はじめに
この記事は、自己学習で行ったデータ基盤構築についての備忘録となります。GCPの公式ドキュメントを参考に作業を行いました。もし、似たようなことをやりたい場合は公式ドキュメントの方を参考にすることをお勧めします。
(参考URL)https://cloud.google.com/scheduler/docs/tut-pub-sub?hl=ja
また、この記事の内容はGCPの無料枠では収まらない(と思う)のでご注意をお願いします。
記事の中にクローリング、スクレイピングをするコードがありますが、実際に行う場合は自己責任でお願いいたします。
なお、プロジェクトはすでに作成してあるものとします。
※内容は2022年5月時点のものです。
1. 作成した分析基盤について
以下のようなデータ基盤を作成しました。
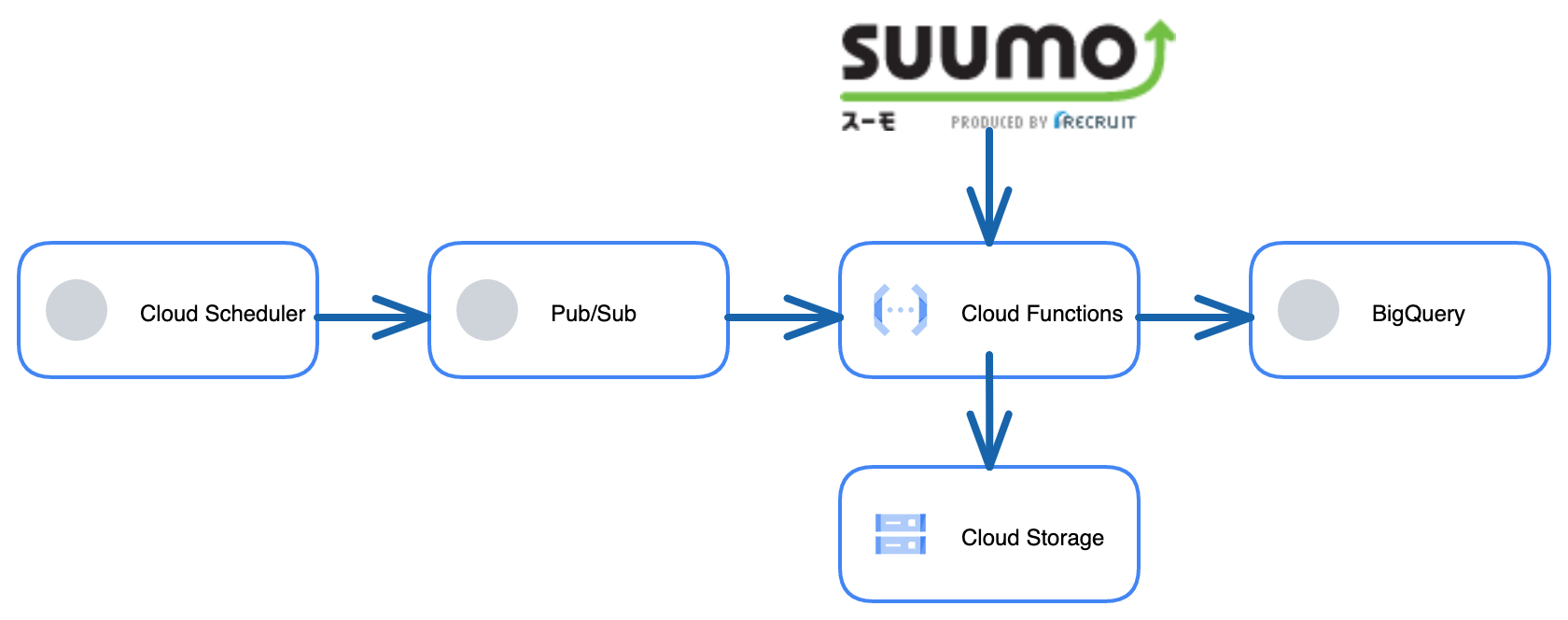
データの流れは以下の通りです。
① Cloud Schedulerが毎日12:00にPub/Subへ通知を送ります
② 通知を受け取ったPub/SubがCloud Functionsを起動させます
③ Cloud Functionsはsuumoから押上駅周辺の「本日の新着」物件の情報をスクレイピングします
④ スクレイピングされたデータはCloud Functions上で最低限の前処理 (不要な文字列の削除など) を行いBigQueryのテーブルへ挿入されます。また、データはCloud Storageにバックアップとしてcsvファイルでも保存されます。
2. BigQueryでテーブルの作成
まずは、スクレイピングしたデータを保存するためのテーブルを作成します。まずはデータセットの作成です。
GCPのページのナビゲーションメニューからBigQueryをクリックするとBigQueryのページに遷移します。BigQueryのページのエクスプローラの欄に自分のプロジェクトの名前があります。プロジェクト名の横の ︙ をクリックしデータセットの作成をクリックします。
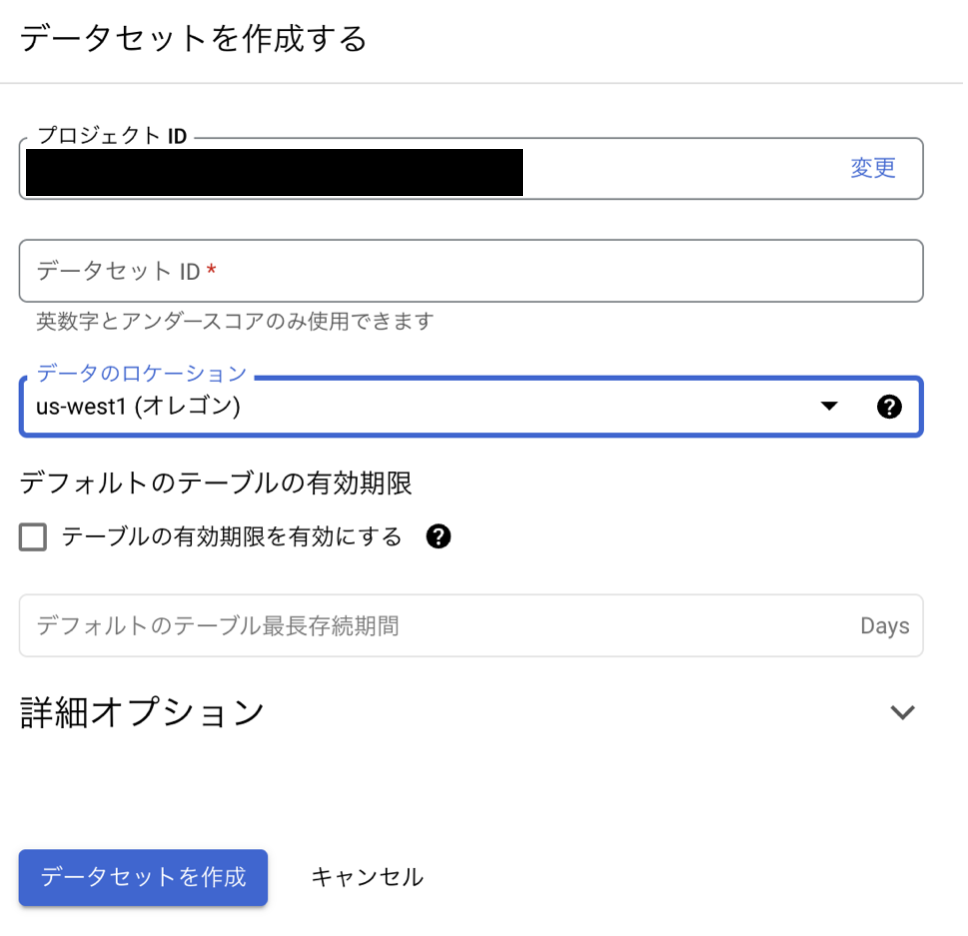
このような画面が出てくるのでデータセットIDにデータセットの名前を入力します。その後データのロケーションも選択します。この記事ではus-west1(オレゴン)を選択しました。
データセットが作成されるとエクスプローラーの欄に作ったデータセットの名前も表示されます。
続いてテーブルの作成を行います。
まずは、データセットを作った時と同じように、今度はエクスプローラ欄のテーブルの名前の横の ︙ をクリックしテーブルの作成をクリックします。
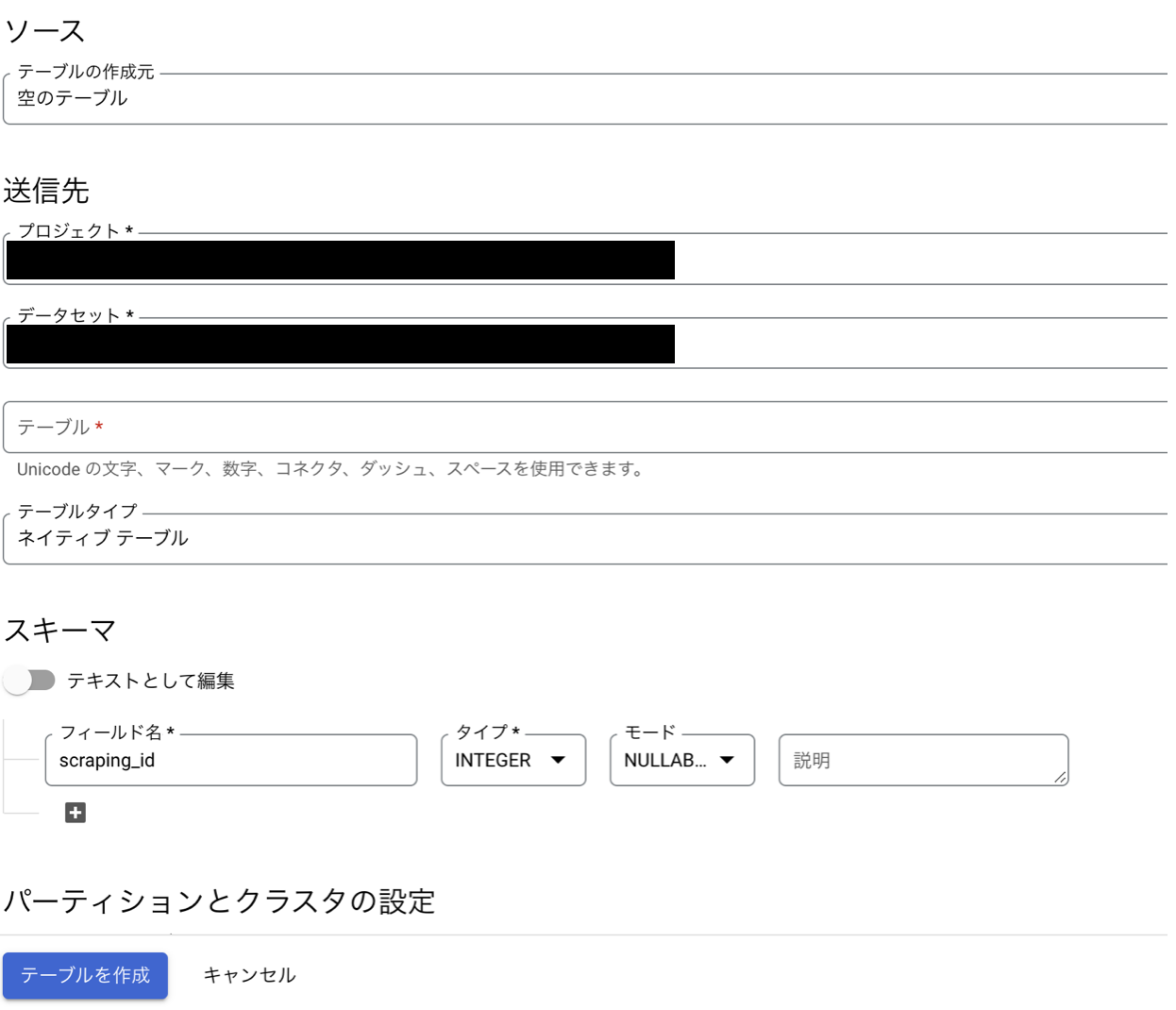
もし、あらかじめCloud storageにデータがあり、それをもとにテーブルを作る場合はテーブルの作成元の欄でCloud storageを選び、「GCPバケットからファイルを選択するか...」の参照からファイルを選択します。送信先のテーブルの欄にテーブル名を記載し、スキーマの自動検出にチェックを入れテーブルの作成を押すことでテーブルの作成を行うことができます。
1からテーブルを作る場合はテーブルの作成元の欄は空のテーブルのまま、送信先のテーブル欄にテーブル名を入力し、スキーマの編集を行います。スキーマの欄の + をクリックすることでフィールドを追加することができます。
