モチベーション
Excelの情報を集計するのにシートに計算式かちゃかちゃいれると動き遅くなる。Python+Excel関連の本を本屋で見かけるようになってきたし、勉強しておこう。
環境
windows10
python3.9
VS Code
Pandas
openpyxl
準備
python、pandasのinstall(pip使ってね)は済んでる前提
お題
こういうExcelがある。
特徴としては部署の列がシートによって異なる。(黄色の列です)
部署毎の人数を集計したい。
| sheet1 | sheet2 | sheet3 |
|---|---|---|
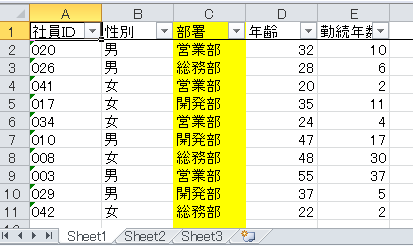 |
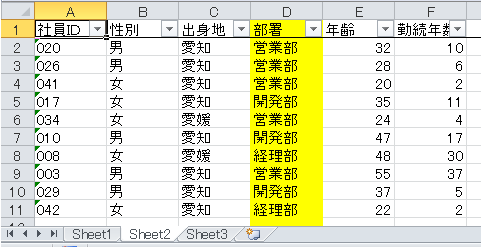 |
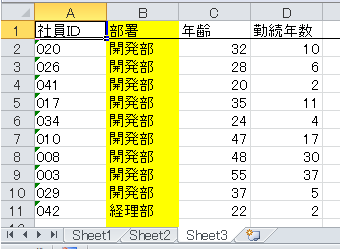 |
早速答え
pandas_lib.pyで2関数定義
- countByKeyFromFileAndSheet:key列を集計する関数:pandas関数のvalue_counts()を使って集計し、to_dict()でdict型に変換します。
- concatenateDict:dictを2つ繋げる関数
pandas_lib.py
import pandas as pd # pandasは、Pythonにおいて、データ解析を支援する機能を提供するライブラリ
import numpy as np
# keyでGroupingしてカウント
def countByKeyFromFileAndSheet(filename, sheetname, key):
df = pd.read_excel(filename, sheet_name=sheetname, engine="openpyxl")
dict = df[key].value_counts().to_dict()
print(dict)
return dict
def concatenateDict(dict1, dict2):
newdict=dict1
for k in dict2:
if k in newdict:
newdict[k] += dict2[k]
else:
#newdict.update(k, dict2[k])
newdict[k] = dict2[k]
return newdict
pandas_main.py
countByKeyFromFileAndSheetでSheet1~3の部署名の列を集計し、dictに格納しておき、concatenateDictでdictを繋ぎdictを生成する。
pandas_main.py
import pandas_lib as pl
dict1 = pl.countByKeyFromFileAndSheet("./example.xlsx", "Sheet1", "部署")
dict2 = pl.countByKeyFromFileAndSheet("./example.xlsx", "Sheet2", "部署")
dict3 = pl.countByKeyFromFileAndSheet("./example.xlsx", "Sheet3", "部署")
dict = pl.concatenateDict(dict1, dict2)
dict = pl.concatenateDict(dict, dict3)
print(dict)
実行結果
dict1-3に集計後、最終的に3シート合計の集計ができていることが分かります。
{'営業部': 4, '開発部': 3, '総務部': 3}
{'営業部': 5, '開発部': 3, '経理部': 2}
{'開発部': 9, '経理部': 1}
{'営業部': 9, '開発部': 15, '総務部': 3, '経理部': 3}
最後に
concatenateDictの中for文使って泥臭く実装しましたが、他にもっとスマートな実装方法あったら、教えて頂きたいです。