はじめに
この記事は Qiita Engineer Festa 2022「アルゴリズム強化月間 - 楽しいアルゴリズムの世界を紹介しよう -」に向けて書いた記事です。
メインの部分は以下の2つの論文の結果となります。
A model classifying algorithms as inherently sequential with applications to graph searching
Depth-first search is inherently sequential
また、次の本も参考にしました。
Limits to Parallel Computation: P-Completeness Theory
tl;dr
DFSは ${\rm P}$ 完全問題で、BFSは ${\rm NC}$ に属します。つまり、BFSは並列計算で効率的に計算することができますが、DFSは効率的な並列計算は出来なさそう、ということです。
前提知識
DFSとBFSの一般的なアルゴリズムについては知っているものとします。DFSとBFSを知っていれば読み進められるようにしたつもりですが、「計算量クラス」「帰着(還元)」「困難性・完全性」などの計算複雑性理論(計算量理論)の基本的な部分を知っているとスムーズに理解できると思います。
DFSとBFSの計算量は同じ?
代表的なグラフ探索のアルゴリズムといえばDFS(深さ優先探索)とBFS(幅優先探索)があります。$N$ 頂点、$M$ 辺のグラフにおけるDFSとBFSの時間計算量はどれくらいでしょうか?競プロ等で実装する場合は、どちらも $O(N+M)$ のアルゴリズムを使うと思います。これより効率的なアルゴリズムは存在しないのでしょうか?逐次計算の場合、入力を読み込む時点で $O(N+M)$ かかるのでこれ以上の改善は出来なさそうです。では、並列計算の場合はどうでしょうか?
スパコンの性能を競う「Graph500」にはBFS部門があります。2022年6月のランキングでは「富岳」が1位となりましたが、$N \fallingdotseq 2.2 \times 10^{12}$、$M\fallingdotseq 35.2 \times 10^{12}$のグラフのBFSを約0.34秒で計算しています1。速すぎますね。とても $O(N+M)$ のアルゴリズムでは実現できない速度です。BFSは並列化することで効率的な計算が出来るようです。
世の中の全てのアルゴリズムは並列化すれば効率的な計算が実現できるのでしょうか?実はそんなことはなく、効率的な並列計算が出来ない(と考えられている)アルゴリズムも存在し、その一例がDFSになります。この記事では、BFSの効率的な並列アルゴリズムと、DFSの計算の困難性の証明を紹介します。
並列計算モデル
並列計算の計算量について議論していきたいので、並列計算のモデルを定義します。定義すると言っても、細かな部分は省きます。厳密な定義はこちらを参照してください。
PRAM
PRAM(Parallel Random Access Machine)というモデルを考えます。
- 任意個のプロセッサー $P_0, P_1, P_2,\ldots$を持つ。
- 任意個の共有メモリのセル $M[0],M[1],M[2],\ldots$を持つ。
- 各 $P_i$ は自分のインデックス $i$ を知っており、それぞれの命令列を実行できる。
- 各 $P_i$ は各共有メモリ $M[j]$ に単位時間(1ステップ)でアクセスできる。
- PRAMの命令は以下の3フェーズを1サイクルとして、全プロセッサーが同期されて実行される。
- (必要ならば)共有メモリから値を読み込む
- (必要ならば)計算を行う
- (必要ならば)共有メモリに値を書き込む
- 入力は共有メモリに書き込まれ、出力も共有メモリに書き込む。