今回作成したテーブルのスキーマは次のようになります。
| フィールド名 | タイプ | モード |
|---|---|---|
| scraping_id | INTEGER | NULLABLE |
| scraping_date | DATE | NULLABLE |
| name | STRING | NULLABLE |
| price_10k | FLOAT | NULLABLE |
| age_year | FLOAT | NULLABLE |
| admin_fee | FLOAT | NULLABLE |
| sikikin_10k | FLOAT | NULLABLE |
| reikin_10k | FLOAT | NULLABLE |
| deposit_10k | FLOAT | NULLABLE |
| sikibiki_10k | STRING(※) | NULLABLE |
| line | STRING | NULLABLE |
| station | STRING | NULLABLE |
| move | STRING | NULLABLE |
| time_to_station | FLOAT | NULLABLE |
| room | STRING | NULLABLE |
| area_m2 | FLOAT | NULLABLE |
| direction | STRING | NULLABLE |
| type | STRING | NULLABLE |
| address | STRING | NULLABLE |
※まれに「実費」という文字列データが出現するのでSTRING型に設定した
3. Cloud Storageでバケットの作成
スクレイピングしたデータのcsvファイルを保存するためのバケットを作成します。
ナビゲーションメニューからCloud Storageを選択し、遷移先のページでバケットの作成をクリックします。
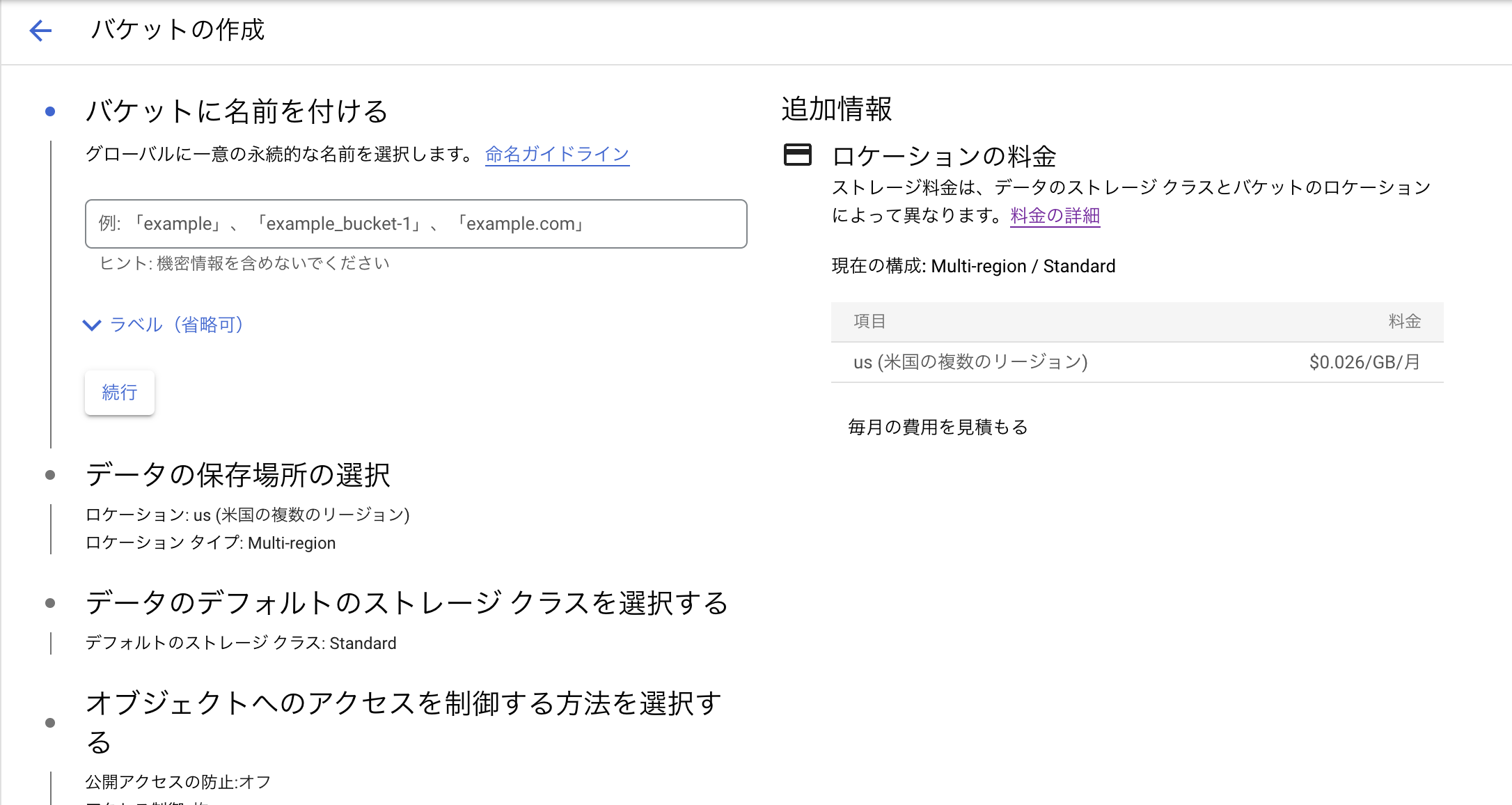
まずはバケットに名前をつけます。これは固有の名前を付ける必要があります。
次にデータの保存場所の選択をします。今回はロケーションタイプはRegionでus-west1(オレゴン)を選択しました。あとの設定はデフォルトのまま作成しました。
バケットを作成したら、バケット内にデータを入れるためのフォルダを作成します。

フォルダを作成をクリックすることでフォルダの作成を行えます。今回はdataという名前でフォルダを作成しました。
4. Cloud Functionsの設定
① 構成の設定
スクレイピングを実行するCloud Functionsの設定を行います。
ナビゲーションメニューからCloud Functionsを選択し、遷移先のページで関数の作成をクリックします。
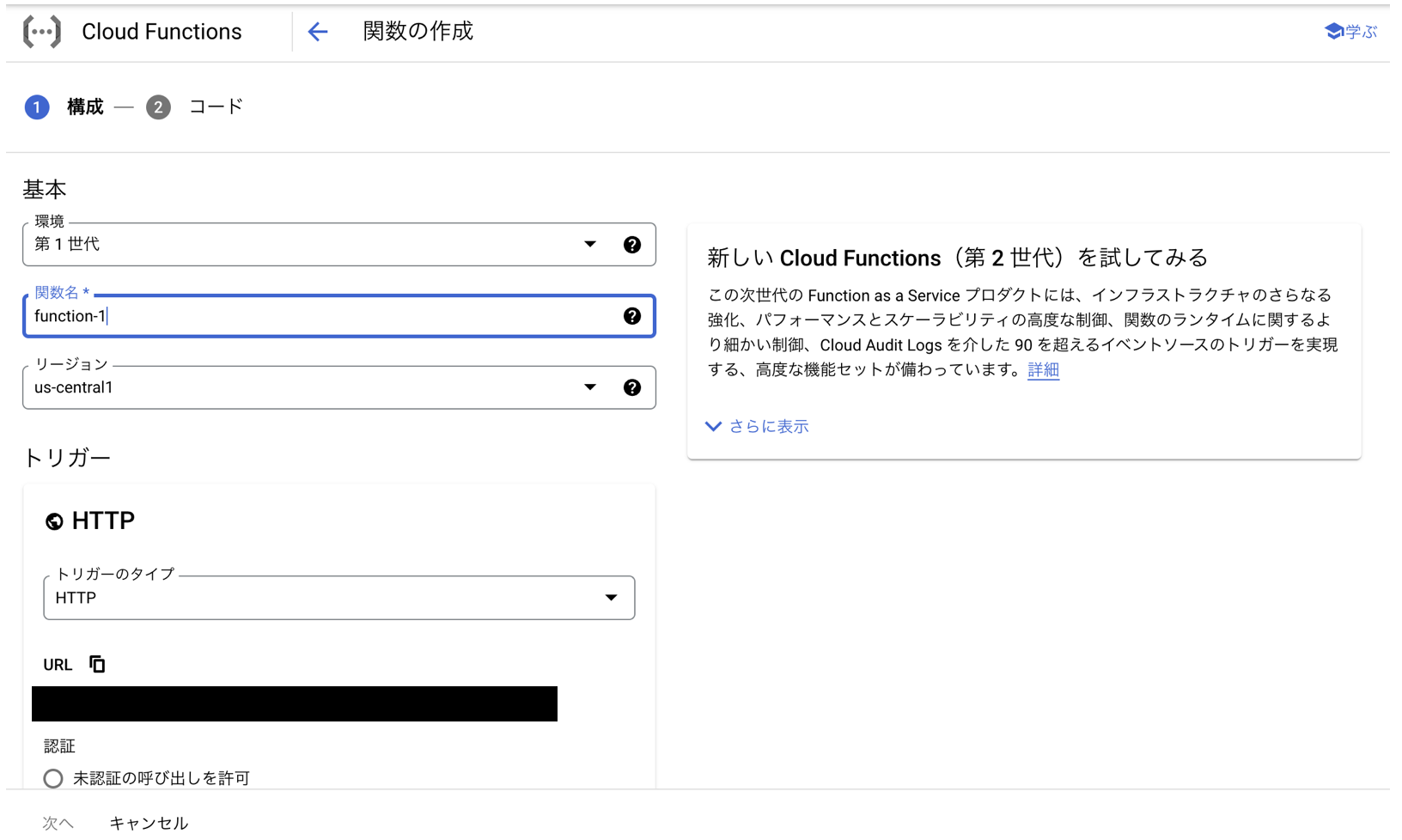
環境は第1世代を選択しました。関数名には関数名を入力します。リージョンはus-west1を選択しました。
トリガーについてですが今回はPub/Subからの通知で関数を動かすのでトリガーのタイプはCloud Pub/Subを選択します。
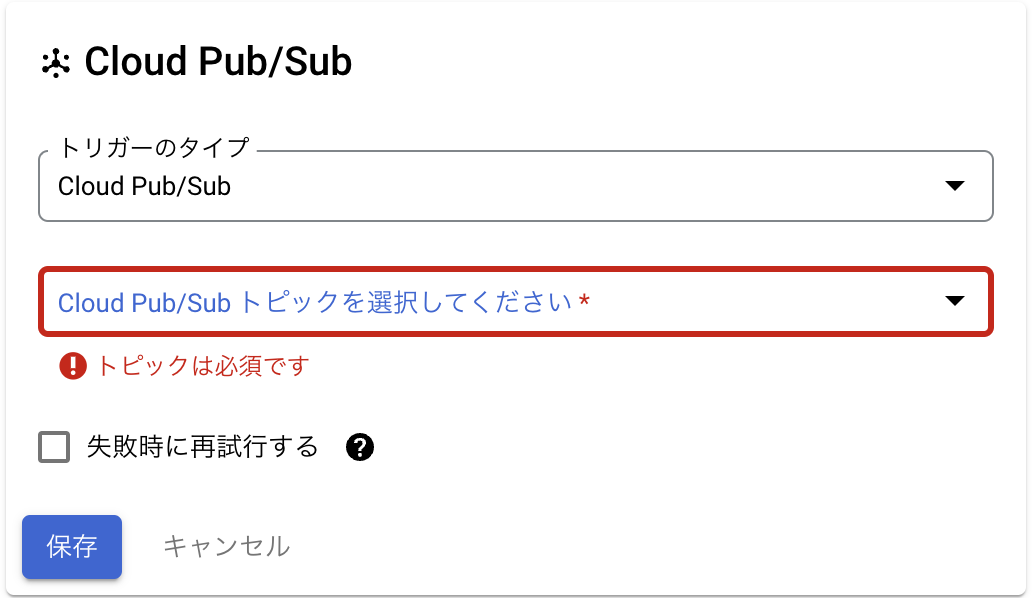
Cloud Pub/Subトピックを選択してくださいとありますが、現時点ではトピックはないので新たに作成する必要があります。▼をクリックしトピックを作成するをクリックします。トピックIDを入力する欄があるのでトピックIDを入力し保存をクリックします。
