前編の続きです。前編ではChan.Unagiには以下の欠点があることを解説しました。
- 読み出しを行うスレッドに対する非同期例外の扱いが面倒
- データがすぐにGCされない
後編では、Chan.Unagiの欠点を克服したキューを作るやり方について解説します。
不要になったデータをGCできるようにする
まずは簡単な方から解決していきましょう。
Chan.Unagiで読み出し終わったデータをMutableArrayから削除できないのは、Chan.Unagiがチャネル(書き込まれた値を複数のキューに書き込まれたかのように読み出す機能を持つ)であるためでした。
であるならば話は単純です。作りたいのはチャネルではなくキューなのでデータを削除すればよいのです。
具体的には、MutableArrayに入れるデータ型の定義に読み出し終わった状態を追加し、読み出し処理の終わりに、この値を書き込めば解決です。
この書き込みはCASを使う必要はなく、直接書き込みを行えばOKです。キューであれば、値を読み出した後にMutableArrayの同じ座標を読みに行く処理は存在しないはずだからです。
この書き込みにより多少のコストはかかりますが、大きな速度低下にはなりません。CASやFetch-and-Addなどと比較して直接書き込むだけの処理はコストが小さいからです。
読み出し処理に対する非同期例外でデータがロストしないようにする
Chan.Unagiでデータがロストするのは、データを待っている読み出し処理が回したカウンターを誰も戻さないことが原因でした。これは別の見方をすると、データを待っている状態以外であればデータのロストを回避できる可能性があるということです。
以下のような状況を考えてみましょう。
- MutableArray上のどこまでデータが確実に書き込まれているかわかっている
- わかっている位置より先については、書き込まれたか、まだ書き込まれていないか不明
このとき、読み出し操作において、読み出しカウンタを回して得た値によって、以下の2つの場合にわけることができます。
- 読み出しカウンタを回して得た値が、データが確実に書き込まれていることがわかっている座標を示していた場合
- 読み出しカウンタを回して得た値が、データが確実に書き込まれていることが不明な座標を示していた場合
前者の場合、読み出し待ちでブロックすることがないため、maskさえしてあればChan.Unagiで起きていたようなデータのロストは起きません。安全に読み出し可能な領域といえます。
問題は後者の場合ですが、前者の場合には安全であることを考えると、「安全に読み出し可能な領域を増やす」ことで安全な読み出しが可能になります。そのために、どれか一つのスレッドに「どこまでデータが書き込まれているか」を走査させればよいのです。1
走査を行うスレッドは誰でも構いませんが、最初に「書き込まれているか不明な座標を得た読み出しスレッド」が行えば問題ないでしょう。
この走査を行うにあたって、以下の課題について考える必要があります。
- 走査の結果、安全に読み出し可能な領域が全く増えない。つまり、読み出し可能だと判明していた領域の次の座標にまだデータが書き込まれていないケースがあること
- 安全に書き込みできる領域が増えるまでの間、他の「書き込まれているか不明な座標を得た読み出しスレッド」を待たせる必要があること
1についてまず考えます。
まだ次の座標にデータが書き込まれていない場合、次の書き込みまでの間読み出しスレッドは何も動作できない状態であるということになります。
書き込みを契機として走査を再開するためには、走査を行うスレッドで書き込みを待つ必要があります。書き込みを待つやり方はChan.Unagiの場合と同じく、MutableArrayにMVarを書き込みそれをreadMVarします。
次に2について考えます。
読み出しスレッドを待たせるとはブロックさせるということです。走査を行うスレッドも書き込みを待つケースがありますから、「書き込まれているか不明な座標を得た読み出しスレッド」は全てブロックする可能性があるということです。
ブロックするということは、非同期例外を処理して戻らなくてはいけない可能性があるということでもあります。このため、既に得た「書き込まれているか不明な座標を示すカウンタの値」を再利用することはできません。再利用すると、非同期例外が投げられたスレッドの値が失われてしまい、データのロストにつながってしまいます。
そこでカウンタの値を「以前に読み出し可能とわかっていた値の末尾」まで巻き戻し、読み出しを待っていたスレッドはカウンタを回し直すことを考えます。これなら、ブロックしている最中に非同期例外を処理したスレッドはカウンタを回さないため、データのロストを防ぐことができます。
このとき「安全に読み出し可能な領域の情報」と「カウンタの値」は同時に更新する必要があります。同時に更新しないと、更新中のタイミングで新しく読み出しを試みるスレッドが意図しない情報をもとに誤った読み出し操作を行ってしまうことになるためです。
しかし、「カウンタの値」と「安全に読み出し可能な領域の情報」の更新は同時に行うことはできません。このため、カウンタの値を更新するのではなく、新しいカウンタを作り直した上で初期値を変更したものを使用し、「新しいカウンタ」と「安全に読み出し可能な領域の情報」を同時に更新します。
最終的にできたキューの型は以下です。(見やすいようにUNPACKやBangなどを取り除いています。また、この部分に関係ない型は省略しています)
