はじめに
今回は,現日本の総理大臣が2021年に総理として実践したいことをデータ(総理所信表明演説)から
導いていいきたいと思います.
分析に至る経緯
僕は,最近就活をぼちぼちしているのですが,あるベンチャー企業の面接をしている
中で政治が進めたい方向とビジネスをマッチさせながら進めて行くというやり方が
あるという話をしていただきました.
その話の中で僕が思ったのは,それを客観的にわかるものがあったら便利だなと感じ
分析してみた感じです.
ちなみに,その企業の面接を受け,お話できたのはすごくよかったなと感じています.
注意事項
この分析は,僕がなるべく客観的にデータを見てストップワードを設定し分析をしています.
特に政治的主張はありません.
また,所属企業や団体とは一切関係なく,一個人としての分析ですのでそちらをご了承いただけますよう宜しくお願い致します.
分析のアジェンダ
・データの取得
使用ライブラリ:☆BeautifulSoup☆requests
・データの前処理
使用ライブラリ:☆MeCab☆pandas
・可視化
使用ライブラリ:☆nlplot
分析過程
データの取得
#第二百四回国会における菅内閣総理大臣施政方針演説
name='https://www.kantei.go.jp/jp/99_suga/statement/2021/0118shoshinhyomei.html'
site = requests.get(name)
data = BeautifulSoup(site.content, 'html.parser')
データの前処理
・データフレームの作成
cols = ['col1', 'col2','col3']
df = pd.DataFrame(index=[], columns=cols)
record = pd.Series(['hoge', 'fuga','fuga'], index=df.columns)
for _ in range(1):
df = df.append(record, ignore_index=True)
・ストップワードを対象テキストから外す(uni-gram用)
text=str(p)
stopwords = ['こと','君','して','これ','(','する','した','ます','よう','ん','私','ふう','あり','いる','中','これ','それ','方','てい','さん','ですが','今','うの','者','の','また','から','ため','等','わけ','たい'\
'とい','そ','(','こ',')','思い','うに','ですか','ころ','うで','二','一','十','三','四','五','六','八','九','いろ','しま','ござ','だき','いと','さ','いか','ながら','対','だい','だい','つき','なか','考え'\
'とい','(',')','とろ','的','い','ある','応','人','とき','答え','年','回','関','月日','いま','ちょっと','たい','上','なる','たま','何','本当','皆様','つて','にお','策','係','げ','考え','まり','はな','日','度','だで'\
'大臣','国務大臣','月','たで','先','後','話','とも','より','ら','しか','ですよ','形','委員会','七','本','間','質問','順','本','など','すね','受け','分','皆','申','総理','委員長','山','基','ゆう','なう','化','たに','百','万','政'\
'機','時','政','場合','是非','以','府','願','国','大変','行','たも','民','会','家','大臣','議論','機','点','件','理解','制','号','議','社','規','員','体','期','庁','場','相談','全','委','長','部','円','組','個','なな','たち','心','党','○'\
'たとう','()','(',')','○(','○()','○(','がま','たとう','○','<','/>','br','p','b','><',"''",'/>','>>','>>',',','○','◯','千','兆','とし','安','力','成','際','額','他','割','米','つくり','つな','にし','億','像','多く'\
'模','池','象','協','限','立','交','定','文','金','地','融','模','〇','域','材','多く','づくり','土','資','格','投','核','官','名','強','未','育','達','添','sc','rit','java','sc','隣','わり','えな',']','おに','なに','適切','末','子'\
'外','教']
for i1 in range(len(stopwords)):
print(stopwords[i1])
text=text.replace(stopwords[i1],'')
・ストップワードを対象テキストから外す(bi-gram,tri-gram用)
text1=str(p)
stopwords = ['○','<','/>','br','p','b','><',"''",'/>','>>','>>',',','○','◯','〇','sc','rit','java','sc',']','円','一','二','三','四','五','六','七','八','九','十','%','百','千','万','兆','億','年'\
,'いき','ます','しま','した','する','こと','げ','ます','つな','げ','そう','した','あり','ます','こう','した','して','から','こと','とし','これ','より','など','さん','か月','間','ある','の','わり','まい','てり',' 上','そ','ため']
for i1 in range(len(stopwords)):
print(stopwords[i1])
text1=text1.replace(stopwords[i1],'')
・形態素分析(uni-gram用)
tagger = MeCab.Tagger("-Owakati")
tagger.parse("")
lst = []
try:
node = tagger.parseToNode(str(text)).next
while node.next:
if "名詞," in node.feature:
lst.append(node.surface)
node = node.next
except:
print("error")
・形態素分析(bi-gram,tri-gram用)
tagger = MeCab.Tagger("-Owakati")
tagger.parse("")
lst1 = []
try:
node = tagger.parseToNode(str(text1)).next
while node.next:
if "名詞," in node.feature:
lst1.append(node.surface)
node = node.next
except:
print("error")
・データフレームに格納
df['col1'][0]=p
df['col2'][0]=lst
df['col3'][0]=lst1
・OnePoint
通常の辞書を利用して,形態素分析を行うと,人名などを一文字ずつ切ってしまったりするので,独自辞書を設定することをお勧めします.