並列計算の例1: 総和

長さ $N$ の配列の総和を計算します。図のように2つずつ要素の和を計算することで、要素数が半分になっていくため、$N/2$ 個のプロセッサーで $O(\log N)$ 時間で総和が計算できます。
並列計算の例2: 辞書順比較
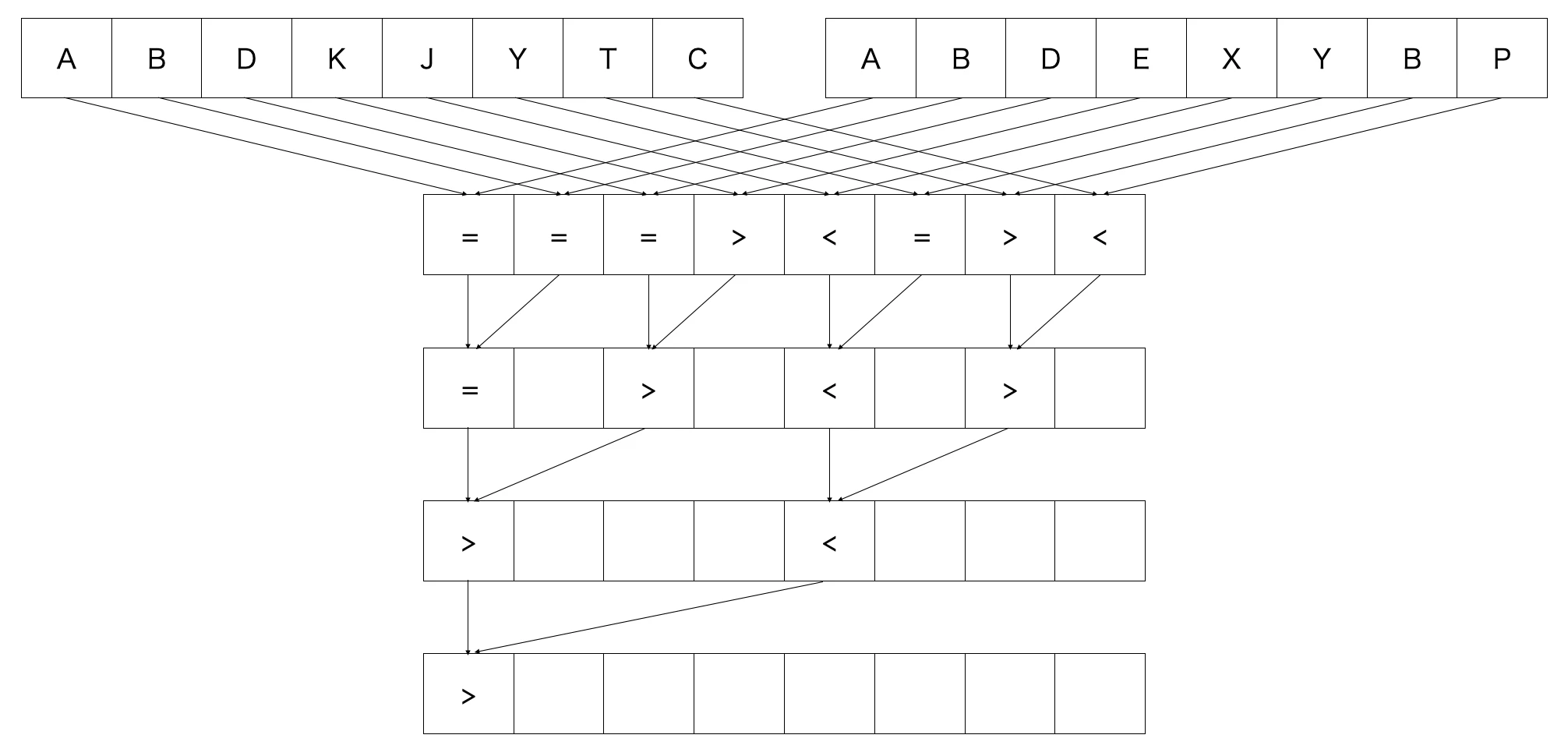
長さ $N$ の2つの文字列の辞書順比較を計算します。初めに各文字について辞書順比較を行います。その後は総和の時と同じく、2つずつ処理します。
- 両方 '=' ならば '=' を書き込む
- 片方のみ '=' ならば '=' でない方の順序を書き込む
- 両方 '=' でないならば、文字列の先頭の方の順序を書き込む
とすれば、最終的に2つの文字列の辞書順比較ができます。$N$ 個のプロセッサーで $O(\log N)$ 時間で計算できました。
計算量クラス
「効率的に並列計算できる」のような特徴で問題を分類するため、計算量クラスを定めます。
2つの計算量クラス ${\rm P}$ と ${\rm NC}$ をPRAMを用いて定義します。${\rm P}$ は ${\rm P }\neq{\rm NP}$ 予想2でお馴染みの、多項式時間で計算可能な問題のクラスで、${\rm NC}$ は並列計算で効率的に解ける問題のクラスです。$n$ を入力長として2つのクラスを以下のように定義します。
$\large{\rm P}$
ある問題をプロセッサー1個、$O(n^k)$ 時間で解くPRAMのアルゴリズムが存在する時、その問題はクラス ${\rm P}$ に属する。ただし、$k$ は $n$ に依存しない定数である。
$\large{\rm NC}$
ある問題をプロセッサー $O(n^{k_1})$ 個、$O(\log^{k_2} n)$ 時間で解くPRAMのアルゴリズムが存在する時、その問題はクラス ${\rm NC}$ に属する。ただし、$k_1$, $k_2$ は $n$ に依存しない定数である。
ここで「問題」と言っているのは「判定問題」、つまり答え(出力)が Yes or No(0 or 1)になるものに限定します。例に挙げた総和の問題なら、入力を長さ $N$ の配列と1つの値 $v$ にして「配列の総和が $v$ に等しいか?」という問題にします。
クラスの定義としては判定問題に限定しますが、任意長の出力をする問題がプロセッサー $O(n^{k_1})$ 個・$O(\log^{k_2} n)$ 時間で解ける時も「${\rm NC}$ で解ける」や「${\rm NC}$ アルゴリズムがある」と言うことにします。説明が楽になるので、割とざっくりと「${\rm NC}$」という用語を使っていきます。
${\rm NC}$ のアルゴリズムを、各プロセッサーを逐次的にシミュレーションしても全体として多項式時間にしかならないため3、問題 $L$ について $L \in {\rm NC} \Rightarrow L \in {\rm P}$ が成り立ちます(逆は言えません)。つまり、クラスの包含関係は ${\rm NC} \subseteq {\rm P}$ となります。