ランタイム、ビルド、接続、セキュリティの設定についてですが、今回の内容では割り当てられるメモリが512MB、タイムアウトは300で設定しました。特にメモリは512MBないとエラーが出てしまうので変更は必須です。
② コード
保存が終わったらコードのタブに切り替え、コードの設定を行っていきます。
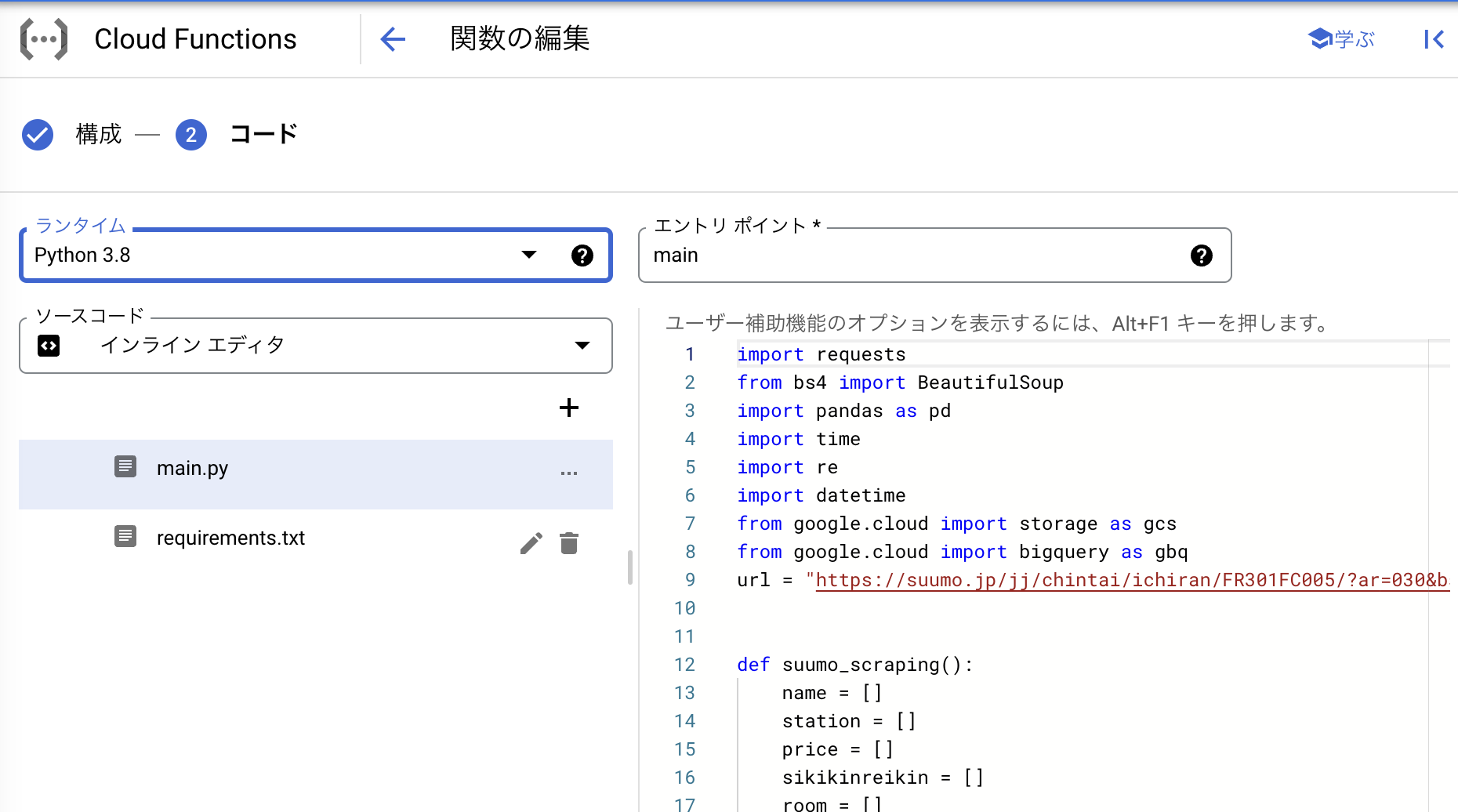
ランタイムは、今回はPythonのコードを実行するのでPython3.8を選択しました。コードは上の図の右下の欄に記載していきます。
以下は今回作成したコードとなります。コードの詳しい内容の説明に関しては割愛します。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import re
import datetime
from google.cloud import storage as gcs # gcsへデータを送るのに必要
from google.cloud import bigquery as gbq # BigQueryのテーブルにデータを挿入するのに必要
# スクレイピングの開始点のURL
url = "https://suumo.jp/jj/chintai/ichiran/FR301FC005/?ar=030&bs=040&ra=013&rn=0045&ek=004506820&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&po2=99&pc=100"
# スクレイピングを実行する関数
def suumo_scraping():
name = []
station = []
price = []
sikikinreikin = []
room = []
age = []
address = []
count_new_list = []
urls=requests.get(url)
# 連続してアクセスするのを防ぐために3秒待つ
time.sleep(3)
urls.encoding = urls.apparent_encoding
soup=BeautifulSoup()
soup=BeautifulSoup(urls.content,"html.parser")
get_url = soup.find("ol",class_="pagination-parts")
# 物件のページ数を取得
num_list =[]
for i in get_url.find_all("li"):
num_list.append(i.text)
num = int(num_list[10]) + 1
# ページ数分だけスクレイピングを実行
for p in range(1,num):
page=str(p)
url_2="https://suumo.jp/jj/chintai/ichiran/FR301FC005/?ar=030&bs=040&ra=013&rn=0045&ek=004506820&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&po2=99&pc=100" + "&page=" + page
urls=requests.get(url_2)
