前回まで
前回の記事
https://qiita.com/asmg07/items/e3be94a3e0f0195c383b
前回はシステム導入について書いたので次は学習について書いていきます.
プログラムのゴール
そういえば,プログラムのゴールを書いてないし決めてなかったのでとりあえず
ゴールを決めます.一応,今は学生で昔授業で作ったプログラムを改良したいなと思って
書いています.一応それが開発の理由です.
とりあえず,ゴールは乃木坂が好きなので,乃木坂個人判別分類器を作れたりしたらいいなw
余談でした.
学習の方法
余談は置いといてとりあえずは,使い方を覚えたいのでいろいろな人がやっているマスクを
しているか,していないかの画像を使ってやっていこうかなと思います.と言おうと思ったけどせっかくなので別のモデルをw
車のモデルを使ってやってみたいと思います.
せっかくなので自分でモデルを作ります.
乃木坂ちゃんたちを見たいよw
手順1 アノテーション
(1)画像作成
使うソフトは以下のものURLを載せておきます.
https://github.com/Microsoft/VoTT/releases
以下のデータセットを作っていきます.
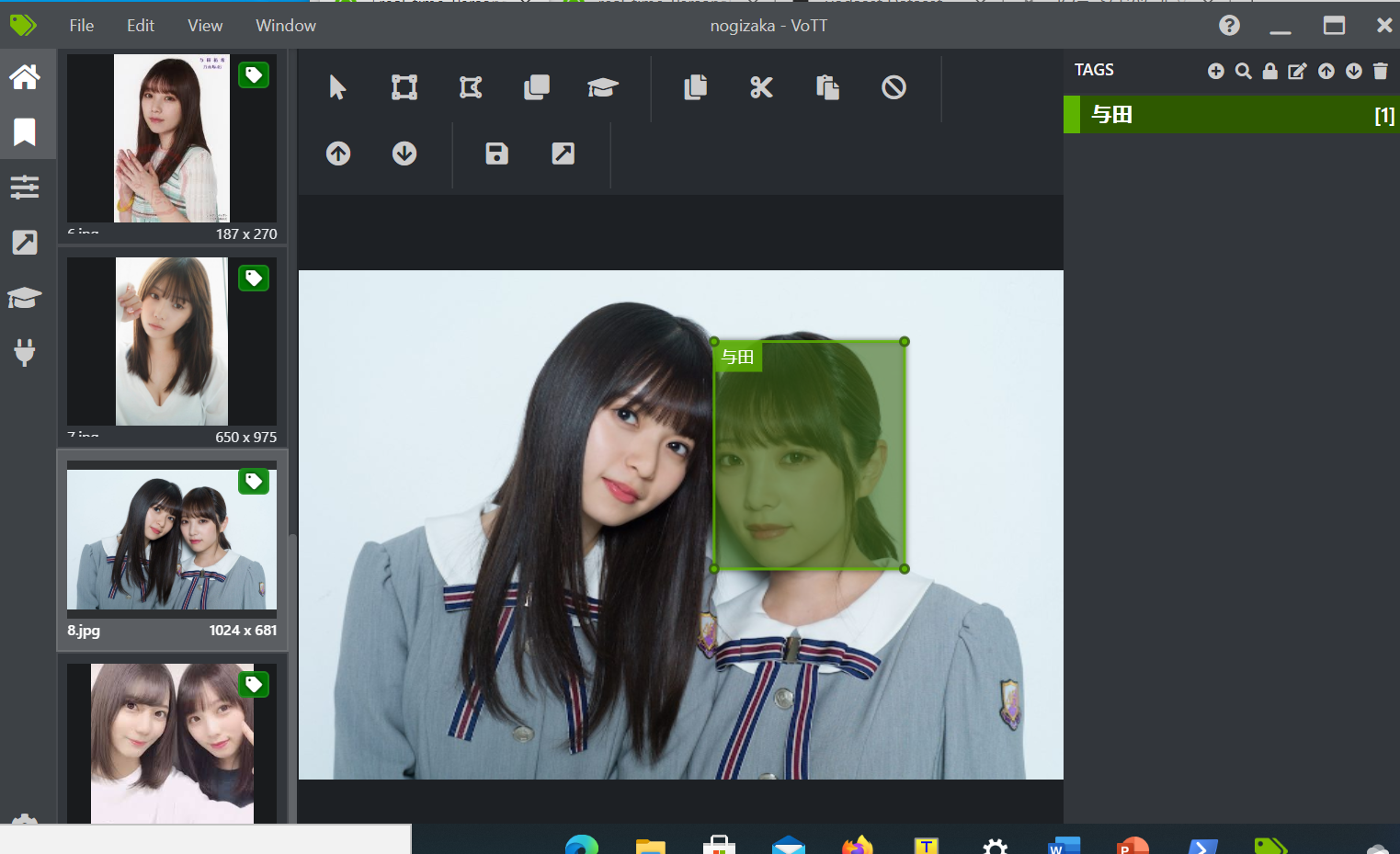
こんな感じで作っています.