P完全
問題の"難しさ"を測るために、P完全という概念を紹介します。
2つの判定問題 $A$ と $B$ の難しさの比較がしたいです。$A$ の任意のインスタンス $x$ を $B$ のインスタンスに変換するアルゴリズム $f$ があったとします( $f$ は任意長の出力が可能とします)。つまり、$f(x)$ は $B$ のインスタンスです。$f(x)$ の答えが $x$ の答えと一致する時、問題 $B$ が解ければ問題 $A$ も自動的に解けることになります。なぜなら、$f(x)$ の答えをそのまま $x$ の答えとして出力すればよいですからです。よって、このようなアルゴリズム $f$ が存在すれば、$B$ の解法を用いて $A$ が解けたことになるので、問題 $A$ は問題 $B$ より難しくないと言えそうです。このように別の問題に変換することを「帰着」や「還元」(英語では reduction)と呼びます。

ここで注意しなければならないのが帰着アルゴリズム $f$ の計算量です。仮に $f$ の計算量として、問題 $A$ を解くのに十分なものが許されているとします。この時、
- $f$: 0 or 1を出力する問題 $A$ を解くアルゴリズム
- 帰着される問題 $B$ : 入力の値は1か?
とすることができます。このように問題 $B$ が簡単すぎる状況で「問題 $A$ は問題 $B$ より難しくない」と言っても何の意味もありません。帰着のアルゴリズムは適切な計算量を設定しなければならないです。
困難性と完全性
ここで計算量理論で重要な困難性と完全性について定義します。計算量を ${\rm NC}$ に限った帰着アルゴリズムを ${\rm NC}$ 帰着と呼び、問題 $A$ から問題 $B$ へ ${\rm NC}$ 帰着できることを $A \le_{\rm NC} B$ と表すことにします。
$\large{\rm P困難}$
問題 $L$ が ${\rm P}$ 困難であるとは、クラス ${\rm P}$ に属する任意の問題 $A$ について $A\le_{\rm NC} L$ であることをいう。
$\large{\rm P完全}$
問題 $L$ が ${\rm P}$ 完全であるとは、$L$ が ${\rm P}$ 困難かつクラス ${\rm P}$ に属することをいう。
感覚的な説明としては、${\rm P}$ 完全な問題とは、クラス ${\rm P}$ の任意の問題より難しい問題、つまり、クラス ${\rm P}$ の中で最も難しい問題となります。
もし何らかの ${\rm P}$ 完全な問題を解く ${\rm NC}$ アルゴリズム $M$ を見つけたとします。クラス ${\rm P}$ の問題 $A$ を「問題 $A$ から ${\rm P}$ 完全問題へ ${\rm NC}$ 帰着し、その帰着された問題をアルゴリズム $M$ で解く」という方法で計算することを考えます。
- ${\rm NC}$ 帰着の計算量: プロセッサー $O(n^{k_1})$ 個・$O(\log^{k_2} n)$ 時間
- $M$ の計算量: プロセッサー $O(n^{l_1})$ 個・$O(\log^{l_2} n)$ 時間
だとします。帰着した${\rm P}$ 完全問題のインスタンスの入力長は高々 $O(n^{k_1}\cdot\log^{k_2} n)$、もっと大雑把に高々 $O(n^{k_1+k_2})$ と見積もれます。よって、この入力に対する $M$ の計算量は
- プロセッサー $O((n^{k_1+k_2})^{l_1})=O(n^{l_1(k_1+k_2)})$ 個
- $O((\log n^{k_1+k_2})^{l_2})=O(\log^{l_2} n)$ 時間
となります。帰着の計算量と合わせても、全体の計算量は ${\rm NC}$ に収まっています。つまり、問題 $A$ も ${\rm NC}$ に属することがいえました。
帰着の計算量を ${\rm NC}$ に制限しましたが、このことにより、もし何らかの ${\rm P}$ 完全な問題を解く ${\rm NC}$ アルゴリズムを見つけたとすると、全てのクラス ${\rm P}$ に属する問題が ${\rm NC}$ に属する、つまり ${\rm P} = {\rm NC}$ であることが言えるわけです4。現状、任意の ${\rm P}$ に属する問題が並列計算で対数多項式時間で解けるというのは考え難いので、${\rm P}$ 完全問題であるということは、効率的な並列計算が存在しないことの強力な示唆となります。