# 連続してアクセスするのを防ぐために3秒待つ
time.sleep(3)
soup=BeautifulSoup(urls.content,"html.parser")
# 「本日の新着」「新着」のタグを検索
house_info = soup.find_all("span",class_="ellipse_pct ellipse_pct--red")
# 「本日の新着」「新着」のタグの中で「本日の新着」の数をカウント
count_new = 0
for i in house_info:
if i.text == "本日の新着":
count_new += 1
count_new_list.append(count_new)
# ページ内の「本日の新着」の数が0でないならスクレイピングを実行
if count_new != 0:
house_name = soup.find_all("a",class_="js-cassetLinkHref")
station_name = soup.find_all("div",style="font-weight:bold")
table_data = pd.read_html(urls.content)
for h in house_name:
name.append(h.text)
for s in station_name:
station.append(s.text)
for i in range(0,count_new):
table = table_data[i]
price.append(table.iloc[0,0])
room.append(table.iloc[0,2])
age.append(table.iloc[0,3])
address.append(table.iloc[0,4])
sikikinreikin.append(table.iloc[0,1])
# ページ内の「本日の新着」が0ならスクレイピングをやめる
else:
break
return name, station, price, sikikinreikin, room, age, address, count_new_list
# 前処理を実行する関数 スクレイピングの際に余計な空白等がついてくるのでここで除去する
# このコードだけだとイメージしにくい。手元の環境でデータを見ながらのほうがイメージしやすい
def preprocessing(name, station, price, sikikinreikin, room, age, address, count_new_list):
station_line_list = []
time_move_list = []
for i in station:
station_line_list.append(i.split(" ")[0])
time_move_list.append(i.split(" ")[1])
station_list = []
line_list = []
for i in station_line_list:
station_list.append(i.split("/")[1])
line_list.append(i.split("/")[0])
move_list =[]
time_list = []
for i in time_move_list:
if "歩" in i:
move_list.append("徒歩")
