オーディオマニア(非エンジニア)がネット上の情報を見ながらアップサンプリングソフトを作ってみました。
電気・情報系の大学で学んだわけでもなく独学ですので「ぼくの考えた最強」の域を出ませんが、なんとか動作するものが出来たので記事にしてみます。
ちなみにsoxのアップサンプリングは十分な精度があってスピードも速いので車輪の再発明をする意味はあまりありません。
要素技術
それぞれググれば参考になるサイトがいくつもヒットします。
色々見すぎてどれを参考にしたのかわからなくなってしまった項目はリンクなしです。
- デジタルフィルタ(FIR)
- FFTを使った畳み込み
- overlap-save法を使った直線畳み込み
- 整数倍のアップサンプリング
- 整数分の1のダウンサンプリング
- FFTを利用したサンプリング周波数変換
- FFTW3
- 高速な言語(nim)
- sox
デジタルフィルタ(FIR)
FIRの方が簡単に望む特性が出しやすいのでFIRで行きます。
フィルタの設計はMatLab等の数値計算ソフトで簡単にできます。
私はフリーのGnu Octave を使っています。
理想ローパスフィルタの場合、無限の長さが必要になります。
有限の長さに収めるために切り詰めると特性が悪化します。
帯域内がフラットにならない、遷移帯域ができる、阻止帯域がゼロにならないなど。
窓関数をかけることによって改善することができますが、遷移帯域幅と阻止帯域の減衰量は相反します。
私は主にカイザー窓を使ってます(よくわかってない)。
作った係数を適応するには「畳み込み」という計算をします。
FFTを使った畳み込み
係数と音声データ両方を「同じ」長さに揃えてそれぞれFFTして周波数軸にします。結果は複素数になります。
それぞれの周波数成分を乗算します。
その結果をIFFTすれば畳み込みを行うことができます。
この方法により計算量を劇的に減らすことができます。
overlap-save法を使った直線畳み込み
音声信号なんかの長く続くデータに短いフィルタ係数を畳み込むのに使います。
2倍のデータで行う例
フィルタ係数長がNのときにフィルタの前にN個のゼロをつけて長さ2Nにする
長さ2NのフィルタをFFTする(結果は複素数)
while データがなくなるまで
N個音声データを読み込む
前回のデータが前半、今回読み込んだデータが後半の長さ2Nのデータにする
長さ2NのデータをFFTする(結果は複素数)
FFTした音声データと予めFFTしたフィルタ係数をそれぞれ乗算
結果をIFFTする(実数になる)
IFFTした結果(長さ2N)の前半のN個を出力する
endwhile
整数倍のアップサンプリング
正しい方法
