はじめに
みなさんはスラブアロケータのカーネルコンフィグでCONFIG_SLAB_FREELIST_RANDOMなるものが存在していることを知っているだろうか。見るからに、ONにするとスラブアロケータが遅くなりそうなオプションである。じゃあなんでこんなコンフィグを用意しているのか。この記事では、その目的と実装、適用後のパフォーマンスについて書きたいと思います。
ちなみに筆者は無効化しています。
SLAB freelist randomizationの目的
この世界にはカーネルの脆弱性を突いて任意のコードを実行させてしまおうとする悪いあんちゃんがいます。しかも、カーネルの脆弱性を突くことで、特権レベルでの任意コード実行というOSとしては壊滅的な状態に陥ってしまう可能性があります。ここで代表的な攻撃手法として、
- ヒープオーバーフロー
- スタックオーバーフロー
などがあります。
そして、SLAB freelist randomizationはこの一つであるヒープオーバーフロー攻撃を防ぐためのものなのです。
ヒープオーバーフロー攻撃
ヒープオーバーフロー攻撃とは、その名の通り、ヒープ領域のメモリをオーバーランして書き込むことを手段とした攻撃方法です。ヒープ領域に確保された構造体などのフィールドはこれによって変更され、任意のアドレスに強制的にアクセスさせたり、構造体に不正な値を保持させることで、結果的に任意コード実行や、プログラムの誤動作を引き起こすものです。
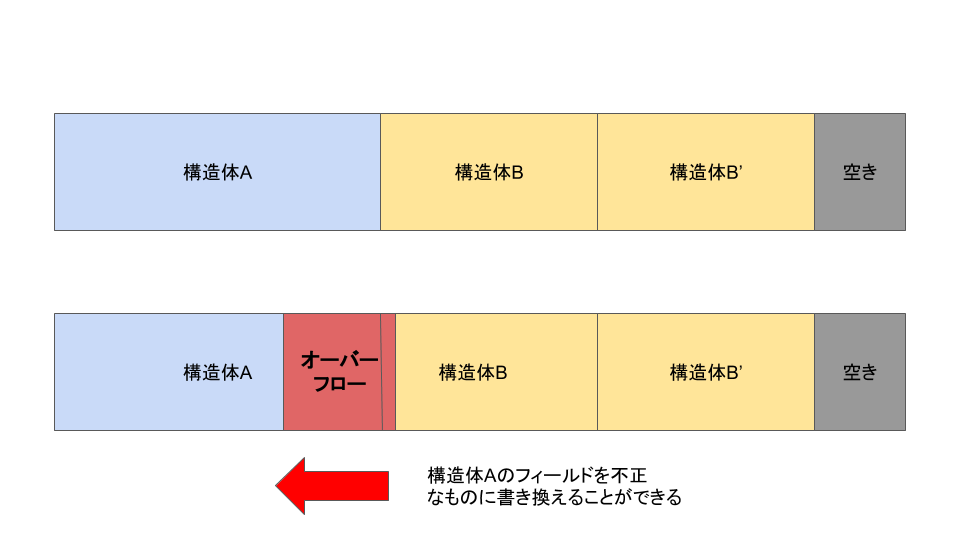
皆さん知っての通り、スラブアロケータはカーネル内のmallocの役割を担っていて、カーネルに対するヒープオーバーフロー攻撃に大きく関わる存在です。そしてスラブアロケータの脆弱性を突くことで、このヒープオーバーフローが起こされてしまうことが理論的に可能であることが証明され、LinuxのCAN(Controller Area Network)を制御するコードで実際にヒープオーバーフローが可能ということです。
流れとしてはshmid_kernelというカーネル内の構造体を大量に確保し、スラブアロケータが管理するページをすべてこれで埋めます。これにより、攻撃対象の構造体の隣にshmid_kernelが来るように仕向けます。この状態で、ヒープオーバーフローを起こし、攻撃対象を上書きすることで、攻撃が成立するわけです。
詳しくはこのページが参考になります。
https://jon.oberheide.org/blog/2010/09/10/linux-kernel-can-slub-overflow/
Linuxカーネル側の対策
Linuxカーネルの開発者たちもこれには黙っていません。既存のスラブアロケータ実装であるSLAB、SLUBではfree list randomizationという機構を導入し、ヒープオーバーフローを防いでいます。
free list randomizationとは、スラブアロケータ内で利用するメモリ領域をランダムに決定することで、すべて同じ構造体で埋めるということを困難にし、今回の脆弱性を回避するという戦略です。なんともめんどくさいですが、しょうがないことなのです。
もちろん、スラブアロケータは高度に最適化されていて、メモリ領域の選択もキャッシュヒット率などを高めるようなアルゴリズムで実装されています。なので、利用するメモリ領域をランダムにすることで、性能が下がるんじゃないかと思われるでしょう。まあ実際下がります。ですが、どちらも微妙なレベルでの変化です。
