概要
nginx のログを fluend で収集し、
elasticsearch にデータを格納。
kibana で可視化を行います。
目的
アクセス、ユーザーの属性等のログを可視化し、
サービス改善の新たな企画、施策に繋げる。
各種ツール説明
nginx -> websever apache的な
kibana -> データ可視化ツール。グラフ化
elasticsearch -> 全文検索エンジン。Apache Luceneを元に作成されている。同じく Lucene が元になっているものとして solr がある。
fluentd -> ログ収集ツール。様々な input 元、 output 先を設定できる plugin が豊富。Rubyで記述されており、plugin の作成も容易
全体の流れ
nginx -> fluentd -> elasticsearch -> kibana
今回は、すべて 1台のサーバーに配置しています。
出来た kibana の画面
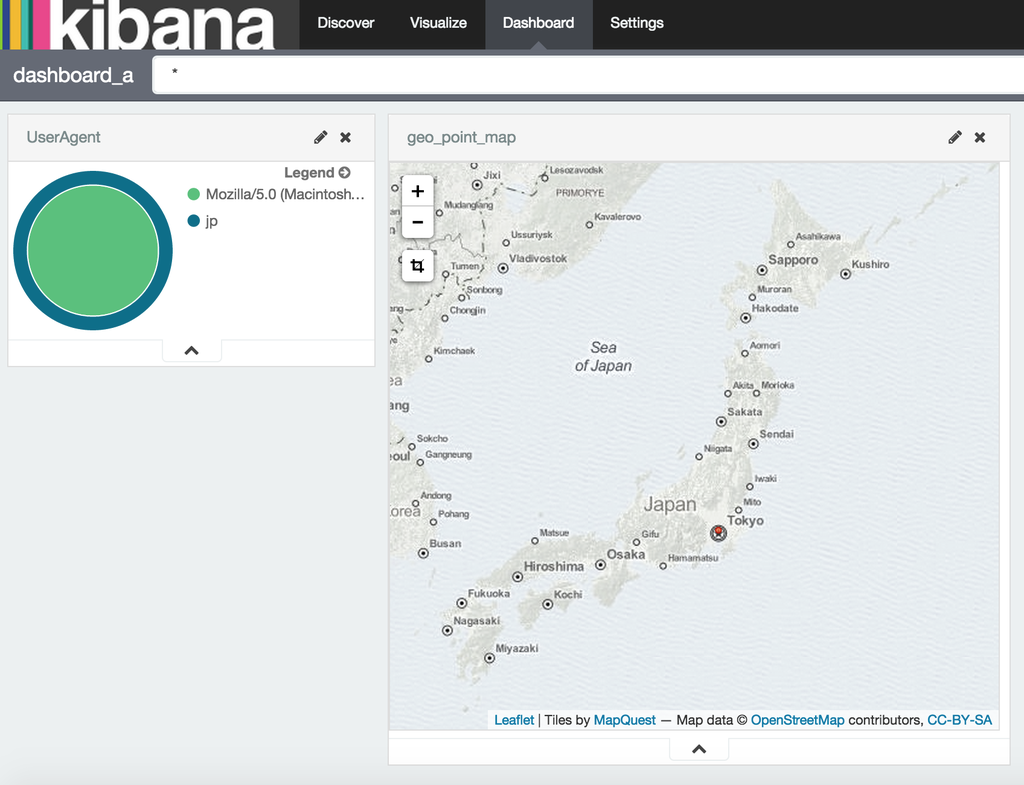
ポイント解説
fluentd
今回の場合は1台で行いましたが、実運用で webサーバー、
ログ収集対象が 1台ということはないと思います。
その場合全台に fluentd を入れ、設定ファイルを仕込む必要があります。
サーバーを chef で構築していれば設定ファイルも同様に配信すればいいと思います。
もし、行っていなくても設定ファイルだけを配置する簡易的なレシピを作ったほうがいいと思います。
<source>
type tail
path /var/log/nginx/access.log
pos_file /var/lib/fluent/access.pos
tag nginx.access
format /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)" "(?<forwader>[^\"]*)")?$/
time_format %d/%b/%Y:%H:%M:%S %z
</source>
上記を web サーバーに仕込む。
format でログ解析の正規表現を指定する。
format nginx.access で nginx のアクセスログ用の format があるが、合わなかったので、それを元に修正。
AWS環境の場合、ELB経由のアクセスだと remote が ELB の ip になる為、x-forwarded-for の値を見る必要がある。
上記正規表現では forwader の箇所に本来のアクセス元の ip が入る。
fluentd では data の流れを tag を元に定義する。
<match nginx.access>
</match>
source ディレクティブに設定した tag に 一番最初にマッチした match ディレクティブが実行される。
※以降、matchするタグがあっても実行されないので注意
<match nginx.access>
type geoip
geoip_lookup_key forwader
<record>
lat ${latitude["forwader"]}
lon ${longitude["forwader"]}
location_properties '{ "lat" : ${latitude["forwader"]}, "lon" : ${longitude["forwader"]} }'
country ${country_code['forwader']}
</record>
tag store.${tag}
</match>
上記のように、match ディレクティブ内で、tag を修正し、
次の match ディレクティブへ処理を引き継ぎながらログの加工等を行う。
上記の match ディレクティブでは geoip プラグインを使用し、
ip アドレスからアクセス元の緯度経度を取得している。
その後、 store. をタグに付与し、次の match ディレクティブへデータを流している。
<match store.**>
type copy
<store>
type stdout
</store>
<store>
type elasticsearch
host localhost
port 9200
type_name nginx
logstash_format true
logstash_prefix nginx-log
logstash_dateformat %Y%m%d
tag_key @log_name
include_tag_key true
flush_interval 10s
</store>
</match>
data を格納する match ディレクティブ。
複数の output 先を用意したい場合は、
type copy を使用し、 ディレクティブを複数記述する。
上記では標準出力と elasticsearch へデータを流している。