ここでようやくこの記事で示すことがちゃんと記述できます。BFSは ${\rm NC}$ に属し、DFS は ${\rm P}$ 完全問題であることを示します。
ある問題 $A$ が ${\rm P}$ 困難であることを示すには、一つの ${\rm P}$ 困難な問題 $B$ から $B \le_{\rm NC} A$ であることを示せばよいです。なぜならば ${\rm NC}$ 帰着は推移的、つまり、$A\le_{\rm NC} B$ かつ $B\le_{\rm NC} C$ ならば $A\le_{\rm NC} C$ であることが成り立つからです。これは上記の、${\rm NC}$ 帰着した後 ${\rm NC}$ アルゴリズムで問題を解いても全体で ${\rm NC}$ であることと同様の議論で示せます。DFSの ${\rm P}$ 困難性も別の ${\rm P}$ 困難な問題からの帰着で証明します。
BFSのNCアルゴリズム
BFSが ${\rm NC}$ に属することを証明します。基本的な方針は、グラフの隣接行列の行列累乗で、各頂点までの最短距離を $O(\log^2 N)$ 時間で求めるというものです。ただ、これだけだと不十分で、距離を求めた後に同一距離の頂点の順序計算を効率的に行います。
BFSの判定問題
「${\rm NC}$ に属する」ことを証明するので、BFSの判定問題を考えます。
- 入力: グラフ $G=(V, E)$、始点 $s \in V$ と2頂点 $v, u \in V$
- 出力: $G$ を $s$ を始点としてBFSで探索したときに、$v$ を $u$ より先に訪れるか?
これで判定問題となりました。以降の議論では、簡単のため $s$ から $V$ の任意の頂点へ到達可能であるとします。また、グラフ $G$ は隣接リストで表現されているとし、BFSはこの隣接リストの順番に従って実行されるものとします。距離計算のところで隣接行列を用いますが、隣接リストから隣接行列への変換は ${\rm NC}$ で計算できます(簡単なので各自考えてみて下さい)。
この判定問題が ${\rm NC}$ で解けたならば、「$N$ 頂点をBFSで訪れる順に出力する」という問題も${\rm NC}$ で解けます。簡単にアルゴリズムを説明すると、まず、$N\choose 2$ 個の全頂点のペアについて、並列に上記判定問題を解いて答えを書き出します。次に各頂点について並列に、「自分より先に訪れる頂点の個数」を総和の計算の要領で $O(\log N)$ 時間で求めます。これで各頂点を何番目に訪れるかが、全体として ${\rm NC}$ で解けました。
距離計算
BFSの判定問題を解いていきます。もし2頂点 $v, u$ の始点 $s$ からの距離が異なれば、どちらを先に訪れるかが分かります。この距離計算ですが、$(\mathbb{N}\cup\{\infty\}, \min, +)$ という半環(トロピカル半環)上で隣接行列を $N$ 乗することで計算できます。簡単に言うと、普通の行列積の掛け算の代わりに足し算、足し算の代わりに2要素の$\min$を取るのですが、足し算は経路長の和を計算し、$\min$は一番短い経路を選ぶ操作となります。これについては日本語解説記事も多くあるので、ここでは説明を省略します。以下の記事等を参考にしてください。「トロピカル代数 グラフ」と検索しても色々出てきます。
動的計画法を実現する代数〜トロピカル演算でグラフの最短経路を計算する〜
行列積一回の計算量を考えます。計算結果の$N^2$ 個の各要素は並列に計算します。各要素について、プロセッサー $N$ 個で「$N$ 個の足し算を行う$\rightarrow N$ 要素の$\min$を取る」という操作を、例に挙げた辞書順比較の要領で $O(\log N)$ 時間で行います。全体でプロセッサー $N^3$ 個・$O(\log N)$ 時間で計算できました。$N$ 乗を計算するには行列積を $O(\log N)$ 回行えばよいので、プロセッサー $N^3$ 個・$O(\log^2 N)$ 時間で計算できることが分かりました。
同一距離の2頂点の順序計算
距離計算ができましたが、2頂点 $v, u$ の始点 $s$ からの距離がどちらも同じ $d$ だったとすると、どちらを先に訪れるのかまだ分かりません。BFSの探索において、$v, u$ にたどり着くまでに通った $d$ 個の頂点がそれぞれ分かれば順序を判定できそうです。言い換えると、探索のBFS木における、根 $s$ から $v, u$ へのパスを計算します。2つのパスが分岐するところで、分岐元の頂点の隣接リストにおいて、分岐先の2頂点どちらが先に現れるかを調べれば、それがそのまま $v,u$ の順序となります。