- ゼロ挿入
- ローパスフィルタでエイリアシングノイズを除去
間違った方法
- ぼくの考えた最強の曲線で補完
- サンプルホールドして階段状波形にしてからローパスフィルタでノイズ除去
間違った方法だとエイリアシングノイズが残ったり、もとの帯域内が変化したりします。
整数分の1のダウンサンプリング
ローパスフィルタで変換後のサンプリング周波数の1/2以上の周波数成分を除去後にデーターを間引く
ローパスフィルタの特性が悪いとエイリアシングノイズが出たり、変換後の帯域内のデータが変化したりします
FFTを利用したサンプルレート変換
N個のデータをFFTした結果(N個の複素数)の高い周波数成分をなくしてN/2個のデータにしてIFFTすればサンプリング周波数は半分になります。
N個のデータをFFTした結果(N個の複素数)に高い周波数成分を加えて2N個の複素数にしてIFFTすればサンプリング周波数は2倍になります。
特性を良くするには適切なフィルタをFFTして掛ける必要があります。
FFTW3
FFTはよく使用される計算なのでいくつかライブラリがあります。
その中でフリーで使えて高速なFFTW3を使っていきます。
ライセンスはGPLなのでそれに従います。
公式サイト https://www.fftw.org/
日本語 @wiki https://w.atwiki.jp/amaeda/ 古いですが使い方は変わってません
使用する関数はとりあえずこの5つ
- fftw_plan_dft_r2c_1d
- fftw_plan_dft_c2r_1d
- fftw_execute
- fftw_import_wisdom_from_file
- fftw_export_wisdom_to_file
fftw_plan_dft_r2c_1d 実数データをFFT(結果は複素数、共役部分は省かれます)するプランを作ります
fftw_plan_dft_c2r_1d 複素数(共役複素数を自動で補います)をIFFTして実数データにするプランを作ります
fftw_execute 作ったプランを実行します
fftw_import_wisdom_from_file wisdomをファイルから読み込みます
fftw_export_wisdom_to_file wisdomをファイルに書き込みます
プランを作るときには FFTW_EXHAUSTIVE を指定します。初回は時間がかかりますが、wisdomを保存して次回に読み込むことで2回目以降は一番高速に実行できます
高速な言語(nim)
プログラミングするにはプログラミング言語が必要です。
どんな言語を使っても構わないのですが、高速でFFTW3が使える必要があります。