(2)Yolo用のデータセットに変更
まぁいろいろやるんですけど参考サイトが参考になります.
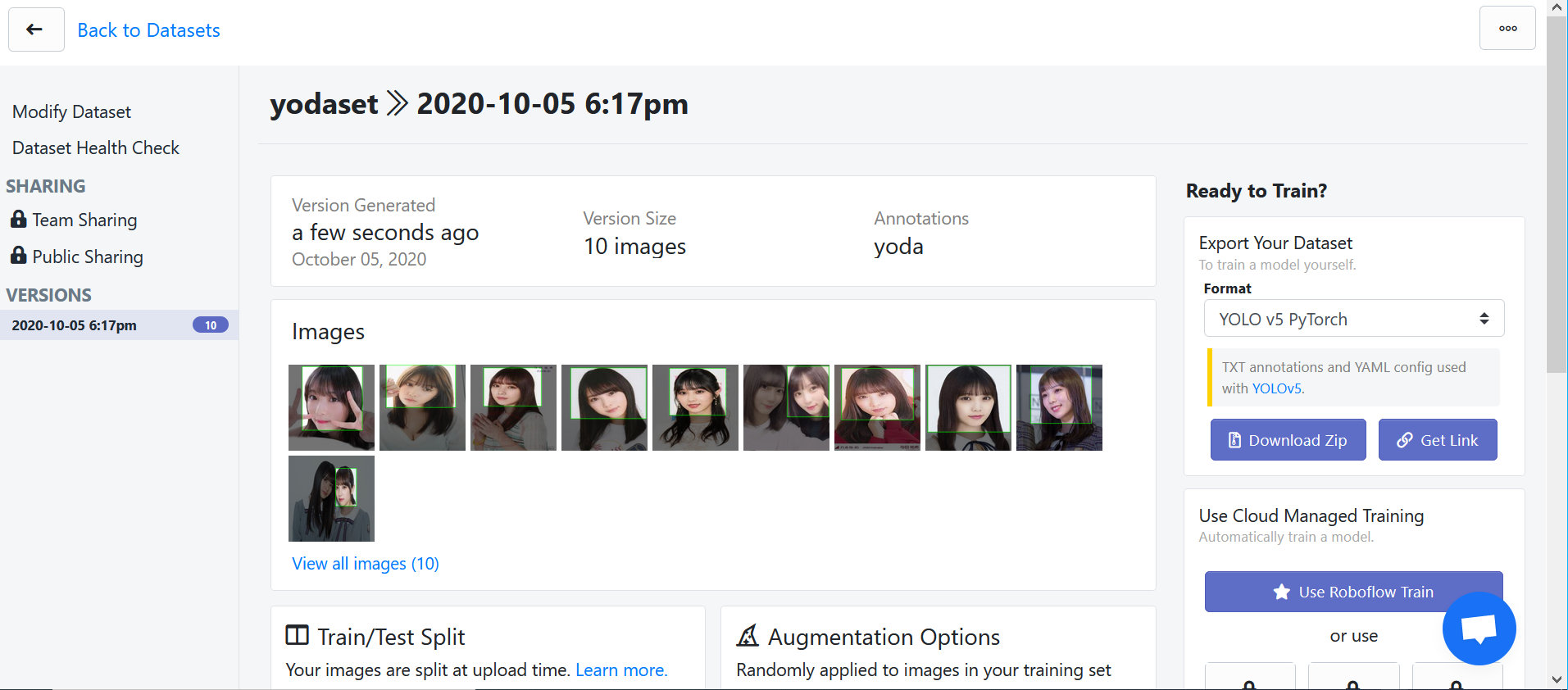
最後は結局こんな感じになります.
以下のサイトを参考にしています.
https://konchangakita.hatenablog.com/entry/2020/08/24/220000
(3)Yoloでの学習
学習については,今現在ローカル環境でやるか,Googleのやつを使うか検討中です.
いろいろ考えたあげく,とりあえずローカル環境でやってみようと思ってやってみようということにしました.
