目的
依存性注入関連の知識をまとめることを目的にしています
- 【まとめ】Singleton, DI, Service Locator比較
- Singletonデメリット
- 依存性の注入がなぜ必要か
- 結合度を下げる方法
- DIパターン
- DIコンテナ
- Searvice Locator
- DIパターン
【まとめ】Singleton, DI, Service Locator比較
- 依存性を注入する方法としてはService Locator/DI/DIコンテナがある
- Service Locator/DIコンテナは依存性の注入を行いたい時に、生成部分の結合を疎にする方法
- Singletonパターンの代わりとしてService Locator/DIコンテナを使うこともできる。Singletonパターンを使う時よりも生成分が疎。
- Singletonは依存性は注入できるが、密結合になる。抽象に依存にはならない。
- DIコンテナは依存関係が一番少なく依存性を注入する方法
- 一番シンプルで使いやすく、Singleton要件がなければDIパターンが一番よい
| 比較観点 | Singleton | Service Locator | DIコンテナ | DI |
|---|---|---|---|---|
| インスタンスの唯一性の担保 | △ | △ | △ | × |
| クラス間密結合の発生 | × | △ | △ | 〇 |
| テストのし易さ | × | × | × | 〇 |
| マルチスレッド耐性 | × | × | × | 〇 |
| 実装のし易さ | △ | △ | △ | 〇 |
Singleton
一般的な実装
class Singleton {
public:
static Singleton* GetInstance() {
if (nullptr == m_instace) {
m_instace = new Singleton();
}
return m_instace;
}
void SetValue(int num) {
m_value = num;
}
int Getvalue() {
return m_value;
}
private:
Singleton():m_value(1){};
~Singleton() = default;
static Singleton* m_instace;
int m_value;
};
Singleton* Singleton::m_instace = nullptr;
動作
Singleton* pInstance1 = Singleton::GetInstance();
printf("1つ目のInstanceの値 %d\n", pInstance1->Getvalue());//1
pInstance1->SetValue(10);
printf("1つ目のInstanceの値 %d\n", pInstance1->Getvalue());//10
Singleton* pInstance2 = Singleton::GetInstance();
printf("新しく取得したInstanceの値 %d\n", pInstance2->Getvalue());//10 pInstance1とpInstance2は同じ
//Singleton instance3;//コンストラクタは使えないので新しい別のInstanceは生成できない
Singleton* pCopyInstance = new Singleton(*pInstance1);
pCopyInstance->SetValue(3);
//Instanceが2つになってしまっている
printf("1つ目のInstanceの値 %d\n", pInstance1->Getvalue());//10
printf("CopyしたInstanceの値 %d\n", pCopyInstance->Getvalue());//3
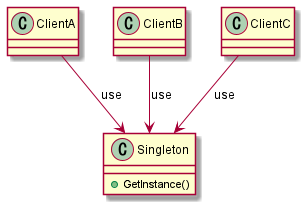
Sinletonのデメリット
-
Instanceの唯一性の担保
- コピーコンストラクタはdeleteしておく必要がある。
- 暗黙的に生成されるCopyコンストラクタで別のInstanceを生成することができる。
- コピーコンストラクタはdeleteしておく必要がある。
-
クラス間密結合の発生
- 発生する
- Singletonはグローバル変数と同じ振る舞いをするため、Singletonクラスが状態を持つ場合(メンバ変数など)はSingletonクラスを使用するクラス同士は互いに影響を受ける
-
テストのし易さ
- しにくい。密結合が原因。
- Singletonクラスが状態を持つ場合は使用者側がSingletonクラスの状態を意識してテストする必要がある。
- 自クラスとSingletonクラスとの関係性だけでテストできない
- Mockとの差し替えができない。クライアントクラスの中でGetInstance()でInstanceを取得するコードを実装してるため、Mock用のクラスをGetInstanceするのも一苦労
-
マルチスレッド耐性
- 低い
- 複数のスレッドで同時に状態が書き換わる、参照される必要がある。Mutexなどが必要。
-
実装のし易さ
- 簡単ではあるが、暗黙的に生成されるコピーコンストラクタをdeleteすることを忘れてはいけない
依存性注入がなぜ必要か
Service LocatorとDIは依存性を逆転させるための実装パターンになります。
依存性注入が解決したい課題について記載しています。
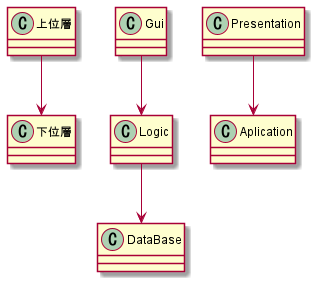
下記のクラス図は上位層が下位層に依存したクラス構成になっています。(結合度が高い状態)
依存性逆転の原則に違反した状態になっています。
このようなクラス構成の悪い点としては
- 上位層が下位層に依存してるために再利用性が低下する
- Logic部分が異なるDataBaseを利用したくなっても使えない
- 上位層が下位層の変更に逐一影響を受ける
- 単体テストが行いづらい
- DataBaseを固定のデータベースを返すようなMocに差し替えてテストしようと思っても差し替えにくい
以下のようにnewがクラス内に存在しているとクラス同士が結合しているので注意です。
class Logic
{
Logic(){
DataBase data =new DataBase()
○○クラス a = new ○○クラス()
○○クラス b = new ○○クラス()
○○クラス c = new ○○クラス()
○○クラス d = new ○○クラス()
}
}
class DataBase{
}
依存性逆転の原則に従って依存性を逆転させます。
Logic→ShopDataBaseの依存関係からLogic←ShopDataBaseの依存関係に逆転します。
(Logic内のDataBaseを継承してShopDataBaseを作っているのでShopDataBaseはLogicに依存しているとみることができます)
