きっかけ
メルカリコンペ1位のコードに出てきたitemgetterとTfidfVectorizerが良く分からなかったから。
まとめ
itemgetter→イテラブル(リスト,文字列などfor文のinに書き込めるオブジェクト)から任意の要素を抜き出すことができる。
TfidfVectorizer→文章内の重要な文字を算出する際に使用する。スコアが高いほど文書内の出現頻度が高く、ほかの文書には出現しにくい文字であることを示す。
itemgetter
name要素を取得する呼び出し可能なオブジェクトが一行目で返されている。
二行目でname要素だけを抽出している。
qiita.rb
from operator import itemgetter
item=itemgetter("name")
item({'name':['taro','yamada'], 'age':[5,6]})

TfidfVectorizer
TF-IDFを算出する際に使用する。
TF-IDFは文書の中で重要な文字列は何かを特定する際に使用する。
コンペ内では、出展されている商品のブランド名を数値化するために使用されている。
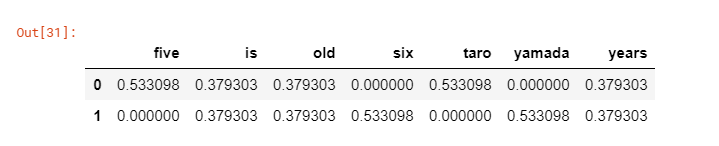
以下の例ではfive,six,taro,yamadaの出現頻度が高く、他の文書には登場していない為、スコアが高くなっている。
qiita.rb
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
sample_string= np.array(['taro is five years old','yamada is six years old'])
tfidf=Tfidf(max_features=100000, token_pattern='\w+')
x=tfidf.fit_transform(sample_string)
pd.DataFrame(y.toarray(), columns=tfidf.get_feature_names())

itemgetter, TfidfVectorizer, Pipelineの併用
itemgetter("name")のインスタンスとTfidfのインスタンスをパイプライン化している。
.transformでname要素の抽出が行われたのちに、name要素の中での重要度の算出が実行されている。
パイプライン化はこちら
qiita.rb
from sklearn.pipeline import make_pipeline, make_union, Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
from operator import itemgetter
from sklearn.preprocessing import FunctionTransformer
import pandas as pd
def on_field(f: str, *vec) -> Pipeline:
return make_pipeline(FunctionTransformer(itemgetter(f), validate=False), *vec)
df=pd.DataFrame({'string':['taro is five years old','yamada is six years old'], 'age':[5,6]})
Pipeline=on_field('string', Tfidf(max_features=100000, token_pattern='\w+'))
Pipeline.fit(df)
data=Pipeline.transform(df)
pd.DataFrame(data.toarray(),columns=tfidf.get_feature_names())