Azure Machine LearningはMicrosoftが提供しているクラウドベースの機械学習のサービスです。
Azure Machine LearningではGUIを使って様々な機械学習の手法を実行することができますがJupyterを使用することも可能となっています。
Azure Machine LearningでJupyter Notebookを使う
Azure Machine LearningのはMicrosoftアカウントをもっていれば無料で試すことができます。Jupyterも無料のプランで使えます。
価格についての詳細は下記のリンクを参照してください。
料金 - Machine Learning | Microsoft Azure
Microsoftアカウント作成
Microsoftアカウントをもっていない場合にはリンク先から作成します。
ワークスペース作成
下記リンクを開き「Get Started」ボタンをクリックし、Microsoftアカウントにサインインします。
Microsoft Azure Machine Learning Studio
「Workspace Not Found」と表示された画面になったら再びブラウザでMicrosoft Azure Machine Learning Studioを開いて「Get Started」ボタンを押します。
成功していれば無料のワークスペースが作成されており以下のような画面が開きます。
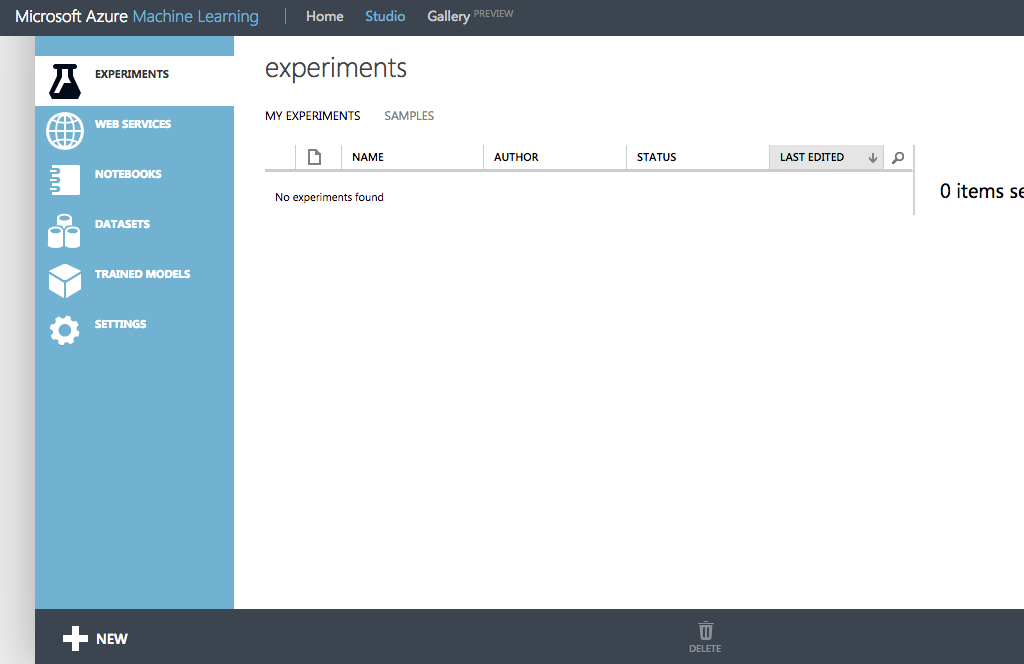
Jupyter Notebookの作成
画面左下の「+NEW」をクリックすると以下のような画面が開くのでNOTEBOOKからPythonのバージョンを選択します。

今回はPython2を選択してみます。Notebookの名前を訊かれるので適当に入力します。
NOTEBOOKSに作成したJupyter Notebookが表示されているのでクリックして開きます。
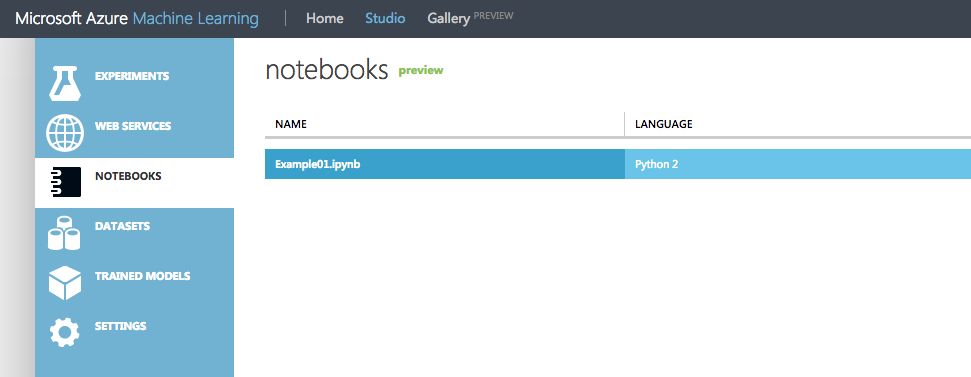
空のNotebookが開きます。この後は通常通り使用できます。