time_list.append(re.sub(r"\D", "", i))
else:
move_list.append("バス")
time_list.append(re.sub(r"\D", "", i))
df=pd.DataFrame()
df["station"] = pd.Series(station_list)
df["line"] = pd.Series(line_list)
df["move"] = pd.Series(move_list)
df["time_to_station_min"] = pd.Series(time_list).astype(float)
price_list = []
admin_list = []
for i in price:
price_list.append(i.split(" ")[0].replace("万円",""))
admin_list.append(i.split(" ")[3].replace("円",""))
admin_fee_list = []
for i in admin_list:
if i == "-":
admin_fee_list.append("0")
else:
admin_fee_list.append(i)
df["price_10k"] = pd.Series(price_list).astype(float)
df["admin_fee"] = pd.Series(admin_fee_list).astype(float)
sikikin_pre = []
reikin_pre = []
deposit_pre = []
sikibiki_pre = []
for i in sikikinreikin:
sikikin_pre.append(i.split(" ")[0])
reikin_pre.append(i.split(" ")[2])
deposit_pre.append(i.split(" ")[4])
sikibiki_pre.append(i.split(" ")[6])
sikikin_list = []
reikin_list = []
deposit_list = []
sikibiki_list = []
for i in sikikin_pre:
a = i.split("敷")[1]
if "万円" in a:
sikikin_list.append(a.replace("万円",""))
else:
sikikin_list.append(0)
for i in reikin_pre:
a = i.split('礼')[1]
if "万円" in a:
reikin_list.append(a.replace("万円",""))
else:
reikin_list.append(0)
for i in deposit_pre:
a = i.split('\xa0')[1]
if "万円" in a:
deposit_list.append(a.replace("万円",""))
else:
deposit_list.append(0)
for i in sikibiki_pre:
a = i.split("\xa0")[1]
if "万円" in a:
sikibiki_list.append(a.replace("万円",""))
elif "-" in a:
sikibiki_list.append(0)
else:
sikibiki_list.append("実費")
df["sikikin_10k"] = pd.Series(sikikin_list).astype(float)
df["reikin_10k"] = pd.Series(reikin_list).astype(float)
df["deposit_10k"] = pd.Series(deposit_list).astype(float)
df["sikibiki_10k"] = pd.Series(sikibiki_list)
room_list = []
area_pre = []
direction_pre = []
for i in room:
room_list.append(i.split(" ")[0])
area_pre.append(i.split(" ")[2])
direction_pre.append(i.split(" ")[4])
area_list = []
for i in area_pre:
area_list.append(i.replace("m2",""))
df["room"] = pd.Series(room_list)
df["area_m2"] = pd.Series(area_list)
df["direction"] = pd.Series(direction_pre)
type_list = []
age_pre = []
for i in age:
type_list.append(i.split(" ")[0])
age_pre.append(i.split(" ")[2])
age_list = []
for i in age_pre:
if i == "新築":
age_list.append(0)
else:
age_list.append(re.sub(r"\D", "", i))
df["type"] = pd.Series(type_list)
df["age_year"] = pd.Series(age_list).astype(float)
df["scraping_date"] = datetime.date.today()
df["name"] = pd.Series(name)
df["address"] = pd.Series(address)
id_range = 0
for i in count_new_list:
id_range = i + id_range
id_list = []
to_day = str(datetime.date.today())
to_day = to_day.replace("-","")
for i in range(0,id_range):
if i < 10:
i = str(i)
id_list.append(to_day + "000" + i)
elif i >= 10 and i < 100:
i = str(i)
id_list.append(to_day + "00" + i)
elif i >= 100 and i < 1000:
i = str(i)
id_list.append(to_day + "0" + i)
else:
i = str(i)
id_list.append(to_day + i)
df["scraping_id"] = pd.Series(id_list)