根 $s$ から $v$ へのパスの計算方法を説明します。
- グラフの辺 $e \in E$ の内、距離 $i$ の頂点から距離 $i+1$ の頂点へと繋がる辺のみを選択し、$G$ の部分グラフ $G'=(V, E')$ を作ります($i$ は $0$ 以上グラフの直径未満の任意の整数です)。BFS木はこの $G'$ のさらに部分グラフとなっていることが分かります。
- $G'$ において $v$ へ到達可能な頂点を全て列挙します($v$ 自身も含みます)。これは、グラフの辺の向きを逆にする必要がありますが、距離計算と全く同じ方法で計算できます。列挙した頂点集合を $V'$ とします。$s$ から $v$ へのパスは、$V'$ の頂点から構成されます。
- $V'$ の各頂点について、自身から出る辺 $e \in E'$ の内、$V'$に含まれる頂点で隣接リストに一番先に登場するものへと繋がる辺を選びます。$v$ へ到達可能なので、$v$ 以外の頂点においてはこのような辺が選べ、選んだ辺の集合を $E''$ とします。グラフ $G''=(V', E'')$ は木となります。
- $G''$ における $s$ から $v$ へのパスを計算します。これが求めるパスとなります。

求めるパスにおいて、$s$ の次に来る頂点というのは、$v$ へ到達可能な頂点の内、隣接リストに一番先に出てくる頂点となります。それ以降の頂点でも、$v$ へ到達可能な頂点の内、隣接リストに一番先に出てくる頂点をたどることになるので、上のアルゴリズムが正しいことが分かります。
計算量がどれくらいになるのか見ていきます。
- $G'$ を作成するには、すでに計算した距離を参照するだけなので、プロセッサー $N^2$ 個・$O(1)$ 時間で計算できます。
- $V'$ を構成する計算量は距離計算と同じ、プロセッサー $O(N^3)$ 個・$O(\log^2 N)$ 時間となります。
- $G''$ の作成ですが、$V'$の各頂点について並列に計算します。各頂点で、隣接リストに含まれる頂点が $V'$ に含まれるかチェックし、含まれる頂点の内一番先に登場する頂点を出力します。これは例に挙げた辞書順比較と同じ要領で、プロセッサー $O(N)$ 個・$O(\log N)$ 時間でできます。全体でプロセッサー $O(N^2)$ 個・$O(\log N)$ 時間となります。
- パス計算ですが、$G''$ において $s$ から到達可能な頂点が、そのまま求めるパスを構成する頂点になるので、距離計算と同様に、プロセッサー $O(N^3)$ 個・$O(\log^2 N)$ 時間で計算できます。ダブリング5で賢く計算すればプロセッサー $O(N)$ 個で済みます。
最後の2つのパスの比較ですが、プロセッサー $O(N)$ 個で、どこで分岐するかを $O(1)$ 時間で見つけられ、分岐先の2頂点の比較も $O(1)$ 時間でできます。
以上より、全体でプロセッサー $O(N^3)$ 個・$O(\log^2 N)$ 時間で計算でき、${\rm NC}$ に収まることが分かりました。
DFSがP完全であることの証明
${\rm P}$ 完全問題の代表例として、CVP(Circuit Value Problem)という組み合わせ論理回路を評価する問題があります。このCVPからDFSへの ${\rm NC}$ 帰着が存在することを示して、DFSが ${\rm P}$ 完全であることを証明します。CVPが ${\rm P}$ 完全であることの証明は、少々テクニカルでチューリングマシンの扱いに慣れていないと理解するのが難しいため、付録として末尾に記載します。
CVP(Circuit Value Problem)
CVPは次のような問題になります。
- 入力: 組み合わせ論理回路 $C$ と $C$ への入力 $x\in\{0,1\}^n$
- 出力: 入力 $x$ に対する $C$ の値 $C(x)\in\{0, 1\}$
一つ注意ですが、入力長は $n$ だけでなく、回路 $C$ の記述長(回路に含まれるゲート数に比例)も含みます。この問題は、論理ゲートの値を一つずつ計算していけば解けるので、線形時間で解けます。つまり、クラス ${\rm P}$ に属します。

さらに、この問題は ${\rm P}$ 困難です。${\rm P}$ に属する問題 $A$ のインスタンス $x$ をCVPに帰着する方法を簡単に説明します。まず、問題 $A$ は ${\rm P}$ に属するので、$A$ を解く多項式時間アルゴリズム $M$ が存在します。$M$ を計算する回路 $C_M$ が存在すれば、帰着は
$x\rightarrow C_M, x$
とすればよいです。$C_M(x)$ は $x$ を $M$ で解いた答えと一致します。現実の計算機も論理回路で構成されていることから、このような回路 $C_M$ を構成することは直観的にはできそうです。繰り返し処理なんかはどう表現するんだ?と思うかもしれませんが、ループする分だけ回路を縦に積み重ねればよいです。$M$ は多項式時間で止まるアルゴリズムなので、このようにしても $C_M$ のサイズは高々多項式サイズになります。
厳密な証明ではチューリングマシンを回路でシミュレートします。付録の証明を参照してください。
NORゲートやNANDゲートは1種類で任意の論理演算ができます。ですので、回路のゲートをそれらに制限したNORCVPやNANDCVPも ${\rm P}$ 完全問題となります。DFSへの帰着はNORCVPからの帰着を示します。
NORCVPからDFSへのNC帰着
BFSのときと同様にDFSの判定問題を以下のように定めます。
- 入力: グラフ $G=(V, E)$、始点 $s \in V$ と2頂点 $v, u \in V$
- 出力: $G$ を $s$ を始点としてDFSで探索したときに、$v$ を $u$ より先に訪れるか?
また、NORCVPのインスタンスとして、
- 回路: $C=(C_0, C_1,\ldots,C_N)$
- $C_i$ は各ゲート
- $C_0$は定数ゲートで $C_0=0$ とする
- $C_i = \neg (C_{i_1} \lor C_{i_2})\ \ \ \ (1\le i\le N$ かつ $0 \le i_1, i_2<i)$
- (必然的に $C_1=1$ となる)
となるものを考えます。CVPの説明では回路と入力は別に考えていましたが、今は入力は回路にエンコードされているとします。$C_N$ の値が回路 $C$ の出力です。
回路 $C$ からグラフを作っていきます。各 $C_i$ に対して同じ構造のグラフを作成します。$C_i$ が入力に現れるゲートが $C_{j_1},C_{j_2},\ldots,C_{j_k}\ \ (i < j_1,\ldots,j_k \le N)$ であるとき、下図のようなグラフ $G_i$ を考えます。