以下に、LKMLに投稿された性能調査の結果をまとめたものを書いておきます。
初期のSLAB実装
ソース
mm: SLAB freelist randomization
- 原文
Performance results highlighted no major changes:
Hackbench (running 90 10 times):
Before average: 0.0698
After average: 0.0663 (-5.01%)
- 要約
以前のものと修正後のものをHackbenchを用いて性能比較
-5.01%性能が低下しました。
SLUB実装と修正SLAB実装
ソース
mm: SLUB freelist randomization
mm: reorganize SLAB freelist randomization
- 原文
slab_test impact is between 3% to 4% on average for 100000 attempts
without smp. It is a very focused testing, kernbench show the overall
impact on the system is way lower.
- 訳(間違ってるかもしれません)
SMP無しでslab_testで100000回の試行を実行したら性能の影響は、3~4%くらいだった。
これはめっちゃ狭い範囲のテストだけど、kernbench曰く、この修正の性能への影響はそうでもないっぽいな。
とのことなので、パフォーマンスには少ししか影響しないようです。では、その実装はどのようになっているのか見ていこうと思います。
先に書かせていただきますと、この記事は、mm: SLAB freelist randomizationのコミットで投げられたパッチを元に書いていきます。
なので、現在の最新のLinuxカーネルとは一部異なることがあることをご了承ください。
最新実装との比較は後日書くかもしれません(きっと)。
実装調査
ここでは、SLABのfree list randomizationについて書いていきます。SLUBの実装ではSLAB側で定義した関数が呼ばれていたりするので、まずはこっちからっていう感じですね。
mm: SLAB freelist randomization では、ここのgit差分をもとに見ていきます。
diff --git a/init/Kconfig b/init/Kconfig
index 0dfd09d54c65..79a91a2c0444 100644
--- a/init/Kconfig
+++ b/init/Kconfig
@@ -1742,6 +1742,15 @@ config SLOB
endchoice
+config SLAB_FREELIST_RANDOM
+ default n
+ depends on SLAB
+ bool "SLAB freelist randomization"
+ help
+ Randomizes the freelist order used on creating new SLABs. This
+ security feature reduces the predictability of the kernel slab
+ allocator against heap overflows.