設定を行っている時は stdout で確認しつつ行うといい。
elasticseach 設定
elasticsearch はスキーマレスな検索エンジンで、
投入するデータの定義を予め elasticsearch に登録しなくても、
データを入れることが可能。
データを見て、自動的にデータの種別を判別する。
との事だが、基本的には自分の行いたい検索に基いて、mapping 設定を行った方がいい。
nginx ログ時の mapping
{
"template": "nginx-log-*",
"mappings": {
"nginx": {
"properties": {
"agent": {
"type": "string",
"fields": {
"agent": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"forwader": {
"type": "string",
"fields": {
"forwader": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"host": {
"type": "string",
"fields": {
"host": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"path": {
"type": "string",
"fields": {
"path": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"referer": {
"type": "string",
"fields": {
"referer": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"remote": {
"type": "string",
"fields": {
"remote": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
},
"location_properties": {
"type": "geo_point"
}
}
}
}
}
elasticsearch では全文検索の為、自動的に投入したデータに対して、
アナライズが行われる。
その場合特定のデータは、kibana で利用する際に意図したデータとして扱えなくなる。
例:
user_agent
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/600.4.10 (KHTML, like Gecko) Version/8.0.4 Safari/600.4.10
→ Mozilla 5.0 Macintosh Intel のように分割されたデータとして扱われる。
user_agent ごとのアクセス数を出したくても、出せなくなる。
そのように、アナライズしてほしくない場合、完全一致の検索をしたい場合は、
index オプションを not_analyzed に設定する。
また、その場合今度は部分検索が出来なくなるため、
同じデータを複数フィールドで持つことが出来る。
"agent": {
"type": "string",
"fields": {
"agent": {"type": "string", "index": "analyzed"},
"raw": {"type": "string", "index": "not_analyzed"}
}
}
agent フィールドはアナライズ
agent.raw フィールドは アナライズしない
というように mapping 設定を行える。
mapping 設定の注意点
1度、投入したデータは変更が出来ない為、
運用を開始してから今まで投入したデータのマッピングを変更したい。となっても、
以前のデータは救えない。
その為、予めどのように可視化したいかを考え、マッピングを定義する必要がある。
※フィールドの追加は容易?
try & error 時のポイント
マッピング設定をする際になかなかうまくいかなかったりするので
try & error になる。その際に、見るポイント
/var/log/elasticsearch/elasticsearch.log
elasticsearch 側のログを監視
マッピング設定が間違っていた場合に elasticsearch の方でエラーが出て、
index が作成されていない事がある。
マッピングを消すリクエストと
マッピングを確認するリクエスト
以下で確認しつつ進める。
curl -XDELETE 'http://localhost:9200/nginx-log-20150613'
curl -XGET 'localhost:9200/nginx-log-20150613/_mapping/?pretty=true'
kibana
適当にぽちぽち