とりあえず1カテゴリでのデータセットでモデルを構築しました.なお,とりあえずでやってみたのでコマンドとかいろいろ間違ってるかもしれません.
train: test/train/images
val: test/valid/images
nc: 1
names: ['yoda']
実行する為に使用したコマンド
学習している過程

結果
学習後の結果はこのように出ました.
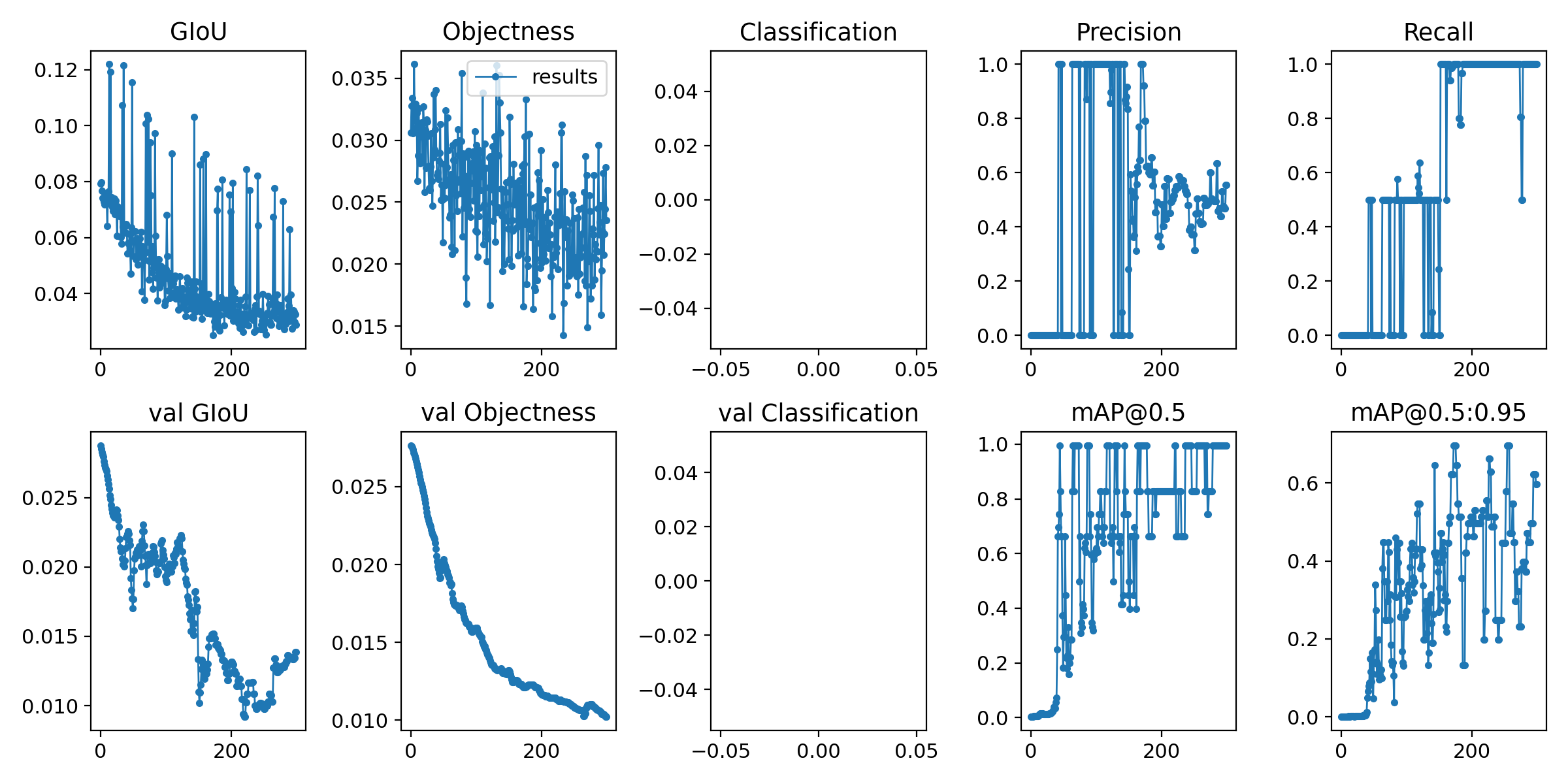
これってうまく学習できているのかな?
よくわかりません.多分できていないような気がする.
まぁモデルを作ったから試しに実行してみました.
結果がこちら

はい.失敗です.
まぁ学習データ10枚の1カテゴリでやったからそんなうまくいかないよね.
次はうまくいくように調整してやってみます.
最後に
今回はモデルの作り方から実行までやってみました.
次はモデルをうまく作るところに焦点を当ててやってみます.