はじめに
初めまして、あたなと申します。
田舎で社内SEをしています。
今回はPythonを使用したツールを開発したので、議事録的に記事に残します。
背景
社内にて大量のPDFのダウンロードを一個一個行っている人を見かけたので、Pythonの練習がてら何かツールを作ってみようと思い作成しました。
ツールについて
このツールはGUI画面にURLを張り付けるとそのURL内のPDFを全て自動で取得するものとなっております。
実行前
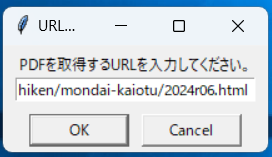
実行後


Pythonでのスクレイピングというと selenium, BeautifulSoupなどのライブラリがあげられると思います。今回は簡易的なもの+静的なページでクリックを想定していないものとして作成しようと思ったので、BeautifulSoupを使用することにしました。
処理内容について下記URLを参考にさせていただきました。ありがとうございました。
またこの処理は大量のPDFをダウンロードしたい場合の想定として、下記URLを使用させていただきました。
処理の流れ
・GUIでURLを張り付ける。
・URLからHTMLデータを取得する。
・HTMLデータからaタグの.pdfで終わるデータを絶対パスに変換後、リストへ格納
同時にPDFの名前も別リストへ格納する。
・保存先のディレクトリを作成する。
・保存先ディレクトリのパスをPDFの名前に連結させる。
・絶対パスと保存先リストを使用してダウンロード処理
コード全容
TOTEMO NAGAI
import urllib.request
import requests
from bs4 import BeautifulSoup
import urllib.parse
import tkinter as tk
from tkinter import simpledialog, messagebox
import os
import time
from datetime import datetime
import re
def sanitize_filename(filename):
# ファイル名に使用できない文字を置換する
return re.sub(r'[\\/*?:"<>.|]', "_", filename)
def download_pdf(url, save_dir):
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
a_tags = soup.find_all("a")
url_list = [] # ダウンロードするPDFのURLリスト
filename_list = [] # ダウンロードするPDFのファイル名のリスト
pdf_found = False # PDF存在フラグ
# PDFに該当するものだけを絶対パスに変換後、リストへ保存
for a_tag in a_tags:
href = a_tag.get("href")
if href and href.endswith(".pdf"):
absolute_url = urllib.parse.urljoin(url, href)
url_list.append(absolute_url)
filename = sanitize_filename(a_tag.text.strip()) + ".pdf"
filename_list.append(filename)
pdf_found = True
if not pdf_found:
messagebox.showerror("エラー", "PDFリンクが見つかりませんでした。")
return 0
# 保存ディレクトリを作成
date_folder = datetime.now().strftime("%Y%m%d%H%M%S")
save_dir = os.path.join(save_dir, date_folder)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
savepath_list = [] # ダウンロードしたPDFの保存先のリスト
for filename in filename_list:
savepath_list.append(os.path.join(save_dir, filename))
# PDFダウンロード処理
for (url, savepath) in zip(url_list, savepath_list):
urllib.request.urlretrieve(url, savepath)
time.sleep(2) # サーバ負荷を軽減するための待機
return len(url_list)
def main():
root = tk.Tk()
root.withdraw()
save_dir = "C:\PDF_download"
url = simpledialog.askstring("URL入力", "PDFを取得するURLを入力してください。")
if not url:
messagebox.showerror("エラー", "URLが入力されていません。")
return
try:
# PDFダウンロードを実行し、ダウンロード数を表示
num_download = download_pdf(url, save_dir)
messagebox.showinfo("完了", f"{num_download}個のPDFの保存に成功しました。")
except Exception as e:
messagebox.showerror("エラー", f"ダウンロード中にエラーが発生しました。:{e}")
if __name__ == "__main__":
main()
●import
必要と思われるものをimportしています。
import urllib.request
import requests
from bs4 import BeautifulSoup
import urllib.parse
import tkinter as tk
from tkinter import simpledialog, messagebox
import os
import time
from datetime import datetime
import re
●サニタイズ
PDFの名前を格納する際に使用する。
これがあるだけで安心感がすごい
def sanitize_filename(filename):
# ファイル名に使用できない文字を置換する
return re.sub(r'[\\/*?:"<>.|]', "_", filename)
●ダウンロード処理関数
GUIで受け取ったURLと保存先のディレクトリを受け取り、ダウンロードの処理を行います。
戻り値としてダウンロードした数を返しています。
部分ごとに処理内容の方を記述していきます。
def download_pdf(url, save_dir):
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