$G_i$ を構成する頂点は $\{{\rm Enter}(i),$ ${\rm IN}(i,i_1),$ ${\rm IN}(i,i_2),$ ${\rm S}(i),$ ${\rm OUT}(i,1),\ldots,{\rm OUT}(i,k),$ ${\rm T}(i),$ ${\rm Exit}(i)\}$ で、図のように辺を張ります。辺に付いている数字は隣接リストに登場する順番です。
図を見ると、$G_{i}$ と $G_{i-1}$ が辺 $({\rm Exit}(i-1), {\rm Enter}(i))$ で繋がっており、$G_i$ と $G_{j_1},\ldots,G_{j_k}$が $2k$ 本の辺で繋がっていることが分かります。
$G_i$ 上で ${\rm Enter}(i)$ を始点にしてDFSしてみます。
- どの頂点も未訪問の場合、探索の順序は下図Type.Aのようになる
- ${\rm IN}(i,i_1)$ か ${\rm IN}(i,i_2)$ が訪問済みの場合、探索の順序は下図Type.Bのようになる
どちらの場合でも、$G_i$ 上の ${\rm IN}(i,i_1)$ と ${\rm IN}(i,i_2)$ 以外の全ての頂点を訪問し、${\rm Exit}(i)$ に到達します。この後も探索を進めるならば ${\rm Enter}(i+1)$ に進むことになります。