df = df.reindex(columns=["scraping_id","scraping_date","name","price_10k","age_year","admin_fee","sikikin_10k","reikin_10k","deposit_10k","sikibiki_10k","line","station","move","time_to_station_min","room","area_m2","direction","type","address"])
# 最後のページのスクレイピングでは「本日の新着」以外のデータも混ざっている
# pd.read_html(urls.content)で取得した賃貸価格など
# それ以外で取得した物件名などは「本日の新着」分のデータしか取得していないのでNULLの部分が出てくる
# NULLが入っているデータは余分なデータなので削除する
df.dropna(inplace=True)
return df
# データをGCSへcsvファイルで保存する関数
def send_storage(df):
project_id = "プロジェクト名"
bucket_name = "バケット名"
gcs_path_1 = "data/suumo_data" # ファイルまでのパス
# ファイル名でスクレイピングした日付がわかるようにする
to_day = str(datetime.date.today())
to_day = to_day.replace("-","")
client = gcs.Client()
bucket = client.get_bucket(bucket_name)
blob_gcs_1 = bucket.blob(gcs_path_1 + "_" + to_day + ".csv")
blob_gcs_1.upload_from_string(data=df.to_csv(index=False))
# BigQueryのテーブルにデータをインサートする関数
def bigquery_insert(df):
client = gbq.Client()
table = client.get_table("テーブルID")
client.insert_rows(table, df.values.tolist())
# Cloud Functionで実行する関数
def main(event, context):
name, station, price, sikikinreikin, room, age, address, count_new_list = suumo_scraping()
df = preprocessing(name, station, price, sikikinreikin, room, age, address, count_new_list)
send_storage(df)
bigquery_insert(df)
実行する場合は、プロジェクト名、バケット名、ファイルまでのパス、テーブルIDはそれぞれ自分のものに変える必要があります。
main.pyの編集が終わったので次はrequirements.txtの編集を行います。
requirements.txtではmain.pyで使用する外部ライブラリについて、どのバージョンをインストールするか指定する必要があります。
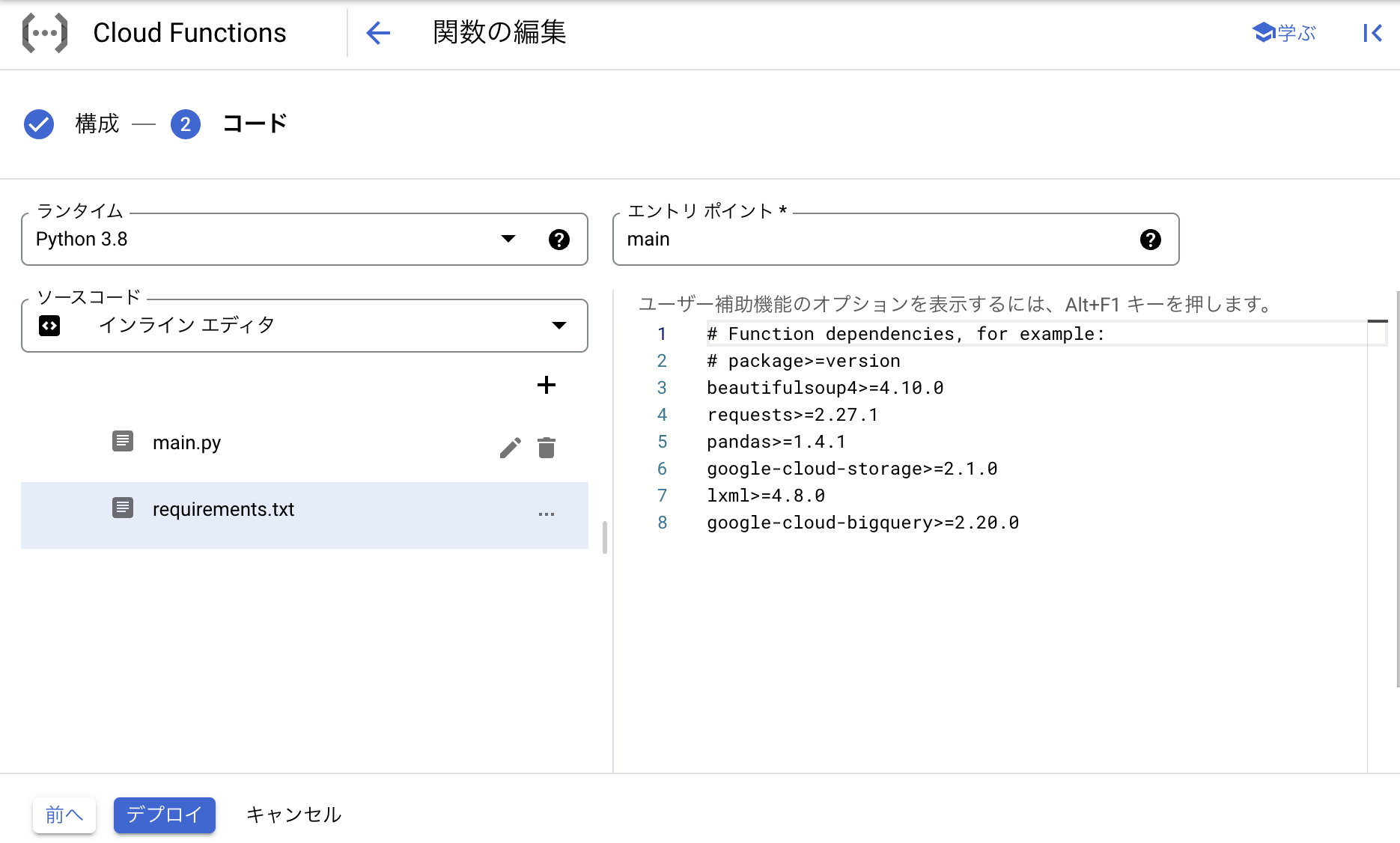