使用可能なライブラリ
Azure Machine LearningのJupyterはAnacondaを使用しており、以下のリストのパッケージが使用可能となっています。
Anaconda Package List — Continuum documentation
Anacondaのバージョンが2.1と少し古くパッケージによっては最新ではない場合があります。
Azure Machine LearningとJupyter Notebookの連携
Azure Machine LearningのJupyter NotebookにはAzure Machine LearningのPythonクライアントがインストールされています。これを利用してAzure Machine Learningの操作やデータのやり取りが可能です。
Azure/Azure-MachineLearning-ClientLibrary-Python
ワークスペースに接続する
まず現在使用しているワークスペースに接続します。接続のために必要なワークスペースのIDとトークンはstudioのSETTINGSから確認することができます。
from azureml import Workspace
ws = Workspace(
workspace_id="YOUR_WORKSPACE_ID",
authorization_token="YOUR_AUTHORIZATION_TOKEN",
endpoint="https://studio.azureml.net"
)
データセットを使用する
使用できるデータセットは以下のようにして確認できます。
ws.datasets
使用したいデータセットの名前を指定してデータを取得し、to_dataframeでデータフレームに変換することができます。
df = ws.datasets['Bike Rental UCI dataset'].to_dataframe()
Experimentからデータを取得する
Experimentの中間データをJupyterで取得するためには「Convert to CSV」にデータを入力します。
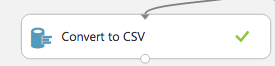
「Convert to CSV」の出力ポートをクリックし「Generate Data Access Code」を選択すると中間データをデータフレームとして取得するためのコードが表示されます。
(ワークスペースへの接続のコードも表示されますがendpointが設定されていないとエラーがでました。上記のようにendpointを追加したら動きました。)
JupyterのデータをAzure Machine Learningのデータセットに追加する
Jupyterで操作しているデータをAzure Machine Learningのデータセットに追加することができます。
データセットに追加する際にはadd_from_dataframeを使用します。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(
np.column_stack([boston.data, boston.target]),
columns=boston.feature_names
)
dataset = ws.datasets.add_from_dataframe(
dataframe=df,
data_type_id='GenericCSV',
name='boston',
description=boston.DESCR,
)
Webサービスを作成する
JupyterからWebサービスを作成することもできます。
例えば次のコードを実行するとaddというするWebサービスが作成されます。
from azureml import services
@services.publish(ws.workspace_id, ws.authorization_token)
@services.types(a = float, b = float)
@services.returns(float)
def add(a, b):
return a + b
既存のWebサービスを使用する
既存のWebサービスをJupyterから使用することもできます。
Jupyterで作成したWebサービスを使用すると認証が通らずうまくいかなかったためGUIで
足し算をするサービスを作成しJupyterから使ってみます。
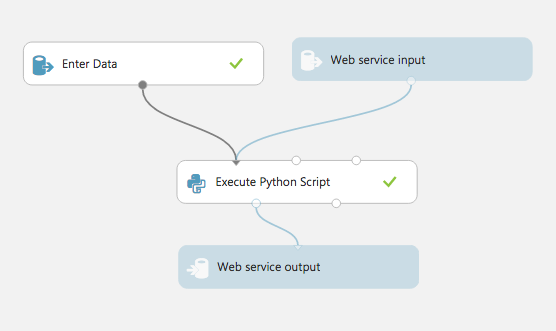
「Execute Python Script」の中身は次のようになっています。
def azureml_main(dataframe1 = None):
dataframe1['c'] = dataframe1.a + dataframe1.b
return dataframe1
これをWebサービスとしてデプロイすると次のように2つの数字を足し算してくれるサービスができます。
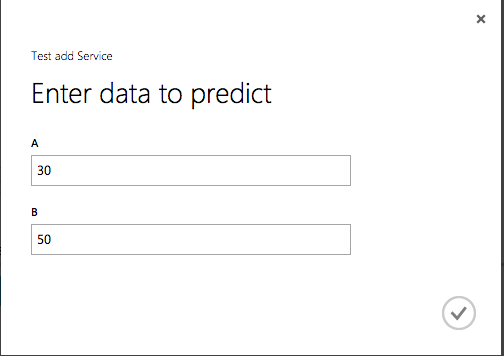

このWebサービスをNotebookから使用するためには次のようにデコレータを使って関数を定義します。
urlとapi_keyは作成したWebサービスのダッシュボート、REQUEST/RESPONSEのヘルプページから取得できます。
from azureml import services
url = 'WEB_SERVICE_URL'
api_key = 'WEB_SERVICE_API_KEY'
@services.service(url, api_key)
@services.types(a = float, b = float)
@services.returns(float)
def add(a, b):
pass
この関数をWebサービスとして使用することができます。(初回は実行まで少し時間がかかります。)
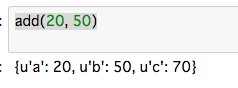
最後に
まだクライアント・Jupyterからできないことも多いですが、今後連携機能が強化されていきそうなので楽しみです。Azure Machine Learningは例が多く用意されているのでJupyterで途中結果を詳しくみたり、グラフを書いたりすると面白そうです。