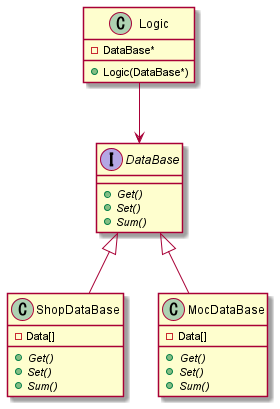
上記のようにすることでLogicが操作する先のDataBaseを切り替えることができるようになります
Test(){
Logic(new ShopDataBase());
Logic(new MocDataBase());
}
そして、LogicにDataBaseオブジェクトを渡している部分が依存性注入(Dependency Injection(DI))になります。
つまり、DIとは使う側のオブジェクトに使われる側のオブジェクト(依存オブジェクト)を渡すことをいいます。
イメージとしてはあるオブジェクトを賢くするために、依存オブジェクトを渡してどんどん賢くしていくイメージでいます。
結合度を下げる方法
結合度を下げる方法として代表的な方法としてSearvice Locatorと先ほど説明したDIパターンがあります
DIパターン
先ほど登場したようにDIパターンとは使う側のオブジェクトに使われる側のオブジェクト(依存オブジェクト)を渡すパターンをいいます。
①コンストラクタで依存オブジェクトを渡すパターン
class DataBase
{
public:
virtual void Set()
{
printf("DataBase");
};
};
class ShopDataBase: public DataBase
{
public:
void Set() override
{
printf("ShopDataBase");
};
};
class Logic
{
public:
Logic(DataBase* data)
{
data->Set();
}
};
int main()
{
Logic BaseLogic = Logic(new DataBase());
Logic ShopLogic = Logic(new ShopDataBase());
}
②Setで依存オブジェクトを渡すパターン
class Logic
{
public:
void SetDataBaseSearvice(DataBase* data)
{
m_DataSearvice = data;
m_DataSearvice->Set();
}
private:
DataBase* m_DataSearvice = nullptr;
};
int main()
{
Logic* BaseLogic = new Logic();
BaseLogic->SetDataBaseSearvice(new DataBase());
Logic* ShopLogic = new Logic();
ShopLogic->SetDataBaseSearvice(new ShopDataBase());
}
③インターフェースインジェクションパターン
インジェクション用のインターフェースクラスを実装し、継承する方法。
class IDataBaseInterface
{
public:
virtual ~IDataBaseInterface() {};
virtual void SetDataBaseSearvice(DataBase* data) = 0;
};
class Logic : public IDataBaseInterface
{
public:
void SetDataBaseSearvice(DataBase* data)
{
m_DataSearvice = data;
m_DataSearvice->Set();
}
private:
DataBase* m_DataSearvice = nullptr;
};
DIコンテナとSearvice Locator
DIコンテナとSearvice Locatorとは?については以下のリンクが分かり易い
Service LocatorとDependency InjectionパターンとDI Container
DI・DIコンテナ、ちゃんと理解出来てる・・?
クラス図はこちら参照
DIコンテナは利用者がオブジェクトを生成せずとも、内部でクラス関係を解消してオブジェクトの生成を行ってくれる。
Searvice LocatorはDIコンテナより依存関係が多く、アンチパターンとされている。
まとめの表を以下のようにした理由だけ記載していきます。
| 比較観点 | Service Locator | DIコンテナ |
|---|---|---|
| インスタンスの唯一性の担保 | △ | △ |
| クラス間密結合の発生 | △ | △ |
| テストのし易さ | × | × |
| マルチスレッド耐性 | × | × |
| 実装のし易さ | △ | △ |
- インスタンスの唯一性の担保
- Service Locator,DIコンテナともに同じ具象クラスを登録することも可能だが、どのインスタンスを取り出すかの指定までは難しい。
- Register箇所を限定すればSingletonと同じ使い方はできる。
- クラス間密結合の発生
- Singletonパターンよりは良く、DIパターンよりは悪い
- DIの場合は抽象IFのみに依存だが、Service Locator,DIコンテナともにService Locator,DIコンテナに対する依存が発生する。Singletonパターンの場合は各クラスに対してそれぞれ依存なのでより密結合。
- Singletonパターンよりは良く、DIパターンよりは悪い
- テストのし易さ
- 微妙
- Service Locatorを使用しているクラスをテストしたい場合は、事前にService Locatorに必要なクラスを登録しておく必要があるが使用者側は何を登録すべきか分かりにくい。あっちこちでService Locatorを使うと恐らく悲惨なことになる。
- DIコンテナはまだまし
- どちらも状態を持つ
int main()
{
//DIの場合はServiceクラスがクラスA,B,Cに依存していることがぱっと見でわかる
auto SampleService = new Service(new A(), new B(), new C());
SampleService .do()
//Service Locator
auto SampleService = Locator<Service>.resolve();//Serviceの中でA,B,Cを使っているので本来は事前にA,B,Cの登録が必要
SampleService .do()//事前に必要なクラスを登録できていない...
}
- マルチスレッド耐性
- 基本実装だけだと耐性なし
- Singletonパターンの時同様に基本的にはグローバル変数と同じなので、マルチスレッド用の対応が必要になる
- 実装のし易さ
- DIパターンやSingletonパターンに比べるとやや複雑
c++で作られたDIコンテナライブラリ
世の中で実際どのように実装されているかは以下を参照
↓ の例はbuild時に登録されていなくてもresolveで生成し、使用できるような設計になっている。
DIコンテナライブラリ
↑の環境構築方法