+
config SLUB_CPU_PARTIAL
default y
depends on SLUB && SMP
diff --git a/mm/slab.c b/mm/slab.c
index 8133ebea77a4..1ee26a0d358f 100644
カーネルビルド設定を反映するためのdefineがなされています。
これが有効化されていると、free list randomizationのコードがコンパイルされます。
diff --git a/include/linux/slab_def.h b/include/linux/slab_def.h
index 9edbbf352340..8694f7a5d92b 100644
--- a/include/linux/slab_def.h
+++ b/include/linux/slab_def.h
@@ -80,6 +80,10 @@ struct kmem_cache {
struct kasan_cache kasan_info;
#endif
+#ifdef CONFIG_SLAB_FREELIST_RANDOM
+ void *random_seq;
+#endif
+
struct kmem_cache_node *node[MAX_NUMNODES];
};
スラブキャシュを保持しておくkmem_cache構造体にvoid *型でrandom_seqというフィールドを追加しています。
どうやら、ここに乱数ほ保存しておくつもりのようです。
以降、slab.cにガリガリ書いていきます。
一応、今から書くコードはSLAB_FREELIST_RANDOMでブロックされたコードです。一気にコードを貼り付けるとわかりにくくなるので、ご了承願います。
+/* Create a random sequence per cache */
+static int cache_random_seq_create(struct kmem_cache *cachep, gfp_t gfp)
+{
+ unsigned int seed, count = cachep->num;
+ struct rnd_state state;
+
+ if (count < 2)
+ return 0;
+
+ /* If it fails, we will just use the global lists */
+ cachep->random_seq = kcalloc(count, sizeof(freelist_idx_t), gfp);
+ if (!cachep->random_seq)
+ return -ENOMEM;
+
+ /* Get best entropy at this stage */
+ get_random_bytes_arch(&seed, sizeof(seed));
+ prandom_seed_state(&state, seed);
+
+ freelist_randomize(&state, cachep->random_seq, count);
+ return 0;
+}
count(cachep->num)が2未満の場合、ランダムにする必要がない(そもそもできない)ので、0を返して終了しています。
ここで、kmem_cache->random_seqを確保しています。kcallocは配列を確保するです。C標準関数のcallocと同じ働きをします。
freelist_idx_tは次のような定義になっています。
# define FREELIST_BYTE_INDEX (((PAGE_SIZE >> BITS_PER_BYTE) \
<= SLAB_OBJ_MIN_SIZE) ? 1 : 0)
# if FREELIST_BYTE_INDEX
typedef unsigned char freelist_idx_t;
# else
typedef unsigned short freelist_idx_t;
# endif
つまり、一つのページをアドレッシングするために必要なサイズだということです。これで、random_seqはページ内の要素をランダムにアドレッシングするためのものだということがわかります。
get_random_bytes_arch(&seed, sizeof(seed));
prandom_seed_state(&state, seed);
では、乱数のシードを取得しています。
次に、確保した配列にランダムな値を入れているであろうfreelist_randomization関数を見ましょう。
+static void freelist_randomize(struct rnd_state *state, freelist_idx_t *list,
+ size_t count)
+{
+ size_t i;
+ unsigned int rand;
+
+ for (i = 0; i < count; i++)
+ list[i] = i;
+
+ /* Fisher-Yates shuffle */
+ for (i = count - 1; i > 0; i--) {
+ rand = prandom_u32_state(state);
+ rand %= (i + 1);
+ swap(list[i], list[rand]);
+ }
+}
簡単ですね。まず、配列にシーケンシャルな値を代入したあと、いい感じにシャッフルしています。このfreelist_randomize関数をcache_random_seq_create関数の最後に呼び出して、乱数バッファの初期化は終了です。
+/* Destroy the per-cache random freelist sequence */
+static void cache_random_seq_destroy(struct kmem_cache *cachep)
+{
+ kfree(cachep->random_seq);
+ cachep->random_seq = NULL;
+}
次は、乱数バッファの破棄処理です。random_seqはkcallocで確保したメモリ領域なので、kfreeで解放すればOKです。
その後、NULLを代入しておきます。
+#else
+static inline int cache_random_seq_create(struct kmem_cache *cachep, gfp_t gfp)
+{
+ return 0;
+}
+static inline void cache_random_seq_destroy(struct kmem_cache *cachep) { }
+#endif /* CONFIG_SLAB_FREELIST_RANDOM */
このコードはCONFIG_SLAB_FREELIST_RANDOMが有効化されていないときにコンパイルされるコードです。特に何もせず、正常終了の0を返して終了です。
@@ -2374,6 +2429,8 @@ void __kmem_cache_release(struct kmem_cache *cachep)
int i;
struct kmem_cache_node *n;
+ cache_random_seq_destroy(cachep);
+
free_percpu(cachep->cpu_cache);
/* NUMA: free the node structures */
これは、__kmem_cache_release関数に追記されたものです。__kmem_cache_releaseはkmem_cache構造体を解放するための関数なので、これが呼ばれたときに、上で説明したcache_random_seq_destroyを呼び出しています。
+/*
+ * Shuffle the freelist initialization state based on pre-computed lists.
