ラノベは全く範疇外で読んだことないんですが、
文章生成AIのGPT-2を触っていて試しに何か生成できないかなと考えた時に、
本屋に行くとよく見かける面白いタイトルの文庫のことを思い出し、
せっかくなのでそのタイトルを学習させて生成してみようと思い至りました。
GPT2について
まずGPT2ですが、OpenAIが作った自然言語モデルで、
発表当時はフェイクニュースに使用される危険性等で話題になったようです。
本家は英語ですが日本語のモデルを作成するプロジェクトがあり、
今回は日本語版のGPT2-Japaneseを使用します。
開発環境
この手の機械学習を実行するには実行速度や容量の関係で
GPUやらメモリやらが結構重要になってきます。
PCローカルで実行してもできなくはないのですが、それなりにスペックを求められます。
そこで便利なのがGoogle Colabです。
Google ColabはPythonの主要なライブラリがインストールされたクラウド上の開発環境で
GPUやTPUで実行させることが可能です。
いろいろ制限はあるものの、かなり使い勝手は良いと思います。
データベースの準備
まず機械学習をするにはデータセットが必要になります。
今回必要なのはラノベのタイトルです。
色々検索したら下記のサイトにラノベのデータベースがあったので、
今回使用させていただきました。
ラノベの杜 - DB検索
上記サイトから各出版社の出版物リストがTSVでDLできたので、
タイトルのみ入っている状態で1ファイルにまとめて整形しました。

タイトルの後ろにある「<|endoftext|>」というのは↓こちらを参考に入れています。
危険すぎると話題の文章生成モデル「GPT-2」で会社紹介文を生成してみました
モデルデータの取得
Google Colabは90分操作がないとセッションが終了してしまいます。
そのためgitからクローンしたソースファイルも、
ダウンロードしたファイルも全て一からやり直しになります。
※任意でプロジェクトを終了させた場合も次同じプロジェクトを実行する場合は一からになります。
そこで、毎回モデルデータをダウンロードしなくて良いように
事前にダウンロードしておいてGoogle Driveにアップロードしておくと良いと思います。
ColabはDriveと連携してファイルの入出力が可能です。
GPT2-Japaneseのモデルはsmall / medium / largeの3種類ありますが、
smallを準備しておきましょう。(じゃないとcolabで動かないです)
https://www.nama.ne.jp/models/gpt2ja-small.tar.bz2
Colab上で実行
手順はGPT2-Japanese公式のwikiと↓こちらを参考にさせていただきました。
gpt2-japaneseによるGPT-2のファインチューニング
GPUで学習させるので事前にColabのNotebook settingsにある
Hardware acceleratorをGPUにしておきましょう。
1.gpt2-japaneseのクローンと必要ライブラリのインストール
※以下まとめてコード書いてますがセルに分けないとエラーになるかも知れません。
# gpt2-japaneseをクローン
!git clone https://github.com/tanreinama/gpt2-japanese
# クローンしたディレクトリに移動
cd gpt2-japanese/
# tensorflowをuninstallしてrequiment.txtに書かれたライブラリをinstall
!pip uninstall tensorflow -y
!pip install -r requirements.txt
2.Google Driveからモデルデータをコピー
# Google Driveをマウント(これを実行すると認証ります)
from google.colab import drive
drive.mount('/content/drive')
# モデルデータをコピーして解凍(Driveのディレクトリは人それぞれ異なります)
cp "/content/drive/My Drive/gpt2ja-small.tar.bz2" "."
!tar xvfj gpt2ja-small.tar.bz2
3.Google Driveからデータセットをコピー
# データセットをコピーするディレクトリを作成
!mkdir lightnovel
# 作成したディレクトリに移動してデータセットをコピー(ファイル名はdataset.txtにしています)
cd /content/gpt2-japanese/lightnovel
cp "/content/drive/My Drive/lightnovel/dataset.txt" "."