$G$ を $G_1,G_2,\ldots,G_N$ と ${\rm Exit}(0)$ からなるグラフとします。このとき以下の同値関係が成り立ちます。
$G$ を ${\rm Exit}(0)$ を始点にDFSで探索したとき、${\rm S}(N)$ を${\rm T}(N)$ より先に訪れる $\Leftrightarrow$ $C$ の出力は $1$
つまり、帰着するDFSのインスタンスとして、グラフ $G$・始点 ${\rm Exit}(0)$・2頂点 ${\rm S}(N), {\rm T}(N)$ を出力すればよいということです。次が $1\le i \le N$ で成り立てば、上記が証明できます。
- $C_i = 1$ のとき、$G_i$ におけるDFSの探索順序はType.Aになる
- $C_i = 0$ のとき、$G_i$ におけるDFSの探索順序はType.Bになる
帰納法で証明します。
i=1のとき
${\rm Exit}(0)$ から ${\rm Enter}(1)$ に来た時、$G_1$ はまだどの頂点も訪問されていないのでType.Aとなります。$C_1=1$ なので成り立ちます。
i=tのとき
$t$ 未満で成り立っているとします。$C_t= \neg (C_{t_1} \lor C_{t_2})\ \ (t_1, t_2 < t)$ とします。
$C_{t_1} = 0$ かつ $C_{t_2} = 0$ の場合、${\rm IN}(t,t_1)$ と ${\rm IN}(t,t_2)$ のどちらも未訪問となるためType.Aになります。$C_t = 1$ となるので成立します。
$C_{t_1} = 1$ または $C_{t_2} = 1$ の場合、${\rm IN}(t,t_1)$ か ${\rm IN}(t,t_2)$ のどちらかは訪問済みのためType.Bになります。$C_t=0$ となるので成立します。
以上で証明できました。最後に $C$ から $G$ への変換の計算量を考えます。$G$ の頂点数は $O(N)$ で、1頂点から高々2本の辺が出ています。各頂点のインデックスが分かれば $O(1)$ 時間で処理できます。各 $i$ について $k$ を並列に計算し、それをプロセッサー $O(N)$ 個・$O(\log N)$ 時間で集計すればよいです。全体でプロセッサー $O(N^2)$ 個・$O(\log N)$ 時間で帰着が計算できます。以上でDFSが ${\rm P}$ 完全であることが示せました。
まとめ
BFSが ${\rm NC}$ に属し、DFSが ${\rm P}$ 完全であることを示しました。同じ計算量のアルゴリズムで実装されることが多いですが、計算量理論的には全く別の特徴を持つというのは面白いですね。
似たような話として、2頂点間の到達可能性判定問題が
- 無向グラフの場合、クラス ${\rm L}$ (決定性対数領域計算可能クラス) の完全問題
- 有向グラフの場合、クラス ${\rm NL}$ (非決定性対数領域計算可能クラス) の完全問題
であることが知られています。${\rm P\ vs\ NP}$ と同様に ${\rm L\ vs\ NL}$ も未解決問題です。他にも様々な未解決問題や興味深い話題があります。是非調べてみて下さい。
付録: CVPがP困難であることの証明
任意のクラス ${\rm P}$ に属する問題が、CVP(Circuit Value Problem)に ${\rm NC}$ 帰着できることを示します。${\rm P}$ に属する問題を解くチューリングマシン $M$ を考えます。CVPの紹介のところで説明した通り、$M$ をシミュレートする回路が構成できればよいです。$M$ は以下を満たすとします。
