はじめに
これからの強化学習の2.4の内容をまとめた記事になります。
一言で言うと強化学習は学習に時間がかかるので、なるべく試行錯誤の回数を減らして、最適ではなくとも妥当な解を求めようという考えで生まれた方法です。
強化学習の学習方針
探索(最適性)を重視
- Q-Learningなど
Q(S_t, A_t) \leftarrow (1 - \alpha)Q(S_t, A_t) + \alpha \Bigl(r_{t+1} + \gamma \max_{a}Q(S_{t+1}, a) \Bigr)
- 第2項からわかるように未来を考慮する
- 最適解が求まる可能性が高い
- 学習が遅い
利用(合理性)を重視
- 経験強化型学習(Exploitation-oriented Learning:XoL)
- 過去の経験のみを考慮する
- 最適な解は求まらないかもしれない
- 学習が速い
経験強化学習の種類
Profit Sharing
- 基本
- タイプ2の混同(後述)がない場合に使える
合理的政策形成アルゴリズム(RPM)
- タイプ2の混同があっても使える
- 決定的合理的政策がある場合に使える
PS-r、PS-r*、PS-r#
- タイプ2の混同があっても使える
- 決定的合理的政策がなくても使える
罰回避政策形成アルゴリズム(PARP)
- 罰がある場合
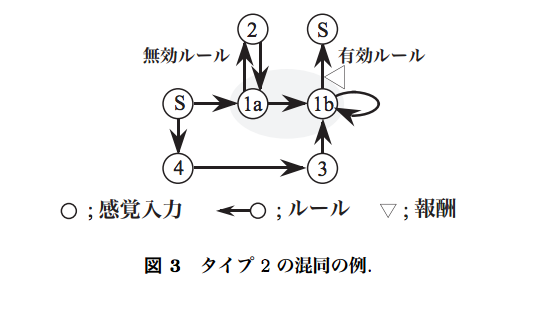
タイプ2の混同
- 不完全知覚により状態を混同し、ルールの価値を混同すること
- 下図だと1aと1bは両方1として認識されてしまう
- 単純に学習させると迂回路を学習してしまう
- なお状態の価値を混同することをタイプ1の混同という
- タイプ1の混同は状態の価値を計算するQ-Learningでは問題になるが、XoLでは状態の価値を使わないので、問題にならない
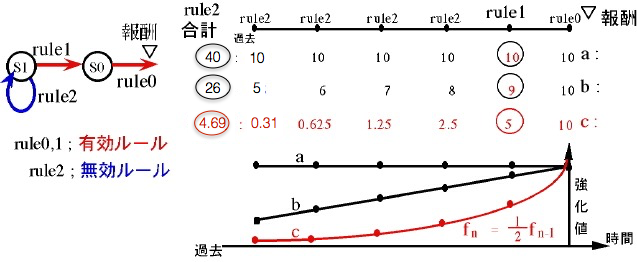
Profit Sharing
- 報酬を受け取ったとき(エピソードが終わったとき)状態-行動(ルール)列が得られる
- これらのルール$r_i$に報酬$\omega_{r_i}$を割り当てる
\omega_{r_i} = \omega_{r_i} + f_i
- すべてのルールに均等に報酬を割り当てると、迂回路があったときに迂回路が余分に強化されてしまうため、うまく学習できないので工夫が必要
- 分配の方法を強化関数$f_i$で定め、以下のPSの合理性定理を満たす強化関数を選べば、迂回路を除いた合理的なルールが得られる
\forall i = 1,2,...W, L\sum_{j=i}^Wf_j < f_{i-1}
$W$はエピソードの最大長
$L$は同一条件化に存在する有効ルールの最大個数。実用上は「可能な行動行動の種類-1」とすればよい
- 例
$f_i$を最も単純な$\frac{1}{行動の種類}$とした場合
合理的政策形成アルゴリズム(RPM)
不完全知覚でタイプ2の混同があった場合でも決定的合理的政策があれば獲得できる。
マルチスタート法によって、失敗したらやり直せるようになったのが理由。
収束判定には最後に2次記憶が更新されてから倍の時間が経てば収束とみなす方法などがある。

PS-r
RPMにランダム性を加えたもの。これにより決定的合理的政策がなくても良い挙動が得られる。

PS-r*
PS-rにおいて、不完全知覚かどうかを$\chi^2$検定により判断し、ランダムに行動するかルールに則って行動するかを選択する。

PS-r#
PS-r*において、不完全知覚かどうかをルールの選択回数により判断し、ランダムに行動するかルールに則って行動するかを選択する。
罰回避政策形成アルゴリズム(PARP)
以下のようなアルゴリズムで罰ルールを判定して回避する
Procedure 罰ルール判定法(PRJ)
begin
これまで経験したエピソードの中で直接罰を得たことのあるルールにマークする
do
以下の条件が成立する状態にマークする
その状態で選択可能なルールが無効ルールまたはマークされたルールのみである
以下の条件が成立するルールにマークする
そのルールで繊維可能な状態のなかの少なくとも1つがマークされている
while 新たにマークされた状態が存在する
end
これではメモリを大量に必要とするので、確率的に罰を回避する方法もある
入力が連続値の場合
- 基底関数で表現し、有限個のパラメータに離散化する
- あとは同様
応用例
- 専門学校などの単位を学士のための単位に当たるかどうかをサジェストする
- ロボットシミュレータでの歩行学習
XoLの発展
- 探索との組み合わせ
- 探索を行うことができる学習器とハイブリッドすることで、利用と探索のトレードオフを設計者がコントロールできるようにする
- 深層学習との組み合わせ
- DQN with PS
- 通常のDQNに加えてProfit Sharingでの報酬も加味してネットワークを更新する
- DQNに比べてかなり速く学習できる
参考
Profit Sharingの不完全知覚環境下への拡張:PS-r*の提案と評価
Profit Sharingに基づく強化学習システム