ここは私の好みで「Nim」を使うことにします。
Nimはスクリプト言語感覚で初心者にも優しい言語だと思います。
情報が少ないのが難点ですが。
fftw3は nimble install fftw3 で使えますが、実行ファイルが肥大化します。
nimbleでインストールできるfftw3.nimの前身の https://github.com/ziotom78/nimfftw3/blob/master/fftw3.nim から必要な関数のみを抜き出して使いました。
関数の使い方が若干違ってます。
sox
公式サイト https://sourceforge.net/projects/sox/
音声処理のスイスアーミーナイフと呼ばれる多機能ソフトです。
音声ファイルのフォーマット変換をこれに任せば楽です。
ライセンスはLGPL
アップサンプリングソフト(44.1Kから96KHz)を作る
44.1KHzから96KHzへのアップサンプリングソフトを作ります。
入力はint32、float64で計算して、int32で出力することにします。
320倍にアップサンプリングして1/147にダウンサンプリングすれば良いのですが、さすがに面倒です。
FFTを使ったサンプルレート変換にします。
音声データを147の倍数で取り込みます。今回は10倍の1470サンプルで行きます。
overlap-save法のために2倍の2940サンプルをFFTします。
FFTW3 の r2c_1dを使うので共役分を省いた1471の複素数になります。
このデータに高域ぶんを水増しして長さ3201のデータにします。
ローパスフィルタは長さ96KHz、長さ3200で作って前半にゼロを付け加えて6400のフィルタにします。
これをFFTして音声データをFFTしたものに掛けます。
結果をFFTW3 のc2r_1dでIFFTして6400の実数データにします。
6400のうち、前半の3200を出力すれば96KHzに変換できます。
フィルタ特性をどうするか?
フィルタの最適な設計なんて出来ないので、グラフで特性を確認しながら適当に調節していきます。
96KHzで長さ3200、カットオフ21750Hz、窓関数kaiser(β値30)
出来上がった直線位相フィルタ特性
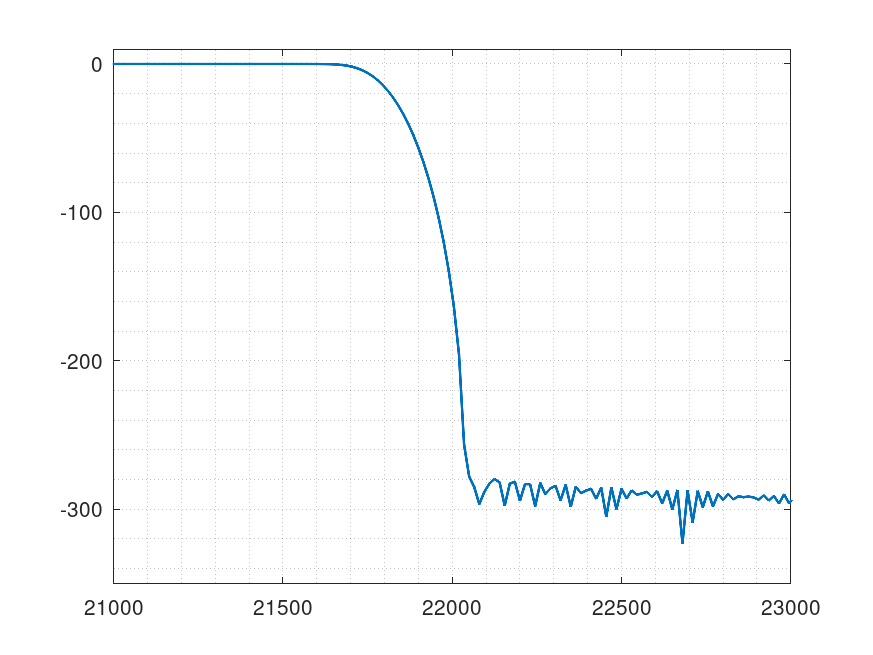
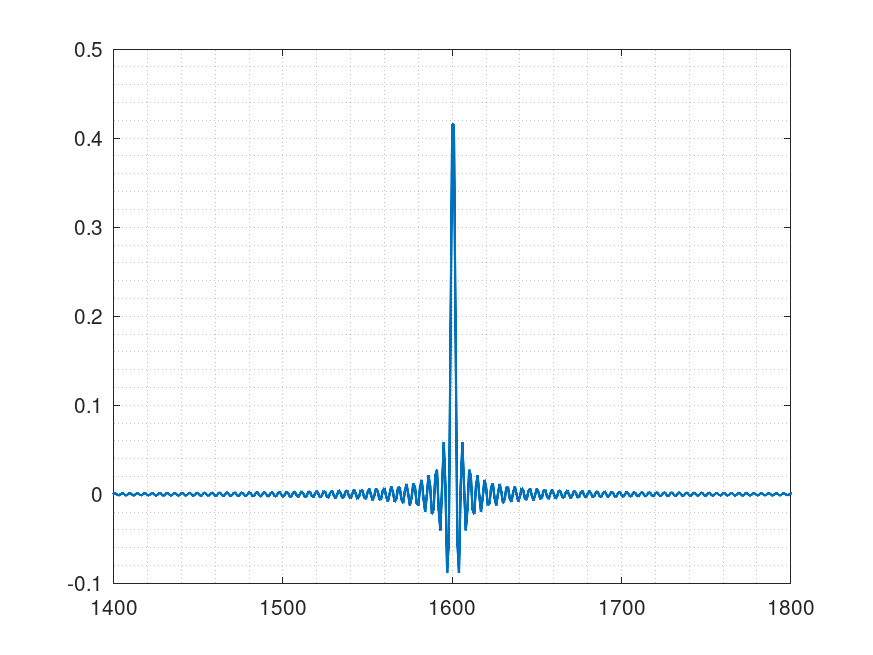
変換して最小位相も作った
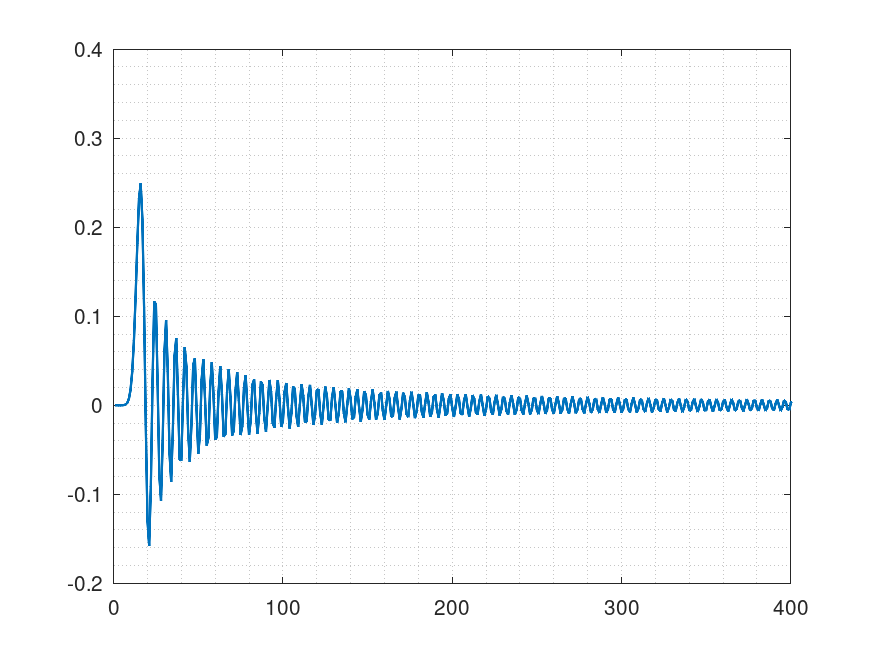
帯域外の減衰量はここまで頑張らなくても良かったかも。どうせ32bit出力なので。
フィルタ特性が悪化する!