使用したい外部ライブラリがある場合は
beautifulsoup4>=4.10.0 のように記載する必要があります。
今回の作業で使用したライブラリとそのバージョンは上の図の通りです。
ここまで記述できたら、エントリポイントにmain.pyで実行したい関数名を入力します。今回の場合はmainを実行したいのでmainと入力しました。
最後にデブロイをクリックすることで関数の登録ができます。しばらく待って、正常にデブロイできているか確認してください。もし、この時点でコード等に不備がある場合はエラーが出ると思います。
デブロイができたら関数のテストを行います。
︙ をクリックし、関数のテストをクリックします。
無事にテストが終われば、GCSにcsvファイルが保存され、BigQueryのテーブルにデータが挿入されているのが確認できると思います。
5. Cloud Schedulerの設定
Cloud Schedulerは時間を設定することで定期的にジョブを実行することができます。
Cloud Schedulerを使うことで、先ほど作ったPub/Subトピックに定期的に通知を送り、Cloud Functionsの関数を実行することができます。
Cloud Schedulerの設定を行います。
ナビゲーションメニューからCloud Schedulerを選択し、ジョブの作成をクリックします。
名前はschedulerの名前です。リージョンは今回はus-west1を選択しました。
頻度についてですが、ジョブの頻度をunix-cron形式で指定する必要があります。unix-cron形式については詳しくは記載しませんが、今回の例では毎日12時ごろに実行したかったので 0 12 * * * と入力しました。
タイムゾーンについては 日本標準時(JST)を選択しました。
ターゲットタイプはPub/Subを選択します。選択するとトピックを選択する欄が出てくるので、先ほどCloud schedulerの設定を行った際に作ったPub/Subトピックを選択します。メッセージ本文については {} を入力しました。オプションについては、今回はデフォルトのままで行いました。
すべての設定が終わったら画面下の作成をクリックします。
作成後はジョブが正常に動作するかテストを行います。
テストを行う前に先ほどCloud Functionsのテストで生成されたGCSのcsvファイルとBigQueryのテーブルに挿入されたデータは削除しておくとわかりやすいかもしれません。
︙ をクリックし、ジョブを強制実行するを押すと先ほどunix-cron形式で設定した時間に関わらずジョブを実行できます。
正常に動作すれば、GCSにcsvファイルが保存され、BigQueryのテーブルにデータが挿入されているはずです。
また、Cloud Functionsではログを見ることができるので、それを確認することでもうまく実行できたかを知ることができます。
ログはCloud Functionsの名前をクリック→ログのタブを押すことで見ることができます。
6. 最後に
Cloud schedulerのページで先ほど作ったジョブの選択し、▶︎再開を押します。何も問題がなければ毎日12時にCloud Schedulerが起動し次々とデータを収集できるようになっていると思います。
1ヶ月弱ほど動かしましたが、正常にデータの収取が行われているので問題はないかと思います。