- 片側(右側)無限の1テープを持つ
- 入力は左詰で書き込まれ、出力は最左のセルに0 or 1を書き込む
- 初期状態でヘッドは最左のセルを指している
- アルファベット集合は $\Sigma$、状態集合は $Q$、遷移関数は $\delta$ である
- 入力長 $n$ に対して、$t(n)=n^{O(1)}$ 時間で止まる
$M$ は $t(n)$ 時間で止まるので、高々 $t(n)+1$ 個のセルにしか触ることができません。この $t(n)+1$ 個のセルを回路でシミュレートします。時間 $i$ $(0\le i \le t(n))$ の左から $j$ $(0 \le j \le t(n))$ 番目のセルの状態 $r_{i,j}$ を表す $\left|\Sigma\right| + \left|Q\right|+1$ 個のブール変数を考えます。
- $r_{i,j}^{\sigma}$: セルに $\sigma$ が書かれているときに $True$ $(\sigma\in \Sigma)$
- $r_{i,j}^{q}$: ヘッドがセルを指しており、状態が $q$ のときに $True$ $(q\in Q)$
- $r_{i,j}^{\neg}$: ヘッドがセルを指していないときに $True$
$i \ge 1$ のとき、状態 $r_{i,j}$ は3つの状態 $r_{i-1,j-1}, r_{i-1,j}, r_{i-1,j+1}$ にのみ依存して決まります。それぞれのブール変数がどのように計算できるか見ていきます。
セルに書かれているアルファベット
時間 $i$ でセル $j$ に $\sigma$ が書かれるのは、時間 $i-1$ で
- ヘッドがセル $j$ にあり $\sigma$ が書き込まれる
- ヘッドがセル $j$ になく元々 $\sigma$ が書かれている
のどちらかのときです。よって、

として、

と計算できます。(qiitaで\coloneqqや\bigveeが使えないので画像を挿入しました。)
状態とヘッド
時間 $i$ で状態が $q$ でヘッドがセル $j$ にあるのは、時間 $i-1$ で
- ヘッドがセル $j+1$ にあり、左に移動し状態 $q$ に遷移する
- ヘッドがセル $j-1$ にあり、右に移動し状態 $q$ に遷移する
のどちらかのときです。よって、

として、

と計算できます。
ヘッドが指していない
時間 $i$ でヘッドがセル $j$ を指していないのは、時間 $i-1$ で
- ヘッドがセル $j-1$ にあり左に移動する
- ヘッドがセル $j+1$ にあり右に移動する
- ヘッドがセル $j$ にある
- ヘッドがセル $j-1,j,j+1$ のどれにもない
のいずれかのときです。よって、

として、

と計算できます。
以上でチューリングマシン $M$ をシミュレートする回路が構成できました(両端のセルの処理等の細かい部分は説明を省きました)。$r_{t(n),0}^1$ が $True$ かどうかで $M$ の出力が 1 かどうかが分かります。$r_{i,j}$ を計算する部分回路のサイズは、$\left|\Sigma\right|$ と $\left|Q\right|$ が定数なので、定数サイズとなります。$(t(n)+1)^2=n^{O(1)}$ なので、回路全体のサイズも多項式サイズとなります。よって、帰着の計算量は明らかに ${\rm NC}$ に収まります。