さて、このフィルタ特性がそのままなら良いのですが、
「FFTした結果の周波数軸で高域を急にゼロにすると特性が悪化」します。
22.05KHz以上をゼロにした場合です。
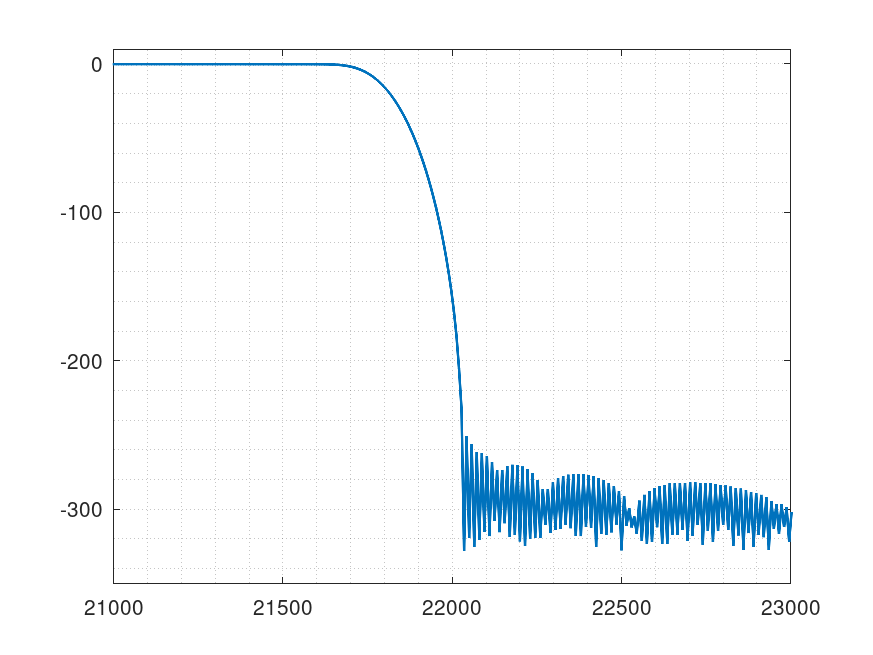
FFTした結果同士を乗算するのは良いのですが、FFTした結果を直接乗算・除算しても思った特性にはなりません。
本来ならばミラーイメージが繰り返し現れるはずなのに、それを急にゼロにしては行けないのです。
FFTした結果の44.1KHz以上をゼロにしたときのフィルタ特性