特に,Wikipediaのやつを使うと良くなりました!
可視化
import nlplot
npt = nlplot.NLPlot(df, target_col='col2')
npt1 = nlplot.NLPlot(df, target_col='col3')
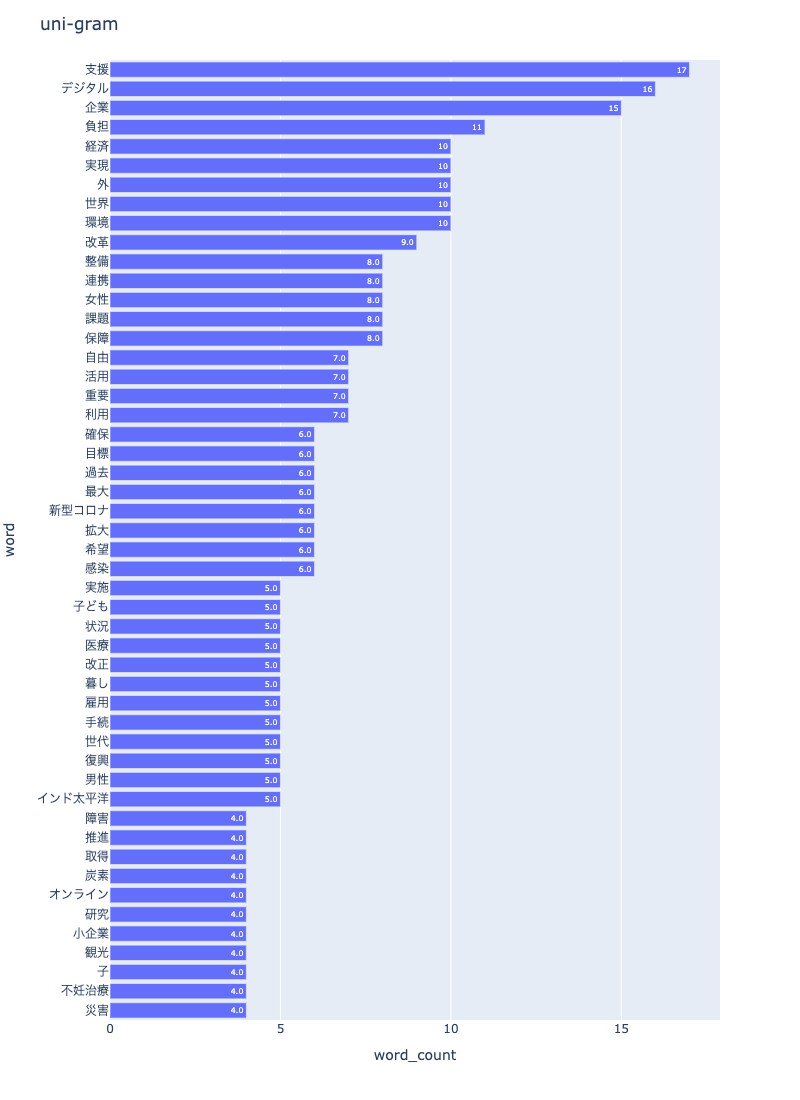
uni-gram
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=50,
save=True
)
可視化画像
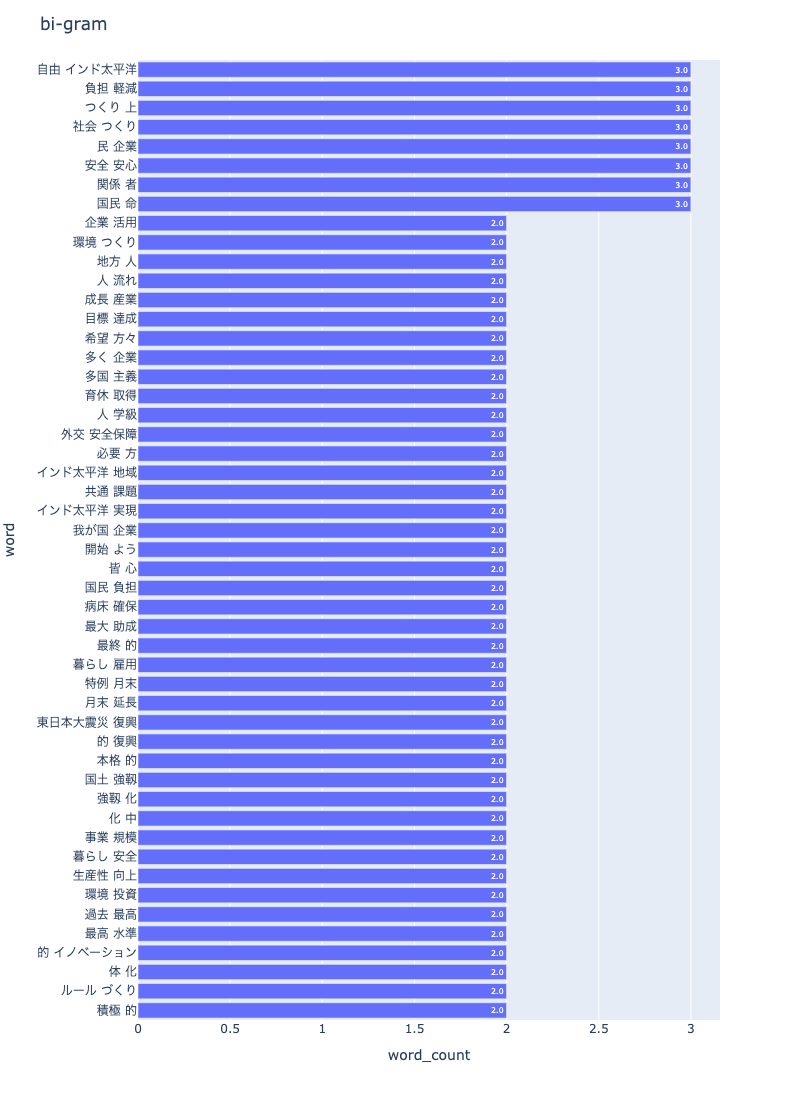
bi-gram
npt1.bar_ngram(
title='bi-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=2,
top_n=50,
stopwords=stopwords,
save=True
)
可視化画像
