知を slack にしたい等々のカスタマイズしたいケースでは現状は Vertex AI Model Monitoring は利用できません。
そんなケースでも、以下の様なパイプラインを任意のモニタリング間隔で定期実行するサービスを実装してしまえば、それほど難しいことはないかもしれません。
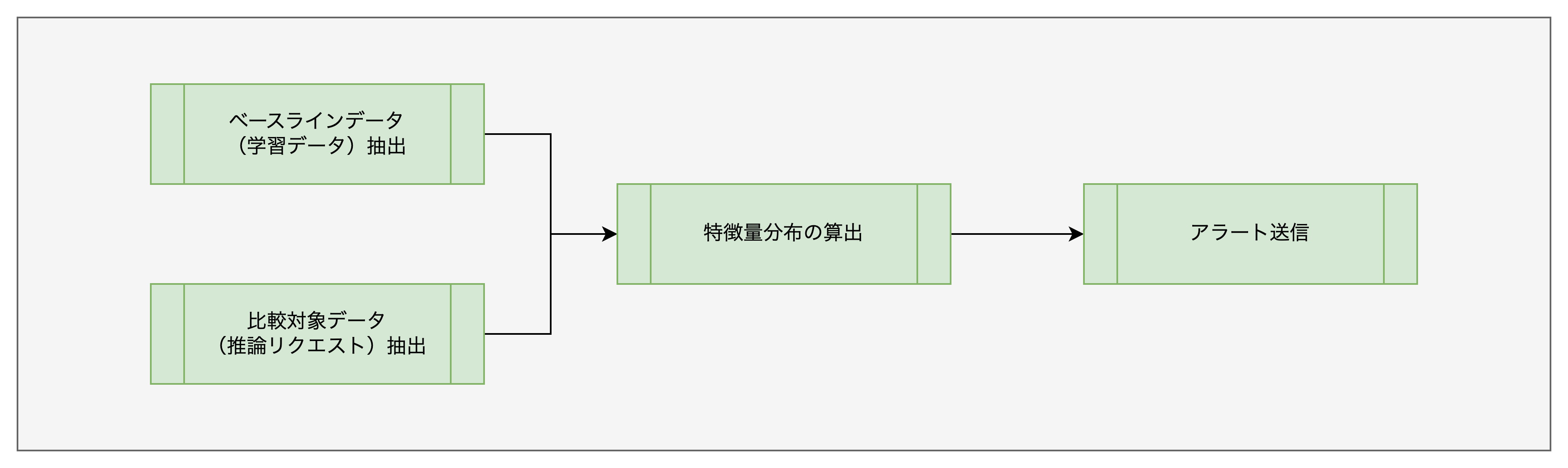
仮に Google Cloud 上にモニタリングサービスを実装すると、以下のサービスが候補になるかと思います。
- データストア:BigQuery、GCS
- パイプライン:Vertex AI Pipelines(Kubeflow Pipelines)
- スケジューラー:Cloud Scheduler + Cloud Functions
まとめ
本記事では MLOps におけるモニタリングの重要性と、Vertex AI によるモデルモニタリングの構築方法について紹介しました。機械学習を活用したサービスはモデル構築がゴールではなく、継続的にサービスを運用していくために、適切なモデルをデプロイし続ける必要があります。モニタリングを含め、そのプロセスを継続的、かつ安定的に提供する MLOps を目指していきたいと思います。
明日 9 日目は、実は同期入社!@uwattotaitaiさんの『Rust UIライブラリ「Dioxus」をReact+Typescriptと比較してみた』です。