+ * return true if the list was successfully shuffled, false otherwise.
+ */
+static bool shuffle_freelist(struct kmem_cache *cachep, struct page *page)
+{
+ unsigned int objfreelist = 0, i, count = cachep->num;
+ union freelist_init_state state;
+ bool precomputed;
+
+ if (count < 2)
+ return false;
+
+ precomputed = freelist_state_initialize(&state, cachep, count);
+
+ /* Take a random entry as the objfreelist */
+ if (OBJFREELIST_SLAB(cachep)) {
+ if (!precomputed)
+ objfreelist = count - 1;
+ else
+ objfreelist = next_random_slot(&state);
+ page->freelist = index_to_obj(cachep, page, objfreelist) +
+ obj_offset(cachep);
+ count--;
+ }
+
+ /*
+ * On early boot, generate the list dynamically.
+ * Later use a pre-computed list for speed.
+ */
+ if (!precomputed) {
+ freelist_randomize(&state.rnd_state, page->freelist, count);
+ } else {
+ for (i = 0; i < count; i++)
+ set_free_obj(page, i, next_random_slot(&state));
+ }
+
+ if (OBJFREELIST_SLAB(cachep))
+ set_free_obj(page, cachep->num - 1, objfreelist);
+
+ return true;
+}
+#else
+static inline bool shuffle_freelist(struct kmem_cache *cachep,
+ struct page *page)
+{
+ return false;
+}
+#endif /* CONFIG_SLAB_FREELIST_RANDOM */
shuffle_freelist関数はSLAB実装に見られるfree listの位置決定や、そのfree listの並びを乱数で設定したりします。
cachep->numが2未満の場合、ランダムにする必要がない(そもそもできない)ので、falseを返して終了しています。
次にfreelist_state_initialize関数を呼び出しています。引数にローカル変数の共用体freelist_init_stateのポインタを渡しています。では、この構造体と関数をチラ見します。
+/* Hold information during a freelist initialization */
+union freelist_init_state {
+ struct {
+ unsigned int pos;
+ freelist_idx_t *list;
+ unsigned int count;
+ unsigned int rand;
+ };
+ struct rnd_state rnd_state;
+};
コメントによれば、free listの初期化状態を保持しておくための共用体らしいです。
rnd_state構造体は次のような定義になっています。
struct rnd_state {
__u32 s1, s2, s3, s4;
};
本来は、ここに乱数のシード値を詰めるようです。
+/*
+ * Initialize the state based on the randomization methode available.
+ * return true if the pre-computed list is available, false otherwize.