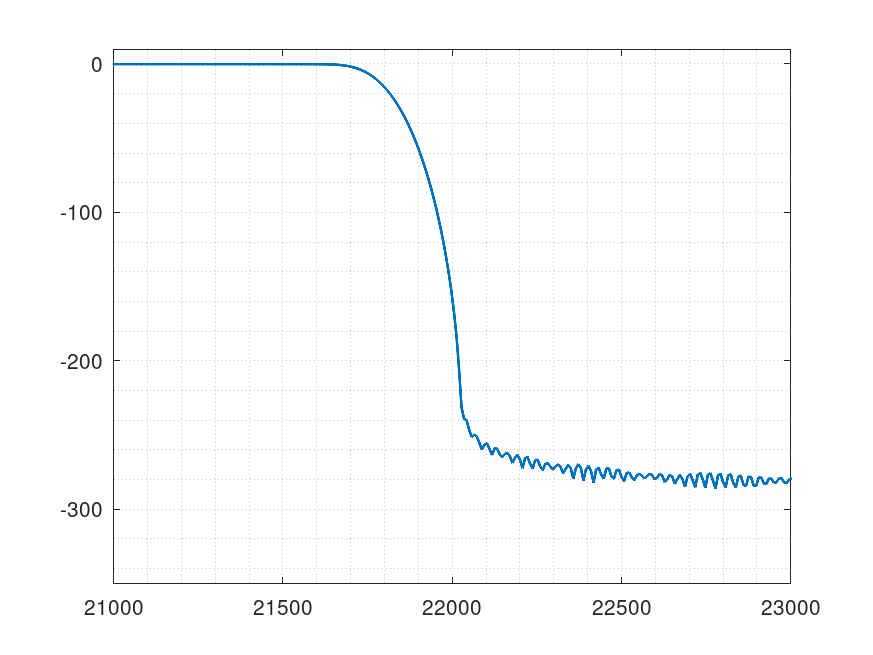
もちろんミラーイメージを完全に残したままフィルタを掛けたほうが良いのですが、44.1KHz以上をカットしても32bit出力なら十分そうです。
ピークが上昇する!
変換するとピークが上昇してクリップしてしまうことがあります。
所謂「トゥルーピーク」問題です。
本質はローパスフィルタを通すと波形が変化してピークが上昇する場合があることです。
これを防ぐためにゲインを調整出来るようにします。
またint32に変換するときに鼻悪魔が出ないようにする必要があります。