a_tags = soup.find_all("a")
pdf_url_list = [] # ダウンロードするPDFのURLリスト
filename_list = [] # ダウンロードするPDFのファイル名のリスト
pdf_found = False # PDF存在フラグ
# PDFに該当するものだけを絶対パスに変換後、リストへ保存
for a_tag in a_tags:
href = a_tag.get("href")
if href and href.endswith(".pdf"):
absolute_url = urllib.parse.urljoin(url, href)
pdf_url_list.append(absolute_url)
filename = sanitize_filename(a_tag.text.strip()) + ".pdf"
filename_list.append(filename)
pdf_found = True
if not pdf_found:
messagebox.showerror("エラー", "PDFリンクが見つかりませんでした。")
return 0
# 保存ディレクトリを作成
date_folder = datetime.now().strftime("%Y%m%d%H%M%S")
save_dir = os.path.join(save_dir, date_folder)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
savepath_list = [] # ダウンロードするPDFの保存先のリスト
for filename in filename_list:
savepath_list.append(os.path.join(save_dir, filename))
# PDFダウンロード処理
for (pdf_url, savepath) in zip(pdf_url_list, savepath_list):
urllib.request.urlretrieve(pdf_url, savepath)
time.sleep(2) # サーバ負荷を軽減するための待機
return len(pdf_url_list)
・HTML取得
URLからHTMLコンテンツを受け取り、BeautifulSoupで扱えるようにし、aタグ要素だけを取得します。
文字化けが発生していたのでUTF-8でエンコードしています。
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
a_tags = soup.find_all("a")
pdf_url_list = [] # ダウンロードするPDFのURLリスト
filename_list = [] # ダウンロードするPDFのファイル名のリスト
pdf_found = False # PDF存在フラグ
・ダウンロードするPDFをリストとして格納
aタグのhref属性のものだけを取得し、.pdfで終わる場合に絶対パスとしてリストに格納する。同時にそのPDFのファイル名もファイル名のリストに格納する。
# PDFに該当するものだけを絶対パスに変換後、リストへ保存
for a_tag in a_tags:
href = a_tag.get("href")
if href and href.endswith(".pdf"):
absolute_url = urllib.parse.urljoin(url, href)
pdf_url_list.append(absolute_url)
filename = sanitize_filename(a_tag.text.strip()) + ".pdf"
filename_list.append(filename)
pdf_found = True
if not pdf_found:
messagebox.showerror("エラー", "PDFリンクが見つかりませんでした。")
return 0
・保存先のディレクトリを作成
ディレクトリ作成後、パスをファイル名の前に付け加える。
# 保存ディレクトリを作成
date_folder = datetime.now().strftime("%Y%m%d%H%M%S")
save_dir = os.path.join(save_dir, date_folder)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
savepath_list = [] # ダウンロードするPDFの保存先のリスト
for filename in filename_list:
savepath_list.append(os.path.join(save_dir, filename))
・PDFをダウンロードする
urllib.request.urlretrieve()を使用し、PDFの絶対パスと保存先の絶対パスを指定しダウンロードの処理を行う。戻り値としてダウンロードしたPDFの数を返します。
# PDFダウンロード処理
for (pdf_url, savepath) in zip(pdf_url_list, savepath_list):
urllib.request.urlretrieve(pdf_url, savepath)
time.sleep(2) # サーバ負荷を軽減するための待機
return len(pdf_url_list)
●メイン関数
GUIを表示させ、URLを入力すると自動でPDFをダウンロードしてくれます。
汎用的に誰でも使えるようにしたかったので、ディレクトリはC直下に新しくディレクトリを作成するようにしました。
def main():
root = tk.Tk()
root.withdraw()
save_dir = "C:\PDF_download"
url = simpledialog.askstring("URL入力", "PDFを取得するURLを入力してください。")
if not url:
messagebox.showerror("エラー", "URLが入力されていません。")
return
try:
# PDFダウンロードを実行し、ダウンロード数を表示
num_download = download_pdf(url, save_dir)
messagebox.showinfo("完了", f"{num_download}個のPDFの保存に成功しました。")
except Exception as e:
messagebox.showerror("エラー", f"ダウンロード中にエラーが発生しました。:{e}")
終わりに
このツールはPythonを初めて2週間時点で作ったこともあり、無駄な部分があると思います。(あれ、save_dir引数で渡さなくてもよくない?など)
しかし自分で手を動かして初めてPythonで作ったこともあり、今では愛着があり、やっぱりプログラミング楽しいと再び思えるきっかけにもなったので、こうして記事に出来たことはよかったと感じました。