data Queue a = Queue
{ queueWriteStream :: (IORef (Stream a))
, queueWriteCounter :: AtomicCounter
, queueReadStream :: (IORef (Stream a))
, queueReadState :: (WVar (ReadState a))
, queueNoneTicket :: (Ticket (Item a))
}
data ReadState a = ReadState
{ rsCounter :: AtomicCounter
, rsLimit :: StreamIndex
}
data Stream a = Stream
{ streamBuffer :: (Buffer a)
, streamNext :: (IORef (NextStream a))
, streamOffset :: StreamIndex
}
type StreamIndex = Int
ReadState にカウンタ(rsCounter :: AtomicCounter)と「どこまで安全に読めるかの座標」(rsLimit :: StreamIndex)を保持し、これをQueueのqueueReadState :: (WVar (ReadState a))に保持しています。WVarというのは、このキューを作成するにあたって自作した部品で「値が空の間も、直前の値を読むことが可能なMVar」のようなものです。
このqueueReadStateを更新することで、上記で説明した動作を実現しています。
さて、ここまでの説明で「読み出し処理に対する非同期例外でデータがロストしないようにする」こと自体はできました。
しかし、あと少し考えるべきことが残っています。
ひとつは、このキューの欠点です。
この方法で作成したキューは、読み出しスレッドがカウンタの値を取得し直すため、「待ち順の公平性」がありません。必ずしも待ちに入ったのとは異なる順番でデータを読み出す可能性があります。
(TQueueやTChanも「待ち順の公平性」がないため、この性質はあまり重要視していないのでOKとしました)
もうひとつは性能についてです。
「どこまでデータが書き込まれているか」の走査は、通常の読み出し操作と異なり、MutableArrayのたくさんの座標の値を読みに行く必要があるため一見すると処理のコストが高そうに見えます。しかし、CASやFetch-and-Addなどと比較するとMutableArrayの読み出しは高速であるため、このコストはあまり大きな問題にはなりません。
また、一度データを読み出しに行っているのに、その場では取り出さずにおいておくというのは、一見すると無駄な処理のように見えますが、各読み出し操作で1つずつデータを読み出すという仕様を実現するためにこのような動作になっています。
速度比較
実際に作ったキュー(KazuraQueue)の速度を他のキューと比較してみましょう。
Chan.Unagiと比較すると、余分なことをしているので遅いはずですが、それでもChanなどよりは速いのが期待する速度です。
測定方法は以下です。
- 同じ種類のキューを10本用意する。
- 各キューに書き込みスレッドと読み出しスレッドをいくつか用意し、合計45000個のデータをキューに通すのを1イテレーションとする。
- 10本のキューで一斉にイテレーションを開始し、イテレーションが終わったら次のイテレーションを開始する
- 合計で20イテレーション終わるまでの時間を計測する
本当は一定時間内で処理できる数を計測したかったのですが、何度か試した限りだとなかなかうまく計測できなかったため、この方法にしました。
計測した環境は、Windows10、CPUはIntel Core i5 2.4GHz(4コア)です。
計測結果は以下です。
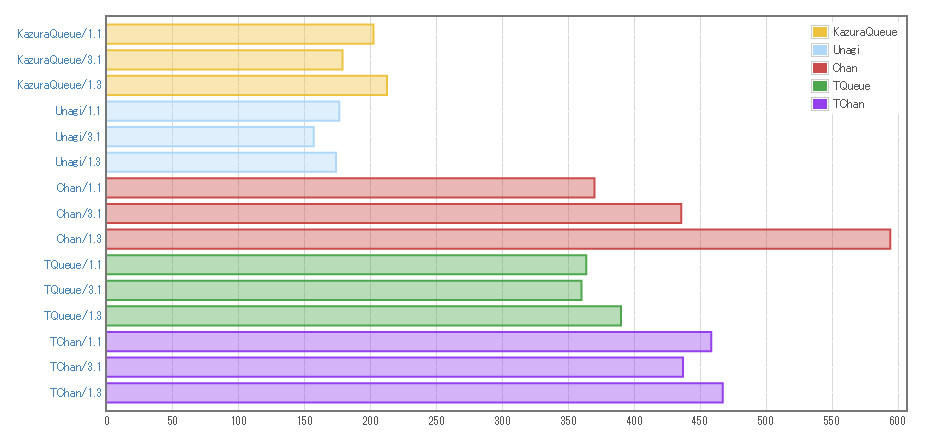
1.1や3.1、1.3は各スレッドに割り当てる書き込みスレッドと読み出しスレッドの数を表しています。(3.1は書き込みスレッド3つと読み出しスレッド1つ)
この結果を見る限り、だいたい期待通りの性能が出ているようです。
まとめ
作成したKazuraQueueの性質と速度のメリット・デメリットをまとめます。
- 速度:Chan.Unagiより若干遅いが、Chan、TQueue、TChanよりは速い
- 「待ち順の公平性」はない
- Chan.Unagiの欠点である「読み出しを行うスレッドに対する非同期例外の扱いが面倒」「データがすぐにGCされない」という性質は克服している
感想
あまりHaskellっぽい話ではないかもしれませんでしたが、Haskellで速度を追求した実装をするにあたって考えたり調べたりしたことの一部を書き出してみました。
前編にも記載していますが、割と自己満足な実装なので実用する機会はないかもしれません。しかし、何かの機会に参考になれば幸いです。
-
厳密にはあるスレッドから書き込まれたデータを読むことができても、別のスレッドからも読むことができるとは限りません。しかし、誰かが書き込まれたデータを読むことができるということは、やがて読めるようになると期待できるので、ブロックせずに繰り返し読み出しを試み続けても、処理のコストはあまり大きくならずにすみます。 ↩