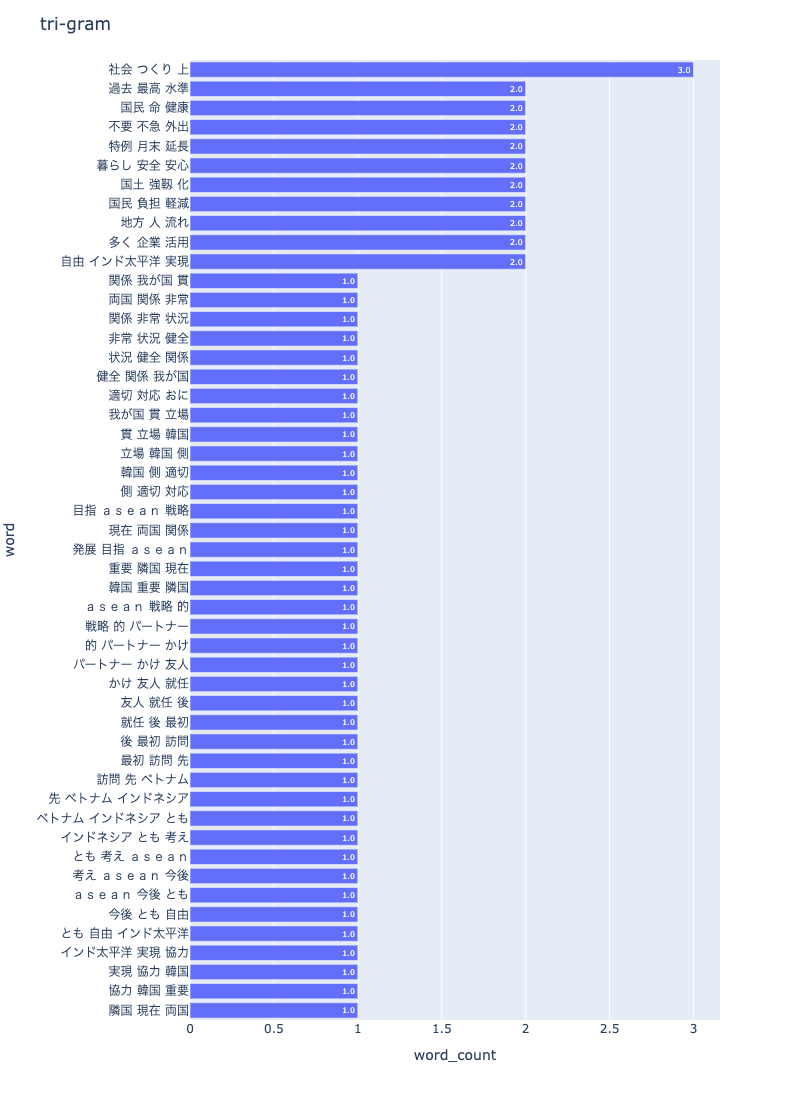
tri-gram
npt1.bar_ngram(
title='tri-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=3,
top_n=50,
stopwords=stopwords,
save=True
)
可視化画像
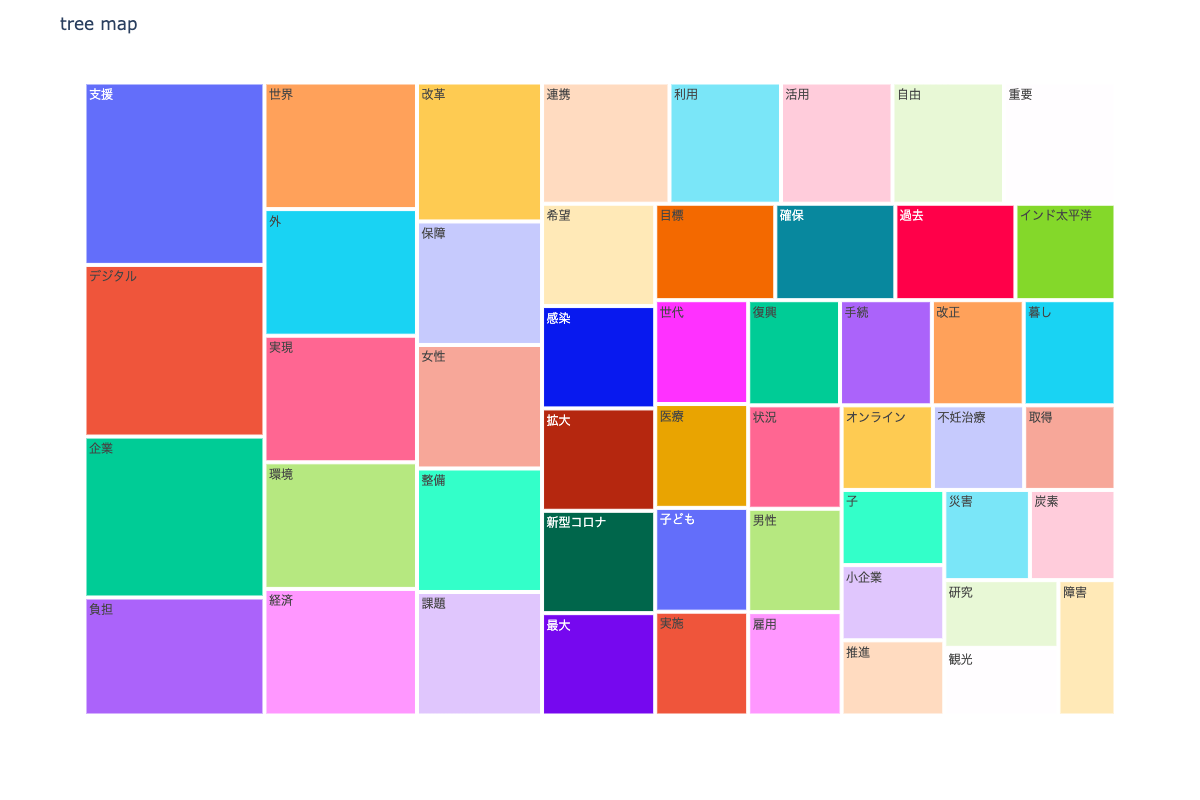
tree map
npt.treemap(
title='tree map',
ngram=1,
stopwords=stopwords,
width=1200,
height=800,
save=True
)
可視化画像
wordcloud
npt.wordcloud(
stopwords=stopwords,
max_words=100,
max_font_size=100,
colormap='tab20_r',
save=True
)
可視化画像

分析全体を通しての感想
今回の分析では,客観性を担保する為に中身にことについて言及はしないでおこうと考えているので,分析自体の感想を少し述べると,
・自然言語は,可視化よりもストップワードをどうとるかが一番難しいところであり,
腕の見せ所なのではないかなと感じました.
例えば,今回はかなり数字などは,ストップワードで設定しましたが,数字を入れるとまた違った形になる可能性も考えられます.
その辺はみたいところによってテイクアンドリリースなのではないかなと感じます.
あとは,政治独特の言い回しは結構多いように感じました.
最後に
皆さんがこの記事を見て,きっと今年の日本はこれに力を入れたいんだなと感じられるものがあるのではないでしょうか?
もっとこういうのが見たい!見たいなコメントを頂けたりするととても嬉しいです!
それでは,今回はこれにて終了したいなと思います.
次記事を書くときは,国会分析をしようかなと思います.
それではありがとうございました.
参考記事
ソース