私の環境だとARMだと大丈夫なのですがx86だとレベルオーバーしたときに想定外のノイズが出ます。
未定義動作は避けたほうが良さそうです。
出来たソフト
作ったソフトは一応githubに上げておきます。
https://github.com/assi-dangomushi/amaUpsample
動作確認はUbuntu22.04 と raspberrypi OS bookworm で行いました。
使い方
アップサンプリングしながら再生することを想定していますが、検証に音声ファイルを変換していきます。
sox test44k.wav -t raw -e s -b 32 - | ./amaUpsample coef1_linear 96000 -1.5 | sox -t raw -c 2 -e s -b 32 -r 96000 - test_96k.wav
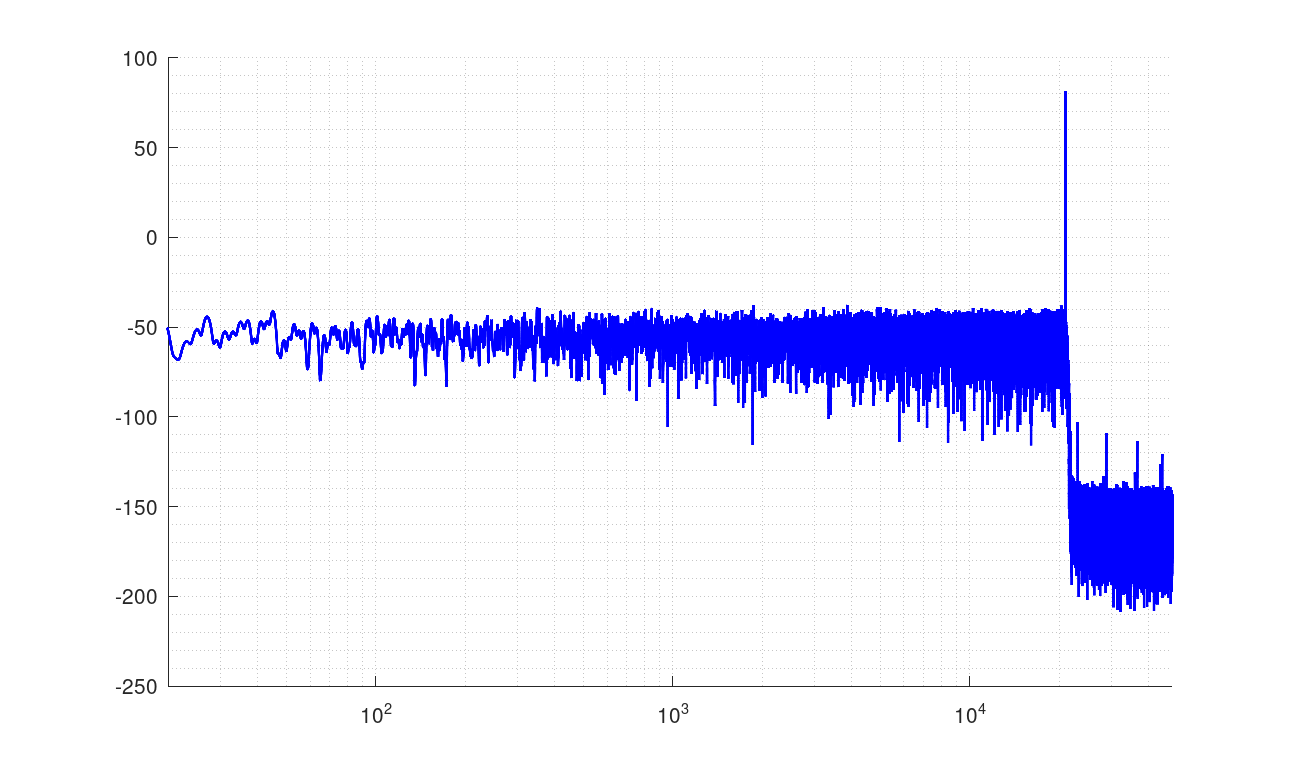
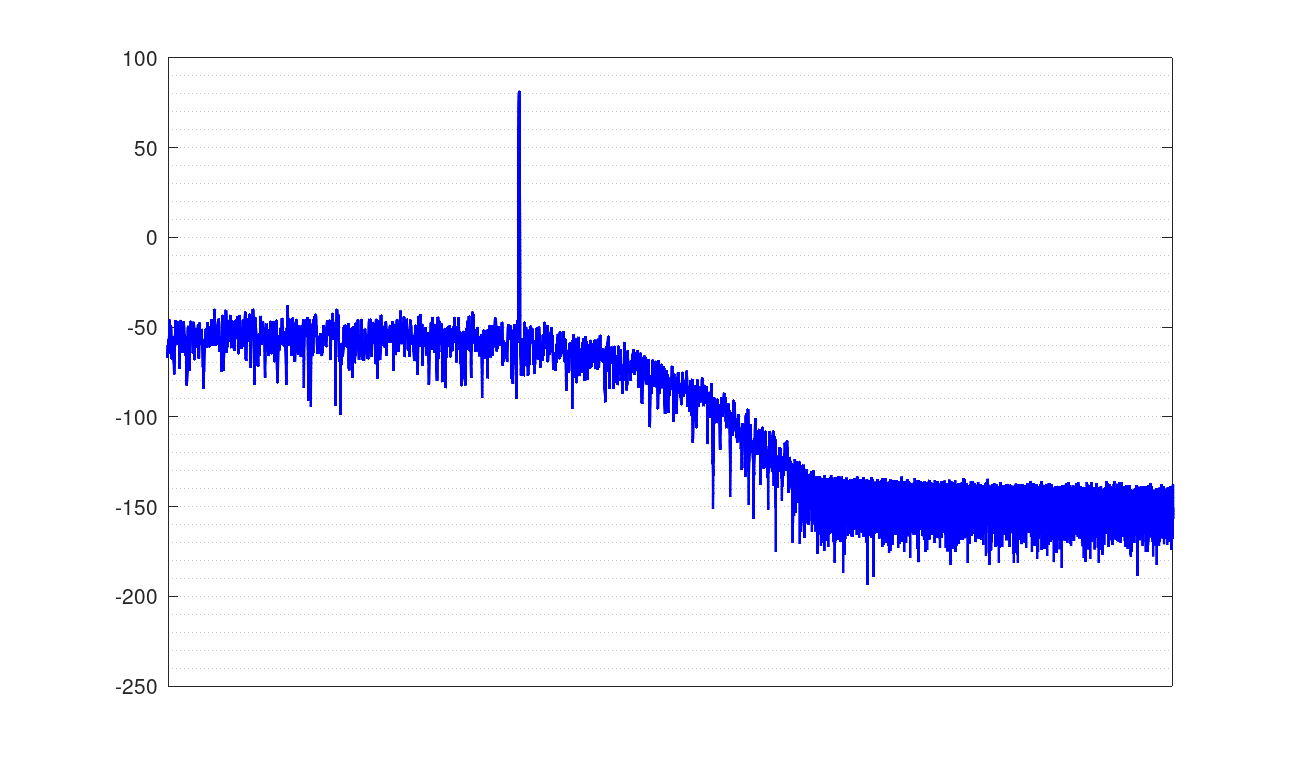
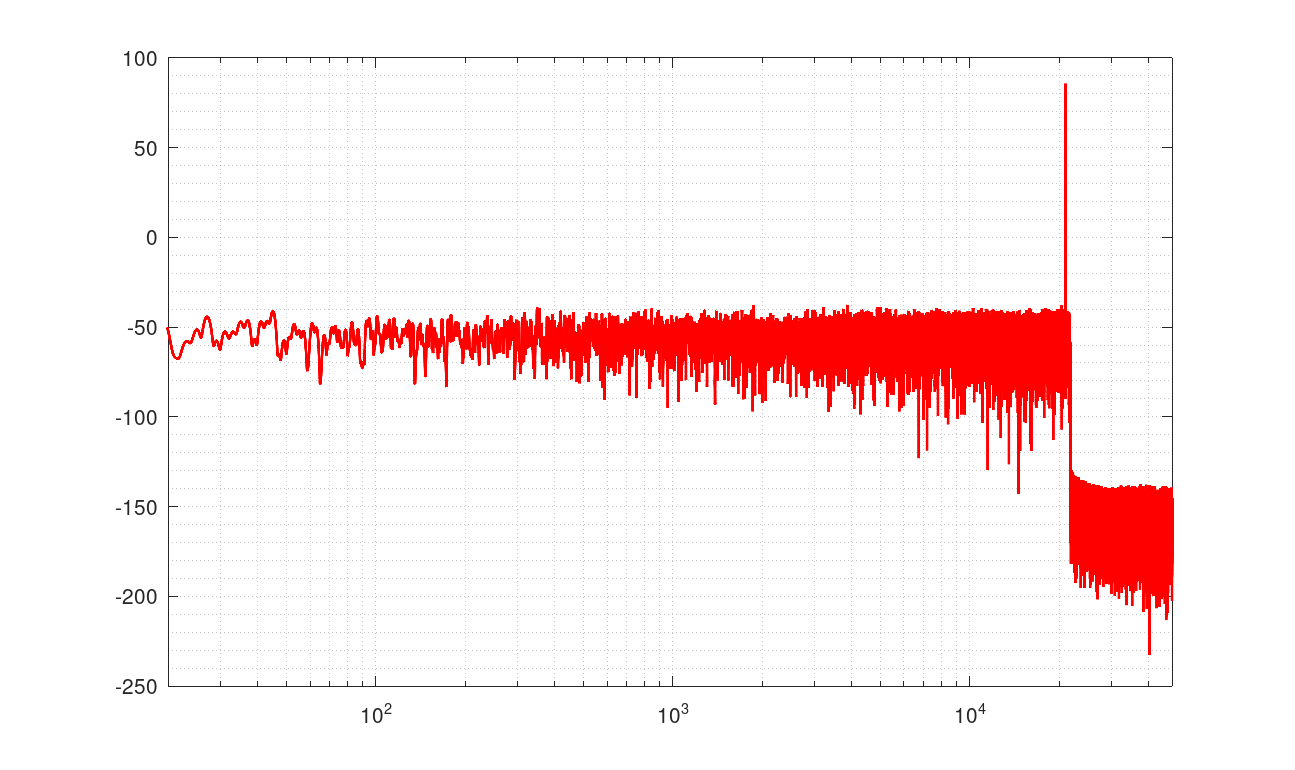
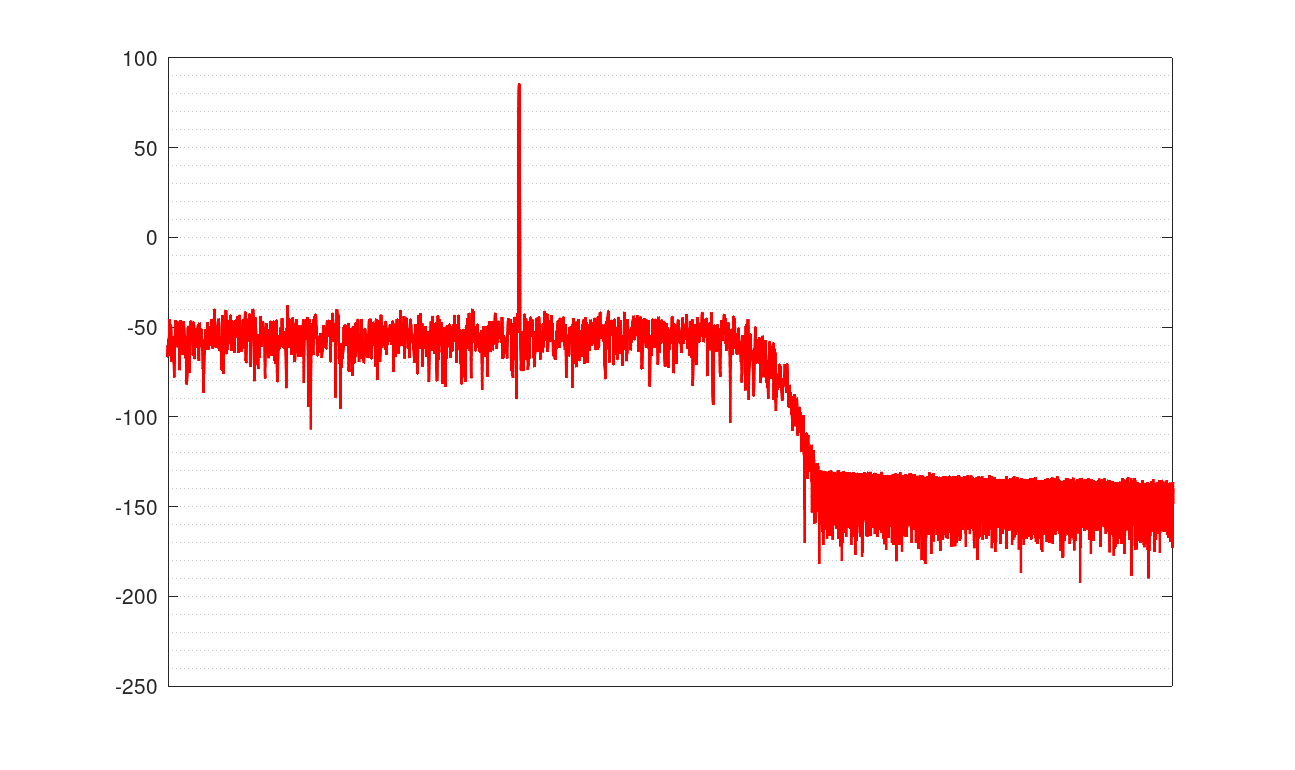
特性
21001Hzの16bit44.1KHzのテスト信号を変換した例
青がsoxのvery high、赤が自作ソフト
処理速度
120秒のテスト信号の変換に1.9秒(Core™ i5-1135G7のシングルスレッド)と十分実用範囲
これなら音声ファイルを再生するときにリアルタイムで変換できます。予めファイルを変換しておく必要はありません。
まとめ
素人がネット上の情報を見ながらアップサンプリングソフトを作ってみました。
もっと良い方法もありそうですが、とりあえず動作しました。
DAC内蔵のアップサンプリング機能がこれより精度が低ければ、音質アップする「かも」しれません。