4.データセットをエンコード
# ディレクトリ移動
cd /content/gpt2-japanese/
# エンコーダーをクローン
!git clone https://github.com/tanreinama/Japanese-BPEEncoder.git
# ディレクトリ移動
cd /content/gpt2-japanese/Japanese-BPEEncoder/
# エンコード(src_dirにはデータセットのディレクトリを指定、dst_fileはエンコード後のファイル名を指定します)
!python encode_bpe.py --src_dir /content/gpt2-japanese/lightnovel/ --dst_file finetune
# エンコード完了するとfinetune.npzが生成されるのでディレクトリを1つ上に移動させます
mv finetune.npz ../
5.fine tuningする
fine tuningは元々のモデルデータに新たなデータセットを学習させる方法です。
# ディレクトリ移動
cd /content/gpt2-japanese/
# エンコード後のデータをGoogle Driveに移動させておくと2回目以降エンコード処理を飛ばせます
cp "finetune.npz" "/content/drive/My Drive/lightnovel/finetune.npz"
# fine tuning実行(base_modelは元になるモデル、datasetはエンコードしたファイル、run_nameは生成後のモデルデータ名です)
!python run_finetune.py --base_model gpt2ja-small --dataset finetune.npz --run_name gpr2ja-finetune_run1
6.生成する
# modelにfine tuningしたモデルを指定し、num_generateで生成数を指定します
!python gpt2-generate.py --model checkpoint/gpr2ja-finetune_run1-small --num_generate 100
結果
試しに100個生成させてみました。
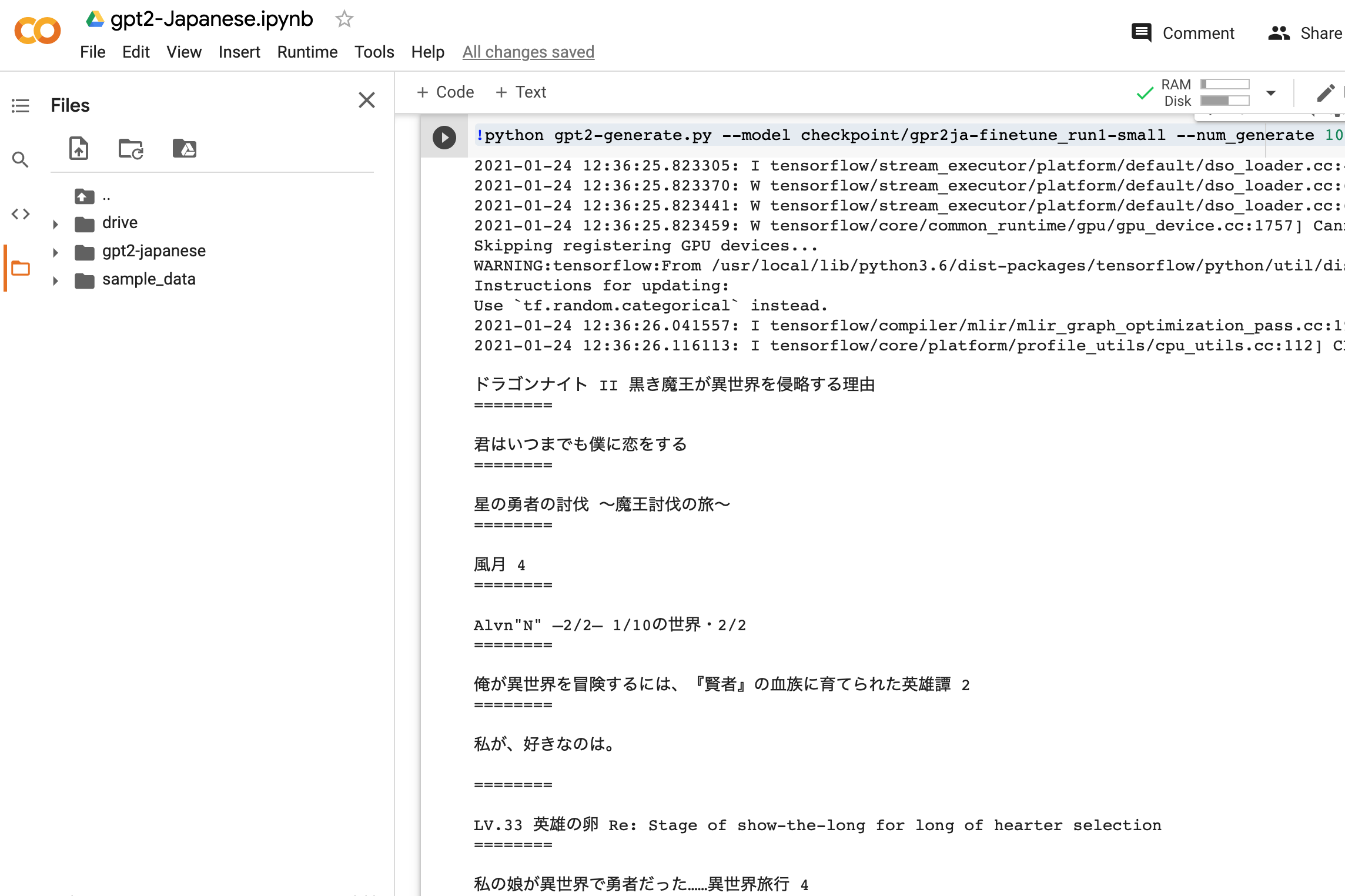
中でも↓この辺が私が思うラノベタイトルっぽくて面白かったです。
・私の娘が異世界で勇者だった……異世界旅行 4
・勇者になったんですけど… 1
・勇者が転生してから異世界行ったけどあんまり強くない、異世界でがんばる 2
・ドラゴンに求婚されたけど、なにか?
個人的にはもっと異世界とかレベル999とかチートとか入って欲しかったのと、
同じ言葉の繰り返しや、生成されないこともあり、
学習のさせ方でもっと精度が上がるのかなと思いました。