+ */
+static bool freelist_state_initialize(union freelist_init_state *state,
+ struct kmem_cache *cachep,
+ unsigned int count)
+{
+ bool ret;
+ unsigned int rand;
+
+ /* Use best entropy available to define a random shift */
+ get_random_bytes_arch(&rand, sizeof(rand));
+
+ /* Use a random state if the pre-computed list is not available */
+ if (!cachep->random_seq) {
+ prandom_seed_state(&state->rnd_state, rand);
+ ret = false;
+ } else {
+ state->list = cachep->random_seq;
+ state->count = count;
+ state->pos = 0;
+ state->rand = rand;
+ ret = true;
+ }
+ return ret;
+}
この関数はfree listのランダム化に関する情報や後々使用する乱数を引数のfreelist_init_stateに詰めるための関数です。
最初の処理、get_random_bytes_arch(&rand, sizeof(rand));で、いい感じの乱数を取得します。
これは、state->randに代入されます。
ちなみに、random_seqがNULL、つまり、事前に乱数バッファが初期化されていない場合は、prandom_seed_stateを呼び出して、state->rnd_stateに乱数シードを詰めて、falseを返し、事前計算されていませんでしたよと通知します。この詰めた乱数シードも後々使います。
/*********** shuffle_freelist関数の一部 **************/
+ /* Take a random entry as the objfreelist */
+ if (OBJFREELIST_SLAB(cachep)) {
+ if (!precomputed)
+ objfreelist = count - 1;
+ else
+ objfreelist = next_random_slot(&state);
+ page->freelist = index_to_obj(cachep, page, objfreelist) +
+ obj_offset(cachep);
+ count--;
+ }
次にこの処理です。kmem_cache構造体にCFLGS_OBJFREELIST_SLABフラグが立っている場合、この処理が走ります。
このフラグは、このページの領域内にfree listのデータを保存しておく領域がある場合、立っています。
このブロックの処理はfree listをどこに保存しておくかという決定を行っています。random_seqがNULLだった場合、precomputedはfalseとなり、free listの一番後ろにfree listの領域を設定します。事前にrandom_seqが確保されていた場合は、next_random_slot関数の返り値がobjfreelistに代入されます。そして、page->freelistには、index_to_obj関数で上で決めたインデックスからスラブキャッシュ領域に変換しオフセットを足したものを代入します。そしてそこにfree listの領域を作ります。最後に、free list分の領域を引くためにcountをデクリメントして、このブロックは終了です。
しかしながら、next_random_slot関数が謎なので、見ていきましょう。
+/* Get the next entry on the list and randomize it using a random shift */
+static freelist_idx_t next_random_slot(union freelist_init_state *state)
+{
+ return (state->list[state->pos++] + state->rand) % state->count;
+}
この関数も、free list randomizationのパッチで追加された関数です。まあrandomってついてるしね。
内容としては、乱数を用いて、ランダムにアドレッシングするような処理になっています。
state->listには何が入っているかと言うと、freelist_state_initialize関数を思い出してください。
kmem_cache->random_seqが代入されているわけです。state->posには0が代入されていて、この処理のあと、即インクリメントされることになっています。つまり、random_seqの先頭から乱数を取り出しているわけです。そして、state->randには乱数が入っているので、2つの乱数を足し合わせ、それをstate->count、つまりバッファに入る要素数で余りをとることで、ランダムにインデックスを決定しています。ここで、重要なことは、返すインデックスは決して重複しないということです。まあ、当たり前ですが、重要なことです。
では次に行きましょう。
/*********** shuffle_freelist関数の一部 **************/
/*
+ * On early boot, generate the list dynamically.
+ * Later use a pre-computed list for speed.
+ */
+ if (!precomputed) {
+ freelist_randomize(&state.rnd_state, page->freelist, count);
+ } else {
+ for (i = 0; i < count; i++)
+ set_free_obj(page, i, next_random_slot(&state));
+ }
+
+ if (OBJFREELIST_SLAB(cachep))
+ set_free_obj(page, cachep->num - 1, objfreelist);
+
+ return true;
+ }
shuffle_freelistの最後です。事前にランダムバッファを作っていない場合は、ここで、上で説明したfreelist_randomize関数を呼び出してpage->freelistに乱数を設定します。事前計算していた場合は、ランダムな順番をfreelistに順番に入れていきます。
ちなみに、set_free_obj関数の実装は次のようになっています。
static inline void set_free_obj(struct page *page,
unsigned int idx, freelist_idx_t val)
{
((freelist_idx_t *)(page->freelist))[idx] = val;
}
簡単ですね。freelist領域を配列のように扱っているわけです。
+#else
+static inline bool shuffle_freelist(struct kmem_cache *cachep,
+ struct page *page)
+{
+ return false;
+}
+#endif /* CONFIG_SLAB_FREELIST_RANDOM */
最後に、CONFIG_SLAB_FREELIST_RANDOMが有効化されていないときの処理を記述して終了です
内容は特になく、falseを返して終了です。
ここからは、既存の関数に書き加えていく修正です。
static void cache_init_objs(struct kmem_cache *cachep,
struct page *page)
{
int i;
void *objp;
+ bool shuffled;
cache_init_objs_debug(cachep, page);
- if (OBJFREELIST_SLAB(cachep)) {
+ /* Try to randomize the freelist if enabled */
+ shuffled = shuffle_freelist(cachep, page);
+
+ if (!shuffled && OBJFREELIST_SLAB(cachep)) {
page->freelist = index_to_obj(cachep, page, cachep->num - 1) +
obj_offset(cachep);
}
cache_init_objsへの追記です。
この関数では、free listの設定や、オブジェクトの属性設定が行われます。
この追記された部分では、shuffle_freelist関数が呼ばれ実際にfree listのシャッフルが行われています。
その結果はbool型のローカル変数shuffledに代入されます。
その後、free listの領域を決定するためにpage->freelistに代入する操作があるんですが、
shuffleを行った場合は、すでにfree listの領域が決定しているので、この操作は飛ばします。
shuffledがfalseだった場合は、free listの領域を決定することになります。
@@ -2502,7 +2659,8 @@ static void cache_init_objs(struct kmem_cache *cachep,
kasan_poison_object_data(cachep, objp);
}
- set_free_obj(page, i, i);
+ if (!shuffled)
+ set_free_obj(page, i, i);
}
}
これもcache_init_objsへの追記です。
これは、シャッフルされている場合は、既にset_free_objが呼び出されているので、実行しないという追記ですね。
@@ -3841,6 +3999,10 @@ static int enable_cpucache(struct kmem_cache *cachep, gfp_t gfp)
int shared = 0;
int batchcount = 0;
+ err = cache_random_seq_create(cachep, gfp);
+ if (err)
+ goto end;
+
if (!is_root_cache(cachep)) {
struct kmem_cache *root = memcg_root_cache(cachep);
limit = root->limit;
@@ -3894,6 +4056,7 @@ static int enable_cpucache(struct kmem_cache *cachep, gfp_t gfp)
batchcount = (limit + 1) / 2;
skip_setup:
err = do_tune_cpucache(cachep, limit, batchcount, shared, gfp);
+end:
if (err)
pr_err("enable_cpucache failed for %s, error %d\n",
cachep->name, -err);
```
これは、enable_cpucache関数への追記です。この関数は、\_\_kmem_cache_create->setup_cpu_cache->enable_cpucacheの流れで呼ばれていて、スラブキャッシュの初期化部分と言ってもいいでしょう。なので、cache_random_seq_create関数で乱数バッファを生成する処理をここに入れています。そして、これが失敗した場合は、新しく作ったendラベルにジャンプするという追記になっています。
# まとめ
今回は、スラブアロケータのfree list randomizationの目的(少しだけ)と実装について触れました。今回触れたものは、パッチが投げられた当時のソースコードになっています。なので、最新のLinuxカーネルのソースコードと比べるとところどころ異なる部分もあるかと思いますが、多くのところは一致しているのかなと思います。
free list randomizationは意外とシンプルな実装で、読むだけなら簡単なんだと思っていただけると嬉しいです。
次は、SLUB実装との比較や最新実装にも触れたいなぁと。今回は、これだけで結構長くなってしまったのと、筆者が疲れたので、ここで終わりにします。
ありがとうございました。
# 参考文献
「詳解Linuxカーネル 第3版」 O’Reilly Japan